
基于深度学习技术的恶意APP软件动态检测技术
2020-04-23 01:22欧阳元东
电子技术与软件工程 2020年5期
欧阳元东
(东莞理工学校 广东省东莞市 523000)
目前,智能手机普及率不断的增加,智能手机应用功能也在不断的增加。由于恶意代码数量与种类持续增加,代码混淆、加密等技术也在不断发展,增加了网络用户数量的流量,从而导致恶意代码检测面临挑战。深度学习为促进人工智能发展主要技术,能够对人脑神经网络模拟,涉及到计算机传统领域。深度学习算法重点为大数据处理,所以深度学习能够在未来互联网用户信息数据爆炸中使用[1]。在信息安全领域中使用深度学习,通过全新的框架模式与检测技术应用到网络用户中,能够使信息安全得到提高。
1 系统的设计结构
本文实现基于深度学习算法的恶意APP 软件动态检测系统,此系统利用爬虫爬取得到良性、恶意软件的特征,在分析数据降维之后使得到的特征通过深度学习算法创建三层神经网络之后,通过数据集交叉验证,确定此方法检测正确率,丰富APP 恶意软件检测的方法,使检测效果得到提高。图1 为系统的设计结构,系统主要包括三大部分,分别为网络爬虫的编写,收集数据集;收集APK静态代码特征与动态行为特征,特征降维之后实现深度学习,并且创建良好神经网络实现检测[2]。
2 恶意代码的检测
通过反编译工具进行静态分析,以此能够得出反编译文件,对虚拟机执行的动作进行解释,去除无关的动作指令,保留手写字母,将其作为动作指令,分别为M为移动、R为返回、G为跳转、I为判断、T 为取数据、P 为存数据、V 为动作指令。之后,对数据提取统计,以此提供检测系统特征集和数据来源。
通过沙盒实现动态分析,以此使未知代码导致的静态分析缺乏检测能力问题得到解决,提高检测性能。利用开源收集系统中的沙盒工具进行分析,从而记录执行次数与动作,分析动作且进行分类。将静态分析思路作为基础,利用相同算法进行机器学习,实现动态行为检测模型的创建[3]。
得出的文本信息就是挖掘样本特征,文档中的内容语言要求人类能够理解和使用。计算机无法理解语义,所以要通过结构化数据实现。那么,就要提取有意义的文本特征,从而解决文本中的问题,得到精准信息后建模,分类文本。利用监督分类实现数据挖掘分类[4]。
3 词向量模型的设计
词向量模型是将文本单词转变成为数字向量的方法,计算机系统处理后此能够理解文本语义信息,并且对信息进行存储。在提取文本信息之后,通过图2 的预处理流程,首先使原始文本中分词与相应预处理使其作为词序列。在语料词表中的词都具有唯一编码,也就是词编码。在得到词序列之后是按元素序列的转变,最后使词编号序列所对应词语转变成为Glove 词向量方式。通过此处理,使原始文本信息转变成为特征图形式。
n-gram 为词向量模型出现前的统计语言模型,此模型使用较为广泛。统计语言模型能够实现单词序列和概率密度学习相互结合,但是此过程较为复杂,还会出现维数灾难等问题。为了使此问题得到解决,学者提出了利用神经网络训练词分布表示,通过相邻句子指数级别信息构成训练语句。此模型能够学习词语出现的序列与分布,利用相邻词预测当前值,实现模型最大化的出现概率进行创建[5]。

图1:系统的设计结构
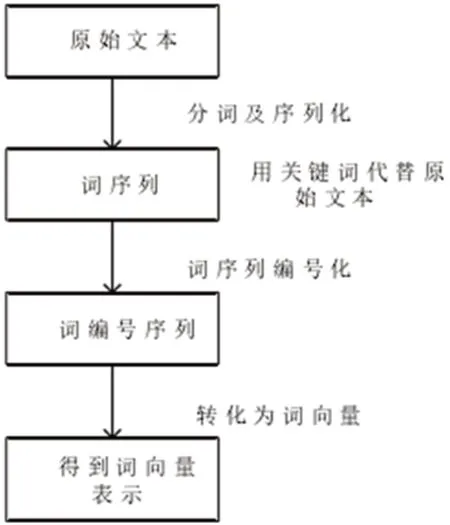
图2:预处理流程
此神经网络模型训练集为次序列W1,...,WT-1,WT,并且利用学习合适函数估算条件概率:

约束条件满足为:

此神经网络模型主要包括隐藏层与共享层的特征层C,利用Softmax 函数创建输出层:
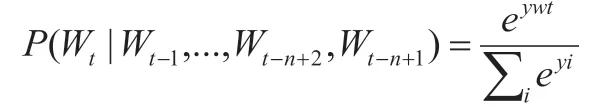
公式中的yi 是指每个输出层i 缺乏归一化概率,最终输出计算公式为:

公式中的x 指的是输入,其他为参数。
通过h 隐藏单元数目创建神经网络,|v|指的是词表大小,|v|维列向量表示b。假如利用随机梯度降低方法进行训练,梯度更新法通过以下公式表示:
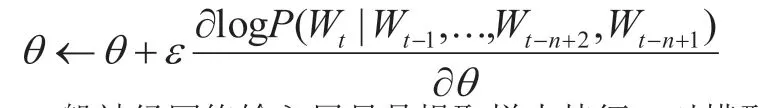
一般神经网络输入层只是提取样本特征,对模型输入层x 进行优化。利用分析结果看出来,此语言模型的效果比较好。
利用前面分析表示,神经语言模型以以上词预测出现下个词的概率,利用监督学习思想。文本中的全部话语指的都是需要分析与处理样本,当前词是指训练标签,然后训练词向量,训练目标指的是当前词的最大化概率[6]。
4 实验设计和分析
本文通过Python 语言实现恶意APP 软件动态检测系统数据预处理模块与API 调用序列编码模块,在数据与处理模块的反编译工具使用Androguard 工具包,恶意应用检测模块神经网络模型为Keras 深度学习框架。本文开发将CNN 为基础的恶意应用检测原型系统,需要环境与工具为笔记本电脑、8G 内存、Python3.6、Java开发工具包和PyCharm。
恶意应用检测为APP 恶意应用检测系统的核心阶段,重点为创建模型,优化模型结构,分类模型训练等。利用深度学习技术创建CNN 模型,深度学习技术为基于高层次与高度模块化神经网络API,主要特点为代码结构清晰、模型创建需要少量代码量等[9]。在创建的CNN 模型中,利用adam 作为优化函数,使用ReLU 作为激活函数。因为为二分类问题,所以使用binary_crossentropy 作为损失函数,网络模型最后一层输出层利用sigmoid 成为激活函数。在模型训练过程中,迭代轮数与样本数在不断的增加,也增加了模型训练准确率。在通过迭代轮数之后,也会降低损失,增加准确率。模型收敛后,也就结束训练。图4 为训练准确率的变化,在历经41 次后,模型准确率逐渐稳定。
因为深度学习模型中有大量节点与隐藏层,主要特点为具有较强拟合能力,能够接受大量特征输入,对应用样本内在信息描述。为了避免出现过拟合的情况,在实验过程中使用正则化方法。在损失函数后添加正则化项,对模型复杂程度控制,避免模型过分拟合数据。在训练模型中将部分参数更新忽略,因为模型引入随机性,使泛化能力得到提高,降低过拟合情况。
5 结束语
本文利用深度学习技术提取APP 多类行为特征数据,之后使特征数据创新性转变成为样本特征矩阵。本文创新传统分类算法在对于大数据低效率型、局限性、同类型特征在APP 恶意行为检测中的问题,使算法分类判性可靠性得到提高。本文对设计的系统进行实验,通过实验结果表示,本作品在执行效率、准确率方面具有良好效果。

图3:词向量模型训练的流程

图4:训练准确率的变化
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
电子制作(2019年19期)2019-11-23
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
高中生学习·高三版(2016年9期)2016-05-14
重型机械(2016年1期)2016-03-01
新高考·高二数学(2015年11期)2015-12-23
