
基于随机博弈与禁忌搜索的网络防御策略选取
2020-04-21 07:57薛雷琦王宇翔
计算机研究与发展 2020年4期
孙 骞 薛雷琦 高 岭,3 王 海 王宇翔
1(西北大学现代教育技术中心 西安 710127) 2(西北大学信息科学与技术学院新型网络智能信息服务国家地方联合工程研究中心 西安 710127) 3(西安工程大学计算机科学学院新型网络智能信息服务国家地方联合工程研究中心 西安 710600)
互联网+时代给社会各个方面带来便捷的同时,网络安全威胁也随之而来,各类网络攻击也日益增多[1].金融、医疗、通信以及电力等重要网络的规模较为庞大,网络结构复杂,网络节点数据维度和数量不断增加[2].近年来,勒索病毒、DDos攻击、钓鱼邮件、木马、缓存区溢出等攻击依然是当前的主要安全攻击行为.当攻击者利用网络漏洞发动以获取目标主机权限的攻击时,防守者必须依据当前网络状态所暴露出的问题快速选择网络防御策略进行有效阻击,这里所说的网络防御策略是由一系列防御动作构成的集合,常用的方法有阻断连接、删除恶意代码、漏洞加固、权限恢复等.当承载大量应用服务的网络系统遭受入侵时如果仅选择切断互联网接入,那么意味着防守方中断了所有的业务,其业务损失代价会给机构带来严重后果,例如游戏、视频服务,或者云平台、集群服务等.因此,这就需要对于网络攻防过程进行精准的数据分析,并得出防护代价最小、防御效果最好的安全策略[3],使得在有限防御条件下尽量保障业务的连续性和可靠性.网络攻击与防御均存在一定的成本代价,也有相应的收益,双方在有限资源条件约束下,通过攻防过程的成本收益计算得出最优的防御策[4].博弈论的目标对立性、策略依存性等特点与网络攻防的特点高度契合[5].国内外基于博弈论的网络攻防研究已经取得了一定的成果,有研究者引入随机博弈解决此类问题.随机博弈不仅将传统博弈的单状态扩展到了多状态,而且对于网络攻防的随机性也做出了更合理的解释.但仍存在前置条件偏离实际、攻防代价模型缺乏现实参数不足等问题,使得防御策略的实用价值降低.
现有的随机博弈大多都是以完全理性博弈为条件[6],完全理性包括分析推理能力、识别判断能力、记忆能力和准确行为能力等多方面的完美性要求,每次所选取的防御策略均为均衡策略,而在实际网络攻防中,攻防双方并不一定会选取均衡策略,双方的信息不对称,并且对抗的复杂度也在动态变化,基本很难达到每次策略的理性.网络环境的复杂性致使实际情况下随机博弈的状态转移概率无法确定,导致现有的方法得到的最优策略很难运用到实际的网络防御中去.张恒巍等人[7]从动态对抗的角度提出攻防信号博弈模型,将攻防双方分别看作信号的接受方与发送方,并对于求解提出了精炼贝叶斯进行均衡求解的方法.姜伟等人[8]提出一种攻防随机博弈模型,该模型针对网络攻防矛盾进行了描述,并且可以对攻击行为进行预测从而选取最适合的防御策略.林旺群等人[3]针对静态博弈无法应对攻击者攻击意图和攻击策略动态变化的不足,提出完全信息动态博弈主动防御模型,从子博弈精炼Nash均衡解.White等人[9]基于完全信息博弈对网络攻防进行了分析,并得出最优防御策略.王元卓等人[2]提出了基于随机博弈模型的网络攻防实验整体架构,对典型的企业网络进行分析.上述研究的前提条件为完全理性,而现实中的网络攻防由于完全理性条件的完美性很难符合,导致以上文献的分析方法在现实中会有偏差,使得防守方所得到的防御策略不一定是代价最小的防御策略,没有很好地为防守方降低成本.
近年来也有将有限理性引入攻防的博弈研究中,有限理性的运用主要在演化博弈当中[10],在攻防博弈中进行学习,从而学习到最优的防御策略以使防御效益最大化.杨峻楠等人[11]将WoLF-PHC方法引入到随机博弈中去,并引入了资格迹以提高在线学习速率.但是,资格迹的引入却带来了附加的内存和运算的开销.张红旗等人[12]在随机博弈中应用了Q-learning方法,设计了防御决策方法,所提方法具有在线学习的功能,但模型对于攻防双方的信息收集程度要求较高,实际中很难做到.黄健明等人[13]通过引入激励系数构建演化博弈模型,以群体为研究对象,采用生物进化机制,但该演化博弈中局中人的信息交换过多,而结果以群体为对象,无法给出个体成员的防御策略.
禁忌搜索方法是一种亚启发式随机搜索方法[14],利用在搜索中通过禁忌表的作用实现“记忆”功能,使得局中人可以通过这种功能进行“经验学习”,固定长度的禁忌表在“记忆”的同时不会消耗额外内存,减少了空间复杂度,提高了计算效率.
本文在有限理性的假设条件下,对攻防随机博弈决策进行研究,在攻防收益量化过程中,同时考虑了惩罚因子与攻击成功率2个因素,使得攻防收益量化更为精确;从时间片的角度考虑攻防状态转换过程的信息与行动顺序,使得攻防过程更加贴切实际攻防过程;引入禁忌搜索方法以“经验学习”的方式对本文所提模型进行分析并设计防御策略选取方法,更好地指导防守方进行防御策略选取,并通过实验验证了本文方法的有效性.
1 网络攻防禁忌随机博弈模型
实际网络攻防面临的情况比较复杂[15],但是有一点是不变的,攻防双方都追求利益最大化,防御者对于状态转移中的概率不确定导致策略选取的不确定性[16],本文从时间片的角度考虑攻防状态转换的过程,分析攻防过程可以将其离散化为一系列时间片.如图1所示,一个状态就是一个时间片,由于有限理性的条件攻防双方获取不到先验知识,所以只能通过检测网络来观察对方的行动,在某一时间片T攻防双方通过检测网络观察对方的行动,至少在时间片T+1上攻防双方会采取相应的行动,虽然攻防双方采取行动可能不是在同一时刻,但是由于攻防双方在采取动作时不知道对方所采取的动作,此时默认为是同时进行,这里的同时是一个信息概念而非时间概念,为了方便理解本文用时间片来进行解释.
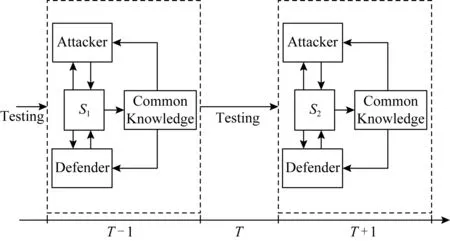
Fig. 1 Attack-defense process图1 攻防过程
实际网络攻防中,状态转移概率难以确定,对于某一网络状态,主要是与前一网络状态有关,但是对于有限理性的前提条件,本文将状态转移概率设为攻防双方的未知信息进行分析,最终获取最优防御策略.基于此给出如下模型定义.
定义1.禁忌随机博弈模型(Tabu stochastic game model,T-SGM).用一个六元组表示为T-SGM=(N,S,D,T,π),具体含义为:
1)N={Attacker,Defender}为博弈参与人,分别表示防守方与攻击方;
2)S={S1,S2,…,Sn}为博弈状态集合;
3)D={D1,D2,…,Dn}为防守方的动作集合,其中D1={d1,d2,…,dl}指防守方在状态S1的动作集合;
4)Len_T=L为禁忌表长度;

6)Ud(Si)为防守方在状态Si下的收益函数.
1.1 攻防博弈状态
本文从时间片的角度考虑网络攻防过程,每个时间片是一个网络安全状态,并将其作为博弈状态集合.某时刻T网络安全状态反映的是当前时刻T网络的脆弱性信息、节点服务信息、节点访问权限等.而攻防双方采取的动作会影响这些信息的改变,进而使得网络安全状态发生转变.依据图1的攻防过程可以将攻防博弈状态用如图2所示的有向图G=(S,E)来表示,其中S表示攻防过程中的博弈状态集合,E表示攻防状态转换关系且用有向边来表示.图2中S={S1,S2,S3}表示博弈过程的3个状态,这3个状态可以转换.在实际的网络环境中,每个状态之间不一定可以转换,导致状态的难以确定,因此本文对于状态的考虑是从时间片去考虑每个状态相对于彼此都是独立的,这是因为时间片不同的关系导致其状态的不同,这样对于状态的考虑就可以对于每个时间片的状态进行最优策略选取,使得防御效益最大化.
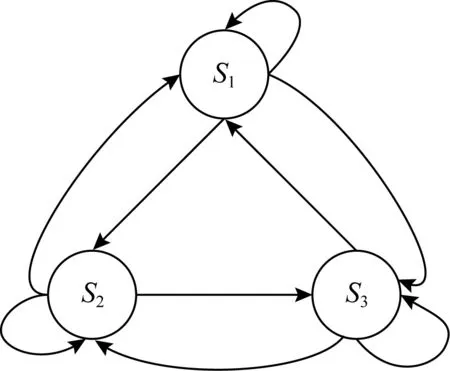
Fig. 2 State graph of stochastic game图2 随机博弈状态图
1.2 攻防收益量化
网络中安全属性的损害包括完整性代价IC、机密性代价CC、可用性代价UC,分别用PIC,PCC,PUC表示安全属性的损害对每一种属性代价的偏重.在参考文献[8,17]的基础上做出如下收益量化.
定义2.攻击成功率.攻击方采取相应的攻击动作的成功率,当攻击一定成功时σ=1,当攻击无效时σ=0,其他情况为0<σ<1.
定义3.损失代价.攻击者采取相应攻击动作造成的系统损失代价可以表示为
Dcosta=σ×AL×HC×(PIC×IC+
PCC×CC+PUC×UC),
(1)
其中,下标a指攻击(attack)动作,AL指攻击动作对应的攻击危害度,HC指主机价值度,σ指攻击动作的成功率.
定义4.防御成本(DC).防守方采取相应的防御动作所需付出的代价,即防御的操作代价与负面代价之和,可以表示为
DCd=Ocost+Ncost,
(2)
其中,Ocost为防御动作的操作代价,具体以实际采取防御动作所需要的代价确定;Ncost为防御动作的负面代价,具体以采取的防御动作对系统所造成的负面影响确定.
定义5.攻击成本(AC).攻击方采取攻击动作所需付出的代价,即操作代价与负面代价之和,表示为
ACa=Ocosta+PC,
(3)
这里Ocosta表示攻击动作的操作代价,实际中以攻击方所采取的攻击动作所需付出代价确定,此处列出为便于读者理解,并不作为模型输入;PC指攻击动作的负面代价,也可以说是惩罚代价,参考文献[16]中的PC等于惩罚因子f与攻击危害度AL之积,即:
PC=f×AL.
(4)
定义6.防御效益(DR).防守方采取相应的防御策略后所获得的收益,表示为
DR=Dcosta-DCd,
(5)
这里Dcosta指在攻击(attack)动作的作用下系统的损失代价,DCd则指防守方采取防御(defend)动作的防御成本.
2 基于禁忌搜索方法的防御策略选取
本节在有限博弈中引入禁忌搜索方法,在攻防过程中基于T-SGM模型采用禁忌搜索方法对防御策略进行选取使得防御效益最大化.
现如今禁忌搜索方法应用居多的领域为组合优化[18].通过对禁忌搜索的思想与操作的理解,本文将禁忌搜索方法引入到随机博弈问题中解决防御策略选取问题.禁忌搜索方法与爬山方法最大的不同是禁忌搜索方法是一种动态邻域搜索方法[18].禁忌搜索方法收敛性的确定性使得策略选取对于方法收敛性的要求得到满足[19].
禁忌搜索方法主要通过禁忌表对当前最优策略进行记忆,达到“经验”学习的目的.这里所说的“经验”学习,是对禁忌搜索方法的一种个人理解,禁忌搜索方法中采用了一种灵活的“记忆”技术,对已经进行的优化过程进行记录和选择,指导下一步的搜索方向[14].这一过程类似于人类的“经验”学习,在寻找过程中一个位置找过,就会形成记忆,下次就不会再找,有类似经验记忆在其中,因此本文将其理解为“经验”学习.禁忌搜索方法的关键要素主要有初始解和适配值函数、邻域和移动、禁忌表及其长度以及终止条件[20].
1) 初始解的获取
禁忌搜索方法需要一个初始解以便与不同的解作比较,以获取目前最优解作为下次迭代的初始解.相对于本文来说也就是不同的防御策略,而在实际的网络攻防中,一开始防御方几乎无先验知识,所以本文将随机的防御策略作为初始防御策略,即初始解.
2) 邻域和移动
移动是从当前解产生新解的途径,在本文中就是对一个初始解开始产生一个新的初始解的过程.领域则是从当前解可以进行的所有移动,即从当前解经过一次移动所产生的所有解.
3) 禁忌表及禁忌长度
禁忌表是存放禁忌对象的一个容器,模拟了人类的记忆机制,主要目的是阻止搜索过程中出现循环并且避免陷入局部最优.而禁忌表的长度对方法的计算量以及存储量都有影响:如果禁忌表长度过长会限制搜索区域,并且会增加运算时间;如果禁忌表长度过短,搜索过程就可能陷入死循环.因此禁忌表长度的选择显得尤为重要,本文对于禁忌长度的值的确定是通过实验仿真讨论确定的.
4) 终止条件
禁忌搜索方法需要一个终止准则来结束方法的搜索进程,参考文献[14]设定固定的迭代步数为终止准则为最常用的方法,因此本文也采用这种方法.在通过实验确定禁忌表长度时,会得到每次达到最优时的迭代步数,而禁忌搜索方法由于禁忌表的存在如果达到最优时会收敛,而本文中所取的迭代次数总会远大于达到最优时的迭代次数,不会出现未收敛就强行中断的结果,在保证方法有效性的前提下体现了收敛性.
5) 适配值函数
禁忌方法中需要一个目标函数来对初始解进行评价.本文通过计算每一个防御策略的防御效益对防御策略的好坏进行评价.本文将式(5)定为本文的适配值函数.基于此给出具体防御策略选取方法.

算法1的行①是对模型本身、整个模型的迭代次数以及禁忌表的初始化;行②是从博弈状态图中获取当前时间片的网络状态;行③~是对当前状态防御策略进行“经验”学习的过程以获得最优防御策略,其中行⑤~⑧是对每一条防御策略进行邻域交换寻得该条策略的最佳组合方式,⑨~是对禁忌表中策略的判断并将优选策略添加到禁忌表,并淘汰掉效益低的防御策略.
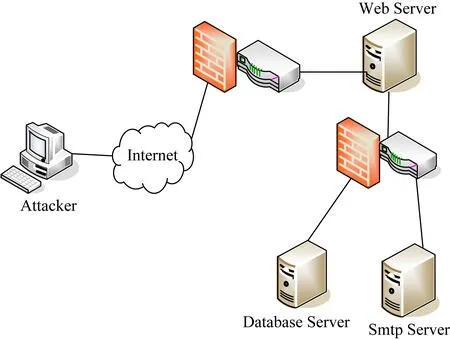
Fig. 3 Experimental network topology图3 实验网络拓扑结构
禁忌搜索方法为了避免陷入局部最优解,采用了一种灵活的“记忆”技术即禁忌表来对目前最优的解进行记录和选择,并指导下一步的搜索方向是一种全局逐步寻优方法[14].因此,禁忌搜索不会陷入局部最优.在本文所提禁忌搜索中,最终所得到的策略即是全局搜索的最优均衡策略,因为每次将所得策略往禁忌表中添加时都会将现在策略与禁忌表中的策略进行比较,使得禁忌表中的策略永远是“best so far”状态,然后只需在禁忌表中选取最优的策略即可获取最优均衡策略,并且禁忌搜索方法的引入会使得对博弈求均衡解变得更加便捷.
3 实验分析
3.1 实验场景
本文的实验环境为如图3所示的典型业务网络系统,攻击方处于外部网络,攻击与防御事件在内部网络发生,防火墙的设置导致普通用户只能访问Web Server,而Web Server可以访问Database Server与Smtp Server,实验网络的脆弱点信息如表1所示:

Table 1 Network Vulnerability Information
针对网络脆弱点信息可列出如表2所示的攻击动作的成功率,攻击危害度以及相对应的惩罚因子,此处的攻击动作的成功率根据历史攻击数据、专家知识所给出.历史攻击数据参考美国麻省理工学院的攻防数据库以及国家安全信息漏洞库(CNNVD),专家知识主要参考文献[8]以及该方向相关文献.

Table 2 Description of Attack Action Related Values
3.2 攻防博弈状态描述
网络状态转移实际上是由攻击者的攻击动作导致,攻击者利用系统弱点实施攻击动作从而获取系统的权限,所以对于每个网络攻击者所拥有的权限是不同的,也就是说攻击者通过不断地获取权限导致网络状态发生变化,此时攻击者在不同时间片所拥有不同权限的网络状态就是攻防博弈的网络状态集.
如果网络遇到入侵时选择切断网络,那么意味着防守方的网络切断了所有的业务来往,这样会使得防守方所需付出代价最大化,鉴于本文最优防御策略的选取,对这种情况不予考虑.本文对于网络状态的考虑是从时间片来考虑的,网络环境复杂导致其网络状态的不确定性,把每个网络状态看作时间片便可得到如图4所示的攻防随机博弈状态图.在状态S1,攻击者在主机上拥有root权限,此时攻击者利用系统脆弱信息1(a1)获取到Web Server的user权限到达状态S2,攻击者也可以直接利用系统脆弱信息2(a2)获取到Web Server的root权限到达状态S3,在状态S2攻击者可以利用脆弱信息3(a3)获取Web Server的root权限到达状态S3,此时攻击者可以借Web Server的root权限利用脆弱信息4,5,6(a4,a5,a6)获取Smtp Server的root权限、Database Server的root权限、Database Server的user权限到达状态S4,S5,S6,到达状态S4后攻击者可以利用Database Server上所存在的脆弱信息8(a8)获取到该服务器上的root权限到达状态S6,在状态S5攻击者还可以利用Database Server上所存在的脆弱信息7(a7)获取到该服务器的root权限到达状态S6.可知,本文的博弈状态集合为S={S1,S2,S3,S4,S5,S6}.

Fig. 4 State chart of attack-defense stochastic game图4 攻防随机博弈状态图
3.3 数据准备
1)N={attacker,Defender}为博弈的参与者,分别指网络攻击的防守方与攻击方.
2) 由3.2节可知本文的博弈状态集合为S={S1,S2,S3,S4,S5,S6}.

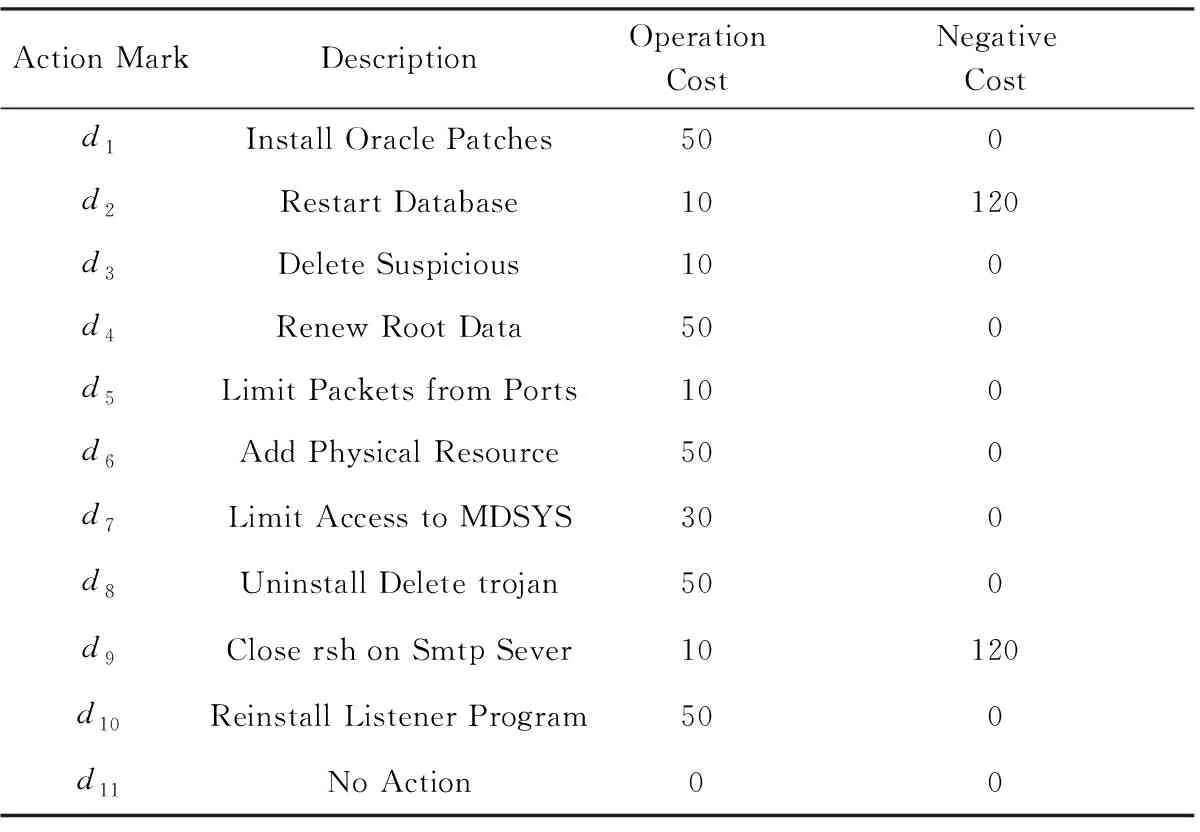
Table 3 Defense Action Description
4) 表4是对不同的禁忌表长度进行实验之后记录的达到结果最优时的迭代步数,并对一个禁忌表长度下的8次记录求平均值.从表4中可以看出,禁忌表长度为10时收敛较快,因此本文取Len_T=10,将禁忌表的长度设为10.

Table 4 Length of Tabu and Corresponding Table of Iteration
6) 将防守方的效益值的初始值设为0,在攻防过程中进行更新.
实际攻防中攻击者的攻击主要以获取服务器权限为主,此时服务器的机密性、安全性以及可用性就会受到损害,在不同的实际场景中对于机密性、安全性以及可用性的安全要求各有不同,其偏重也不相同,因此设置也有所差异.在文献[8]中,作者将三者偏重设为相同,本文根据实验环境的特征对相关参数进行了设置.因此,在本文的实验中我们将服务器的安全属性代价值假设为IC=40,CC=30,UC=30,将属性代价偏重假设为PIC=0.4,PCC=0.3,PUC=0.3.
3.4 实验对比与分析
通过实验得出最优策略以及对应的防御效益值,并将所得结果与经典的防御策略选取方法进行比较,以验证本文方法的先进性.对图4分析可以得到整个博弈过程中状态S3的博弈状态最为复杂,所以本实验对该状态进行分析,对其余的博弈状态的分析方式均与该状态的分析方式相同.
在本节中首先将本文所提方法收敛性与文献[8,11,13]作比较,验证本文方法的收敛性的优劣,结果如图5~7所示.之后就防御效益将本文方法与随机博弈中的文献[8,11]以及演化博弈中的文献[13]的方法作对比,验证本文所提方法的先进性.
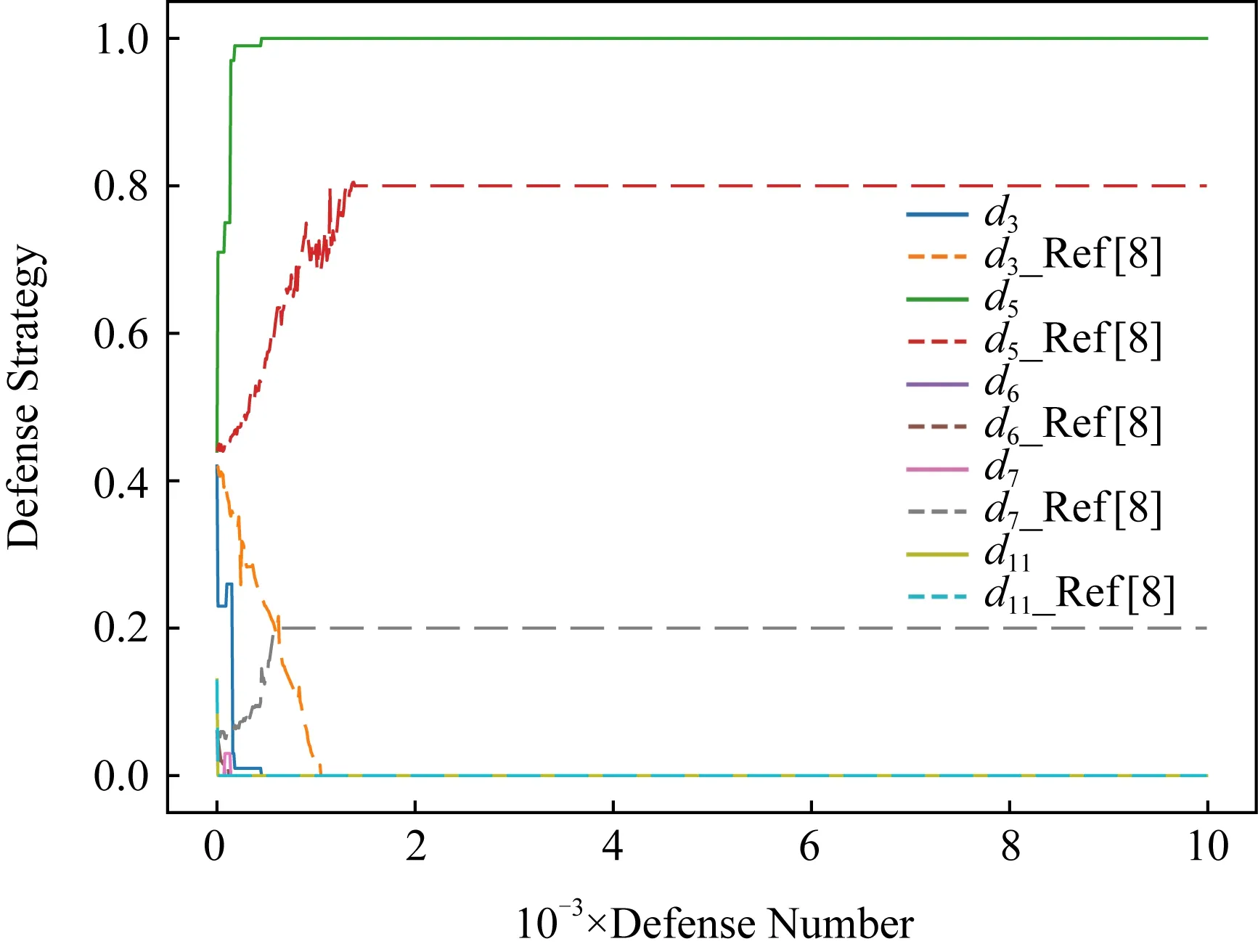
Fig. 5 Comparison of convergence with the method in ref [8]图5 与文献[8]方法收敛性对比

Fig. 6 Comparison of convergence with the method in ref [11]图6 与文献[11]方法收敛性对比

Fig. 7 Comparison of convergence with the method in ref [13] 图7 与文献[13]方法收敛性对比
图5~7中横坐标均为实验迭代次数,纵坐标为采取防御动作的概率,图中实线均为本文方法,虚线为对比方法.从3个图中可以看出,本文方法的收敛性能最好,本文方法在迭代423次时就已经收敛,而文献[8]方法经过1 289次迭代时才会收敛,文献[11]方法达到收敛则是在897次,文献[13]方法经过1 887次迭代收敛,因此就收敛性而言本文方法收敛最快.
采取本文方法所得到的防御策略如图8所示,其中横坐标指实验次数,纵坐标采取防御动作的概率.可以看出本文方法的收益曲线的收敛速度较快,这正是由于禁忌表达到的“经验”学习的功能,使得后一条策略的收益值永远大于前一条策略,也就使得本文的策略变化曲线不会上下波动而是梯度上升,可以看出本文方法本质上是一种爬山方法的扩展,相对于爬山方法跳出了局部搜索可以获取全局最优,具有区别于一般性爬山方法的全局性弱等特征.
采取文献[8]方法所得的防御策略为(P(d3)=0,P(d5)=0.8,P(d6)=0,P(d7)=0.2,P(d11)=0),采取文献[11]方法所得的防御策略为(P(d3)=0,P(d5)=0.9,P(d6)=0,P(d7)=0.1,P(d11)=0),采取文献[13]方法演化稳定均衡后的防御策略为(P(d3)=0,P(d5)=0.8,P(d6)=0,P(d7)=0.2,P(d11)=0),本文对所比较方法的每1 000次收益进行求平均,并对所求平均进行数据可视化得到如图9所示的平均效益变化.这里需要说明,防御操作是应对攻击操作的,无论防御是否能减少或避免防守方的损失,防御动作自身首先是需要付出代价的,因此防御效益值一般均应为负值.

Fig. 8 Defense decision of our method图8 本文方法的防御决策

Fig. 9 Comparison of piecewise average defense benefits图9 分段平均防御效益变化对比
图9中横坐标指实验次数,纵坐标防御收益,本文的实验与3个文献中的方法做了对比.本文的平均效益值与文献[8]方法的平均效益差距明显,文献[8]方法对于策略的选取始终是选择纳什均衡策略,然而当前提条件为实际情况中的有限理性时攻击方基本不会采取纳什均衡策略,此时该方法所得的效益比较低.相比较文献[11]方法,本文方法所获得的收益有高有低,但大多数情况下本文方法所获得的效益比较高,而且本文方法的空间复杂度在相对于文献[11]所提方法来说更低.文献[13]方法虽然考虑了学习因素,但是由于所需参数很难准确量化,导致最终结果与实际存在偏差.可以看出代表本文方法的曲线的收益值基本都大于其他3种方法,本文对于禁忌表的使用不仅在收益值上获得了提高,而且对于方法本身的工作量也得到了降低,对于防御效益较低的策略,禁忌表会拒绝加入,进而不用进行后面的工作,直接对更新的策略进行攻防预演.
本文对整个实验过程的防御效益值求平均与文献[8,11,13]方法做对比,并对实验结果进行数据可视化结果如图10所示:

Fig. 10 Comparison of cumulative average defense benefits图10 累计平均防御效益变化对比
图10中横坐标指实验次数,纵坐标指防御效益,可以看出文献[13]方法的收益要低于其他3种方法,本文方法在前1 000次防御的平均收益要高于文献[8,11]方法,之后与它们的收益基本相同.在防御方还未学习到均衡策略时本文方法高于其他2个文献的方法;当防御方学习到均衡策略时本文的方法与其他2个文献的方法基本持平.
表5中文献[8,11]方法的时间复杂度均通过其文献中所列方法进行分析所得,文献[13]方法是根据公式进行的演化博弈并没有给出伪代码,但依据其公式及过程可知其时间复杂度也是O(n2)数量级的.文献[8,13]中并未对方法的空间复杂度进行相关说明,具体复杂度并不清楚,主要占据空间的因素为防御策略、防御效益,相对于文献[11]方法的立即回报、资格迹、防御策略、当前防御策略以及防御效益明显要小,相对于本文的禁忌表、防御策略、防御收益也明显要小.文献[11]方法的空间复杂度在其文中列出,平均运行时间是将本文与对比文献进行10 000次防御决策求其20次平均值所得.从表5中可以看出,本文相对于文献[11]方法更节省空间,而且运行时间也稍快一些,文献[8,13]方法虽然在时间上快一些,但是其方法的收敛性以及最终防御策略并没有本文好.综上,本文方法更适合进行防御策略选取.

Table 5 Analysis of the Efficiency of Reference Resources
3.5 方法综合比较
本节将本文模型与一些经典的模型进行综合对比,对比结果如表6所示:
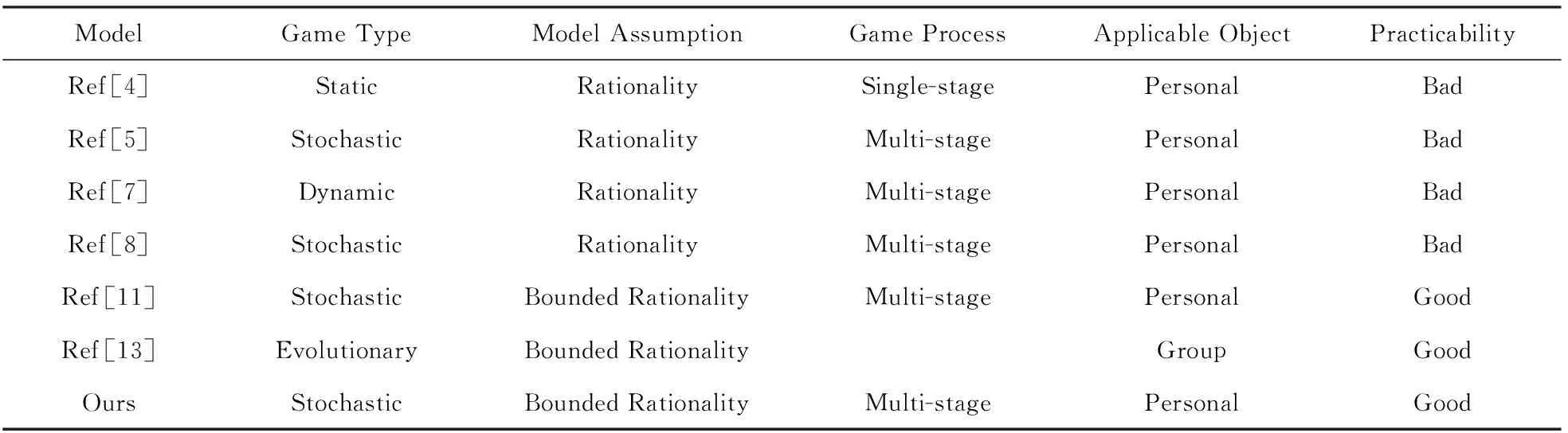
Table 6 Comprehensive Comparison of Typical Models
文献[4-5,7-8]所提方法的假设前提均为完全理性,然而在实际情况中很难会出现均衡情况,以此来对实际网络攻防的防御策略进行抉择不太理想.文献[11,13]和本文方法以有限理性为前提,更符合实际情况,能更好地指导防守方选取最优防御策略.文献[11]的方法引入了资格迹,能很好地指导个体进行实时决策,根据系统的反馈进行学习,加快了学习速率的同时增加了内存和运算的消耗.文献[13]方法对群体的演化进行研究,对群体成员的策略进行调整,不能很好地指导个体进行防御策略选取.根据3.4节中最终收敛所得到的策略可以计算得到相应的防御效益值,具体为:文献[8]方法收敛时的防御效益值为-2 114,文献[11]方法收敛时的防御效益值为-1 812,文献[13]方法收敛时所得到的防御效益值为-2 114,本文方法收敛时所得到的防御效益值为-1 510.相比之下,本文所提的方法是“数据驱动学习”通过禁忌表的反馈数据进行学习,在不消耗更多资源的情况下指导个体防御策略选取,所获得的防御策略与对比文献相比较优.
4 结束语
本文针对当前互联网社会中网络安全威胁的防御策略问题展开分析,根据现实网络攻防特征,在有限理性约束条件下,建立随机博弈模型分析网络攻防过程,并提出了一种基于禁忌搜索方法的防御策略选取方法对模型进行求解,通过构建禁忌随机博弈模型,将攻击成功率与惩罚因子一并纳入进攻防收益量化函数,使得攻防损失价值计算更符合实际网络防护.利用禁忌表的数据计算得出最优的防御策略,使防守方以最低的代价实现最好的网络防守效果,而且该方法中禁忌表的存在大大减少了方法的工作量,提升了方法效率.通过典型网络环境的实验对比分析表明,本文方法是一种对防御策略选取有效的方法.
猜你喜欢
今日农业(2022年16期)2022-09-22
今日农业(2022年14期)2022-09-15
今日农业(2022年13期)2022-09-15
现代电子技术(2022年11期)2022-06-14
甘肃教育(2020年24期)2020-04-13
爱你·心灵读本(2018年6期)2018-09-10
爱你(2018年16期)2018-06-21
海峡姐妹(2017年12期)2018-01-31
语文世界(初中版)(2017年5期)2017-06-22
作文与考试·初中版(2017年12期)2017-04-19
