
面向低维工控网数据集的对抗样本攻击分析
2020-04-21 07:56:58张世琨
计算机研究与发展 2020年4期
周 文 张世琨 丁 勇 陈 曦
1(北京大学软件与微电子学院 北京 100871) 2(北京大学软件工程国家工程研究中心 北京 100871) 3(中国航空油料集团有限公司 北京 100088) 4(鹏城实验室 广东深圳 518000) 5(中国软件测评中心 北京 100048)
云-边计算、人工智能、物联网等新一代信息技术与工业制造技术的加速融合,促使工业控制系统由封闭走向开放、由单机走向互联、由自动化走向智能化;拓展了工业控制系统发展空间但同时扩大了工业控制系统攻击面,工业控制网络面临的传统安全威胁和工控网络特有的安全威胁日益增多.近10年里,工业控制网络经历了各种网络攻击,造成巨大损失.台湾积体电路制造股份有限公司(中文简称:台积电,英文简称:TSMC)2018年8月遭网络攻击,损失1.7亿美元[1];全球知名铝生产商挪威海德鲁公司(Norsk Hydro A.S.)2019年3月遭网络攻击,损失4 000万美元[2];全球知名汽车零部件制造商丰田集团旗下子公司——日本丰田纺织株式会社(TOYOTA BOSHOKU),2019年9月遭遇攻击,损失3 700万美元[3].工业系统的网络攻击正成为一种日趋严重的安全威胁.
入侵检测是一种主动防御措施,能够及时发现目标系统潜在的入侵行为[4].机器学习算法,特别是深度神经网络(deep neural networks, DNNs)学习算法在工控网络系统入侵检测方面展示了卓越的检测能力[5-6].与信息网络不同,工业控制领域常用的监视控制与数据采集系统(supervisory control and data acquisition, SCADA),网络拓扑结构固定,节点之间的事务重复并有规则,这种相对固定的工作模式更加有利于入侵检测系统(intrusion detection system, IDS)检测异常活动.
然而机器学习算法由于本身存在一些缺陷,导致其容易受到由对抗样本引起的白盒或黑盒攻击[7-17].对抗样本是导致学习算法错误分类的数据集,攻击者通过对正常数据集进行不明显的修改来迫使机器学习算法在面对这些对抗样本时表现出不鲁棒行为,对修改过的数据集产生错误分类.对抗样本攻击根据攻击者是否完全掌握机器学习模型(包括模型的结构及参数值、特征集合、训练方法,在某些情况下还包括其训练数据),可以分为白盒和黑盒攻击.攻击者在完全了解机器学习模型的前提下,产生对抗样本,该样本对于该机器学习模型的攻击就称为对抗样本白盒攻击.具有不同架构的2个机器学习算法,其中一个机器学习算法A产生的对抗样本能导致另一个机器学习算法B对该对抗样本以高置信度做出误判,就称机器学习算法B遭受了对抗样本黑盒攻击.
目前关于对抗样本攻击的研究集中在非结构化数据集或者是特征丰富(高维)的结构化数据集.本文的研究对象是工控网络数据集,选取了密西西比大学公开的结构化的低维(特征少)天然气数据集[18],旨在通过构建实验来分析4个常见优化算法SGD[19],RMSProp[20],AdaDelta[21]和Adam[22]与对抗样本攻击力的关系,分析对抗样本对典型机器学习算法的攻击力,并研究对抗训练是否能有效提高深度学习算法抗白盒攻击的能力.
本文的主要贡献有4个方面:
1) 基于DNN模型生成了对抗样本,并调查了典型优化算法(SGD,RMSProp,AdaDelta和Adam)对对抗性样本的生成能力的影响.实验结果显示基于Adam优化算法的DNN模型在对抗样本生成方面,具有高收敛速度和高生成率.
2) 提出了一个新指标来评估典型优化算法与对抗样本白盒攻击能力的关系,并与文献[17]提出的指标进行对比.实验结果显示,基于Adam优化算法的DNN模型产生的对抗样本白盒攻击力最强,可以最大程度地提高结构化数据集的错误分类.
3) 比较典型机器学习算法(决策树、随机森林、支持向量机、AdaBoost、逻辑回归、CNN和RNN)的抗对抗样本黑盒攻击的能力,以及评估不同优化算法产生的对抗样本对各个机器学习算法的攻击能力.实验结果显示,对抗样本对各个典型机器学习算法都具有黑盒攻击能力,RNN对黑盒攻击的防御能力最好,使用Adam优化算法的DNN模型产生的对抗样本的黑盒攻击能力最强,使用AdaDelta优化算法的DNN模型产生的对抗样本的黑盒攻击能力最弱.
4) 通过对抗样本训练,提高深度学习模型对对抗样本白盒攻击的防御能力.
公开文献调研结果显示:这是首次在工控网数据集上调查优化算法对对抗样本的白盒攻击和黑盒攻击能力的影响,也是首次调查典型机器学习算法抗对抗样本黑盒攻击的能力.
1 基础知识和相关工作
本节首先介绍本文涉及到的一些概念知识,然后讨论相关工作.
1.1 基础知识
机器学习模型旨在学习其输入和输出之间的映射.通常,给定输入input由x个特征组成,模型会产生输出output,该输出是y维向量,表示input被分类为每个类别的概率.本文探索典型机器学习模型,包括决策树[23]、随机森林[24]、支持向量机[25]、AdaBoost[26]、逻辑回归[27]、卷积神经网络(convo-lutional neural network, CNN)[28]和循环神经网络(recurrent neural network, RNN)[28].
深度学习过程实则为一个优化算法进行最优化求解的过程,首先求解最小化目标函数(又称为损失函数)ξ(θ)的梯度ξ(θ),然后向负梯度方向更新参数θ,即θt=θt-1-ηξ(θ),其中η为学习率.根据深度学习优化算法梯度与学习率关系,深度学习优化算法可分为2个大类:1)学习率η不受梯度ξ(θ)影响,即η全程不变或者按照一定规则随时间变化,随机梯度下降法(SGD)、带Momentum的SGD和带Nesterov的SGD都属于这一类;2)优化过程中,学习率随着梯度自适应地改变,并尽可能去消除给定的全局学习率的影响,这一类优化器有很多,包括AdaDelta,RMSProp和Adam等.本文考虑4种已经应用于各种深度学习任务并取得出色效果的算法:SGD,RMSProp,AdaDelta和Adam.
1.2 相关工作
Szegedy等人[7]中发现了DNN存在对抗样本,并提出了一种通过盒约束优化方法来可靠检测这些扰动的方法,该方法的有效性取决于内部网络状态.文献[8]中引入了另一种对抗样本生成技术,也就是快速梯度符号方法(fast gradient sign method, FGSM),该方法核心思想是通过梯度来生成攻击噪声,即通过模型的损失函数对样本求导、取符号函数、乘上扰动强度来产生对抗样本.文献[8]给的实例如图1所示,图1(a)是原图,一般的分类模型都会将其分类为熊猫(panda),但是通过添加由神经网络梯度生成的攻击噪声图1(b)后,得到图1(c)的攻击图像,虽然看起来还是熊猫,但是模型却将其分类为长臂猿(gibbon).

Fig. 1 Generating adversarial examples by using FGSM[8]图1 FGSM产生对抗样本[8]
基于FGSM和原始损耗梯度,Rozsa等人[9]提出了一种新的对抗样本生成方法,即热/冷(HC)方法,该方法能够为每个输入有效地生成多个对抗样本.Papernot等人[10]介绍了一种通过利用模型输入和输出之间的映射关系来产生扰动的方法,他们使用前向导数评估模型输出对每个输入的敏感度.此外,Papernot等人[11]提出了面向RNN的对抗性输入序列的方法.以上这些工作都是讨论对抗样本的白盒攻击.与这些产生对抗样本工作不同的是,本文旨在验证优化算法是否会对对抗样本的白盒攻击能力造成影响.
除白盒攻击外,Papernot等人[12]引入了具有替代数据集的黑盒攻击,并提出DNN架构对对抗性样本的可传递性影响是有限的.Gao等人[13]引入了替代训练和线性增强来增强对抗样本黑盒攻击.Shi等人[14]介绍了一种使用Curls迭代和Whey优化的新型对抗样本黑盒攻击,可以使轨迹多样化并压缩噪声.Grosse等人[15]采用基于网络的入侵检测系统数据集NSL-KDD和Android恶意软件检测数据集DREBIN来分析对抗样本.Wang等人[16]研究了对抗样本的黑盒攻击能力.以上这些工作都是针对某一特定优化算法开展的.Wang等人[17]研究了不同优化算法对对抗样本白盒和黑盒攻击能力的影响.文献[17]与本文工作相似,二者之间的区别有4方面:
1) 数据集特征数目不一样,即数据集维数不一样.本文考虑的数据集的特征数目不到20,而文献[17]研究的各个数据集至少有100个特征.
2) 对抗样本生成方法不一样.本文使用FGSM[8],而文献[17]利用JSMA(jacobian-based saliency map approach)[10]来生成对抗样本.
3) 评估对抗样本白盒攻击能力的指标不一样.本文提出用同比损失率,而文献[17]用的是Dvalue,具体定义见2.3节.
4) 本文在对抗样本黑盒攻击能力方面调研了更多机器学习算法的防御能力.
对抗样本生成的基本思路是:在训练模型的过程中,把输入固定,然后调整参数,使得最后结果能对应到相应的输入;生成对抗样本时,将模型固定,通过调整输入,观察在哪个特征方向上只需要微小的扰动即可使得模型给出想要的错分的分类结果.
在关于检测和防御对抗样本的机制方面,Papernot等人[11]介绍了一种防御机制,以减少对抗样本对DNN的影响.Li等人[29]提出了一种通过使用卷积层输出的统计信息来检测对抗样本的方法.Tramèr等人[30]介绍了集成对抗训练方法,通过从其他模型传递的扰动来增加训练数据;实验结果表明,该技术对黑盒攻击具有强大鲁棒性.
生成对抗样本的主要方法有FGSM和JSMA.Szegedy等人[7]首次提出针对深度学习场景下的对抗样本生成算法—BFGS,提出深度神经网络所具有的强大的非线性表达能力和模型的过拟合可能是产生对抗样本原因之一.Goodfellow等人[8]对该问题进行了更深层次的研究,认为高维空间下深度神经网络的线性行为是导致该问题的根本原因,并设计出一种快速有效的对抗样本生成算法—FGSM;该方法通过求出模型对输入的导数,然后用符号函数得到其具体的梯度方向,接着乘以一个步长,把得到的“扰动”加在原来的输入,从而得到FGSM对抗样本.JSMA是由Papernot等人[10]在2016年提出的一种对抗样本生成算法,通过对数据集部分特征进行扰动来生成对抗样本,不仅可以误导神经网络输出错误的分类结果,还可以预设一个目标,让神经网络输出指定的(错误)分类结果.由于本文考虑的数据集的特征少,很难用JSMA生成对抗样本,因此采用FGSM方法通过对每个特征进行扰动来生成对抗样本.
2 对抗样本攻击的分析方法
本节介绍了数据预处理方法,给出了白盒和黑盒攻击实验的设计,描述了评估指标.
2.1 数据集预处理
原始数据通常会出现数据不完整或数据无用问题,数据预处理目的就是纠正这些错误,或者删除存在问题的数据,因此需要对原始数据进行数据预处理.对于本文使用的天然气数据集,一共有274 628条记录,其中有210 528条记录特征并不完整,也就是说76.7%的记录不完整.如果利用少量的23.3%的完整数据记录,通过平均值或其他方法来填充76.7%缺失数据,很难使修补的数据记录能有效表述数据记录真实特点;鉴于此考虑,本文去掉了特征缺失记录.最终获得了64 100条完整的数据记录,这也导致特征更少,原始数据的特征不到30,该数据集一共有七大类攻击类型,即label 2~label 8,每类中还包含了子类,例如MSCI(3)表示该类攻击具体包含3个子类.表1给出了原始数据的特征,其中前4行是预处理后的数据包含的特征.
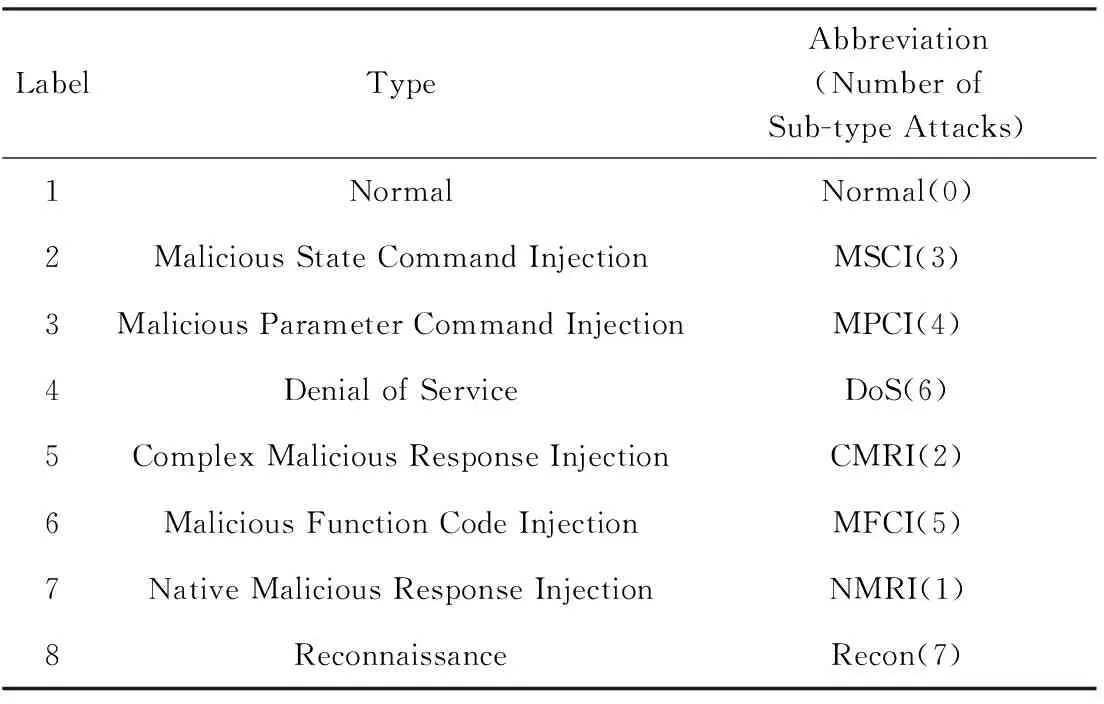
Table 1 Attack Types表1 攻击类型
在天然气数据集中,针对离散特征,我们采用One-hot编码,针对连续特征采用Standard Scaler编码方法.这2种编码方法具体内容为:
1) One-hot编码.回归、分类、聚类等机器学习算法的特征之间距离计算或相似度计算都是在欧氏空间进行.One-hot编码将离散特征的取值扩展到了欧氏空间,离散特征的某个取值对应欧氏空间的某个点.离散型特征使用One-hot编码,能让特征之间的距离计算更加合理.例如,本文采用的天然气数据集中的system mode,统计结果显示该特征一共有3个特征值,分别是0,1,2,那么其One-hot编码分别是:0用[0,0,1]表示,1用[0,1,0]表示,2用[1,0,0]表示.
2) Standard Scaler编码.数据集的标准化是许多机器学习估计器的共同要求:如果单个特征看起来不太像标准正态分布数据(例如均值和单位方差为0的高斯),那么它们可能表现得很差.例如,学习算法的目标函数中使用的许多元素(例如支持向量机的RBF核或线性模型的L1和L2正则化)假设所有特征都以0为中心并且具有相同顺序的方差.如果一个特征具有比其他特征大几个数量级的方差,则它可能主导目标函数,并使估计者无法像预期那样正确地从其他特征中学习.Standard Scaler编码通过计算训练集中样本的相关统计数据,在每个特征上独立地进行居中和缩放,然后存储均值和标准差,以便使用变换方法在以后的数据上使用.具体为
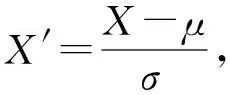
(1)
其中,μ是某一特征的均值,σ是该特征的标准差.最终我们得到了四分类的数据集,如表2所示:
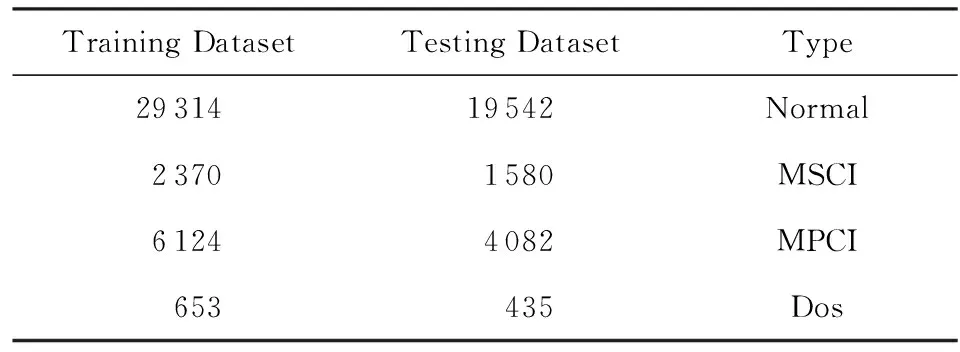
Table 2 Training and Testing Dataset After Pre-processing表2 预处理生成的训练集和测试集
2.2 攻击模型
本文考虑的对抗攻击是通过构造对抗性数据来实现,之后该对抗性数据就如正常数据一样输入机器学习模型并得到欺骗的识别结果.在构造对抗性数据的过程中,根据攻击者是否掌握机器学习模型,可以分为白盒和黑盒攻击.
2.2.1 对抗样本的生成
FGSM和JSMA都可以用来生成对抗样本.FGSM通过将损失函数的导数应用于输入来生成扰动.目前针对结构化数据集产生的对抗样本,都是采用JSMA,这些数据集特征丰富,但是对于特征少的数据集,JSMA很难生成对抗样本,所以我们采用FGSM来合成对抗样本.图2给出了天然气数据集的对抗样本生成流程.

Fig. 2 Generating adversarial sample of Gas dataset图2 天然气数据集的对抗样本生成
本文采用SGD,RMSProp,AdaDelta和Adam这4种优化算法具有3个隐藏层的深度神经网络DNN模型来生成对抗样本.分别用SGD模型、RMSProp模型、AdaDelta模型和Adam模型来表示这4种优化算法下的DNN模型,相应的对抗样本分别表示成SGD对抗样本、RMSProp对抗样本、AdaDelta对抗样本和Adam对抗样本.这些模型除了要使用的优化算法和学习率不同外,其他超参数都相同.学习率是优化算法的一部分,并且不同的优化算法具有不同的最优学习率,以帮助其快速更新模型的参数.因此,我们为每个优化算法调整最佳学习率,以便基于该优化算法的模型可以最快收敛并达到最佳性能.
4个模型中的3个隐藏层依次是256,512,128个节点,选择ReLU作为激活函数,以确保模型的非线性;采用比率0.5法对模型进行正则化并防止过拟合.输入维和输出维对应于每个预处理数据集.实验将epoch设置为15,以调查在不同优化算法下每种轮数下的对抗性样本生成指标的变化,从而获得最适合对抗性样本生成的模型.
2.2.2 白盒攻击
白盒攻击要求攻击者能够获知目标模型使用的算法,以及算法所使用的参数.在白盒攻击中,首先利用原样本训练集对2.2.1节提到的4个模型(SGD模型、RMSProp模型、AdaDelta模型和Adam模型)进行训练,从而获得各自最适合原样本测试集的模型,然后利用这些模型去测试2.2.1节生成的相应的对抗样本,从而评估优化算法与对抗样本白盒攻击能力的关系.
2.2.3 黑盒攻击
黑盒攻击指攻击者利用对抗性样本的可传递性对目标模型实施攻击,攻击者并不知道目标模型所使用的算法和参数.本文选择决策树、随机森林和线性支持向量机、AdaBoost、逻辑回归、CNN和RNN来评估对抗样本针对典型机器学习模型和深度学习模型的跨模型攻击能力.构建的CNN层是conv16-conv32-full32,convN表示具有N个过滤器的卷积层,而fullN表示具有N个节点的完全连接层.RNN层为LSTM30-LSTM60-full32,其中LSTMN表示具有N个单位的LSTM层.这7个机器学习模型都先在原样本训练集经过调试,能够对原样本测试集有效进行分类;然后对这些目标模型分别注入对抗样本,来评估对抗样本黑盒攻击能力以及评估各机器学习模型的抗黑盒攻击能力.
2.3 评估指标
在评估优化算法对对抗样本生成的影响方面,采用对抗性样本的生成率来评估对抗性样本生成的有效性:

(2)
如2.2节所述,本文将所有判别分为目标判别和非目标判别,这是一个二分类问题,可以采用混淆矩阵及其派生指标来评估黑盒攻击的性能.表3给出了混淆矩阵的定义.表4给出了分类模型的评估指标计算公式,精准率(Precision)表示模型预测为正类的数据中,正样本所占的比例;召回率(Recall)表示真实结果为正类的数据中,正样本所占的比例;假正例率(FPR)是指真实结果为负类的数据中,被错误分到正样本类别中真实的负样本所占的比例;F1-score综合考虑了精准率和召回率两个指标;准确率(ACC)是指真实结果占所有样本的比例.

Table 3 The Confusion Matrix表3 混淆矩阵

Table 4 The Calculation Formula for Evaluation Index of Binary Classification Model
在白盒攻击方面,采用同比损失率来评估对抗样本的白盒攻击能力,同比损失率可计算为

(3)
其中,ACC原样本表示在原样本测试集的ACC值,ACC恶意样本代表对抗样本数据集下的测试的ACC值.同比损失率大,则白盒攻击能力强.需要指出文献[17]定义了Dvalue=ACC原样本-ACC恶意样本来评估对抗样本的白盒攻击能力,文献[17]认为Dvalue大,则白盒攻击能力强.
3 实验结果与分析
本节首先介绍生成的对抗样本的结果以及对抗样本白盒攻击结果;然后给出对抗性样本黑盒攻击实验结果;最后给出对抗训练的实验结果.
实验测试环境为:Intel CoreTMi7-6700 CPU核心频率3.4 GHz、内存16 GB、实验用的软件为Tenserflow 2.0版.
3.1 白盒攻击结果分析
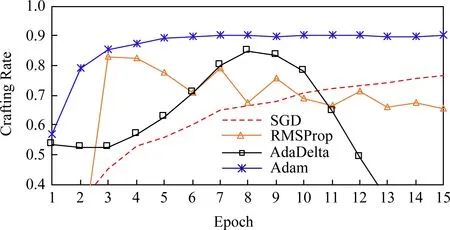
Fig. 3 Crafting rate of Gas dataset图3 天然气数据集的对抗样本生成率
本节介绍了DNN模型分别在4个优化算法下生成对抗性样本的结果,分别用SGD样本、RMSProp样本、Adam样本和AdaDelta样本表示由SGD模型、RMSProp模型、AdaDelta模型和Adam模型生成的对抗样本.图3给出了各模型对抗性样本的生成率,可以观测到Adam样本收敛速度最快,RMSProp样本和AdaDelta样本的曲线波动很大;AdaDelta样本生成率先增加后降低,而其他样本生成率曲线趋向稳定.总之,生成率结果与文献[17]结果截然相反.
图4给出了原样本训练集的DNN在原样本测试集的ACC值.我们观测到Adam模型收敛速度与RMSProp最接近,RMSProp比Adam略好,比其他模型都收敛快,而且ACC结果最好;收敛速度最慢的是AdaDelta模型,而且ACC最差.

Fig. 4 ACC of Gas dataset图4 天然气数据集的原样本的ACC

Fig. 5 Normalized Dvalue of Gas dataset图5 天然气数据集的同比损失率
图5和图6分别给出了天然气数据集的同比损失率和Dvalue.这2个指标旨在反映对抗样本白盒攻击力,我们可以观测到,无论哪个指标都显示Adam样本的白盒攻击能力最强,随后分别是RMSProp样本、SGD样本和AdaDelta样本.因此,仅考虑Dvalue,Adam优化算法是在结构化数据集上生成对抗性样本的最佳选择.同时我们也发现如果使用同比损失率,SGD样本的白盒攻击能力比RMSProp样本攻击能力弱;但是如果使用Dvalue,当轮数大于12以后,SGD样本的白盒攻击能力比RMSProp样本攻击能力强.需要指出的是,在本文数据集里,这2个指标的结果差别不大,但是其他数据集却得出不同结论.例如DREBIN[15 ],图7给出了采用同比损失率计算的结果,我们观察到SGD样本白盒攻击力最强,而且远远超出其他样本;图8给出了文献[17]在DREBIN数据集的Dvalue,结果显示Adam样本的白盒攻击力在各种迭代轮数下最强或者和其他样本一样.其实同比损失率可以看作是归一化的Dvalue,用于对比对抗样本白盒攻击能力更有意义.
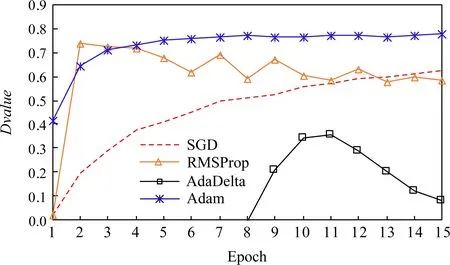
Fig. 6 Dvalue of Gas dataset图6 天然气数据集的Dvalue
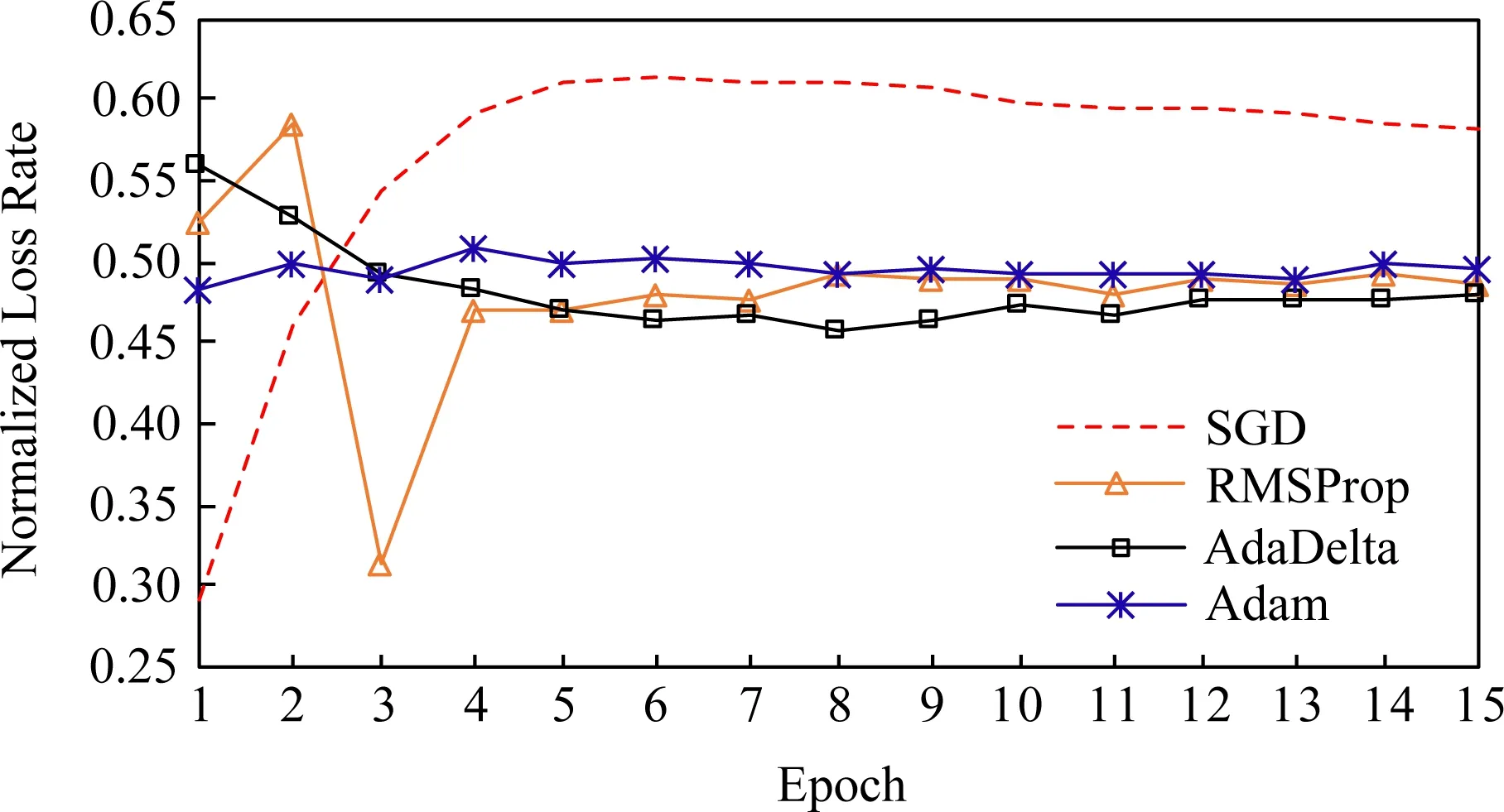
Fig. 7 Normalized Dvalue of DREBIN dataset图7 DREBIN数据集的同比损失率
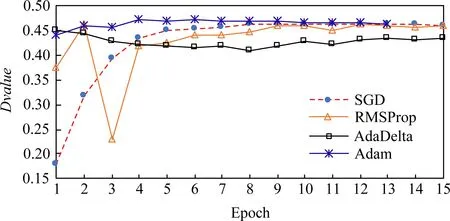
Fig. 8 Dvalue of DREBIN dataset图8 DREBIN数据集的Dvalue
3.2 黑盒攻击结果分析
表5给出了各个机器学习算法在原样本、SGD样本、RMSProp样本、Adam样本和AdaDelta样本下进行测试而产生的各个指标值的结果,包括准确率、精准率、召回率、F1-score和AUC(ROC曲线的面积).我们观察到:
1) 所有对抗样本对典型机器学习算法和卷积神经网络学习算法都具有攻击性;相比之下,循环神经网络学习算法却表现出很好的抗各类对抗样本黑盒攻击的能力.
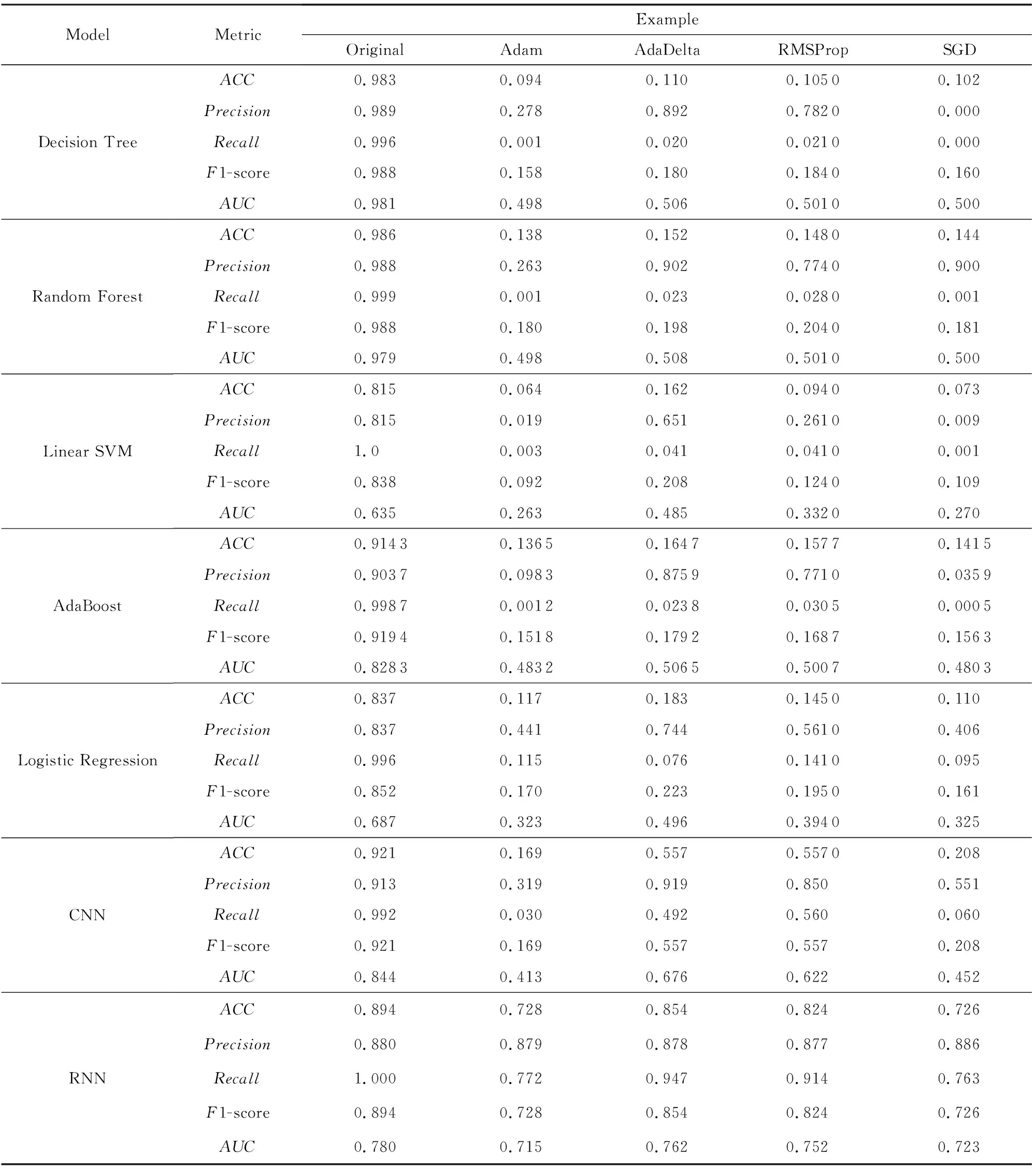
Table 5 Comparison of Machine Learning Algorithms in Resisting Adversarial Example Black-Box Attacks表5 机器学习算法抗对抗样本黑盒攻击的能力比较
2) AdaDelta样本在4种对抗样本中的黑盒攻击能力最弱,Adam样本的黑盒攻击能力最强,这2点与在白盒攻击实验中的结果一致.
3.3 对抗样本训练
表6给出了对抗样本训练对DNN防御对抗样本白盒攻击的能力的影响,采用了Adam优化算法.原样本训练的DNN模型对原样本测试集进行测试的结果为92.2%,而在对抗样本测试集的结果为13.8%.对抗样本训练的DNN模型对原样本测试集进行测试的结果为90.2%,比原样本训练的DNN模型的ACC结果小;而在对抗样本测试集的结果为87%,比原样本训练的DNN模型的ACC结果有巨大提升,说明对抗训练确实提高深度学习模型的抗攻击能力.
Table 6 Effect of Adversarial Example Training on the DNN Capability in Resisting White-Box Attacks
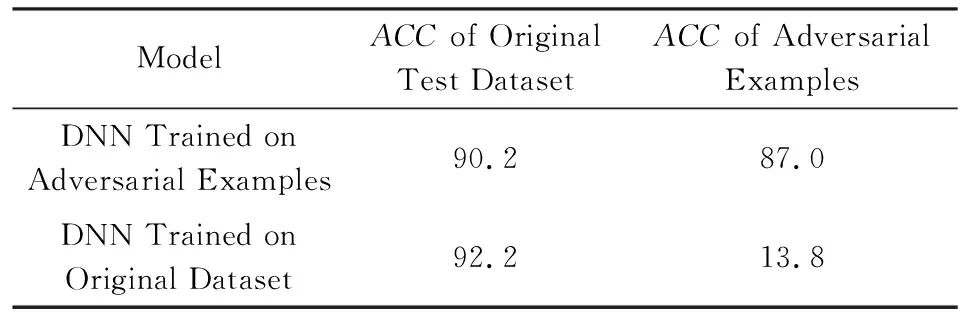
表6 对抗样本训练对对抗白盒攻击能力的影响 %
4 总结与未来工作
工业控制系统是关系国家安全的重要基础设施的组成部分,入侵检测机制可以降低或消除各种威胁给工控系统带来的危害.随着机器学习算法在工控系统入侵检测中的日益推广,机器学习算法自身的安全问题也越来越受到关注.本文针对一个公开的低维天然气工控网数据集,通过构建实验来研究对抗样本的白盒攻击和黑盒攻击力.实验结果显示低维工控网络数据集下的对抗样本攻击特点与其他非工控网络数据集的实验结果有差别.实验结论为:
1) Adam模型能够高效并快速生成对抗样本;
2) Adam模型生成的对抗样本白盒攻击能力最强,AdaDelta模型生成的对抗样本白盒攻击能力最弱;
3) 对抗样本对各个典型机器学习算法具有黑盒攻击能力,其中RNN对黑盒攻击的抗击能力最好;
4) 对抗样本训练能够提高深度学习模型防御对抗样本白盒攻击的能力.
需要指出的是,本文只探讨了提高深度学习模型的抗白盒攻击的能力,未来工作之一是研究如何提高深度学习算法抗黑盒攻击的能力.此外,我们将在更多的工控网数据集上检测我们的实验结论,并分析这些实验现象的潜在机理.
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29 03:15:16
网络安全与数据管理(2022年3期)2022-05-23 13:26:34
通信学报(2021年2期)2021-03-09 08:55:32
小学生学习指导(小军迷联盟)(2019年10期)2019-09-24 09:02:38
小学生学习指导·小军迷联盟(2019年10期)2019-09-10 07:22:44
大科技·百科新说(2018年9期)2018-12-01 10:15:54
通信世界(2018年29期)2018-11-21 06:34:44
电测与仪表(2014年3期)2014-04-04 09:08:08
校园足球(2010年8期)2010-01-24 08:54:36
