
基于MobileNet的恶意软件家族分类模型
2020-04-20 05:03曾娅琴张琳琳张若楠
计算机工程 2020年4期
曾娅琴,张琳琳,张若楠,杨 波
(新疆大学 a.软件学院; b.网络空间安全学院; c.信息科学与工程学院,乌鲁木齐 830046)
0 概述
自动化代码生成工具可以迅速生成大量的恶意代码变体,这对互联网的安全构成了极大的威胁。根据瑞星公司2019年中国网络安全报告统计,2018年共截获病毒样本总量多达7 786万个,病毒感染次数11.25亿次,病毒总体数量比去年同期上涨55.63%。因此,如何对大量的恶意软件进行检测和分类已成为恶意代码分析的挑战之一。
常用的恶意代码分析方法有静态分析和动态分析2种。静态分析是通过提取源代码中的操作码[1-2]、API调用[3]和函数调用[4]等信息来分析软件的执行逻辑,从而实现对恶意代码的检测和分类。这种方法可以对代码进行详尽的细粒度分析,快速地捕获语法和语义信息,从而能够有效地识别出已知的恶意代码。但此方法很容易受到代码混淆和加密技术的干扰,无法检测出未知的恶意代码及其变体。动态分析方法是针对静态方法存在的问题提出的,其通常在虚拟环境中执行样本来分析函数调用[5]、控制流信息[6]、文件操作和注册表修改记录[7]等行为信息。动态分析方法需要执行恶意代码,能够有效地识别和分类恶意代码,但在恶意代码的运行过程中有可能对执行恶意代码的系统产生危害。静态分析和动态分析都有各自的优点和缺点,但考虑到动态分析所需的时间和资源,静态分析更有利于分析呈指数爆炸性增长的恶意软件及其变体。
近年来,基于可视化的方法[8-10]被用于恶意软件的检测和分类。文献[8]通过结合恶意代码逆向分析与可视化,将“.text”段函数块的操作码序列SimHash值可视化,提高了恶意代码可视化的效率和恶意软件分类准确率。文献[9]为了获得比全局特征更灵活和强大的特征描述符,采用局部特征,如局部二值模式和密集尺度不变特征变换,通过将它们分组成块并使用新的视觉词袋模型来获得特征描述符。文献[10]通过结合图像分析技术与恶意代码变种检测技术,将恶意代码映射为无压缩灰阶图片,使用灰阶共生矩阵(GLCM)算法提取纹理指纹特征,采用加权综合多分段纹理指纹相似性匹配方法检测恶意代码变种和未知恶意代码。上述研究证明了基于可视化的恶意软件检测方法不但能够有效地提高恶意软件的检测能力,而且能够检测出恶意软件的变体。因此,本文将恶意软件可视化为灰度图,通过纹理特征来表示同一家族中的恶意软件在代码结构上的相似性。
随着人工智能的发展,基于可视化的方法大多结合支持向量机(SVM)[11-12]、K最近邻(KNN)[13]、随机森林(RF)[14-15]等机器学习和卷积神经网络(CNN)[16-19]、栈式自编码(SAE)[20]等深度学习的方法。基于机器学习的方法需要依靠人工特征工程,特征提取过程耗时又费力。与机器学习方法相比,深度学习方法不但能够自动提取特征,而且能够提高恶意软件的分类能力。例如文献[18]的方法比SVM、KNN的分类准确率高,文献[20]的方法分类准确率比RF提高了2.472%,比SVM提高了1.235%。但随着CNN的层数越来越深,网络越来越复杂,恶意软件检测过程中的参数量和计算量也逐渐增多。例如在文献[16]中,随着GoogleNet和ResNet的网络加深,计算量不断增加,资源消耗也不断增加,运行时间也随之增加。
为了解决CNN网络中参数量过多和计算量过大的问题,本文构建一种基于可视化方法的轻量级CNN的恶意软件家族分类模型。
1 相关工作
基于MobileNet v2的恶意软件家族分类模型以恶意软件的纹理特征作为分析对象。首先,需要将恶意软件进行反汇编,生成反汇编.ASM文件;其次,利用.ASM文件将恶意软件可视化,使恶意代码以灰度图的方式展示出来,以此表示恶意软件家族在代码结构上的相似性;再次,采用MobileNet v2构建深度学习模型,利用预处理的恶意软件灰度图数据作为模型的输入,训练模型,自动提取灰度图的纹理特征;最终,利用Softmax分类器进行调整,通过对恶意代码纹理进行特征筛选,将恶意软件划分到所属的家族中,完成分类。本文模型工作原理如图1所示。

图1 本文模型整体技术路线
1.1 恶意软件可视化
恶意代码可视化的概念由NATARAJ等人[21]于2011年提出的,他们将恶意代码的二进制文件转换成灰度图像,再结合GIST特征来进行聚类。由于采用可视化的思维,其难度不受恶意软件数量的影响,这极大地提高了处理效率。
本文采用纹理特征作为研究对象,研究基于纹理的恶意软件家族分类方法。因此,需要将恶意转件可视化为灰度图,其具体步骤如下:
步骤1以二进制的形式读取样本中任意一个经过反编译形成的.ASM文件,每读取8 bit作为一个基本单元,并执行后续步骤。
步骤2将该基本单元中的二进制序列转换为一个无符号的十进制整数,该数值范围为0~255,然后将该值映射为图像中的任意一个像素的灰阶值(0表示黑色,255表示白色)。
步骤3将步骤2中灰阶值组成的数组转换为一个固定宽度的二维矩阵。
重复上述步骤,直到文件全部读取完毕。恶意软件可视化的流程如图2所示。

图2 恶意软件可视化流程
在上述步骤生成的灰度图基础上,利用纹理特征筛选策略选择出有效的纹理特征。本文通过轻量级的CNN模型自动进行特征的提取、筛选和描述。
1.2 MobileNet v2模型
相对于DBN、SAE方法,CNN的优点是通过感受野和权值共享来减少网络训练过程的参数。但是随着CNN网络层数不断的增多,参数量也随之增加,从而增加了网络运行过程的计算量与资源开销。本文采用MobileNet v2模型[22]对恶意软件进行特征提取和分类,其原因是MobileNet v2采用深度可分离卷积结构,不但能够通过自学习机制自动提取纹理特征,而且能够在保持类似精度的条件下显著地减少模型参数和计算量。
MobileNet v2是在MobileNet v1[23]的基本概念上构建的,它将MobileNet v1和残差网络ResNet的残差单元结合起来,用深度可分离卷积层代替残差单元的瓶颈层。深度可分离卷积是许多高效神经网络架构的关键构建块,其基本思想是用分解版本替换完整的卷积运算符,该分解版本将卷积分成2个单独的层,以此来减少运算量以及参数量。第1层是深度卷积层,它通过对每个输入通道应用单个卷积滤波器来执行轻量级滤波。第2层是1×1的点卷积层,该层通过计算输入通道的线性组合来构建新特征。
深度可分离卷积与标准卷积、深度卷积(DW)、点卷积在结构上存在一定的区别,深度可分离卷积运行过程中的计算量也与它们存在差异。在标准卷积中,每个卷积核的通道数与输入数据的通道数相同。若输出图像大小为DF(即卷积核在输入图像上执行的卷积次数),二维卷积核的大小DK,输入数据的通道数为M(即卷积核的通道数),输出数据的通道数N(即卷积核的个数),则标准卷积的计算量为:
DK×DK×M×N×DF×DF
(1)
DW的计算量为:
DK×DK×M×DF×DF
(2)
点卷积的计算量为:
N×M×DF×DF
(3)
而深度可分离卷积的计算量为:
DK×DK×M×DF×DF+N×M×DF×DF
(4)
因此,传统卷积相比于可分离卷积的计算量为:
(5)
由上述公式可看出,深度可分离卷积的计算量少于标准卷积,因此,MobileNet v2可在一定程度上减少模型的资源开销。
直接将深度可分离卷积运用到残差块中,会产生以下问题:
1)深度可分离卷积层提取得到的特征受限于输入的通道数,若是采用以往的residual block,先“压缩”,再通过“卷积提取特征”,那么深度可分离卷积提取到的特征就会很少,而MobileNet v2一开始先“扩张”6倍。 通常residual block里面是先“压缩”,然后“卷积提取特征”,再“扩张”,MobileNet v2就变成了先“扩张”,然后“卷积提取特征”,再“压缩”,因此被称为倒立的残差块(inverted residuals)。
2)当采用倒立的残差块后ReLU会破坏特征,这是因为ReLU对于负的输入,输出全为零,而本来特征就已经被“压缩”,再经过ReLU又会“损失”部分特征。因此,MobileNet v2不采用ReLU,而是采用线性瓶颈层,以达到保护特征的目的。
瓶颈层之间的连接捷径(shortcut)连接的是缩减后的特征映射(feature map)。针对stride=1和stride=2,在块上有稍微不同,主要是为了与shortcut的维度匹配,因此,当stride=2时,不采用shortcut。以上2种架构构成了MobileNet v2的基本结构Bottleneck,具体结构如图3所示。

图3 MobileNet v2的核心结构
标准的MobileNet v2结构如表1所示。

表1 标准MobileNet v2的网络结构
在表1中,每行描述一个或多个相同层的序列,重复n次,同一序列中的所有层具有相同的输出通道数c,每个序列的第一层步长为s,其他层的步长为1,所有空间卷积使用3×3的核。扩展因子t用于调整输入图像的大小,如表2所示。

表2 扩展因子t的应用
Conv2d操作包含卷积和ReLU6,卷积公式如下:

(6)
其中,x(t)和h(t)函数是卷积的变量,p是积分变量,t是使函数h(-p)位移的量,*表示卷积。
在MobileNet v2模型的每一层中均有一个BN层,使网络可以恢复出原始网络所要学习的特征分布情况。
本文将恶意软件的灰度图作为恶意代码分析的对象,选择的纹理特征数量比文献[17]少。因此,为了防止MobileNet v2网络深度过大而引起过拟合的问题,通过多次实验测试,本文在原MobileNet v2模型的基础上去掉原始模型中最后2个Bottleneck层以及与最后1个Bottleneck层相连的Conv2d层,保留了原模型的前14层。为了适应模型的输入数据,将模型中的平均池化操作Avgpool的大小由原来的7×7改为3×3。本文的MobileNet v2的基本结构如图4所示。

图4 本文神经网络模型结构
上述模型将恶意软件灰度图作为输入,输出一组特征映射,然后将所得特征映射输入Softmax分类器,输出一组大小与恶意软件家族数目相同的概率分数,最后选择得分最高的家族作为给定恶意样本的类标签。
1.3 分类
通过本文MobileNet v2模型提取纹理特征后,采用Softmax将各个恶意样本划分到各自的家族中。Softmax模型是逻辑回归模型在多分类问题上的推广,其核心思想是通过估算样本所属类别的概率对多类别样本进行分类。
在Softmax回归中,假设训练集为{(x1,y1),(x2,y2),…,(xm,ym)},标签数据为yi∈{1,2,…,k},则对于一个给定的测试数据xi,其所对应的类别标签yi的概率分布为:
(7)

2 实验结果与分析
2.1 实验数据
本文实验数据取自微软公司发布在Kaggle上的恶意软件分类大赛数据集,其中包含9个恶意软件家族,所有恶意软件去除PE头,分别包含IDA反编译工具得到的“.ASM”文件和16进制表示的“bytes”文件。本文采用“.ASM”文件,共10 868个样本,表3给出了恶意软件家族的分布情况。

表3 恶意代码家族的分布情况
2.2 评价指标
本文为了方便定量分析,统一使用数据集样本数量为10 868,同时使用准确率A来评价模型的性能。
(8)
其中,NTP代表正确分为某一类别的恶意样本数量,NTN代表被正确分为其他类别的恶意样本数量,NP代表某一类恶意样本的量,NN代表其他类别的样本量,四者均由混淆矩阵得出。
2.3 实验结果
2.3.1 模型调优结果与分析
将预处理灰度图数据输入模型,对模型进行训练。在实验中,随机按比例抽取70%数据作为训练集,其余作为测试集。
模型中的学习率lr、迭代次数epoch和批次大小batch_size等参数的设置,都会对最终分类结果造成一定的影响。因此,本文通过调整参数来优化模型,使其能够适应恶意软件的灰度图数据。在实验中,首先保持其他参数为默认值,调整学习率lr。经过实验,随着lr的变化,模型的分类准确率随之发生变化,结果如图5所示。

图5 学习率对分类结果的影响
由图5可知,当lr=0.000 07时,模型的泛化能力最高。在此基础上,保持其参数不变,调整迭代次数epoch,测试其对模型分类性能的影响,结果如图6所示。

图6 迭代次数对分类结果的影响
由图6可知,随着epoch的增加,分类准确率并不会一直提高。这是因为:当epoch少时,模型学习特征的能力不足;当epoch多时,模型出现过拟合的现象。本文取epoch=15。在确定lr和epoch后,本文实验测试了批次大小batch_size对模型分类性能的影响,结果如图7所示。

图7 批次大小对分类结果的影响
由图7可知,随着batch_size的变化,模型的分类能力逐渐变化。当batch_size为10时,模型的分类能力最佳。同时可发现,在不同的参数组合下,特征的表现能力有所不同。经上述实验得到最佳参数,因此,下文实验参数设置为lr=0.000 07,epoch=15,batch_size=10,在此情况下,模型能更好地适应恶意软件样本,其分类性能更佳。
2.3.2 灰度图纹理分类能力
在本实验中,纹理特征的选择对于恶意软件家族分类结果至关重要。因此,选取不同的像素点数目进行准确率对比实验,结果如图8所示。

图8 不同灰度图纹理的模型分类准确率
由图8可知,当灰度图的像素点数目在3 136时,模型的分类性能最佳,并且在3 600和4 096时分类效果相对稳定。从图中还可以看出,当灰度图的像素点数目在2 500时,模型的准确率有一个提高,然后保持稳定,因此,像素点数目在2 500到4 096间包含了恶意代码家族类别的核心信息。
2.3.3 模型整体对比分析
将训练数据与测试数据设置为7∶3的固定比例,验证不同方法对于实验结果的影响。
实验使用MobileNet v2模型与文献[16-18,21]的4种模型进行对比,其中文献[16-18]的模型均采用了微软发布的恶意软件分类竞赛数据集。文献[16]将恶意软件的操作码转为图像,分别分析ResNet和GoogleNet在此图像上的分类效果;文献[17]将恶意软件映射为彩色图像,利用经典的CNN模型对恶意代码进行分类;文献[18]利用了一种敏感哈希方法SimHash来表示操作码的图像,然后利用改进的神经网络模型MCSC对恶意代码进行分类;文献[21]是经典的恶意代码可视化方法,是一种通过提取图像的GIST特征进行聚类的方法。各个模型的精度表现如图9所示。

图9 分类模型的准确率对比
由图9可知,使用纹理特征来表示恶意代码家族的相似性能达到较好的分类结果。而且从上述实验能够看出,在恶意代码分类领域,本文模型能够自动提取恶意代码的纹理特征。实验结果证明:本文模型对恶意代码纹理特征的表达能力更显著,能更准确地分类恶意代码及其变体。
本文通过计算MobileNet v2模型的参数量,并统计其他对比模型的参数量,从侧面反映各个模型的资源消耗情况,实验结果如表4所示。

表4 7种网络模型的参数使用情况
在表4中,层数仅包含卷积层和全连接层,不包含池化层。由表4可知,随着模型层数的增加,模型的参数量逐渐增多,在输入数据相同的情况下,模型的计算量随之增大,从而增加了模型的资源开销。通过对上述数据进行比较,本文模型不仅能提高模型的分类准确率,而且降低了模型运行过程中的资源开销。
为了验证所选可视化图像和MobileNet v2模型对恶意软件分类的有效性,将恶意代码的灰度图作为分析对象,利用机器学习的4个模型RF、SVM、决策树、KNN对恶意代码进行分类,并与本文模型进行对比,结果如图10所示。
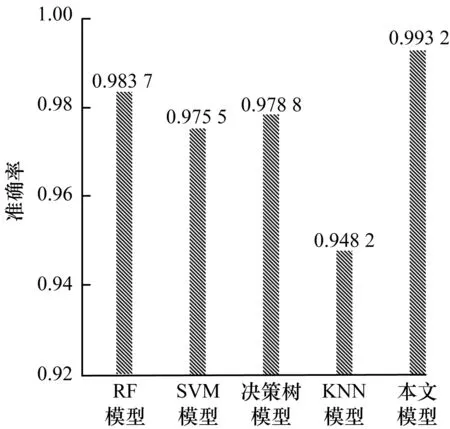
图10 机器学习模型与MobileNet v2的分类结果对比
由图10可知,在采用相同灰度图的情况下,MobileNet v2模型的分类效果更好。实验结果进一步证明,基于轻量级CNN的恶意代码分类模型能够提取恶意代码的特征,提高特征的表达能力,从而提高模型的分类性能。
由上述实验分析可知,MobileNet v2模型在计算量和参数量均较小的情况下,能够自动提取纹理特征并进行恶意软件家族的分类。该模型不受恶意软件数量和类别的影响,能够解决各类恶意代码爆炸式增长而难以分析的问题,为实际应用提供了一种时间和资源消耗较低的恶意软件家族分类方法。
3 结束语
本文结合恶意软件可视化方法和轻量级的CNN模型,提出一种计算量和参数量较少的恶意软件分类模型。利用灰度图像表示同一家族的恶意软件在代码结构上的相似性,构建轻量级的CNN模型MobileNet v2并进行训练。采用自学习机制自动提取恶意软件的纹理特征,利用Softmax分类器将恶意软件样本划分到所属的家族。实验结果表明,该模型具有良好的分类能力,并且时间和资源消耗均较低。下一步将利用大数据分析技术,结合源代码的操作码特征或API特征,以提高本文模型对恶意软件的检测效率和准确率。
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22
北京航空航天大学学报(2022年6期)2022-07-02
师道·教研(2022年1期)2022-03-12
天津医科大学学报(2021年1期)2021-01-26
海洋信息技术与应用(2020年1期)2020-06-11
软件(2020年3期)2020-04-20
传媒评论(2019年4期)2019-07-13
摄影之友(影像视觉)(2018年12期)2019-01-28
Coco薇(2017年8期)2017-08-03
自动化学报(2017年5期)2017-05-14
