
最小类内方差支持向量引导的字典学习
2020-04-20 13:12王晓明
计算机工程 2020年4期
王晓明,徐 涛,冉 彪
(西华大学 a.计算机与软件工程学院; b.机器人研究中心,成都 610039)
0 概述
稀疏表达(Spare Representation,SR)利用超完备的基向量有效表示样本数据,广泛应用于图像分类[1-3]、超分辨率[4]、压缩[5]和去噪[6]等方面。将超完备的基向量称为字典,其中的每一个基向量称为原子。模式分类技术利用数据的鉴别信息,从真实样本数据中学习完备的字典以提高分类效率。此类基于模式分类的字典学习算法被称为鉴别性字典学习(Discriminative Dictionary Learning,DDL)。
DDL利用具有信息鉴别能力的训练样本学习超完备字典以提高编码系数的鉴别性能,在图像分类中的广泛应用使其成为当前研究的热点之一。研究人员现已提出一系列DDL算法,其中的一种字典学习算法旨在利用字典的重构误差进行分类。文献[7]提出结构不一致和共享特性的聚类字典学习算法。文献[8]提出特定类别的子词典与细粒度共享的字典学习算法。这两种字典学习算法结合字典的结构特性,强制性地为字典增加鉴别信息,然而在类别数量巨大的分类任务中不能取得理想的分类结果。另一种字典学习算法通过寻找最优字典提高字典鉴别能力。文献[9]通过学习字典和分类器对原始KSVD算法[10]进行扩展,提出鉴别性KSVD算法(Discriminative KSVD,D-KSVD),提高了字典的鉴别能力。文献[11]在D-KSVD算法的基础上增加一致性类标签限制条件,提出类标签一致KSVD算法(Label Consistent KSVD,LC-KSVD),提高了编码系数的鉴别能力。由于LC-KSVD算法忽略了原子间的相似特征,鉴别性能提高有限,因此文献[12]提出局部特征和类标嵌入约束的字典学习算法(Locality Constrained and Label Embedding Dictionary Learning,LCLE-DL),在一定程度上解决了原子相似性对鉴别性能的影响问题。文献[13]提出有监督的逻辑损失函数字典学习策略。文献[14]阐述了泛化任务驱动字典学习框架。文献[15]通过间隔最大化思想研究字典学习问题,并采用多类损失函数进行字典学习。文献[16]提出Fisher鉴别字典学习算法(Fisher Discrimination Dictionary Learning,FDDL),FDDL兼顾重构误差和编码系数的鉴别能力,采用类别特性策略学习结构化字典,通过对编码系数引入Fisher鉴别准则提高字典鉴别能力,但是FDDL算法在处理多样本的问题中时间开销较大。文献[17]提出的大间隔字典学习算法将SVM的大间隔原理作用于字典训练过程,提高字典的鉴别能力。文献[18]提出支持向量引导的字典学习算法(Support Vector Guided Dictionary Learning,SVGDL),将标准的SVM[19]作为鉴别项用于编码系数向量,在编码系数的更新过程中采用二次合页损失函数计算其加权距离的平方并更新编码系数。通过引入固定参变量证明FDDL算法固定的权值分配策略仅是SVGDL算法的特例,并将范数作为稀疏控制条件,表明其在时间效率和识别率上均优于FDDL算法。
本文基于SVGDL算法的权值分配策略,提出最小类内方差支持向量引导的字典学习算法(Minimum Class Variance Support Vector Guided Dictionary Learning,MCVGDL),将MCVSVM算法作为鉴别项并与协作表达(Collaboration Representation,CR)相结合。MCVSVM是对标准SVM的改进,其最优分类超平面更符合数据特征的空间分布情况,也是对标准SVM最优超平面的修正。实验将MCVGDL算法与SVM、CRC、SRC、KSVD、D-KSVD、LC-KSVD、FDDL和SVGDL算法在多个常用数据集上进行对比。
1 相关工作
1.1 l2范数协作表述理论
鉴于稀疏表达优化l0和l1的时间开销问题,文献[20]提出结合最小二乘和l2范数的协作表达算法。文献[21]进一步分析了协作表达和稀疏表达在分类问题上的工作原理。
(1)

1.2 支持向量引导的字典学习模型
SVGDL[18]是一种改进的鉴别性字典学习模型,其将协作表达式(1)和标准的SVM相结合,通过引入固定参变量,证明了FDDL算法固定分配权值的策略是其自由分配权值的特例。SVGDL算法模型为:
(2)
其中,w是标准SVM的分类超平面,b是对应的偏置,类标签向量y=[y1,y2,…,yn],β是平衡参数,旨在协调l2范数和鉴别项之间的关系,H(S,y,w,b)定义为:
(3)
1.3 最小类内方差支持向量机
SVM[19]是典型的大间隔分类器,广泛应用于模式识别和机器学习中。然而,传统SVM建立的超平面是基于最大间隔原则[14],从而导致该方法仅考虑每类数据边界上的样本点,而没有利用数据的分布信息,因而在一定程度上制约了其泛化能力的进一步提高。针对这一问题,文献[22]提出最小化类内方差支持向量机。MCVSVM可以看作是一种结合SVM和Fisher线性鉴别的分类器,与标准SVM不同,MCVSVM建立的决策超平面既考虑了数据的边界信息,又考虑了数据的分布信息。因此,其不易受到例外样本点和噪音的影响,具有更强的鲁棒性和更好的泛化性能。MCVSVM的定义为:
s.t.yi(wTsi+b)≥1-ξi,i=1,2,…,n
(4)
其中,ξ=[ξ1,ξ2,…,ξn]是松弛向量,θ是惩罚系数,控制着错误分类数据的惩罚程度,θ越大,惩罚程度越大,θ越小,惩罚程度越小,Sω是类内散度矩阵,其定义为:
(5)

s.t.0≤αi≤θ,i=1,2,…,n,αTy=0
(6)

文献[23]将二分类MCVSVM扩展成多分类问题,并取得了优于SVM的分类实验结果。由于MCVSVM兼顾大间隔和数据分布信息,具有更好的鲁棒性和泛化能力。因此,MCVGDL使用MCVSVM对SVGDL算法进行改进。
2 MCVGDL算法
SVGDL算法采用标准SVM[19]作为鉴别项,通过大间隔编码系数引导字典学习,仅考虑每类编码系数边界上的样本点表示系数样本点,而没有利用编码系数的空间分布信息。与SVGDL算法不同,MCVGDL算法采用MCVSVM[22-23]作为编码系数的鉴别性条件,同时兼顾边界上的编码系数及其空间分布信息。
2.1 MCVGDL算法的目标函数
受MCVSVM[22-23]和SVGDL[18]启发,本文使用MCVSVM替换式(2)中SVGDL算法的鉴别条件,并借鉴文献[18]的一对多策略建立如式(7)所示的MCVGDL算法目标优化函数:
(7)

2.2 MCVGDL算法的求解
借鉴文献[18]的求解方法,虽然MCVGDL算法并不是联合的凸优化问题,但固定其中的多个变量后,式(7)转化为可交替优化的凸优化问题。因此,采用交替优化策略分别更新字典D、编码系数矩阵S和MCVSVM分类器{w,b}。
2.2.1 编码系数S更新
借鉴文献[18,24]的更新方法,固定字典D、w、b和拉普拉斯矩阵Lc。更新每一个si,目标函数式(7)转换为如下方式求解:
(8)

(9)
si=A-1B
(10)
其中,I是单位矩阵。

(11)
(12)
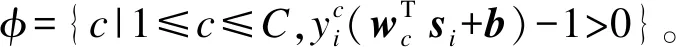
2.2.2 字典D更新
借鉴文献[25]的更新方法,固定编码系数S、w、b和拉普拉斯矩阵Lc。目标函数式(7)转变为求解协作表达字典D的更新过程。更新的D的目标函数为:
(13)
该目标函数可以通过文献[25]的拉格朗日对偶问题求得,给出J(D)的Lagrange函数为:
J(D,λ)=Tr[(X-DS)T(X-DS)]+
s.t.λj>0,∀j∈{1,2,…,K}
(14)
其中,λ是Lagrange乘子,可求得其对偶问题为:

Tr(DTD-DST(SST+Λ)-1(DST)T-cΛ)
s.t.λj>0,∀j
(15)
其中,Λ=diag(λ),通过求其对偶问题并将所得最优解λ代入DT=(SST+Λ)-1(DST)T,可得字典D的最优解。
2.2.3 MCVSVM的W、b和L更新
固定字典D和编码系数S,式(7)的优化问题转变为求解多类MCVSVM的二次规划问题。本文使用二范数的MCVSVM作为模型式(7)的鉴别条件,同时采用一对多的策略训练多类模型。二范数的MCVSVM定义如下:
s.t.yi(wTsi+b)≥1-ξi,i=1,2,…,n
(16)


综合以上更新过程,MCVGDL算法具体步骤如下:
输出训练后的字典D、W、b和拉普拉斯矩阵L
1.T=0
2.For i=1 to n
使用式(10)更新si;
else
使用式(12)更新si
end For
3.借鉴分类字典学习算法[25]更新字典D;
4.借鉴最小类内方差支持向量机[22]求解二次规划问题的方法,更新W、b和拉普拉斯矩阵L;
5.若相邻两次迭代后目标函数值之差小于收敛阈值Delta,则迭代终止,否则返回步骤2继续执行,直到收敛或达到最大迭代次数T终止;
6.End
2.3 分类方法

(17)
3 实验结果与分析
为保证实验公平性,本文所有实验均基于Intel i3-4130 @3.40 GHz的处理器,4 GB内存空间,64位Windows 7旗舰版系统软件和MATLAB R2013b版本应用软件。
MCVGDL算法模型涉及3个主要参数,分别是平衡参数α、β和MCVSVM惩罚系数θ。实验中为防止过拟合的产生,采用交叉验证方式自由选取参数,并且需综合多因素以获得良好的模型性能。对于实验中涉及的人脸识别数据集和物体识别数据集的参数设置,将在对应的实验与数据集中给出模型的参数设置。
由于MCVGDL算法是基于协作表达和SVM结合的算法,同时针对SVGDL使用MCVSVM进行改进,因此将基于协作表达的CRC分类算法[20]、基于稀疏表达的SRC分类算法[26]、SVM算法[19]及SVGDL算法[18]在USPS[27]手写数字数据集上进行实验对比。同时,与KSVD[10]、D-KSVD[9]、LC-KSVD[11]、LCLE-DL[12]、FDDL[16]、BDLRR[28]等学习算法在人脸识别(Extended Yale B[29]、Yale[30]、ORL[31]和AR[32])和物体识别(COIL20[33]、COIL100[34]和Caltech101[35])数据集上进行实验对比。LC-KSVD2算法是对LC-KSVD1算法的改进且效果更好,本文中的LC-KSVD特指LC-KSVD2。另外,对于人脸识别数据集还增加了基于稀疏表示和图像预处理的ASF-SRC算法[36]进行对比。实验部分给出MCVGDL和其他8种对比算法在Extended Yale B、Yale、ORL、COIL20、COIL100和Caltech101数据集上的实验结果,比较不同训练样本条件下的识别准确率。
由于字典大小(即字典所包含原子的个数)对识别率存在影响,因此为说明字典原子个数K对识别率的影响,本文将分别在Yale B、Yale和ORL 3个人脸数据集上随机选择样本并固定训练样本,同时调整KSVD、D-KSVD、LC-KSVD、FDDL、SVGDL和MCVGDL算法的字典原子个数,给出调整字典原子个数后的识别率变化曲线,通过其平均识别率的变化曲线对字典原子个数进行具体分析。
3.1 手写数字识别
美国邮政的USPS[27]手写数字数据集收集了9 298张0~9数据的数字图像,每一张图像大小为16像素×16像素。虽然该手写数字数据集中的类别较少,但是简单的笔画构成增加了识别难度,使得同类数字的个体特征差异较大,字典学习方法能有效学习其固有特征。对其分别选择7 291张图像作为训练数据,剩余的2 007张作为测试数据。MCVGDL参数设置为α=1e-3、β=1e-7和θ=10,并固定字典原子个数。由于MCVGDL算法采用二范数的正则项作为(协作稀疏表达)稀疏控制条件,使用SVM的大间隔分类理论和Fisher线性鉴别分析作为模型的鉴别性条件引导字典学习,进一步探究了结合SVM的鉴别字典学习方法与基于协作表示和稀疏表示的分类方法的鉴别性能和优势。因此,在USPS手写数据集上将MCVGDL和CRC、SRC、SVM、SVGDL算法进行对比。表1是USPS手写数字的平均识别率,相比于CRC、SRC、SVM算法,本文算法提高了2%~3%,相比于SVGDL算法提高了1%~2%,说明将SVM作为基于协作表达或者基于稀疏表达的字典学习的鉴别条件,可以增强字典模型的鉴别能力,考虑编码向量的空间分布信息可以有效提高模型的分类性能,在一定程度上增强了模型的泛化性能,使得模型分类能力得到进一步提升。

表1 USPS手写数字的平均识别率
3.2 人脸识别
3.2.1 Extended Yale B数据集上的实验结果
由耶鲁大学计算视觉与控制中心创建的Extend Yale B人脸数据库中共有38个类别,包含不同光照条件和面部表情的2 414张正脸图像。每一个人有64张192像素×168像素的图像。为保证实验公平性,采用大小为32像素×32像素的图像作为实验数据,并随机为每一类别选择数量为5、10、20、30的图像作为训练数据,剩余部分作为测试数据。MCVGDL的参数设置为α=2e-3、β=1e-7和θ=20,固定字典原子个数K为190、380、760、1 140,实验结果如表2所示。

表2 Extended Yale B数据集上的识别率和标准差
3.2.2 Yale数据集上的实验结果
由耶鲁大学计算视觉与控制中心创建的Yale人脸数据集中共有15个类别的165张图像。每一个人具有11张不同光照、姿态、表情的面部图像。为保证实验公平性,采用大小为32像素×32像素的图像作为训练数据和测试数据,并随机为每一类别选择数量为2、4、6、8的图像作为训练集,剩余部分作为测试数据。MCVGDL的参数设置为α=2e-3、β=1e-7和θ=20,固定字典原子个数K为30、60、90、120,实验结果如表3所示。

表3 Yale数据集上的识别率和标准差
3.2.3 ORL数据集上的实验结果
由剑桥大学AT&T实验室创建的ORL人脸数据集包含40个人的400张人脸图像,每一个类别有10张图像。该数据集包含每一个人不同时期、视角、表情和面部细节的图像。为保证实验公平性,所有实验采用大小为32像素×32像素的图像作为训练数据,并随机为每一类别选择数量为2、4、6、8的图像作为训练数据,剩余部分作为测试数据。MCVGDL的参数设置为α=2e-3、β=1e-7和θ=20,固定字典原子个数K为80、160、240、320,实验结果如表4所示。

表4 ORL数据集上的识别率和标准差
3.2.4 AR数据集上的实验结果
AR人脸数据集包含126个类别且超过4 000张的人脸图像。与Extended Yale B不同的是,其具有更加丰富的面部表情(微笑、生气和尖叫等)、光照变化和面部遮挡等。对于AR人脸集,分别选择50个男性和50个女性共2 600张图像(每人26张)作为实验数据,并随机为每一类别选择数量为3、5、7的图像作为训练数据,剩余部分作为测试数据,参数设置为α=2e-3、β=1e-7和θ=20,固定字典原子个数K为300、500、700,实验结果如表5所示。

表5 AR数据集上的识别率和标准差
3.3 物体识别
3.3.1 COIL20和COIL100数据集上的实验结果
由哥伦比亚大学创建的COIL20图像数据集包含20个类别不同物体从不同角度每隔5秒拍摄的1 440张图像,每一类别有72张图像,其大小为32像素×32像素。实验中随机为每一类别选择数量为5、10、20、30的图像作为训练数据,剩余部分作为测试数据。图1是COIL20数据集中的部分样本图像。

图1 COIL20数据集示例图像
MCVGDL模型的参数设置为α=2e-3、β=1e-7和θ=10,固定字典原子个数K为100、200、400、600,实验结果如表6所示。

表6 COIL20数据集上的识别率和标准差
COIL100数据集包含了100个类别从不同角度拍摄的7 200张图像,模型参数设置与COIL20一致,选择数量为5、10、15、20的图像作为训练集,剩余部分作为测试数据,固定字典原子个数K为500、1 000、1 500、2 000,实验结果如表7所示。

表7 COIL100数据集上的识别率和标准差
3.3.2 Caltech101数据集上的实验结果
加利福尼亚理工学院创建的Caltech101图像数据集包含超过29 780张101类的不同物体图像。由于物体数据集的固有特性,借鉴文献[11]的实验布局方式,随机为每一类别分别选取数量为5、10、15、20的图像作为训练数据,剩余部分作为测试数据,并固定字典的原子个数。MCVGDL模型的参数设置为α=2e-3、β=1e-7和θ=10,固定字典原子个数K为510、1 020、1 530、2 040,实验结果如表8所示。

表8 Caltech101数据集上的识别率和标准差
3.4 字典大小对识别率的影响
字典在稀疏表达和协作表达的应用中具有重要作用,且获得合适大小的字典也十分重要。字典的大小影响着鉴别性字典的鉴别能力,合适的字典大小有助于提高识别率和降低计算开销。在限定训练样本的前提下,通过字典大小的调节可以保证较高的识别率,同时能降低计算开销。
针对Extend Yale B随机为每一类别选择32张图像作为训练数据,字典原子个数K依次按照78,116,154,…,1 218变化,每一次为每一类别增加一个字典原子的方式递增,即每次增加38个字典原子。每次固定字典原子个数K后,Extend Yale B数据集的实验结果是20次随机选择图像进行训练和测试得到的平均识别率。图2是Extend Yale B数据集上KSVD、D-KSVD、LC-KSVD、FDDL、SVGDL和MCVGDL算法字典原子个数K变化后的识别率曲线。

图2 Extend Yale B数据集上字典原子数变化情况下的算法识别率比较
针对Yale和ORL数据集分别为每一类别选择8张图像作为训练数据,并固定训练数据。对于Yale数据集,字典原子个数K依次按照30、45、60、75、90、105、120的大小变化。对于ORL数据集,字典原子个数K依次按照80、120、160、200、240、280、320的大小变化。每次固定字典原子个数K后,Yale和ORL数据集的实验结果是50次随机选择不同训练和测试样本得到的平均识别率。图3和图4分别给出了Yale和ORL数据集上KSVD、D-KSVD、LC-KSVD、FDDL、SVGDL和MCVGDL算法字典原子个数K变化后的识别率曲线。

图3 Yale数据集上字典原子数变化情况下的算法识别率比较

图4 ORL数据集上字典原子数变化情况下算法识别率比较
3.5 结果分析
由于MCVGDL结合了SVM和协作表达,采用MCVSVM对SVGDL算法进行改进,因此本文提出最小类内方差支持向量引导的字典学习算法。该算法不仅考虑每类数据边界上的样本点,而且利用数据的分布信息,同时,其采用的MCVSVM可以看作是SVM和Fisher线性鉴别的分类器,与FDDL采用Fisher鉴别条件所不同的是,MCVSVM利用了SVM大间隔原理最大化数据类别间的距离,并自动分配权值,MCVGDL与SVGDL类似,是对FDDL固定分权模式的改进。
表2~表8列出了KSVD、LC-KSVD、D-KSVD等11种算法与本文提出的MCVGDL算法的平均识别率。在Extended Yale B、Yale、ORL和AR数据集上的实验结果表明,本文算法在小数量的样本条件下识别率相比于SVM和CRC算法有大幅提升,最高提升了12%,相比于SVGDL和FDDL平均提升了1%~2%,最高提升了3%。随着样本数量的增加,MCVGDL算法依然表现出了优于其他算法的分类性能。当训练样本数量增加到一定程度时,所有算法均表现出良好的分类性能,然而在大部分情况下MCVGDL分类性能最好,但是训练样本的增加必然会增加模型的训练时间,从而证明MCVGDL算法对于样本条件的鲁棒性,同时说明了采用MCVSVM对SVGDL进行改进的合理性,以及大间隔分类器考虑数据信息分布的必要性。在COIL20不同数量训练样本的情况下,当训练样本为5时,SVM表现出优于其他算法的分类性能,但是MCVGDL相比于FDDL、SVGDL仍然提高了1%~2%,相比于FDDL、SVGDL和MCVGDL字典学习算法均表现出更好的分类性能。当训练样本增加到10和20时,FDDL、SVGDL、KSVD、D-KSVD、LC-KSVD和MCVGDL在分类性能上非常接近,MCVGDL相比于其他算法仍有不同程度的提高,相比于CRC和SRC平均提高了5%,说明将SVM和协作表达相结合可以提高字典的鉴别能力。在COIL100数据集上,训练样本为5时,SVM表现出优于其他算法的分类性能。随着训练样本的增加,MCVGDL具有更高的识别率,当训练样本个数增加到20时,BDLRR识别率达到87.4%,优于其他算法,但是MCVGDL仍然表现出优于SVGDL的识别率和稳定性,说明了采用MCVSVM对SVGDL改进是有效的。在Caltech101不同训练样本的条件下,MCVGDL在大部分情况下的识别率均优于FDDL、KSVD、D-KSVD、LC-KSVD算法,但是在训练样本数为5的条件下BDLRR算法的识别率更高。随着样本数量的增加,MCVGDL表现出优于SVGDL算法的识别率,表明融合Fisher准则的MCVSVM对SVGDL算法的改进思路是正确有效的。
图2~图4是本文算法和其他典型字典学习算法在固定训练样本条件下,调整字典原子个数K对识别率的影响。可以看出,MCVGDL和SVGDL算法在3个数据集上(Extended Yale B、Yale和ORL)均表现出了良好的稳定性和识别率。KSVD、D-KSVD、FDDL和LC-KSVD算法在字典原子数量增加到一定程度时,识别率呈现递减趋势,尤其是KSVD算法,其对于字典原子大小的选择非常敏感。MCVGDL和SVGDL都表现出对字典原子数K较强的鲁棒性,但是MCVGDL展现出更高的识别率,说明了SVGDL和MCVGDL可以在大样本条件下,兼顾识别性能和运算性能,选择合适大小的字典,降低时间开销,同时保证了良好的识别性能。
不同训练样本和字典数量情况下的实验说明了通过SVM引导字典学习可以获得更好的分类性能。相比于SVGDL采用标准的SVM作为鉴别项,MSVGDL采用MCVSVM作为鉴别项,既考虑了大间隔原理,也考虑了类内散度(数据的分布信息)。实验结果表明,改进类内方差的MCVGDL算法可以在一定程度上提高模型的稳定性和识别率。
4 结束语
为提高基于字典学习算法的分类性能,本文利用MCVSVM算法对SVGDL算法进行改进,通过兼顾最大化间隔原理和数据分布信息得到最大化类间间隔和最小化类内方差的分类器,并充分考虑编码向量的分布信息,保障同类样本编码向量总体一致,同时降低向量间对应分量的耦合度及修正SVM分类矢量,充分挖掘编码向量鉴别信息,从而更好地引导字典学习,提高字典鉴别能力。实验结果表明,在不同样本和字典原子数量条件下,该算法对于人脸和物体均具有较高的识别率。但本文采用单一合成字典学习模型,限制了字典鉴别能力的提高,因此融合解析字典与合成字典的双字典学习算法将是下一步的研究重点。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
小学阅读指南·低年级版(2019年11期)2019-07-01
中国听力语言康复科学杂志(2019年3期)2019-06-24
听力学及言语疾病杂志(2019年3期)2019-05-24
唐山师范学院学报(2018年6期)2018-12-25
中国交通信息化(2018年3期)2018-06-13
小天使·一年级语数英综合(2017年11期)2017-12-05
读者(2016年14期)2016-06-29
中国交通信息化(2016年2期)2016-06-06
