
基于深度学习与特征融合的人脸识别算法
2020-04-20 03:38李菲菲
电子科技 2020年4期
司 琴,李菲菲,陈 虬
(上海理工大学 光电信息与计算机工程学院,上海 200093)
人脸识别是通过人的脸部特征信息进行身份识别的一种生物识别技术,具有防伪性能好、非侵犯性等优点。近年来,人脸识别成为模式识别、图像处理、机器视觉及神经网络等学科的研究热点,其在国防安全、身份认证、视频监控、互联网交互等领域有重要的研究价值。传统的人脸识别流程包括人脸检测、人脸对齐、人脸特征提取和人脸分类4个阶段。其中人脸特征提取是人脸识别的关键,特征提取的好坏直接影响分类的准确率。传统的特征提取方法中,局部二值模式(Local Binary Pattern,LBP)是一种用来描述图像局部纹理特征的算子,由于其具有计算简单、特征分类能力强等特点,被广泛的运用到人脸识别研究当中[1-3]。然而在非限制环境下,由于人脸图像的复杂性,用传统的特征提取方法达不到理想的效果,且特征的表达方式过度依赖于人工选择。
近年来,深度学习受到了越来越多研究者的关注,它在特征提取上相比于浅层模型有明显的优势。深度学习是包含多级非线性变换的层级机器学习方法,其通过组合低层特征形成更抽象、更有效的高层表示,且这些表示具有良好的泛化能力[4]。其中,卷积神经网络是一种经典且广泛应用的深度学习方法,其神经元间的连接模式受启发于动物视觉皮层组织。卷积神经网络的局部感知、权值共享及池化操作等特性使其更接近于生物神经网络,可以有效降低网络的复杂度,减少模型学习参数;同时使模型对位移、缩放、旋转或其他形式的形变具有一定程度的不变性,并具有强鲁棒性和容错能力[5-6]。在人脸识别任务中,与传统方法提取的特征相比,卷积神经网络通过卷积、激活函数、池化等一系列运算自动学习到的强大表示能力的特征更具优越性,且在LFW数据集上的认证识别率已经超过人眼的识别率[7-8]。但是使用卷积神经网络提取的图像特征忽视了图像的局部结构特征,且网络会因为光照等因素学习到不利的特征表示。传统特征提取方法LBP是一种用来描述图像局部纹理特征的算子,其具有光照不敏感、平移不变和旋转不变性等特点。将传统特征提取方法LBP与卷积神经网络结合,二者之间的互补性可以提高提取特征的判别性。
VGG[9]作为一个经典的卷积神经网络,其结构中多个小滤波器的卷积层的组合,可以在使用更少的参数的同时增强特征的表达。本文对VGG网络进行深浅特征相融合称之为SDFVGG网络,提出了一种基于LBP与SDFVGG网络的新方法。该方法将LBP人脸特征图与原图相结合作为SDFVGG网络的输入,使SDFVGG网络不仅可以自动学习原始人脸图像的信息,还可以学习LBP纹理信息。
1 基本原理1.1 LBP算法
LBP指局部二值模式,是一种用来描述图像局部纹理特征的算子。其基本原理为:原始的LBP算子定义在一个像素3×3领域内,以邻域中心像素为阈值,将相邻的8个像素灰度值与阈值进行比较。如果相邻像素值大于阈值,则该像素点的位置被标记为1;反之,则为0。因此,3×3邻域内的8个点经过比较产生8位二进制数。随后将8位二进制数依次排列形成一串二进制码,然后转化为十进制数,该十进制数就是中心像素的LBP模式。
LBP算子由下面计算式得到
(1)
其中,(xC,yc)为中心像素的坐标;ic为中心像素的灰度值;ip(p=0,1,…,7)表示中心邻域上的8个像素值;s(x)为符号函数定义为
(2)
经过LBP算子得到LBP模式如图1所示。
则可得到中心像素的LBP模式为(00010011)2=19。由于局部二值模式是人脸的局部信息特征且具有光照不敏感、灰度平移不变和旋转不变性等特点,因此将原始图像与LBP图像结合作为卷积神经网络的输入使卷积神经网络提取的人脸特征更丰富、更具表征能力。
1.2 VGG
VGG是牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发的深度卷积神经网络。VGG在AlexNet基础上将单层网络替换为堆叠的3×3的卷积层和2×2的最大池化层,减少了卷积层参数并加深网络结构提高了性能,成功地构建了16~19层深的卷积神经网络。与之前state-of-the-art 的网络结构相比,VGG错误率大幅下降,并取得了 ILSVRC[10]2014 比赛分类项目的第2名和定位项目的第1名。此外,VGG的拓展性很强,迁移到其他图像数据上的泛化性非常好。
VGG16整个网络的卷积核尺寸均为3×3,卷积步长为1,采用的最大池化尺寸均为2×2,步长为2。网络拥有5段卷积,前两段各有2个卷积层,后3段各有3个卷积层,每段内的卷积核数量一样,依次是64、128、256、512、512;两个3×3的卷积层堆叠具有大小为5×5的感受野,3个3×3的卷积层堆叠的感受野为7×7。使用3个3×3的卷积层堆叠跟一个7×7的卷积层相比有如下优点:(1)前者拥有比后者更多的非线性变换,即前者可以使用3次ReLU[11]激活函数,而后者只有一次,这使得卷积神经网络对特征的学习能力更强;(2)3个串联的3×3的卷积层拥有比一个7×7的卷积层更少的参数量。同时每段卷积后会连接一个最大池化层用来缩小图片尺寸,从而减少最后全连接层中的参数。VGG16结构如图2所示。
图中Conv表示网络的卷积层,Maxpool表示最大池化层,FC表示网络的全连接层。
本文采用迁移学习的方法,用fine-tuning的方式对在ImageNet数据集上预先训练好的VGG16模型进行训练。所谓迁移学习,就是将一个问题上训练好的模型通过简单的调整使其适用于一个新的问题。迁移学习解决了训练数据不足以及训练时间的问题。
2 SDFVGG算法
2.1 特征融合方法
本文提出了一种将VGG网络深浅特征相融合的方法。其基本过程和原理如图3所示:
(1)通过不同尺度的并行多层卷积层提取网络不同的浅层特征,增强了特征的表达能力;
(2)将不同的浅层特征与网络深层特征通过Concat层相融合,生成融合特征;
(3)将融合特征通过该并行多层卷积块生成不同的融合特征,将这些不同的融合特征与该网络更深层的特征相融合,生成最终的融合特征。
2.2 SDFVGG网络结构
将VGG网络采用图3所示的特征融合方法得到的SDFVGG网络结构如图4所示,图中虚线框所示为特征提取和融合的并行分支。SDFVGG网络通过连接层逐级融合特征,Concat-2层的输出是最终的融合特征。
其中,并行分支中Conv6-1、Conv6-2、Conv6-4与Conv7-1、Conv7-2、Conv7-4卷积核数量为64;Conv6-3、Conv6-5与Conv7-3、Conv7-5卷积核数量为128;Max-pool6与VGG网络最大池化层参数一致。并行结构中,1×1卷积层虽增强了激活函数的非线性特征,却没有扩大感受野;不同尺度的卷积层的并行连接增加了网络的宽度,提高了网络的性能,使网络提取的特征更丰富。但当扩展网络使参数数量增加时,易发生过拟合。因此在网络第一层和第二层全连接层中添加Batch Normalization可以控制过拟合,加快收敛速度。最后一个全连接层参数设置为分类数,Soft-max层通过计算每个类的概率,得到相应的最大概率类别。
3 输入特征融合算法
本文将原始图像信息与局部二值模式信息相结合作为SDFVGG网络的输入,使SDFVGG网络不仅能学习全局原始图像信息又能学习图像的局部特征,从而使得网络提取的特征更充分、更具表征能力。具体的输入特征融合方式如图5所示。
4 实验过程
4.1 数据库
大规模的人脸数据集CAS-PEAL[12]包含了1 040个人的99 594张照片,其中男性595人,女性445人,图像涵盖了各种姿势、表情、配饰、灯光、背景等方面的变化。人脸数据集CAS-PEAL-R1是CAS-PEAL的子集,包含了1 040个人的30 863张图像。这些图像分属正面与侧面两个子集。在正面子集中,所有的图像都是由特定的摄像机拍摄,被拍者正对着摄像机。其中,377人有6种不同表情的图像;438人有佩戴6种不同配饰的图像;233人有在至少9次光照变化下获得的图像;297人在2~4种不同的背景下拍摄了照片;296人拥有与相机距离不同的图像。此外,66人在6个月的时间间隔内,在两次试验中记录图像。侧面子集包含了1 040人的21种不同姿势的图像。
在实验中使用了最具代表性的3组人脸集合,分别是表情集(PE)、配饰集(PA)、光照集(PL)。其中PE包含377人的1 884张面部图像,PA包含438人的2 616张面部图像,PL包含233人的2 450张面部图像。将每个集合图像按照9:1比例分为训练数据集与测试数据集,并将所有人脸图像根据眼睛坐标进行裁剪缩放到大小为230×200像素的图像。图6为经过处理后的人脸示例。
4.2 实验结果及分析
为了证实本文提出方法的有效性,在CAS-PEAL-R1人脸数据集上进行3组人脸识别实验:
(1)比较网络特征融合对实验结果的影响。将原始图像分别作为VGG与SDFVGG网络的输入,在3个子集PE、PA、PL上进行实验,对比网络特征融合对实验结果的影响。如表1所示,对于PA和PL两个子集,得到的SDFVGG网络的识别准确率均高于VGG网络,说明将网络深浅特征融合可以增强特征的表达,提高识别准确率;
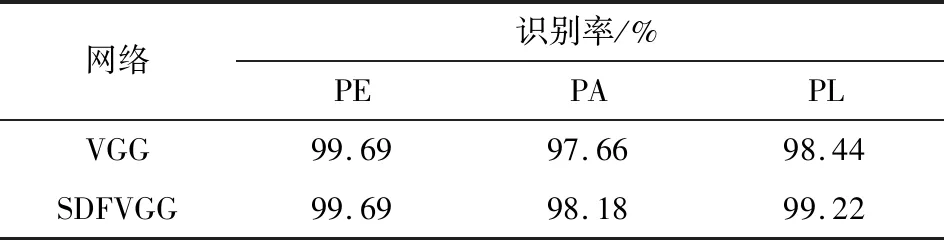
表1网络特征融合的影响Table 1.Influence of network feature fusion
(2)比较不同输入数据类型对实验结果的影响。让SDFVGG网络的输入分别为原始图像、LBP图像以及原始图像与LBP相结合的图像,在相同的实验条件下,得到的3个子集PE、PA、PL识别准确率如表2所示。从中得出,只使用LBP图像作为网络的输入得到的人脸识别准确率比用原始图像得到的识别率低,因为LBP图像相比原始图像有信息损失。但是将原始图像和LBP图像相结合得到的人脸识别准确率比单独使用LBP图像得到的识别率要高且该算法的泛化能力更强。这是因为LBP 图像更好的表达了图像的局部特征,将二者结合既弥补了信息的损失又增加了图像的局部特征信息,因此识别率得到提高;
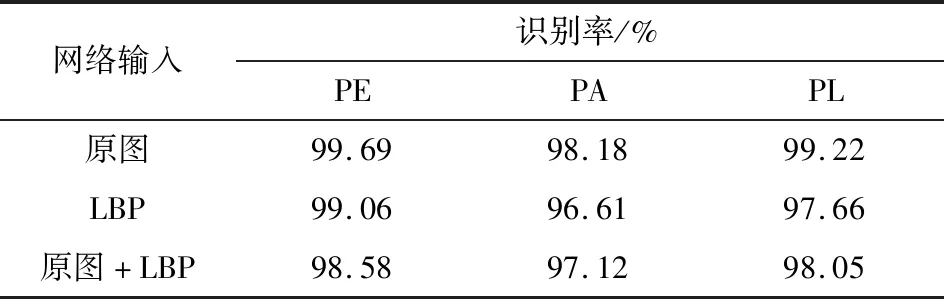
表2不同输入类型的识别率比较Table 2.Comparison of recognition rates for different input types
(3)本文提出的方法与其他方法在CAS-PEAL-R1人脸数据集上的比较。如表3所示,首先可以看出本文研究方法相对于已有算法在PE与PA两个子集上的精度分别提高了0.58%和3.72%,充分证明了该算法的正确性。与此同时,本文提出的研究方法在PL子集上的识别准确率为98.05%,远远高于往年的几种算法,证明了将LBP局部特征信息与原始图像信息相融合作为SDFVGG网络输入的有效性。

表3与其他方法的比较Table 3.Comparison with other methods
5 结束语
本文提出一种 LBP与SDFVGG网络相结合的人脸识别方法,该算法用不同尺度的并行多层卷积层提取VGG 网络的深浅特征并相融合,增强网络特征表达。LBP 算子提取的人脸图像具有光照不敏感、灰度平移不变和旋转不变性等特点,通过将LBP局部结构信息与原始图像信息结合作为网络的输入,可使SDFVGG网络提取更具有判别性的人脸特征。在 CAS-PEAL-R1人脸数据库上的实验结果表明,这种方法有助于提高人脸识别的准确率。
猜你喜欢
作文中学版(2022年1期)2022-04-14
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
奥秘(2021年5期)2021-06-15
学生天地(2020年31期)2020-06-01
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
科技传播(2019年24期)2019-06-15
电子制作(2019年9期)2019-05-30
