
基于锁位的并行二进制分割防碰撞算法研究
2020-04-18 13:15:06贺晓霞贾小林
计算机应用与软件 2020年4期
贺晓霞 贾小林
(西南科技大学计算机科学与技术学院 四川 绵阳 621000)
0 引 言
RFID技术是一种无线自动识别技术,按照工作频率的不同,可以分为低频(LF)、高频(HF)、超高频(UHF)和微波等不同种类。其中超高频RFID系统通常用于远距离识别和多标签的场合。为了有效地解决UHF RFID系统中出现的信道争用的情况[1],通常有以下两种解决方案:
(1) 采用并行方式实现多卡识别;(2) 根据规定时间,电子标签挨个发送数据,在此时间内只有一个电子标签在工作。
对于第一种情况,一般采用码分多址和频分多址的方式,然而这样会增加系统的成本和复杂性。在第二种情况下,可以使用TDMA方法与软硬件结合或它们的组合来实现。实现起来并不复杂,但是如果没有好的算法,要识别所有的电子标签将花费很长时间。
在RFID多标签系统中,主流防碰撞算法可以划分为:(1) 基于Aloha的算法,如纯Aloha(PA)、时隙Aloha(SA)、帧时隙Aloha(FSA)、动态帧时隙Aloha(DFSA)以及其他的改进算法[2];(2) 基于树的算法,主要有查询树(QT)[3]、二进制搜索(BS)[4]、增强型搜索树算法(EBST)[5]、碰撞树(CT)[6]以及改进的碰撞树算法(ICT)[7]等;(3) 混合算法,例如树时隙Aloha(TSA)、混合查询时隙(HQT)以及哈希树算法等[8]。然而基于Aloha算法有一个严重的问题,称为“标签饥饿”[2],该问题可能导致标签一直无法被识别。基于二进制树的算法的核心思想是不断地将碰撞标签分为两个不相交的子集,直到识别询问区中的所有标签[9],通常需要较长的识别时间。
识别过程通常都是通过标签的唯一ID进行识别,当标签被完全识别出来之后,就会被消除,不再参与后续的应答。例如,在文献[10]中,如果发生碰撞,阅读器将通过用0或1来选择路径进行答复。标签位与查询位一致的标签继续下一个位仲裁,而产生碰撞的标签将记录碰撞位置并同时进入静默状态。在ID-BTS[11]中提出了类似的协议。这些算法中标签都需要带一个计数器作为指针,每个标签在冲突仲裁过程中传输ID的每一位。文献[12]提出了一种新的自调整多叉树防碰撞算法(new anti-collision algorithm based on adjustive multi-tree,NAM),该算法是一种基于多叉树搜索的确定性算法,其引入了异或运算,使得空闲时隙的数量降低。
上述两种技术主要有三个缺点:(1) ID-BTS算法每次识别后发送最后一个碰撞比特位置的查询,唤醒非活动标签,识别过程相对较慢,并且重复发送相同的位查询请求会造成大量的时间开销;(2) 阅读器的命令帧相对较长,ID-BTS算法在每次标签识别之后都会产生一定的时间开销,是一种慢速算法;(3) 对于NAM算法,随着标签数量以及标签位数的增加,空闲时隙也会随之增加,数据传输量仍相对较大。
1 算法设计
本文提出了一种基于锁位式的并行二进制分割(LPBS)防碰撞算法。该算法利用曼彻斯特编码方式,按位判断,确定并提取碰撞位,组成新的标签序列,使得非碰撞位的信息不再参与传输。例如识别标签为10011100、11000110时,检测到的碰撞位是D6、D4、D3、D1,因此组成新一轮查询序列为1X0XX1X0,不需要再重新发送非碰撞位的信息,而只需要传送碰撞的那4位,使得信息的传输量减少了50%。同时,采用并行二进制分割技术,使得阅读器和标签可以进行一位标签应答。该方法可以动态修改标签与标签之间的相对回复顺序,发送的比特数量等于除了叶子节点之外的二叉树节点的数量的两倍。该技术只使用阅读器的一位来响应发送的数据量(1:碰撞,0:无碰撞)。标签可以通过阅读器确定上一轮查询中位传输的结果,从而使得标签能够在应答队列中不断地修改其识别的顺序。因此,标签可以确定其未来的应答顺序并设置自传输控制。本文提出的基于锁位的并行二进制分割防碰撞算法(LPBS),结合了上述两种技术的优点,在减少阅读器和标签之间传送的比特数量的同时,减少碰撞时隙,时间开销也比传统的二叉树防碰撞算法有一定的改进。图1显示了并行二进制分割技术和深度优先搜索(DFS)[13]技术之间的差异。

(a) 深度优先搜索(DFS)路径

(b) 并行二进制分割路径图1 两种方法的路径示意图
1.1 相关定义
(1) Lock-request(ID,1):该指令表示锁位指令。阅读器发送位查询请求,检测发生碰撞的位置,如果冲突置为1,反之无冲突为0。当标签接到锁位的指令时,比较自身与阅读器的序列,提取出置为1的比特位,组成新的一轮查询序列号,而没有产生碰撞的位置信息可以忽略,下一轮查询也无需再次发送。
(2) request(x,p):查询指令。阅读器的查询前缀为第一个参数,碰撞位置的最高位作为第二个参数。
标签采用简单的逻辑运算,基于两个计数器和两个寄存器,实现自传输控制和动态更新回复命令。寄存器和计数器的定义如下:
(1) 当前路径寄存器(CPR):用于存储当前该位级别的路径数(二进制分支数量)。
(2) 下一条路径计数器(NPC):用于存储连续发现路径的总数。当碰撞的标签回复阅读器时,该计数器增加,任何碰撞都会增加二进制分支的数量。CPR的值将在每轮二进制分割结束后由该计数器中的内容加载。
(3) 当前顺序寄存器(COR):用于在CPR中存储相对于当前路径数目的标签回复顺序。
(4) 下一个顺序计数器(NOC):用于跟踪记录标签回复顺序的变化,当二叉树中出现一个新的子树时,它会增加。在每层子树分裂结束时,COR将被NOC内容加载。
1.2 阅读器操作
初始化阅读器堆栈,发出查询请求,阅读器根据标签的应答不断更新现有的伪二叉树。阅读器通过扫描之前二进制分割级(上一层子树)发现的路径,来探索潜在的分支路径节点信息。检测到碰撞发送1,没有碰撞发送0。每个标签都知道当前的回复顺序,阅读器通过标签的回答报告标签的传输状态(碰撞或无碰撞)来更新该顺序。
1.3 标签操作
标签操作具体描述如下:
1) 标签接收阅读器启动命令。
2) 标签重置计数器和寄存器的值。
3) 一位标签响应其回复顺序,一个比特阅读器紧跟着报告结果。
4) 在之前的二进制分割级别(即上一层子树)中,扫描之前发现的路径(节点)。
5) 每个子树发送当前层中的当前标记位。
6) 每个节点的阅读器通知标签冲突状态。
7) 标签修改各自控制计数器如下:如果“没有碰撞”,那么它的顺序和路径总数没有变化;如果“碰撞”,那么增加总数路径(NPC++)。
8) 标签接到锁位指令Lock-request(ID,1),比较自身与阅读器的序列,提取出置为1的比特位,生成新的一轮查询序列号,忽略没有产生碰撞的位置信息,下一轮查询也无需再次发送。如果在当前级别中没有扫描标签,或者如果标签通过发送它的标记位1来参与当前的标签冲突,那么在下一个分割级别中增加其应答顺序(增加NOC的值)。
9) 寄存器(COR,CPR)由相应计数器的内容更新(NOC,NPC),标签接收request(x,p)查询指令,将上一轮产生碰撞的标签位组成新的查询前缀。
10) 扫描下一个分割级别,并重复从步骤4)开始的过程,直到完成ID长度的“n”级别。
2 算法性能分析
本节将从多个角度分析LPBS算法的时间复杂度、吞吐率以及标签通信的复杂度。时间复杂度可以通过分析总时隙数验证,而标签通信复杂度可以通过标签发送的位数验证。
阅读器通过图2所示的顺序扫描树节点来重建二叉树,并在每个节点接收标签响应。表1详细描述了基于LPBS算法下分支节点探测的过程。

图2 并行分裂扫描用于探索路径

表1 LPBS算法的防碰撞过程(---:静默)

续表1
(1) 传输总比特数(标签与阅读器之间)。如图1(b)所示,除叶子节点外,树节点的数量等于9个节点。每个节点消耗1位用于标签响应,阅读器消耗1位用于报告每个节点的类型(碰撞或无碰撞)。
通过阅读器发送的比特数量和通过标签发送的比特数量相同,均为9比特。因此,阅读器和标签之间传输的总比特数等于两项之和,为18比特。而文献[14]为了标识与本文例子中相同数量的树节点,使用了30个比特位。
(2) 总时隙数分析。总时隙数也称为时间复杂度,可以分为空闲时隙和碰撞时隙两种状态进行分析。
无空闲时隙状态,在本文中只讨论二叉树情况,因此不存在四叉树、多叉树混合查询的情况。当查询过程中没有空闲时隙时,可以看成是完全二叉树查询,Tem代表空闲时隙的数量,则此时Tem等于0。假设总时隙数为T,碰撞时隙为Tc,阅读器询问区中的标签数量为m,则有:
T=Tem+Tc+m
(1)
当进行完全二叉树查询时:
T=2m-1
(2)
(3) 吞吐率。单位时间内某信道成功交付数据的平均速率为:
S=m/T
(3)
3 算法仿真及分析
本文通过MATLAB平台进行该算法的仿真实验,假设:(1) 阅读器具有丰富的记忆和较强的计算能力;(2) 标签的内存和计算能力有限;(3) 阅读器和标签之间有一个共享的通信信道;(4) 标签不能相互交换信息。
如图3所示,比较LPBS算法与动态按位仲裁算法(DBS)[16]在标签数与总的传输比特数量之间的关系,可以看出LPBS算法中阅读器与标签之间传输的总的比特数量比DBS算法少。

图3 标签数与传输比特数的关系
图4为ID长度为16比特的情况下,识别标签所用的时间与标签数量之间的关系。可以看出,BIBD[15]算法识别300个标签需要花费480 ms,传统的查询树算法需要花费2 550 ms。动态查询树算法需要1 500 ms识别所有的标签,而本文提出的LPBS算法则只需要143 ms。
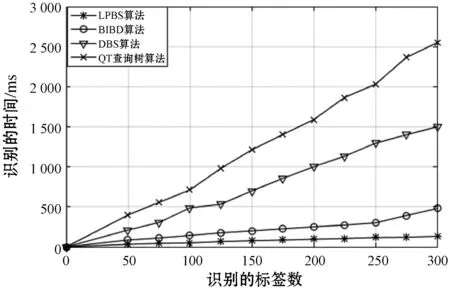
图4 40 KB/s速率下标签数量与识别时间的关系
图5为LPBS算法和QT[3]算法、DBS算法、BIBD算法在总时隙数方面的比较。可以看出,随着标签数量的增多,本文提出的LPBS算法与其余两种算法相比,所需的总时隙数明显更少。

图5 标签数量与总时隙数的关系
4 结 语
本文提出了一种新的基于锁位的并行二进制分割防碰撞算法(LPBS),可以应用于UHF RFID多标签识别防碰撞系统中。LPBS算法利用曼彻斯特编码按位判断,确定并提取碰撞位,使得非碰撞位的信息无需再次传输。同时,采用并行二进制分割技术,使得阅读器和标签可以进行一位标签应答。该方法可以动态修改标签与标签之间的相对回复顺序,将阅读器传输的信息最小化为仅一位反馈。该算法在减少阅读器和标签之间传送的比特数量的同时,减少碰撞时隙,时间开销也比传统的二叉树防碰撞算法有一定的改进。通过性能分析和仿真实验表明,本文算法在大多数情况下优于已有的防碰撞算法。
猜你喜欢
电脑报(2022年37期)2022-09-28 05:31:07
电子设计工程(2022年15期)2022-08-17 10:07:04
中等数学(2021年8期)2021-11-22 07:53:38
现代计算机(2021年14期)2021-07-09 17:19:40
数学大王·低年级(2019年10期)2019-11-25 08:23:26
中等数学(2019年4期)2019-08-30 03:51:44
东北师大学报(自然科学版)(2018年3期)2018-09-21 09:06:36
武汉轻工大学学报(2016年4期)2017-01-16 08:53:03
现代计算机(2015年17期)2015-09-26 02:01:54
河南科技(2014年24期)2014-02-27 14:20:01
