
汉字部件拆解方案新探
2020-04-12 11:24潘泰
现代语文 2020年11期

摘 要:拆分汉字时只要相交就不拆解,或者只要不同就分立为不同部件的做法并非总是突出汉字字形特征的最佳方案。对现行汉字字形的系统性拆解应该符合人们的认知规律,尽量体现字形的区别性差异点,满足字形的拓扑相似性等要求。在漢字字形的拆解中可以兼顾字源理据,但并非总是必须如此。
关键词:汉字;部件;系统性;认知
一、引言
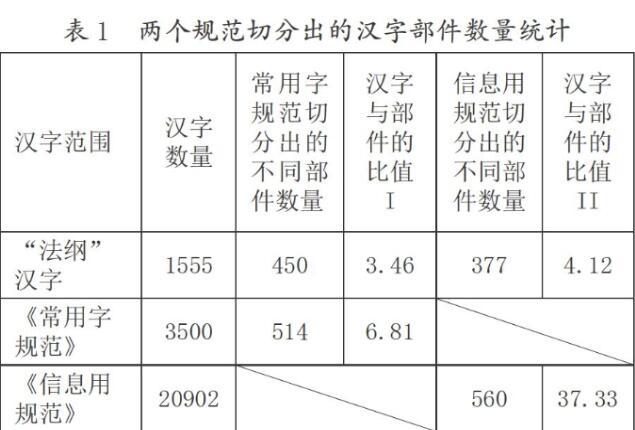
在汉字的学习中,部件的辨认(recognize)和复写(reform)是其中的关键环节之一。不过,现有的汉字部件拆解方案却不太适用于人们习得汉字的场景。我们以法国基础阶段的汉语教学大纲所包含的1555个基础汉字为研究对象[1],以《现代常用字部件及部件名称规范》[2](以下简称《常用字规范》)和《信息处理用GB 13000.1字符集汉字部件规范》[3](以下简称《信息用规范》)这两个规范为参照,对这1555个汉字进行了全部拆解。具体情况如表1所示:
可见,这两个规范在处理最初的1555个基础汉字时,分别使用了450个和377个不同的部件,每个部件的平均利用率只有3至4次,似乎很难达成“以部件促整体”的效果。反而是在渡过最初的难关之后,汉字和部件的比值才得到显著提升,部件的效率也才得到较好的体现。
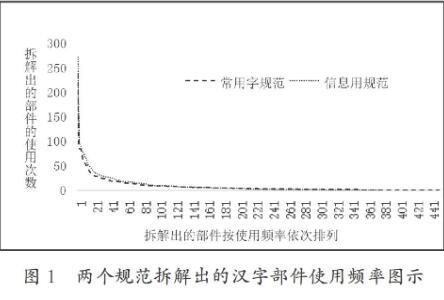
不仅如此,对于这1555个基础汉字,这两个规范拆分出来的部件的使用率还非常不均衡。使用频率最高的部件“口”分别有237次和273次;只使用了1次的部件却分别有102个(占22.67%)和73个(占19.36%)之多,只使用了3次或3次以下的部件高达226个(占50.22%)和168个(占44.56%)。如果把这两个“规范”拆解出来的所有部件按使用频率从高到低依次放在横坐标上,再用纵坐标代表它们的使用次数,就能得到下面的折线图(只针对这1555个基础汉字)(见下页):
图1直观地提示我们,无论采用何种办法,汉字部件的常用度都是一种“断崖式”的分布:高频部件非常集中,就那么几十个部件(如使用频率最高的1号部件“口”);大量的部件使用频率都非常低,但这样的部件却是绝大多数。在对汉字字形的部件拆解过程中,“一字一例”的现象非常突出,这也是造成汉字难认、难记、难学的主要原因之一。
与此同时,这样的统计结果所反映出来的现状,也促使我们在汉字下级单位的研究中采取另外的路径,一条必须与大多数中国人习得汉字的认知规律保持一致的路径,否则,势必会极大地抑制汉字习得的效果。
二、汉字字形拆解的系统性
基础汉字的部件构成存在“各不相同”的情况,能够加以利用的系统性规律本就不多,如果继续坚持“交重不拆”的原则①,将所有字形有异的下级构成部分都分别确立为不同的部件,就显得既不经济,又不科学。一个极端的例子就是上述两个规范为了贯彻笔画相交则不拆解的原则,为包含“”的汉字及其下级单位总共设置了多达22个独立的部件,它们是“”、“”和“尹聿事兼争妻隶肃秉庸”。事实上,“”既具有明确的语义价值,同时它又总是以与其他笔画或部件交叉的形式出现,因而具有作为符号的明确的系统性价值,把“”独立出来是可行的、有效的。
将存在于现行汉字系统中的部件规律,尽可能多地通过部件拆解体现出来,这是我们对“系统性”的主要理解。同理,将“黑象禹禺革重鬼”“平半夹乎伞?”“”等汉字或汉字构成部分都不予拆解,似乎有点儿回避问题的嫌疑,也未能满足系统性的要求。
系统性的含义还可以描述为尽量减少对于同一字形的多种拆解,尽量做到“一字一拆”。第一,现有的两个规范中都有对部件“就大不就小”的说明:“表中部件规定了汉字部件拆分的下限,一般不宜再行拆分。”[2](P6)“表中部件没有包容关系,不得将大部件拆分为小部件。”[3](P5)比如,“京向食言”既然已经作为独立的成字部件,就不应将它们继续拆解为“亠口小、丿冂口、人丶艮、丶三口”等更小部件。这个原则还是应该坚持,否则所有的部件就能全部拆解为数量极其有限的笔画,这不符合部件拆解的初衷。当然,对两个“规范”将这几个字看作是独立的部件而不予拆解的作法,我们仍持保留意见。
第二,两个规范中确实还存在一些“一字多拆”的问题。即使是坚持“交重不拆”的原则,有些部件仍然会有可能导致某些汉字或部件的多种拆解。我们认为,这类部件似乎都应该继续拆解或归并进入其他部件为宜②。例如以下部件(这里用“→”表示拆解,用“/”表示“或者”):
?: → ?十 / 丷干,关 → ?大 / 丷天,
并 → ?廾 / 丷开,兰 → ?二 / 丷三;
戊万:成 → 戈 / 戊,
→ 万 / ;
:充 → 丶儿 / 亠厶儿,
云 → 一 / 二厶;
?:益 → 丷皿 / ?八皿;
上下:卡 → 上卜 / 下;
六父:交 → 六乂 / 亠父;
业亚:並(碰) → ?业 / 丷亚;
歹:死 → 歹匕 / 一夕匕;
丆:夏 → 丆目夂 / 一自夂;
兀:元 → 一兀 / 二儿。
三、汉字字形拆解的认知规律
在认识复杂事物的时候,人们总是会自觉不自觉地运用比较和分类的方法。也只有当比较和分类比较充分时,我们对该事物的认知才会更为深入。具体到对汉字字形的认知,至少有以下两个方面的原则应得到足够的重视。
(一)差异点突出原则
众多的形近部件不仅加大了汉字辨认的难度,更为关键的是它们模糊了汉字字形的区别性特征。比如,笔画的数量通常具有区别不同字符的价值,但也有反例,“良”和“朗郎”中的“”就是如此;笔画的形态,包括是横竖撇捺折中的哪个笔画,带钩还是不带钩,相对长短关系,出头不出头等特征,通常也具有区别性价值,但是对于“奏”下半的第一笔、“灬”的第一笔、“勇”的第四笔、“尖”的竖笔、“周韦”的横笔、“射”的第二撇等,这些特征又起不到区别不同字符的作用。这样的情况有很多,可能导致的结果是令人不清楚究竟哪些是重要的,必须认清楚和写清楚,哪些则是可以模糊处理的。
我们认为,要想建立汉字字形区别性特征的概念,分立并非总是最佳方案,有选择地进行进一步拆解,也应该是解决问题的方案之一。比如,将“子”和“予”分立为不同部件,还是未能很好地提示二者的差异,仍有可能导致写起“予”來,不是少了点,就是忘了钩,而将“予”拆分成“乛丶乛亅”四个单笔画部件,似乎能更好地还原母语者的认知过程。同理,将“专年与”等复杂字形拆分为更小的部件,也应该是有必要的,这样的例子还有很多。
我们对现行汉字系统中存在的高度形近的汉字或部件进行了归纳,将其大致分为四个大类。下面,就对这四类分别予以示例说明,其中,带下划波浪线的不予切分,其他的则可以进行进一步拆解。
1.横竖类①
1)扌 才 丁 寸
干 千 于 亍
土 士 工 耂
牛 午 ?
王 壬 主
羊
手 丰 乍
隹 隺 雀
里 重 垂
2)丨 亅
刂
川 世
3) 卜
止 ? 正 疋
廾 丌 升 开 井 并
艹 ? 廿 甘
2.撇捺类
1)八 丷 小 忄
东 乐
平 半 夹 乎 伞
立 产
业 亚 严 並
少 乑
2)人 乂 入 义
大 文 太 丈
天 夫 矢 失 夹 夭 夬 央
?
史 吏 更
厂 广
3)木 禾 术 本 末 未 朱
束 朿 柬
米 来 采 釆 耒
4)之 廴
斤 斥 丘 乒 乓
艮
爪 爫 瓜
亻 彳
亥 豕 豸
3.折钩类
1)乚 乙
己 已 巳
七 毛 乇 屯 长
氏 氐
乞 气
九 丸 卂 凡
2)又 叉 久 及 攴 支
友 犮 发
3)戈 弋 戋 戉 戍
戊 成 戌 威 咸
4)儿 几 兀 元
尢 尤 龙
无 旡 冘
5)勹 勺 匀 勿 匆
勾 句 匈 匃
丂
马 鸟 与
乃
6)子 了 予 矛
7)月
8)刀 刃 刅
刁 卫 习
力 方 为 办 万
9)弓 弗 夷
10)
11) 夕 歹 歺
12)厶 纟 幺 乡 ?
13)韦 书 丐
14)水 永 丞 承
氺 隶 函
4.框架类
1)凵:丩 出 击 缶
冂:巾 市 巿 帀 币
用 甩 甫 冉 而
舟 丹 册
内 肉 禸 两
(冎)
贝 见 页
:尸 巴 户 尺 戶
?
五 丑
匚:牙 臣 巨
: 彐 彑
2)口 日 目 白 自 百
罒 皿 四 血
且 耳 曲
西 酉 覀
臼 囟 囱 卤
中 虫 串
母 毌
田 甲 申 由 电
需要指出的是,在拆分的时候,一般是选择常见的保留,不常见的拆解。我们不妨加以举例说明,具体如表2所示:
表2 形近部件的拆解示例
水 ‖ 氺 → 亅冫(绿) 儿 ‖ → 丿乚(免)
‖ 丬 → 冫丨(北)
(壮) 月 ‖ → (那)
己 ‖ 巳 → 乚(包)
已 → 乚 弓 ‖ 弗 → 弓(费)
→弓丨丿(弟第)
衣 ‖ 农 → 冖
展 → 尸? ‖ 氐 → 丿丶(低)
→ 丿(旅)
夕 ‖ 歹 → 一夕(死)
久 →
夜 → 亠亻夂丶 天 ‖ 矢 → 丿天
夫 → 二人
失 → 丿二人
羊 ‖ → 丷干(南)
→ 丷一丨(隔)
→ (養)
? → 丷二人(卷) 厶 ‖ → 丶(去)
(以)
→ 丨一丶(遇)
→ 丿丶(留)
→ 丶(瓜)
木 ‖ 本 → 木一
末 → 一木
未 → 八
术 → 木丶
束 → 木口
朿 → 木冂(刺) 戈 ‖ 弋 → 丶(武)
→ 丿(烧)
戋 → 一戈(钱)
戉 → 戈(越)
→ 爿戈(藏)
在表2中,“‖”左边的部件不拆解,“‖”右边的部件可以继续拆解。需要指出的是,“巳”“已”的拆分方法一样,但“已”不会作为部件出现在其他汉字当中。“天”作为部件的常用度要低于“矢”,但“天”却是最先学习的基础汉字之一,远比独用的“矢”常见得多。“水”和“氺”的道理也一样,大概很少会有人先接触“氺”这个部件,再去习得“水”这个整字。
这种在部件拆解时的“人为”干预,可能比自然形成的“分隔沟”更具有认知价值[4]。通过拆解,人为突出形近部件的差异,可以逐步建立部件之间的区别性特征,符合中国人识别汉字时先轮廓、后细节的一般心理过程[5]。
(二)拓扑相似性原则
还必须认识到,大多数情况下,我们的“用户”是具有高度形象思维能力和抽象思维能力的人,而不是机器。某些部件在表面上有一定的差异,但其实都蕴含着相同的笔画和笔画关系,就像拓扑学所说的“几何图形在连续改变形状时还能保持不变”一样,可以认为是同一个部件。我们把这样具有图形近似性的汉字构成元素,视作是不具有区别性意义的相同部件,而合并为同一部件,同时以其独立使用或最常见的形式作为主部件(在“:”左边),其余的作为附形部件(在“:”右边)。两个规范在这个问题上处理得有些不够理想,可以进一步归并的至少还有以下部件:
艹:(贲);
(半/棒):(那/判);
王:(玩);
己:(改);
丰:(邦),(寿);
羊:(着),(翔);
手:(看),(拜);
丁:(可);
(临/竖):(面),(费),(师),(齐/鼻),(肃);
止:(延);
木:朩(杂);
乛(买):(候/书),(敢),(登),(丑);
七:(化),(民/绕),(长),(东/练),(切),(曳);
卩(即):(节),(报);
乙:(飞/气);
几:(朵),(风);
月:(背),(然);
冂(同):(周/用),(奂/奥),(勇);
(负):(尔),(久);
日:曰,(冒)。
还有一些部件也是可以归并的:
(飞):(永/隶/聚),(率/兆);
冫(冰):(匀/习/弱),(求);
乂(义):(更/史),(凶);
亼(合):(今);
(展):(很);
匚(医):(既/舞/降);
廴:(及);
之:辶(进);
豕:(象)。
同时,作偏旁所导致的字形变化大多也应该归并,如“匕儿工爿?子穴雨”和“顷顽攻藏顾孩空露”等字中的形近部件。
差异突出和相似归并其实是同一个问题的两个方面,最终的目标仍然是建立系统的汉字部件区别性特征。就此而言,学界同仁今后还应继续努力,以揭示汉字、部件及笔画的哪些特征在哪些场合具有区别不同字符作用的规律。同时,我们所理解的汉字字形的拆解并非是简单的“加减法”,需要在拆解的过程中体现辨认(recognize)和复写(reform)汉字的认知规律。
四、结语
需要说明的是,将复杂的字形与形近的字形进行进一步拆解,并非一定会“破坏”汉字的字源理据。首先,通过字形来获取汉字的音、义信息,并不是一件容易的事,也许早在许慎创作《说文解字》的时代就已经是非常困难的了。因此,在《说文》之外,还有以义为核心(以《尔雅》为代表)和以音为核心(从《仓颉篇》到《切韵》等)的字书传统[6]。这三大传统发展到如今,反而是以形求音义的《说文》类型最为薄弱。汉字的符号性也许早就超越了理据性,现行汉字的字形理据亟需理论与实际相结合的研究。其次,对于有些汉字或部件来说,进一步拆解更能体现其字源理据。如上文提到的“”,还有从“尺、首、金、、”中拆解出的“尸、自、亼土、夕、羊”等,都能更好地体现部件提示整字语音和语义的理据。当然,当字源与字形相冲突时,应以现行字形为准则,这也是包括两个规范在内的大多数人的共识。
基于上述汉字部件拆解的新方案,我们对1555个“法纲”汉字进行了第三次部件切分,结果如表3所示:
从表3可以看出,按照本文所建议的新方案切分出来的每个汉字的平均部件数量(3.0618)较之《常用字规范》(2.4157)和《信息用规范》(2.6914)有一定程度的上升,但并不很大。这体现出新方案切分出的汉字部件的颗粒度变得更为细致,但并不“细碎”,没有发生令人担心的与笔画混同起来的现象。最为显著的是,在这1555个最基础的汉字中,新方案的每个部件的使用频率(7.81次)比《常用字规范》(3.46次)和《信息用规范》(4.12次)有了非常大的提升,大致翻了一番。同时,新方案部件的使用频率折线图(以频率最高的前50个部件为例)也变得平缓了一些。具体如图2所示(仅以1555个基础汉字为范围):
这说明我们用较少的部件组成了较多的汉字,部件的重复利用率得到了较大幅度的提高,高频部件的分布也更加均衡合理,能够助推实现以旧知拓展新知的设想,同时也符合一般性的认知规律。
当然,由于汉字问题的复杂性,不可能一蹴而就地解决所有的问题。新方案也不是完美无缺的,也许还有对部件拆分系统性考虑不够周全的地方,但本文的思路应该更容易得到识字的心理过程的验证,也许还能起到抛砖引玉的作用,激发更多人的研究兴趣。此外,还有少量汉字,不能仅仅依靠部件拆解的方式来促进习得,如“员”和“呗”、“只”和“叭”、“束”和“杏”、“杲”和“杳”等,这些问题仍需持续深入研究。
附录:
新方案基础汉字部件表(202个)
1画(15):
一 丨 丿 丶 乛 乙 亅 乚 〇
2画(45):
二 十 厂 丁 匚 七 丂 (8);
卜 刂 冂 (5);
亻 八 人 乂 勹 匕 儿 几 九 (14);
亠 冫 冖 讠 丷 (6);
卩 阝 丩 凵 刀 力 乃 厶 廴 又 ? (12)
3画(53):
三 干 土 士 工 艸 廾 大 扌 才 寸 (13);
忄 口 囗 山 巾 (6);
川 彳 彡 亼 个 犭 夕 夂 饣 (11);
广 亡 门 氵 宀 之 (7);
彐 尸 弓 己 也 女 小 子 纟 马 乡 幺 (16)
4画(43):
丰 王 天 耂 ? 廿 五 木 犬 车 戈 牙 瓦 (15);
止 ? 日 中 贝 见 (6);
牛 手 毛 攵 片 斤 爪 爫 月 欠 (11);
文 方 火 灬 户 礻 心 (7);
巴 爿 水 (4)
5画(25):
甘 石 戊 (4);
目 且 田 由 甲 申 皿 罒 (8);
钅 生 禾 白 鸟 (5);
疒 立 头 穴 衤 (5);
皮 母 (3)
6画(13):
耳 西 页 虍 虫 竹 ? 自 臼 舟 亥 羊 米
7画(6):
豆 豕 ? 我 身 豸
8画(2):
雨 隹
参考文献:
[1]Ministère de l'?ducation nationale(法国国家教育部). Chinois, classe de seconde générale et technologique(普通及技术类高中第一学年汉语大纲)[DB/OL]. https://www.education.gouv.fr/bo/2002/hs7/default.htm,3 octobre 2002,2002-10-03.
[2]中华人民共和国教育部.现代常用字部件及部件名称规范[DB/OL]. http://www.moe.gov.cn/ewebeditor/uploadfile/2015/01/13/20150113090318445.pdf,2009-03-24.
[3]中华人民共和国教育部.信息处理用GB13000.1字符集汉字部件规范[DB/OL]. http://old.moe.gov.cn/ewebeditor/uploadfile/2015/01/12/ 20150112165337190.pdf,1997-12-01.
[4]苏培成.现代汉字的部件切分[J].语言文字应用,1995, (3).
[5]胡平.汉语儿童识字的心理机制及其给教育的启示[J].华东师范大学学报(教育科学版),2000,(1).
[6]张滌华.论《康熙字典》[J].江淮论坛,1962,(1).
A New Way to Dispart Chinese Characters
Pan Tai
(School of International Education, Wuhan University, Wuhan 430070, China)
Abstract:In the process of disparting Chinese characters, the best method is not always to persisting in the traditional theory which requires to keep crossing storks or parts in wholes or set different parts as independent ones. A new way to dispart Chinese Characters systematically this paper suggested is to try to show the differences of similar parts if they are valuable to distinguish different characters as more as possible while merge them together if they are not. This new method accords with the cognition of Chinese characters better and probably cannot give consideration to Chinese etymology within every case.
Key words:Chinese characters;parts;systematicness;cognition
基金項目:孔子学院建设和汉语国际教育2018年度课题重点项目“法国孔子学院初中级汉语教学大纲研发”(18CI01B)
作者简介:潘泰,男,武汉大学国际教育学院副教授,语言学及应用语言学博士。
猜你喜欢
医学食疗与健康(2022年2期)2022-04-23
中国新闻周刊(2021年9期)2021-03-29
科学与财富(2020年6期)2020-05-19
小学语文教学·会刊(2019年2期)2019-09-10
文教资料(2017年15期)2017-09-18
考试周刊(2017年8期)2017-02-17
人间(2016年26期)2016-11-03
青年文学家(2016年27期)2016-11-02
小学教学参考(语文)(2016年9期)2016-09-30
电脑爱好者(2016年9期)2016-05-16
