
基于BERT的警情文本命名实体识别
2020-04-09 14:49王孟轩
计算机应用 2020年2期
王 月,王孟轩,张 胜,杜 渂*
(1.迪爱斯信息技术股份有限公司,上海200032;2.电信科学技术第一研究所,上海200032)
0 引言
命名实体识别(Named Entity Recognition,NER)是自然语言处理技术(Natural Language Processing,NLP)中的一个重要领域[1],也是警情数据智能分析的关键。其核心内容是找出一套可有效识别并抽取文本中人名、地名、时间等实体要素的算法。近年来,基于神经网络的命名实体识别方法被相继提出,其主要思路是先使用卷积神经网络(Convolutional Neural Network,CNN)、循 环 神 经 网 络(Recurrent Neural Network,RNN)等网络结构提取序列隐含特征,然后利用条件随机场(Conditional Random Field,CRF)求解最优序列[2-6],这些算法较经典统计学习方法,如隐马尔可夫模型(Hidden Markov Model,HMM)、条件随机场模型(Conditional Random Field,CRF)等性能上有显著提升[7]。中文命名实体与英文不同,依赖分词的方案无法解决词语错分造成的误差传递问题,而仅依赖传统字符词向量(Skip-gram、CBOW(Continuous Bag Of Words)等)的方案无法很好地解决一词多义问题[8],部分工作开始探索新型词向量表达方法。Peters 等[9]提出的ELMO(Embeddings from Language MOdel)学习训练词向量与上下文的关系函数而非词向量的方式解决上述问题;Google[10]则提出一种新型语言模型 BERT(Bidirectional Encoder Representations from Transformers),在各类NLP 任务上均达到了目前最好的结果。
本文提出的BERT-BiLSTM-Attention-CRF模型采用BERT预训练语言模型训练中文词向量,较完整地保存了文本语义信息,提升了模型的上下文双向特征抽取能力,并较好地解决了命名实体的边界划分问题;使用句子级注意力机制对文本语义信息进行编码,相比传统的BiLSTM 模型,对语义信息的利用更为充分,提升了模型对实体的识别率,模型总体命名实体识别精确率达91%。本文的另一工作在于制定了一套与警情处理相关的命名实体识别标准规范,并依据规范在脱敏数据上标注实体,建立相应的警情语料数据集。以电信诈骗为例,该模型将识别实体类别从三类(人名、地名、机构名)拓展到目前的七类(受害人名、案发时间、相关地名、诈骗方法、转账途径、损失金额、处理方法)以满足实际场景中的业务需求。
1 BERT-BiLSTM-Attention-CRF模型
模型主要由四部分构成,分别是BERT 预训练语言模型、BiLSTM 层、Attention 层以及CRF 层。模型首先利用BERT 预训练语言模型对单个字符进行编码,得到单个字符对应的词向量;接着利用BiLSTM 层对输入文本进行双向编码,在解码前使用注意力机制增加上下文相关的语义信息;最后将包含上下文信息的语义向量输入CRF 层进行解码,CRF 层可以输出概率最大的标签序列,从而得到每个字符的类别。
为提升训练速度,并确保词向量编码具有足够丰富的表征能力,该模型使用的词向量是在1998 人民日报语料库上预先习得的。模型整体结构图1 所示:其中X1,X2,…,XN表示输入词向量;紧接着的为BERT 预训练语言模型层,主要由两组Transformer 构成;H1,H2,…,HN表示BiLSTM 层的隐含向量;Uchar表示Attention 层的加权函数,用于计算两两单词之间的关系权重;V 为加权后的拼接向量;接下来的部分为CRF层,用于计算每个输入向量的实体类别标签,如地址(LOC)、人名(NAME)等实体类别,其中“B-”表示实体开头,“I-”表示实体除头以外部分。
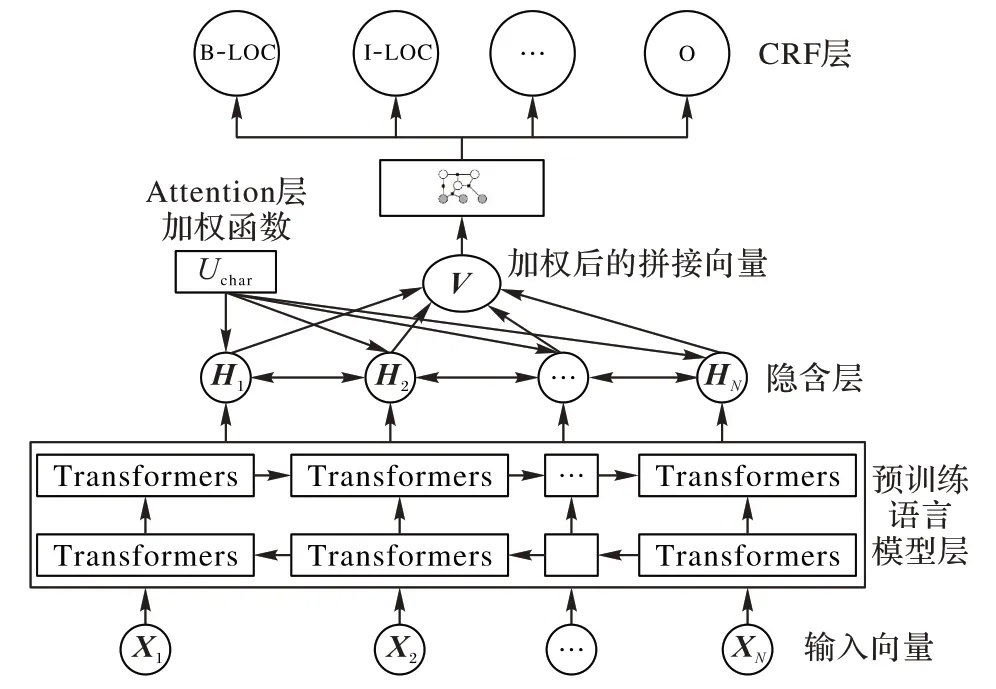
图1 BERT-BiLSTM-Attention-CRF模型Fig.1 BERT-BiLSTM-Attention-CRF model
1.1 符号约定
本文设定wq、wk、wv分别为权值矩阵的q、k、v 维,Q、K、V为权值矩阵,W 为偏置矩阵,x、h 为输入向量和隐向量,b 表示偏置量,P、A为转移矩阵。
1.2 BERT预训练语言模型
语言模型(Language Model,LM)是自然语言处理领域的一个重要概念,简单来说,语言模型是计算任意语言序列w1,w2,…,wn出现概率p(w1,w2,…,wn)的方法,即:

神经网络语言模型(Neural Network Language Model,NNLM)最早是Bengio等[11]于2003年提出的,它是关于计算给定序列情况下后一个词语出现概率的方法。在由词w1,w2,…,wT构成的句子组成的训练集中,神经网络语言模型的目的是学到下面的语言表征模型:
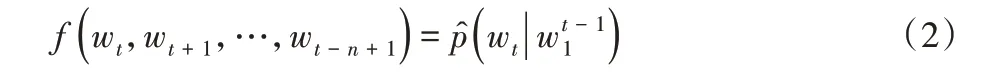
传统语言模型是静态的,无法根据上下文很好地表征字词的多义性等,针对这个问题,本文采用了BERT 预训练语言模型,结构图如图2 所示,E1,E2,…,EN为模型的输入向量,T1,T2,…,TN为模型的输出向量。
图2 BERT预训练语言模型Fig.2 BERT pretraining language model
BERT 预训练语言模型采用双向Transformer 作为特征抽取器,与传统循环神经网络相比,可以获取更长的上下文信息,提升了特征抽取能力;同时,该模型改进了常见的双向语言模型,转而使用上下文融合语言模型,该语言模型不再是简单地将从左到右和从右到左的句子编码简单拼接起来,而是随机遮挡部分字符(默认遮挡15%字符,以下称token),训练中损失函数只计算被遮挡的token。遮挡方法如下:
1)80%被遮挡词用符号masked token代替;
2)10%用随机词替换;
3)10%不变。
每个字符对应的词向量由三个向量组成,分别是Token Embeddings、Segment Embeddings 和Position Embeddings。其中,Token Embeddings 为词向量,第一个词为cls,用于下游的分类任务;Segment Embeddings 用于区分不同句子,便于预训练模型做句子级别分类任务;Position Embeddings 是人为给定的序列位置向量。示意图如图3所示。

图3 BERT预训练语言模型的词向量构成Fig.3 Word vector composition of BERT pretraining language model
此外,增加了句子级别的训练任务。该项任务是在预训练模型中加入了一个二分类模型,学习句子之间的关系。具体做法是随机替换部分句子,利用上一个句子对下一个句子做“是或否”的预测。
BERT 预训练语言模型使用的Transformer 特征抽取器[12],Transformer是目前自然语言处理领域流行的网络结构,每个单元仅由自注意力机制(self-Attention)和前馈神经网络(Feed Forward Network)构成,单元可以连续堆叠。其结构图如图4所示。
Transformer 中最重要的结构是自注意力机制模块,结构如图5,图中MatMul表示矩阵相乘运算。
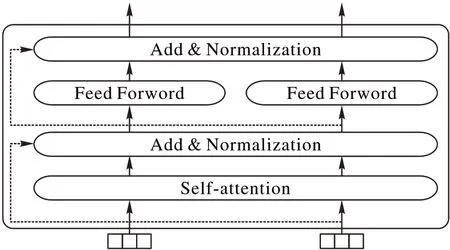
图4 Transformer特征抽取器结构Fig.4 Structure of feature extractor Transformer
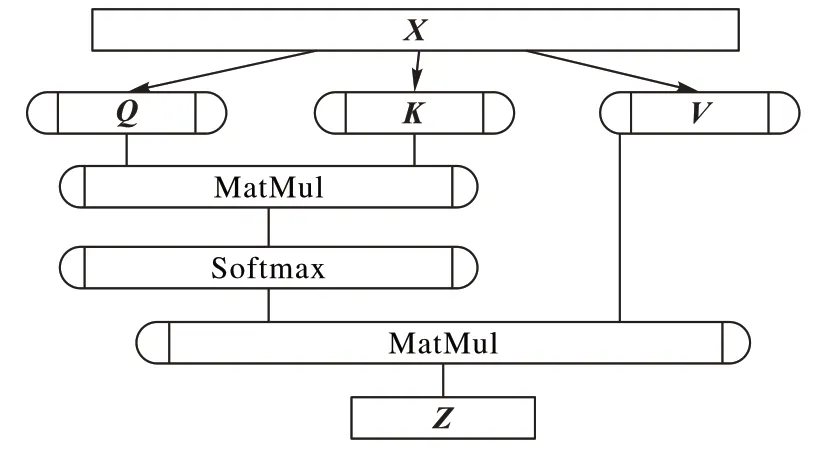
图5 自注意力机制示意图Fig.5 Schematic diagram of self-attention mechanism
在自注意力机制中,每个词对应3 个不同的向量,它们分别是Query 向量(Q)、Key 向量(K)和Value 向量(V),长度相同,由嵌入向量乘以三个不同的权值矩阵wq、wk、wv得到。
每个词的重要度score由Query向量和Key向量相乘而得:

Attention 值通过使用SoftMax 对score作平滑而得,平滑后的结果与Value向量相乘:
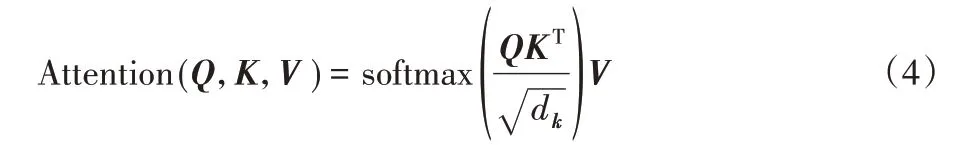
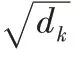
实际使用中,一般先通过注意力机制计算注意力包含注意力的编码向量Z,然后将Z 送入前馈神经网络层,用作训练下游任务,即:
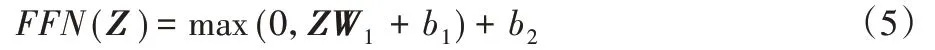
BERT 预训练模型使用了由多个自注意力机制构成的多头注意力机制(multihead-attention),用于获取句子级别的语义信息。

为解决深度神经网络训练困难的问题,Transformer 模块还使用了“短路连接”[13]和“层归一化”[14]方法,见图4 虚线部分。“短路连接”是残差网络中常使用的方法,它的思路是将前一层信息无差地传递到下一层从而解决深度神经网络中梯度消失问题;“层归一化”是指对每一层的激活值进行归一化处理,这样可以加速模型训练过程,使得模型尽快收敛。
1.3 BiLSTM层
循环神经网络(RNN)[15]是神经网络中一类重要的结构,自带时序性的特点使得这类网络模型在自然语言处理、序列预测等领域具有广泛应用。
本文使用的长短期记忆(Long Short Term Memory,LSTM)神经网络[16]结构是对传统RNN 结构作了较大改进。LSTM 神经网络是指一类具有记忆单元的循环神经网络,由Schmidhuber在1997年提出。
每个LSTM 单元里最重要的是门控单元I-gate、F-gate 和O-gate,分别称作输入门、遗忘门和输出门,均使用前一时刻的隐藏单元与当前时刻信号作为门控单元的输入,利用Sigmoid函数进行非线性激活,更新方式如下:
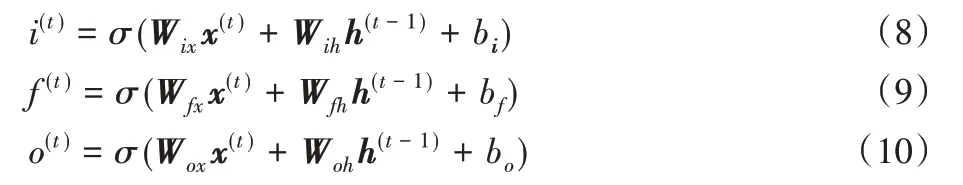
其中:c(t)为LSTM 中的记忆信息,由两部分组成,分别为遗忘门f 控制的历史信息与输入门i 控制的当前信息。更新方式为:
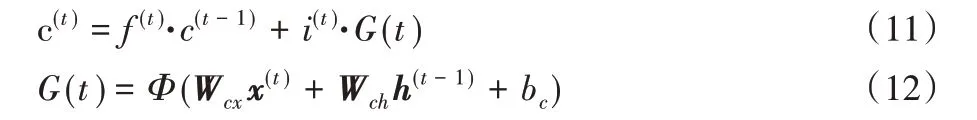
隐藏单元的更新由输出门o和记忆信息c(t)决定,即:

传统单向循环神经网络结构只能捕捉序列的历史信息,而序列标注等任务中每个字的标签与上下文联系同样紧密。受 此 启 发,Graves 等[17]提 出 了 双 向 循 环 神 经 网 络(Bidirectional RNN,BRNN)结构,该模型成功地应用于实体识别中,并取得了当时最好的结果。后续,Graves 等[18]提出了BiLSTM 这一改进模型,进一步提升了模型利用上下文信息的能力,在语音识别、词性标注、实体识别等领域得到了大规模应用。
1.4 Attention层
Attention 层主要是用来获取上下文相关的语义信息,经过编码的隐向量包含丰富的上下文信息特征,然而这些特征具有相同的权重,因此区分实体种类时,存在较大误差。Attention机制将对得到的每个词向量xi,通过

分配权重αi,其中S 表示由x1,x2,…,xn构成的句子。在Attention 中,每个字符的距离都为1,字符之间的相关性通过权重αi体现,便于划分词语边界,从而解决字符级数据集词语边界难以区分的问题。
1.5 CRF层
条件随机场是序列标注任务中的一种常见算法[19],因此可以用于标注实体类别。序列标注模型中常使用的是线性链条件随机场,是一种根据输入序列预测输出序列的判别式模型。对 于 指 定 序 列X(x1,x2,…,xn),其 对 应 标 签 为Y(y1,y2,…,yn),若满足下列条件:
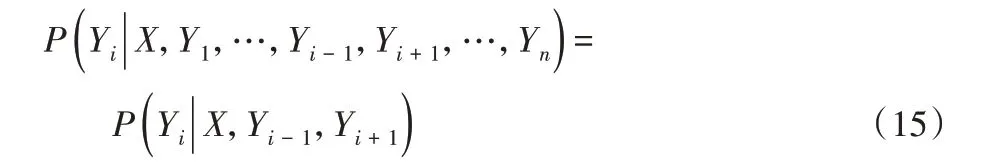
设P(N,K)为解码层输出的权重矩阵,进而可以得出评估分数S(x,y),即:

其中:A为转移矩阵,k为标签个数,n为序列长度。
序列标签y的最大概率可以用SoftMax函数计算,即:
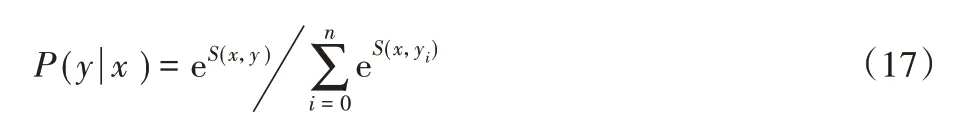
训练时一般使用极大似然法求解P(y|x)的最大后验概率:
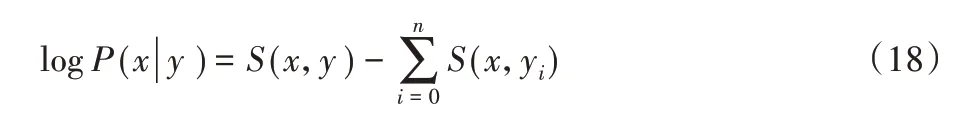
线性条件随机场的训练和解码一般使用Viterbi算法[20]。
2 数据标注规范及评估方案
本文使用的数据集由10 万字左右的电信诈骗相关接处警文本构成。识别的实体为:报警人姓名、报警时间、相关地点、诈骗手段、诈骗金额,诈骗途径(包括转账方式等)和处理方式。
2.1 标注规范
数据的标注采用BIO 三段标记法:对于每个实体,将其第一个字标记为“B-(实体名称)”,后续的标记为“I-(实体名称)”,对于无关字,一律标记为O。相比BIOES 五段标记法,BIO 三段标记法最大的优点是支持逐字标记,BIOES 法需要将单字标为“S(Single)”,而这需要先对数据进行分词处理,容易将分词产生的误差向下传播,影响模型最终效果。
以电信诈骗为例,结合例子说明命名实体的标注规范。
相关人名 将警情文本中的人名信息,例如“张某某”,“冒充宋清云经理”中的“宋清云”按<相关人名>相关的人名</相关人名>方式标注。
相关时间 将警情文本中的时间信息,例如“2018年9月15日”“上午7点左右”“国庆节那天”等,按照<相关时间>相关的时间</相关时间>方式标注。
相关地点 警情文本中的地点信息较为杂乱,例如“江南造船厂附近”“光瑞路2 号”“鼓楼区”“长山花园5 号”,包括小区、各类道路、各种建筑物等名称,按照<相关地点>相关的地点</相关地点>方式标注。
诈骗手段 诈骗手段描述较长,例如“帮忙办理信用卡……”“以交辅导费为由,让……”“冒充其老板向其借钱”等,均标记文本中的首句缘由部分,例如上面三个例子依次标记“办理信用卡”“以交辅导费为由”“冒充其老板”部分。
诈骗金额 不仅要记金额数值,还需要将数值的单位标记出来,例如将“300 元”“十万元人民币”“一百块钱”等按<诈骗金额>诈骗的金额</诈骗金额>方式标注。
诈骗途径 诈骗途径主要包括转账途径一类的信息,例如将“通过中国银行转账”“支付宝转账”“微信转账”等按<诈骗途径>转账的途径</诈骗途径>的规则标注。
处理方式 将警情文本中的处理方式按<处理方式>具体处理方式</处理方式>。
标记好的数据处理后共分16 大类,分别为B-Name、I-Name、B-Time、I-Time、B-Location、I-Location、B-Reason、I-Reason、B-Money、I-Money、B-Measure、I-Measure、B-Deal、I-Deal、O 和<Padding>。为保证训练时采用的长度一致(256×1维),额外添加了一个占位符<Padding>。
2.2 评估标准
命名实体识别的评价标准主要包括精确率(P)、召回率(R)和F 值,并定义Tp为模型识别正确的实体个数,Fp为模型识别到的不相关实体个数、Fn为模型没有检测到的相关实体个数。具体公式如下:
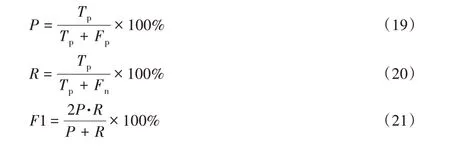
3 实验及结果分析
3.1 实验环境
所有实验采用的环境如表1所示。

表1 实验环境Tab.1 Experimental environment
3.2 参数设置
本文使用的主要参数包括:BERT预训练语言模型默认使用12 头注意力机制的Transformer,预训练词向量长度为768维;单个处警文本长度多位于160~300 字,故每次读取的序列长度为256,每批次大小为64;优化器采用的是Adam[21],学习率设置为5×10-5,实验结果显示较小的学习率有助于模型找到最优解;丢弃率[22]为0.5;为缓解梯度消失和爆炸的影响,LSTM 隐含单元设为128,层数为2;还使用了梯度裁剪技术,clip 设置为5;Attention 层参数为64,即每个词向量被压缩为64 维;经过CRF 层的全连接层参数为16,即分为16 类,每类为16×1维的one-hot向量。
3.3 结果分析
为验证模型的有效性,主要进行了四组对比实验,使用的模型分别为CRF++、BiLSTM-Attention-CRF、BiLSTM-CRF 和BERT-BiLSTM-Attention-CRF。
其中,CRF++模型使用的是线性立链条件随机场算法,采用单字匹配的模式,原理是利用特征函数构建特征方程,特征函数主要包括句子s、词在句中的位置i以及前一个词、后一个词的标签;使用梯度下降法训练,解码时使用Viterbi 动态规划法。
BiLSTM-CRF 是深度学习领域比较有代表性的序列标注模型,实验中采用的是基于字符标注的版本,字向量是采用CBOW 在警情语料上预先训练好的,每个字向量为128×1维。
为了比较Attention 在句子语义编码中的作用,本文设计了包含Attention 机制的BiLSTM-Attention-CRF 模型与BiLSTM-CRF 模型进行对比,除Attention 层以外,其他参数设置均相同。
本文设计的BERT-BiLSTM-Attention-CRF 模型采用的字符向量是利用BERT 模型在大规模中文语料上预训练好的,字向量为128×1维。
BERT-BiLSTM-Attention-CRF 模型的损失函数曲线如图6所示,其中:val-loss 表示验证集交叉熵损失值;loss 为训练集交叉熵损失值。由于采用的是Adam 优化器,它可以根据训练过程自动地调节学习率,损失函数曲线有较为明显的阶段性特征。
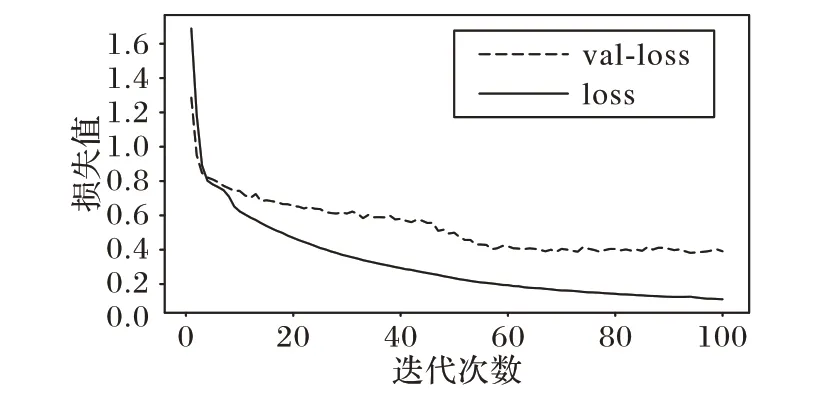
图6 验证集与训练集损失函数曲线Fig.6 Loss curve of validation set and training set
三组实验的结果如表2所示。
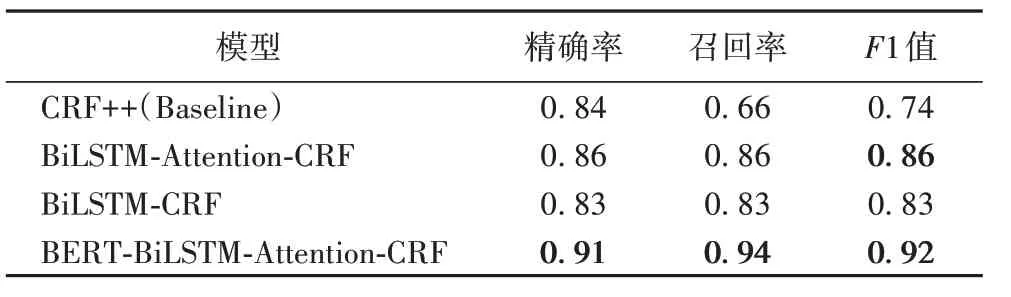
表2 各个模型的命名实体识别结果Tab.2 Results of named entity recognition of each model
本文对比了各个模型在测试集上的具体表现,各类实体标记结果方式如下,其中XX 表示文字,下划线用于标识各类实体。

CRF++标记结果如下:

BiLSTM-Attention-CRF标记结果如下:

BiLSTM-CRF标记结果如下:

BERT-BiLSTM-Attention-CRF标记结果如下:

由上述结果可以看出,CRF++模型无法准确抽取实体边界信息,甚至有错抽和误抽的情况。这主要是由于CRF++模型的实体抽取建立在分词基础上,而时间、地点包括姓名一类的实体均属于未登录词范畴,模型对这一类的未登录词识别较弱。BiLSTM-Attention-CRF 模型相比BiLSTM-CRF 和CRF++,在实体识别上准确率较高,边界划分也更为准确,但对于“诈骗途径”这类实体的识别较差;本文模型对实体边界的划分较以上模型更为准确,例如可以将地点信息“北京”“广州”准确抽取出来,且对“诈骗手段”的识别也较为灵活,不拘泥于部分常见词语,而将相关的语义信息全部标记出来。
根据表2,本文提出的BERT-BiLSTM-Attention-CRF 模型准确率比CRF++的基准模型高7%,F1值高0.18,表明神经网络在特征抽取能力上比传统统计学模型要更强;与BiLSTMAttention-CRF 模型相比,准确率提升了7%,表明BERTBiLSTM-Attention-CRF 模型使用的BERT 词向量预训练模型较word2vec 训练的一类静态语言模型,在把握语义方面更加精准,对于实体识别等自然语言处理任务的性能提升有较大影响。
在测试集上的实验表明,使用Attention 机制在语义编码时效果最佳,如BERT-BiLSTM-Attention-CRF模型不仅可以准确地抽取姓名要素,对地点、时间等实体的抽取也更为灵活,“从南京到广州”远比“南京”“广州”语义信息丰富,对于较复杂的原因类实体,也可以得到“运输信息,谎称”的字样,比单纯的“谎称”要更为实用。
BERT-BiLSTM-Attention-CRF 模型对各类实体的识别率见表3。
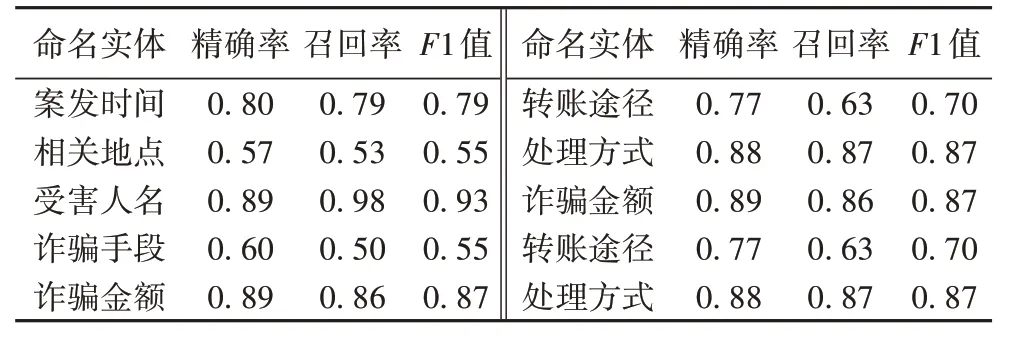
表3 各类实体的识别率Tab.3 Recognition rate of different named entities
本文提出的模型对于案发时间、受害人名、诈骗金额以及处理方式这四类实体具有较高的识别率和F1 值,对相关地点、诈骗手段、转账途径等实体识别率较低,这主要是因为这些实体描述方式过于多样,难以找到通用规则表述,例如相关地点中包括住宅地址、公司名、广场名等多种类型,找出一个通用规则的方法尚不理想。这些问题可以通过对各个实体类别作进一步细分来解决。
4 结语
基于BERT 的命名实体识别模型与传统模型相比,在准确率、召回率和F1 值上均有较大程度的提升,对报警文本中的常见实体例如案发时间、受害人名、处理方式等具有较高的识别率,可以满足部分业务需求。为进一步提升模型的性能,后续可以从细化、完善各类实体的标记规则和拓展语料规模等方面着手。
由于命名实体的分布数目分布不均匀,单纯地使用各个实体权重相同的损失函数进行训练效果不是很好,可以设计基于各类实体数目分布的加权损失函数进一步优化,提升部分稀疏实体的识别率。
猜你喜欢
中老年保健(2022年5期)2022-11-25
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
作文大王·低年级(2019年10期)2019-11-25
当代陕西(2019年5期)2019-03-21
学生天地(2018年19期)2018-09-07
21世纪商业评论(2018年3期)2018-03-02
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
高中生学习·高三版(2016年9期)2016-05-14
