
基于联合损失函数的小规模数据人脸识别
2020-04-07 02:28张欣彧尤鸣宇朱江韩煊
北京理工大学学报 2020年2期
张欣彧, 尤鸣宇, 朱江, 韩煊
(同济大学 电子与信息工程学院,上海 201804)
近年来,深度神经网络的发展促进了人脸识别的快速发展[1],这得益于庞大的人脸数据集和独特的模型设计. 目前,多个大规模人脸数据集已经公开,如VGGFace[2]、Ms-Celeb-1M[3]. 网络模型呈现出越来越深、宽的趋势. 同时,损失函数的设计也极大地提高了网络的判别能力,如DeepID系列[4-6]将识别和验证信息进行同时优化,CenterLoss[7]对每一类学习一个类中心,A-Softmax[8]利用大角度间隔将类别分开. 这些方法的共同点在于将类间距离拉大,类内距离缩小,从而提高模型的分类性能.
然而,这些方法均在大规模公开数据集上训练、测试. 针对现实生活中小规模人脸数据集,此类方法存在以下3个问题:① 公开的大规模人脸数据集多数为名人明星的照片或截取的视频帧,且欧美人居多,多变性较差. 在实际应用中,由于人种、光照、年龄、遮挡、姿势等问题,使得人脸识别更具有挑战性. ② 现有方法均在深度神经网络上进行训练,模型参数较多. 然而,直接在模型上训练小规模人脸数据集容易陷入过拟合,泛化能力较差. ③ 现有的方法均在公开数据集上测试,其在小规模数据集上是否有效尚未可知.
针对以上问题,本文做了如下工作:① 评估了不同后处理方法在小规模数据集上的应用效果,证明在小数据集上,传统后处理方法仍能在一定程度上提升特征的表征能力. ② 提出基于联合损失函数的小规模数据深度神经网络重训算法,提高深度神经网络在小规模人脸数据集上的泛化能力. ③ 通过实验表明,使用本文方法重训后,模型在学校2017级新生数据集上达到95.32%的Top1检索精度,97.83%的Top5检索精度.
1 小规模数据学习常用的特征后处理方法
传统特征后处理方法是从预训练网络中提取图片特征,将特征通过传统方法使得其映射到另一空间中,达到在新的空间中具有最小的类内距离和最大的类间距离,从而提高特征的判别能力. 本文对比了3种后处理方法,分别为LDA(线性判别分析)、LMNN (大间隔最近邻)和Joint Bayesian(联合贝叶斯,简称JB),后文会具体分析各方法的实际应用效果.
2 基于联合损失函数小规模数据深度神经网络重训算法
本文提出基于联合损失函数的小规模数据深度神经网络重训算法,即结合在大规模人脸数据上训练得到的深度神经网络与现有的优化损失函数,在小规模数据集上进行重训,使其泛化到最优的效果.
2.1 模型结构
本文采用CenterLoss的模型结构,并在分类层之前加入DeepVisage[9]提出的特征归一化模块. 该网络结构应用于大规模人脸数据集的预训练过程及小规模人脸数据的重训过程.
该模型结构共有27个卷积层,4个池化层和1个全连接层. 每一个卷积核都是3×3的大小,激活函数使用PReLU. 本文采用2×2的最大池化层,512维输出的全连接层. 归一化模块加在分类层之前. 归一化后的特征为本文所采用的人脸表征特征.
具体模型结构如图1所示,其中,ResBlock结构块为残差结构,具体结构见图2.
2.2 损失函数
2.2.1Softmax损失函数
Softmax是最常使用的损失函数,具体公式如下
(1)
(2)
式中:F(xi)为第i个样本的特征;wk和bk为第k个类别的权重和偏置;N和K分别为批训练样本的数目和类别的数目.
2.2.2CenterLoss损失函数
CenterLoss对每一个类学习一个类中心,用于缩小单个样本特征和类中心特征之间的距离,使同类别的特征更加聚集,不同类别的特征更加分离. 具体公式如下
(3)
式中:F(xi)为第i个样本的特征;Cyi为第i类的类中心,类中心是通过训练得到的.
2.2.3A-Softmax损失函数
A-Softmax通过几何分析Softmax,该方法将原先的距离问题转变为角度问题,引入权重归一化为1的限制条件,提出分类的边界可由权重和特征之间的角度来决定,通过角度间隔参数,控制类间的角度大小. 具体公式如下
(4)

2.2.4联合损失函数
联合损失函数将多类损失函数结合,起到联合优化的效果. 本文采用Softmax和CenterLoss或A-softmax联合优化方法,使得网络在多个函数的优化下,提高其表征能力. 具体公式如下
L=LS+γLA/C,
(5)
式中:γ为损失函数权重,当γ=0时为Softmax函数,当γ≠0时为联合损失函数.
2.3 基于联合损失函数小规模数据深度神经网络重训算法
本文提出的方法在小规模人脸数据的迁移训练中使用联合损失函数,代替在大规模人脸数据的预训练过程中所使用的Softmax损失函数. 具体训练步骤如下所示.
① 利用Softmax函数,在大规模公开数据集上训练人脸分类模型. 得到预训练的深度神经网络结构.
② 利用联合损失函数,在上述深度神经网络上进行小数据集的重训练,保证所有层都能够有效训练,得到迁移学习后的新的网络结构.
③ 通过②得到的模型结构提取小数据集的特征,进行人脸识别精度计算.
3 实验结果与分析
3.1 训练细节
3.1.1大规模公开人脸数据
采用该数据清洗后的Ms-Celeb-1M作为训练数据,并保留类别数目大于30的数据. 经过处理后,该数据集共有60 042类,4.36百万张人脸图片.
本文采用LFW、YouTube作为公开测试数据集. LFW测试集共有6 000对人脸,分在10个文件夹中. 每个文件夹中包含300对同一个人的人脸对,300对不同人的人脸对. YouTube测试集共有500个视频人脸对,其中250个为相同人视频对,250个为不同人视频对,并均分在10个文件夹中.
3.1.2学校新生人脸数据
本文收集了2015,2016和2017年的新生人脸数据,该数据集全部为证件照片,每个人共采集3张照片,分别为入学采集照片、身份证照片和高考照片. 采集到的2015级新生共有3 542人,2016级新生共有4 021人,2017级新生共有4 290人. 在本文中,2015级和2016级新生结合起来作为小规模数据的训练集,2017级新生数据作为测试集.
该数据虽都是证件照,但是具有多变性,具体有如下几点:① 身份证在强光条件下拍摄,照片肤色偏白,入学采集照片和高考照片在大厅里拍摄,照片肤色偏暗;② 身份证年龄相比较剩下两者较年轻;③ 身份证采集时要求不能佩戴眼镜、首饰、头发不能过耳朵等,在高考和入学采集时没有此项要求;④ 不同阶段妆容变化较大,特别是女生.
3.1.3模型训练细节
本文采用MTCNN预训练方法,在Ms-Celeb-1M数据集中,如果该方法不能有效检测出关键点,则将该图片剔除掉. 随机翻转用于图片增强. 采用随机梯度下降进行优化. 在训练大规模数据集时,学习率从0.1开始,每70 000次迭代后下降10倍,共训练210 000次迭代. 在重训学校新生数据时,学习率从0.000 1开始,每2 000次下降10倍,共训练5 000次.
3.1.4模型评估标准
在公开数据集LFW和YouTube上,本文进行1对1验证评估. 通过10倍交叉验证,得到验证准确度.
在学校2017级新生数据集上,本文采用人脸检索评估. 针对每一个2017级新生的入学采集照片,计算其与同级每个人的身份证和一卡通照片的相似度,将两者的均值作为最终相似度. 本文评估检索到的前1名、前5名、前10名是否包含与待检索图片相同身份的人.
3.2 大规模数据预训练结果
对比了在相同Ms-Celeb-1M训练数据集的情况下,不同模型结构在公开测试数据集的表征能力. 结果如表1所示.
表1 不同模型结构在公开数据集上的结果

Tab.1 Results of different model structures on the public test datasets%
从结果中可以发现,本文使用的模型结构在公开数据集上具有很强的表征能力. 在LFW测试集上,DeepID2+和A-Softmax较本文模型复杂度更高. 在YouTube数据集上,本文的模型达到了最佳的效果.
在学校新生数据集上,直接使用上述预训练模型进行人脸检索,检索精度结果如表2所示. 其中,不同年级之间无交叉,即分别进行检索,如2015级的新生在2015级的数据集中进行人脸检索. 该评估方法符合实际的新生报到的应用场景.
表2 大规模数据模型在学校新生人脸的检索结果
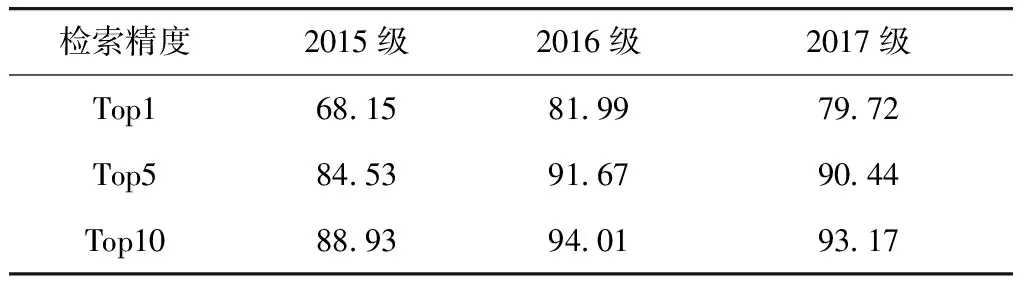
Tab.2 Retrieval results of model trained on large-scale datasets on school freshmen dataset%
从表2中可以看出,即使在公开数据集上表现良好,直接应用在小规模数据集上效果却仍然很差,究其原因,是学校新生数据集与公开数据集之间存在着较大的差别.
3.3 学校新生数据后处理结果
3.3.1在小规模数据集上进行特征后处理
用大规模数据预训练模型提取学校新生数据特征. 将2015级和2016级新生图片的特征作为后处理方法训练集,共7 563类,每类各3张图片. 2017级新生的特征作为测试集.
本文评估了LDA、LMNN和JB 3种方法. 在保证特征维度为512维的情况下,3种方法在2017级新生图片上的结果如图3所示.
从图3可以看出,特征后处理方法可以很大程度上提高特征的表征能力. JB可以将检索精度的Top1从79.72%提高到97.13%,提高了17.41%. 经过特征后处理,除LDA外,LMNN和JB均在Top1的结果上超过了直接使用大规模数据模型Top5的结果. 由此可见,特征后处理能够很好地提高特征在目标领域的表征能力.
3.3.2在小规模数据集上重训
迁移学习中常用的方法是直接在小规模数据集上进行重训,即固定全连接层前所有层的参数,只训练全连接层和分类层,从而减少需要学习的参数,使得网络能够在小规模数据集上拟合. 本文采用2种重训的方法,第1种为固定全连接层前所有层参数,训练全连接和分类层;第2种为全部层均进行训练,分类层学习率为其他层的10倍. 实验结果如表3所示.
表3 不同重训方法在2017级新生人脸的检索结果

Tab.3 Retrieval results of 2017 freshmen face dataset with different finetune methods%
从表3中可以看出,同时重训所有的层和只训练后2层的效果差别不大,且前者略微低于后者,可见在小规模重训过程中,全连接层包含了大部分的判别性特征,重训所有层反而增加多余参数. 将表3与图3相比较,可以看出,只在模型上进行小规模数据重训,效果会远低于传统方法,例如重训FC+分类层的效果在Top1上比联合贝叶斯后处理低9.41%.
3.4 基于联合损失函数的小规模数据集重训结果
在学校新生数据集上利用联合损失函数在预训练模型上进行重训. 本文分别采用CenterLoss-Softmax(CS)和A-Softmax-Softmax(AS)联合优化函数,其中在CS中,γ取0.01,在AS中,γ取1,间隔超参数m为4. 实验具体结果如表4所示.
表4 基于联合损失函数的重训模型在2017级新生数据的检索结果

Tab.4 Retrieval results of 2017 freshmen face dataset with finetune models based on joint loss functions%
从表4中可以看出,使用联合损失函数在小规模数据集上进行重训,能够有效提升检索精度. AS可以将Top1精度从79.72%提高到95.31%,超过了LDA、LMNN后处理方法. 虽然比JB的检索精度低,但是训练过程简单,易于实现.
3.5 讨 论
3.5.1与Face++对比
因Face++的开源API不稳定,且进行一次相似对对比平均需要2.02 s,因此本实验选取2017级人脸数据的100个人上进行测试,且将入学采集人脸作为检索数据,将身份证照片作为数据库. 检索结果如下.
从表5可以看出,在100个人的检索结果中,Face++有2个人的检索不在Top10的范围内,但CS仅1人未检索到Top5的范围内,AS的效果在Top5上已经能达到100%的检索精度效果. 因此,本文的基于联合损失函数的小规模数据集算法能够有效提升检索效果.
表5 在2017级新生数据的100人中基于联合损失函数的重训算法与Face++的检索结果对比
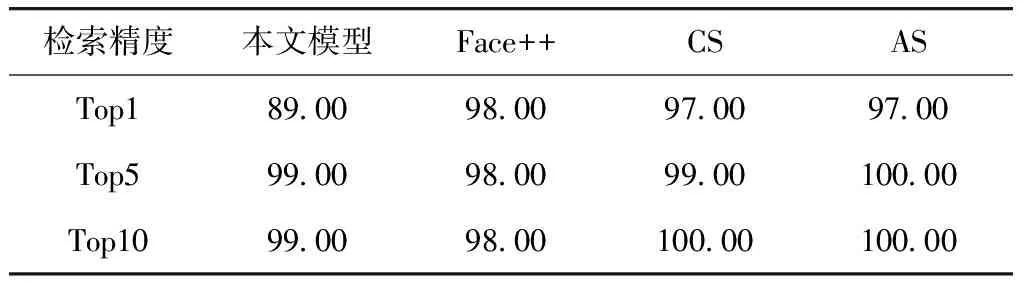
Tab.5 Comparison with finetune methods based on joint loss functions and Face++ on 100 identities in 2017 freshmen dataset%
3.5.2损失函数权重γ取值
γ取值不同,会对最终的模型效果产生影响,为了选取最佳的γ值,本文进行了一系列对比实验,结果如表6及表7所示,其中“-”表示模型不收敛,结果均在2017级数据集上测试.
表6 不同γ取值在CS联合损失函数的重训模型上的检索结果

Tab.6 Retrieval results of different finetune models with CS joint loss functions with different values of γ%
表7 不同γ取值在AS联合损失函数的重训模型上的检索结果

Tab.7 Retrieval results of different finetune models with AS joint loss functions with different values of γ%
从表6与表7中可以看出,在CS中,γ=0.001时Top1可达93.92%.γ越大,效果越差,到γ=1时模型不收敛. 在AS中,γ=1时最好,Top1可达95.31%,同样γ越大,效果越差,γ=1 000时,Top1只有72.14%,比在预训练模型的79.72%低7.58%. γ=0.1时模型不收敛. 因此,γ的取值对于联合损失函数模型的重训效果有很大的影响. 本文接下来的工作即研究通过训练得到适合本模型的最优γ取值.
3.5.3角度间隔超参数m取值
本文同时研究了在AS联合优化函数的作用下,角度间隔超参数对于小规模数据集重训的影响. 分别使用m=1和m=4,并绘制了训练过程中2017级新生数据上的检索结果,如图4所示.
从图4中可以看出,随着迭代次数不断增加,检索精度不断升高,并从3 000次循环开始保持平稳.m=4比在m=1的情况下,模型收敛更快,精度更高. 因此,角度间隔更有利于提高小规模数据集重训的收敛速度和精度.
4 结 论
本文提出了基于联合损失函数的小规模数据深度神经网络重训算法,即在大规模数据集上训练好的模型上,使用联合损失函数作为监督,在小规模数据集上进行重训. 该方法能够充分训练模型结构中所有参数,很大程度提高深度神经网络在小规模人脸数据集上的泛化能力. 同时,本文对比了多种特征后处理方法和重训方法,实验表明,本文方法能够在学校新生数据集上达到较好的实验效果. 此外,本文还讨论了模型参数的选择,通过实验证实了超参数的选择对模型的效果有很大的影响. 本文的方法为后续小规模数据人脸识别的研究提供了启发,同时也能够促进深度神经网络在实际场景中的进一步应用.
猜你喜欢
计算机研究与发展(2022年1期)2022-01-19
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
奥秘(2021年5期)2021-06-15
计算机应用(2020年12期)2020-12-31
科教新报(2020年35期)2020-12-28
科教导刊(2020年27期)2020-11-09
留学(2019年14期)2019-08-23
中国总会计师(2017年10期)2017-12-13
文苑(2015年9期)2015-09-10
