
基于XGBoost的火电机组污染物排放预测研究
2020-04-06 04:45:34李钟钦
发电设备 2020年2期
周 虹, 陈 斌, 李钟钦, 高 飞
(1. 上海漕泾热电有限责任公司, 上海 201507;2. 上海发电设备成套设计研究院有限责任公司, 上海 200240)
2017年火电机组发电量占全国总发电量的70%以上,目前火力发电在我国发电结构中依然占据主导地位,但是火力发电过程中会排放出大量的粉尘、SO2及NOx等污染物[1-2]。随着我国电力体制改革的不断深化和节能减排的不断推进,发电厂越来越重视污染物排放控制[3-4]。
污染物排放预测是控制污染物排放的一项重要工作,机组运行人员可以根据预测的污染物排情况来进行机组生产调度,及时降低污染物排放量[5-7]。
在现有的对污染物排放预测的研究中,学者分别从污染物排放的时序数据和特征、当前时刻机组运行的状态等角度出发,探索不同方法在预测机组污染物排放方面的效果。任玉珑等[8]使用Rains-Asia模型,从宏观角度对西部地区未来10 a的SO2排放进行预测并提出相应建议。张书豪[9]基于灰色理论结合BP(Back Propagation)神经网络模型和灰色模型(GM),提出了以GM(1,1)、GM(0,4)及BP神经网络为主要结构的污染物排放预测模型。苏银皎等[10]提出使用改进小波神经网络模型预测火电厂污染物的排放,并优化了特征提取方法,提升了神经网络的输入特征数据性能。杨训政等[11]将深度学习中的长短期记忆(LSTM)网络算法应用于污染物排放预测,同样获得不错的效果。梁肖等[12]基于LSTM网络算法,使用了配对的遗忘门和输出门,优化了LSTM网络算法的神经元结构,提出将改进型的LSTM循环神经网络(ALSTM-RNN)算法用于火电机组污染物排放预测。
上述文献所使用的方法是针对污染物排放时序数据进行预测,然而在实际机组运行过程中,影响污染物排放的因素除了时序数据本身的特征外,还有机组出力,以及季节、天气、温度等外界环境的影响,基于数值的算法模型则无法完成此任务。笔者针对GE 9F燃气轮机(简称燃机)机组污染物排放影响因素较多的特点,提出了一种基于极端梯度提升(XGBoost)的算法,实现了污染物排放预测。
1 XGBoost算法
XGBoost算法是一种可扩展的端到端基于树的Boosting系统,是一种基于AdaBoost算法和梯度提升决策树(GBDT)算法演化而来的提升算法。
1.1 GBDT算法
Boosting分类器属于机器学习中的集成学习模型,其思想原理是利用很多个效率高但准确率相对较低的树模型整合成为一个准确率较高的模型。GBDT算法是由FRIEDMAN J H[13]于2001年提出,该算法由梯度提升和决策树整合而成。GBDT算法的具体流程是:
(1) 初始化。基于经验估计损失函数极小化的常数值。
(2) 训练。训练树的构成和参数:计算当前模型中损失函数负梯度值,作为残差的估计;估计回归树叶子节点的区域,拟合残差的近似值;利用线性搜索,估计叶子节点区域的值,目的是使损失函数达到极小化;更新回归树模型。
(3) 模型生成。满足条件的回归树模型即最终模型,输出模型。
1.2 XGBoost算法
通常来说,目标函数的优化效果决定了模型的准确性,目标函数优化效果越好,预测值就越接近真实值,模型的泛化能力也就越好。
不同于传统的GBDT算法只利用一阶导数信息的方式,XGBoost算法对损失函数进行了二阶泰勒展开,并且在目标函数外引入了正则化项从整体上求最优解,以权衡目标函数的下降程度和模型的复杂程度,避免模型的过度拟合。XGBoost算法的原理是将原始数据集分割成多个子数据集,将每个子数据集随机分配给基分类器进行预测,然后将弱分类的结果按照一定的权重进行计算来预测最后的结果。
首先,定义一个目标函数O为:
O(Φ)=L(Φ)+Ω(Φ)
(1)
式中:L为训练损失函数;Ω为正则化项;Φ为模型参数,如最大树深度、最小叶子节点权重等。
其次,确定训练损失函数和正则化项。常用的损失函数有均方根误差损失函数、log对数损失函数、指数损失函数、绝对值损失函数,由于均方根误差ERMSE对结果中特大或特小的误差反应较敏感,因此笔者选用ERMSE作为损失函数,其计算公式为:
(2)

回归树通过优化剪枝和控制数的深度来预测,其原理是控制模型的复杂度和正则化的极大似然估计。笔者所采用的正则化项也是基于这个思想,通过采用叶子节点数目T和叶节点分数的L2范数平方来定义正则化项:
(3)
式中:γ为阈值,是叶子节点数T的系数,可理解为对树做了前剪枝;λ为正则化项里叶节点分数的L2范数平方的系数,用于防止过拟合;wj是树叶上的分数向量。
根据以上训练损失函数和正则化项,可以得出预测优化的目标函数为:
(4)

(5)
式中:ft(xi)为第t棵树。
再进行二阶泰勒展开后,可以得到对于第t次的目标函数Ot(Φ)为:
(6)
对目标函数进行二次泰勒展开后可以求解的目标函数只依赖于每个数据点在误差函数的一阶导数和二阶导数,从而能更快并准确地得到最优的预测值。
2 污染物排放预测
2.1 特征提取
笔者使用的原始数据主要包括2 h内的天然气质量流量、燃机有功功率、NOx排放质量浓度、日期、外界环境参数等,用于预测未来1 h内的NOx排放质量浓度,共形成46个特征参数。部分提取特征参数见表1。
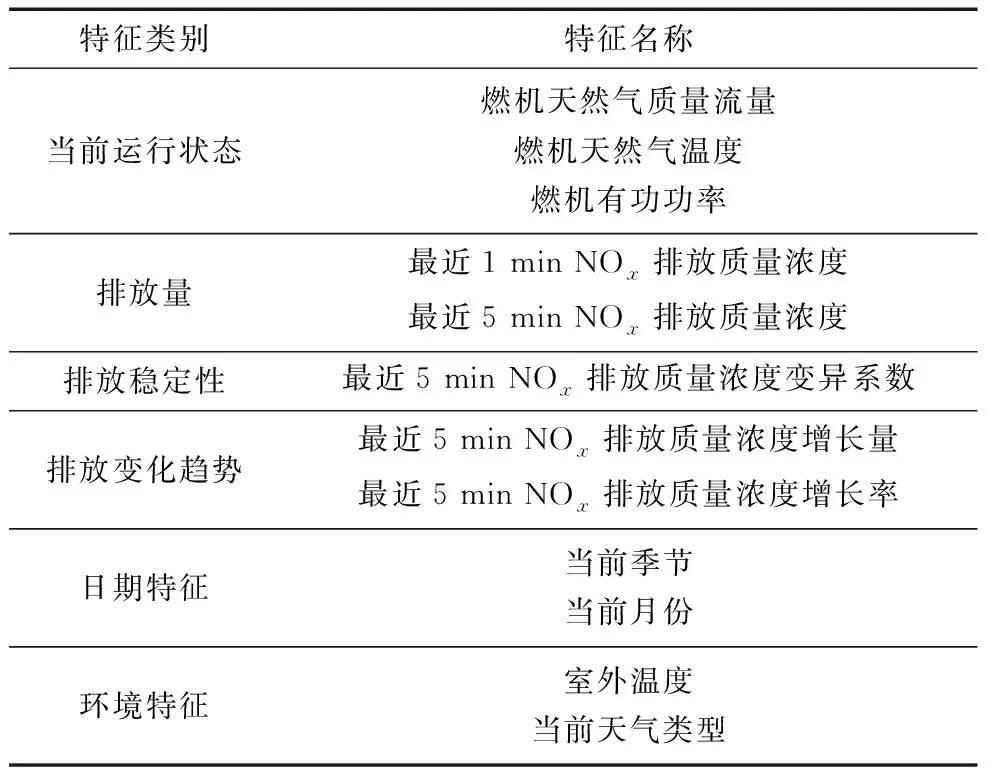
表1 部分提取特征参数
2.2 基于XGBoost算法的模型训练
对原始数据进行特征提取后,转换成独热编码的方式,将其输入到XGBoost算法模型中进行训练。算法流程图见图1。
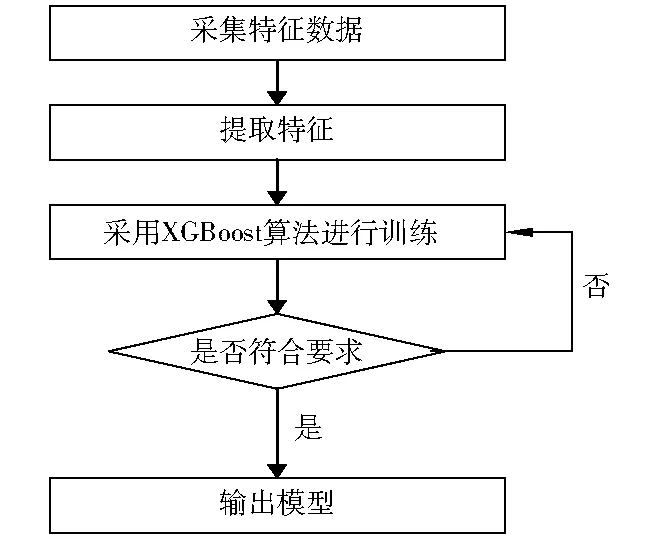
图1 算法流程图
笔者选择ERMSE作为判断预测误差的标准,若训练结果不满足需求,则不断调整模型参数重复训练,其中可调整的参数主要包括最大树深度、最小叶子节点权重、学习速率等。
3 结果及分析
笔者对比了不同参数下训练结果的差异,最大树深度对影响整个模型的复杂程度的影响见图2。由图2可知:随着训练次数的增加,ERMSE不断下降,在训练100次后基本稳定;对比不同最大树深度的差异,最大树深度取6、10、20时,随着最大树深度的增加,ERMSE不断增大,因此最大树深度最终选择在6左右即可。
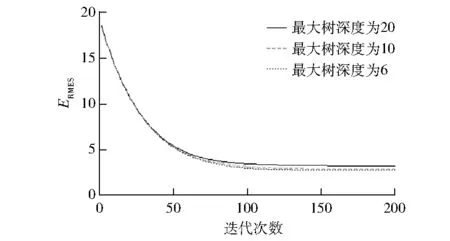
图2 不同最大树深度对应的训练结果
最小叶子节点权重可以用于防止模型过拟合,其对ERMSE的影响见表2。由表2可知:当最小叶子节点权重低于0.5时,模型ERMSE基本不变,因此最小叶子节点权重最终选择在0.3~0.5即可。

表2 最小叶子节点权重对ERMSE的影响
在最终选定模型中,最大树深度为6,学习速率为0.02,最小叶子节点权重为0.3,输入特征共15个,训练最终模型。按照重要性排列的前7个特征参数见图3。

图3 按照重要性排列的前7个特征参数
将数据按照样本数量比为7∶3进行划分训练集和测试集,NOx排放质量浓度预测结果见图5。ERMSE为2.43,平均相对误差为15.9%。
总体上,基于XGBoost算法的污染物排放预测能够满足多源数据条件下的预测需求,能够同时处理数值型和字符型的数据源,其预测结果的准确度也处于较高水平。

图4 预测值与实际值对比
4 结语
笔者针对火电机组预测污染物排放问题,提出了一种使用XGBoost算法进行火电机组污染物排放预测的方法,该方法融合了机组运行数据特征,以及季节、天气、温度等外部数据特征,建立了预测模型,针对NOx排放质量浓度的实际值和预测值进行了误差计算,最终整体ERMSE为2.43,平均相对误差为15.9%,其预测值能够为实际工作提供有效参考。
由于数据资源有限,所研究内容未涉及压气机进口空气参数等强特征参数,未来可进一步扩展数据覆盖面以提高模型泛化能力;所采用方法中特征提取部分依然依赖人为经验,特征的全面性有待提高,下一步工作将研究使用卷积神经网络模型来自动提取优化特征,并训练模型,以进一步提高预测准确度。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
今日农业(2021年11期)2021-11-27 10:47:17
国际眼科杂志(2021年9期)2021-09-15 03:24:42
河北电力技术(2021年2期)2021-07-29 09:16:36
环境科学研究(2021年6期)2021-06-23 02:39:54
环境科学研究(2021年4期)2021-04-25 02:42:02
少儿科学周刊·儿童版(2021年23期)2021-03-24 01:00:31
装备制造技术(2020年2期)2020-12-14 03:09:16
中国卫生(2015年12期)2015-11-10 05:13:34
自动化博览(2014年9期)2014-02-28 22:33:32
