
工程教育专业认证背景下的学生评教数据分析初探
2020-04-04 06:36傅思思
计算机教育 2020年2期
傅思思,王 茜,葛 亮
(重庆大学 计算机学院,重庆 400044)
0 引言
中国在2013 年6 月的国际工程联盟大会上,成为《华盛顿协议》组织的预备成员,并于2016年6 月成为该协议组织的正式成员,这标志着我国高等工程教育开始步入国际化轨道,同时也对我国工程教育提出了更高的要求[1]。“持续改进”作为专业认证的三大基本理念之一[2],是指通过建立内部质量监控、毕业生跟踪反馈、社会评价等机制,定期对教学全过程进行监督、评价和调控,形成质量闭环,全面促进专业建设和教学改革,不断提高人才培养质量。课程教学作为教学活动的基本环节,学生对课程教学的评价数据就成为“持续改进”教学实施效果的重要评价依据之一。
学生评教是指学生根据任课教师的教学方式、教学效果等多方面的综合表现,结合学生自身的收获和进步,用学校制定的评价指标,对教师的教学活动作出评价的判断活动[3-4]。学生评教最早出现于美国的高校中,自20 世纪20 年代诞生,经历了几个时期的不同发展[5]。国内高校学生评教从20 世纪80 年代中期开始在各高校开展起来,并逐步走向系列化、规范化、公开化[6]。文献[7]中分析了目前高校学生评教存在的主要问题有部分学生不能理性、客观地进行评价,对严格要求的教师打低分;对评教数据的处理不够科学,按一定比例去掉一部分数值再取平均值的办法并不能保证完全处理掉明显不合理的分数值。
传统的评教数据分析主要是对李克特量表式的学生评分进行分析[8],对教学设计与内容、教学形式、课程管理、课程考核、学习收获等方面的学生评分进行加权平均得到学生对教师教学的评分。这种做法虽然简单、易于操作,但是容易受到学生随意评分的影响。当学生随意评分时,传统的评教数据分析法很难评判学生评分的真实可靠性。学生评教中的评论文本,相对于评分数据,蕴含更多信息,且容易判断学生是否随意评教。本文方法尝试从学生评教的评论文本中抽取评教信息,构建一种新的评教数据分析方法。
1 基于自然语言处理的评教文本分析方法
本文尝试利用自然语言处理方法对学生评教的评论文本进行分析处理,主要包括数据清理、目标意见提取、主题匹配、教师画像等步骤。学生评教数据来源于西部某重点大学2014 学年的学生评教记录,在研究实验前已对数据中的学生学号、教师工号进行了脱敏处理。数据集共有26 098 名学生对1 664 门课程2 032 名教师的259 103 条评教记录。由于评论是评教的选填项目,在259 103 条评教记录中,只有18.9%的记录是有评论文本数据的。学生评教记录的格式见表1。

表1 学生评教记录样本数据
1.1 数据清理
由于学生可以自由填写评论内容,因此需要对学生评教记录中的评论文本进行数据清理,使参与分析的评论数据可靠有效。首先,数据清理会去除对评教分析无用的记录,包括清除无评论的记录和只包含“666”等纯数字评论文本的记录。此外,对于像“很好”这样的短评论文本,虽然评价了教师的整体教学效果,但是无法对应到教师教学活动的具体某个方面,因此对短评论文本也进行了清理。原始评教数据集经过数据清理后,共有10 136 名学生对754 门课程1 532 名教师的36 532 条评教记录,其中评论文本平均有18.9 个字。
1.2 目标意见元组提取
为了能从评论文本中提取学生有关教师教学的评价意见,首先需要提取出评论文本包含的目标意见元组。目标意见元组描述了学生对课程教学活动中某一具体方面的评价。这里首先使用斯坦福大学的自然语言处理工具包CoreNLP[9]对评论文本进行语法分析,得到词语间的依赖关系;然后使用2016 年Hao 等人提出的双向传播算法[10]提取出目标意见元组。表2 为目标意见元组提取的一个例子。

表2 目标意见提取的一个例子
1.3 主题匹配
本文使用被广泛采用的IDEA 评教模型[11]评价教师的课程教学活动,即进行教师画像。它从以下6 个主题评价教师教学活动:①课程组织与规划;②表达交流的技巧;③师生互动;④课程难度/工作量;⑤考试与评分;⑥学生自我评价。为此,需要将提取出的目标意见元组匹配到IDEA 评教模型的某个主题,以形成教师画像。
本文使用2010 年Rehurek 等人提出的方法[12]将目标词和主题词分别用一个词向量进行表示,然后用余弦相似度计算目标词向量与主题词向量间的相似度,取相似度最高的主题词作为目标词对应的主题。相似度计算公式如下:
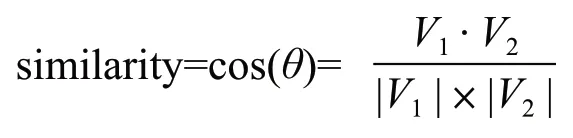
1.4 教师画像
使用中文语义词典HowNet 把目标意见元组中的意见分为正面评价和负面评价两类,然后统计教师分别在IDEA 6 个主题中正面评价记录数和负面评价记录数的占比情况,一条正面评价记录计分为1,一条负面评价记录计分为-1,最终得到教师画像。教师画像的6 个主题得分的取值范围为[-1,1]。当得分为1 时,表示该主题所有的评价记录都是正面评价;而当得分为-1 时,表示该主题所有的评价记录都是负面评价;分值越靠近1,说明教师在主题的正面评价越多。
2 学生评教文本数据分析方法实践
2.1 评估学生评教文本分析方法的有效性
目标意见元组提取是本文方法的核心步骤,为了验证其有效性,采用机器提取结果与人工提取结果进行比对的方法。首先,请3 位领域专家分别对10 000 条评论记录中的目标意见元组和所属主题进行人工标记。如果对同一条评论记录出现3 位领域专家的标记不一致情况,则通过领域专家的讨论,最终达成一致,从而降低人工标记的随意性。通过上述方法得到人工提取结果集。然后对相同的评论记录,以本文方法提取目标意见元组和所属主题,得到机器提取结果。对机器提取结果与人工提取结果进行比对,计算准确率(Precision)、召回率(Recall)和F1值,对比结果见表3。从表中结果可以看到,机器提取结果与人工提取结果的相符程度较好。
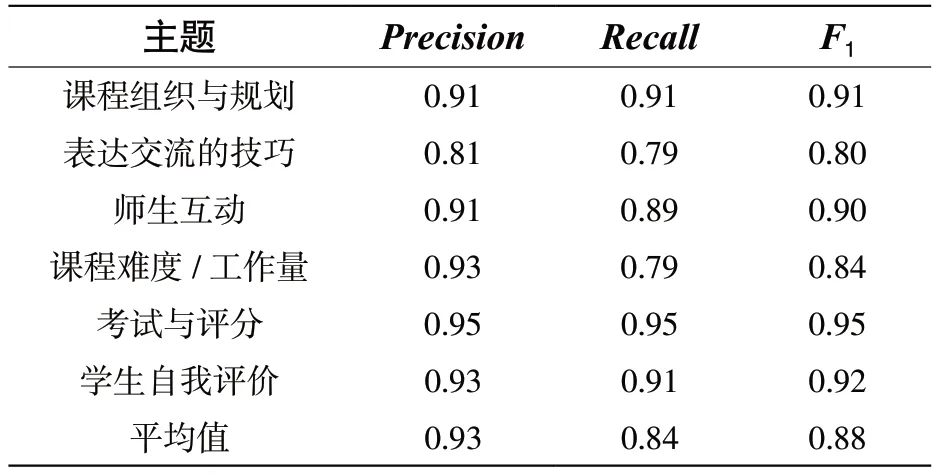
表3 机器提取与人工提取的结果对比
2.2 分析发现学生评教的薄弱环节
一条学生评教的评论文本通过本文方法处理,可以得到该评论文本所评价的教师教学活动主题,进而可以统计出每个主题包含的评论文本条数。对西部某重点大学2014 学年的学生评教记录中的10 136 名学生对754 门课程1 532 名教师的36 532 条评教记录进行分析处理后,得到表4 的统计结果。

表4 学生评论在各主题评论数的占比情况
从表4 数据可以看到,学生在“教师的表达交流技巧”和“课程难度/工作量”方面的评论数占比最高,说明这两方面是学生关注度最高的方面,也是学生直接感受最多的方面,是在学生自由评论时最容易被涉及的内容,但同时可以看到,“学生自我评价”方面的评论数占比最低,只有4.3%,是评教的薄弱环节。分析其原因主要有两方面:一是通常评教环节是让学生评价教师的教学活动,很多学生没有意识到评教内容也包括自我学习收获的评价,以反映出教学活动的目标是否达成;二是学生对课程学习目标不太明确,因此不能对照学习目标评价学习收获的多少。对此,教师应该在今后的课程教学活动中,更好地明确课程学习目标,加强学生自我评价的意识和能力,弥补评教的薄弱环节。
3 结语
基于自然语言处理技术对学生评教数据中的评论文本进行分析处理的方法,可以作为评分分析方法的有效补充,为工程教育专业认证“持续改进”理念的达成提供支持。相关实验验证了新方法的有效性,而新方法得到的分析结果也为评教方法的进一步完善提供了帮助。未来的工作是将新方法得到的分析结果反馈到教学活动的改进中,通过对连续多年的学生评教数据的分析,进一步验证新方法在教学“持续改进”中的效用。
猜你喜欢
云南教育·小学教师(2022年4期)2022-05-17
天津教育·下(2022年4期)2022-05-10
甘肃教育(2021年12期)2021-11-02
甘肃教育(2021年10期)2021-11-02
甘肃教育(2021年10期)2021-11-02
艺术评论(2020年3期)2020-02-06
福建基础教育研究(2019年3期)2019-05-28
现代职业教育·职业培训(2018年10期)2018-05-14
教育教学论坛(2017年31期)2017-08-30
河南教育·基教版(2015年5期)2015-06-05
