
基于FP-Growth的社交好友推荐方法研究
2020-04-02 02:48熊才权
湖北工业大学学报 2020年1期
熊才权,陈 曦
(湖北工业大学计算机学院,湖北 武汉 430068)
随着Web2.0时代的发展,用户成为网络内容的主导者。人们通过网络社交活动,例如评论关注转发收藏等形式参与网络社交获取相应的信息。然而随着网络社区的发展,用户数量规模的急剧扩增,人们对社交的需求更加丰富,人们不仅仅想要通过社交平台跟线下的好友进行交互,还想通过网上社交活动拓展自己的朋友圈,以获取一些自己需要的资源和时兴的动态消息。在如今主流的社交网络上的好友推荐大多采取FOF[1]理论拓展朋友圈,如果两个用户拥有很多共同好友,那么他们是朋友的概率将会很大。Armentano[2,3]等人将社交网络结构和用户特征结合,将邻域内满足条件的用户推荐给目标用户。Akbari[4]等人提出了一种基于图拓扑和人工蜂群的新方法,改进了FOF为三度分离的好友推荐,有效的扩大了朋友推荐的范围。基于已有的好友进行推荐,虽然具有较高的可信度,但是更多的是推荐线下可能认识的好友,无法推荐社交网络上基于兴趣相同的好友,同时也存在冷启动问题。YANG[5]等人使用社会化标签将社交网络拓扑结构和用户兴趣网络结合起来进行个性化推荐。Wu W[6]等人使用词频反文档TF-IDF算法提取用户文本关键词,为每个用户自动添加兴趣和标签,为目标用户推荐兴趣相似的用户。肖晓丽[7]等人提出基于用户兴趣和社交信任的聚类推荐算法,对于用户数据矩阵稀疏和扩展性差问题提出了解决方案,在一定程度上解决了冷启动问题。基于兴趣的好友推荐可以很好的解决社交网络中朋友圈拓展问题,但是容易忽略潜在好友。王兵辉[8]提出社交网络中潜在好友推荐算法。向程冠[9]等人改进AprioriTid算法应用于好友推荐。基于关联规则算法的好友推荐可以解决复杂的好友关系网络问题,同时也可以挖掘潜在好友。因此,本研究通过分析用户相互关注关系挖掘用户的好友关系,通过实验比较分析关联规则算法FP-Growth和Apriori算法计算好友关系数据,挖掘社交网络中的好友频繁模式,为好友推荐提供有效的建议。
1 好友关系复杂网络问题
微博作为国内成熟的社交平台,由于其主要的社交功能属性,及其作为信息交流的集散地,大量的用户活跃在其中,从而提供了可获取的社交关系网络,通过研究该平台的社交网络关系,不仅可以实现推荐系统的应用,同时通过对复杂的社会关系的解析可以提供高价值的数据分析。

图1 单一/多好友关注关系网络结构图
用户可以通过关注这种形式形成强关联模式如图1,一个用户可以根据兴趣关注某个好友,同时可以看到该好友还关注了哪些好友,而好友的好友还有其好友,如此,可以扩增好友圈,但寻找的过程中,通过浏览好友短文本信息,耗时久且效率低,并且一旦用户根据兴趣标签关注多个好友,那么好友的好友的数量将激增,用户将很难找到“志同道合”的好友,而数据挖掘知识能够很好解决这类复杂问题,通过设定阈值,利用关联规则算法挖掘出其中哪几个好友常常是同时被关注的,也就是说某个好友被关注的同时还会连带关注某些好友,以此强关联模式帮助用户找到相似兴趣的好友具有较高的推荐可信度。
2 基于FP-Growth的好友推荐方法
1.1 FP-Growth算法
FP-growth算法是深度优先算法中最新最高效的本质上不同于Apriori算法的经典算法,将数据库的信息压缩成一个描述频繁项相关信息的频繁模式树。Apriori算法有两步骤:一是发现所有的频繁项集;二是生成强关联规则。发现频繁项集是生成强关联规则的前提也是算法中关键的步骤。在Apriori算法中利用“频繁项集的子集是频繁项集,非频繁项集的超集是非频繁项集”这一性质有效对频繁项集进行修剪[10]。Apriori算法有两个致命的性能瓶颈:1)产生的候选集过大(尤其是2-项集),算法必须耗费大量的时间处理候选项集2)多次扫描数据库,需要很大的I/O负载,在时间、空间上都需要付出很大的代价。FP-Growth[11]算法不同于Apriori算法,主要采取数据结构中树存储的概念对数据集进行挖掘,其中有两个关键步骤:一是生成频繁模式树FP-tree;二是在频繁模式树FP-tree上挖掘频繁项集,FPTree算法在不生成候选项的情况下完成Apriori算法的功能。
FP-Growth算法的效率优于一般的类Apriori算法,因为FP-Tree算法的整个过程只需要遍历两次事务数据库,并且把大量的数据压缩存储在树中,时间与空间的开销都优于Apriori算法。
1.2 基于FP-Growth的好友频繁模式挖掘
在复杂的社交网络中,通过FP-Growth算法可以挖掘用户-好友的关注关系。如表1好友关系数据集中,suid表示用户编号,tuid表示用户关注的好友。
好友频繁模式挖掘步骤:
1)设定最小支持度为2。
2)tuid列中得到频繁项的集合和每个频繁项的支持度并降序排序{T2:7,T1:6,T3:6,T4:2,T5:2}记为L,依据L对tuid列重排序,如{T1,T2,T5}重排序后为{T2,T1,T5},以此类推。
3)构建好友关系FP-Tree,以null为根节点,将tuid重排序后的项集依次插入树中,如果项集中元素在FP-Tree中没有节点,则重新建立节点。如果节点已经存在,则在原有节点上计数加1,直到项集中所有元素插入到树中,则好友关系FP-tree树构建完成图2。

表1 好友关系数据集

图2 构建好友关系FP-Tree
4)调用FP-growth(Tree,null)开始进行频繁模式挖掘。伪代码如下
输入:好友关系Tree,模式后缀 a
过程:
if Tree含单个路径R then
for 单路径R每个节点(b) do
频繁模式b U a组合,
该组合支持度support=b支持度(舍去小于设定支持度为2的组合);
end for
else
for 多路径项头表D
b=DiU a组合为模式后缀,生成其条件模式基c
产生一个频繁模式c U b组合,其支持度support =c支持度>2;
end for
end if
if Treeb≠∅ then
调用 FP_growth (Treeb,b);
end if
输出:满足支持度的好友频繁模式
由以上好友关系FP-Tree树,可以根据模式后缀挖掘频繁模式。如果条件FP-Tree是单路径的,则可以通过简单排列组合得到该后缀树的频繁模式。以模式后缀为T5的条件模式树为例:它的条件模式基为(T2T1:1),(T2T1T3:1),通过组合变成{T2:2,T1:2,T3:1},由于{T3:1}支持度小于1舍去,则通过排列组合后可以得到模式后缀为T5并且支持度大于2的频繁模式:{ T2T5:2,T1T5:2,T2T1T5:2}。

图3 模式后缀为T5的条件模式树
单路径条件模式树可以直接采用排列组合挖掘频繁模式,但是对于多路径情况的条件,模式树需要另外的考虑。以模式后缀为T3的条件模式树为例,它的条件模式基为(T2T1:2),(T2:2),(T1:2),这是一个多路径树,
首先通过模式后缀T3和项头表中的每一项做组合得到一组频繁模式{T2T3:4,T1T3:4},然后递归调用FP-Growth,模式后缀为{T1,T3},它的条件模式基为{T2:2},它是单路径条件模式树,通过组合可得{T1T2T3:2}。最后还需要挖掘模式后缀为{T2,T3}的频繁模式,由于该模式后缀为空,则递归调用结束。最终得出模式后缀为T3的频繁模式为{ T2T3:4,T1T3:4,T1T2T3:2}。

图4 模式后缀为T3的条件模式树
基于FP-growth好友推荐算法,最终得到支持度不小于2的好友频繁模式见表2。

表2 好友频繁模式生成表
从好友模式生成表中,挖掘出好友关系数据集中所有的频繁模式,其中{T2T5:2}表示T2,T5用户同时被关注,可以看作是一类组合,它的支持度为2。{T2T1T3:2}表示T2,T1,T3用户同时被关注,该组合的支持度也为2。{T2T1:4}表示T2,T1用户同时被关注,它的支持度为4。对于满足最小支持度的组合也就是频繁模式都可以挖掘出来,如果在社交平台上需要某一类组合的最小支持度为20,那么通过FP-Growth递归挖掘,再通过降序排序就可以推荐Top-N好友组合,这就使得社交网络复杂关注关系的好友推荐具有推荐意义。
3 实验评估
3.1 实验数据集
为了验证算法的有效性,将新浪微博平台作为实验的对象,实验数据集从新浪微博平台抓取,通过清理、集成、变换3个步骤对数据集进行处理,将处理后的63641条新浪微博信息,1391718条用户好友关系存储数据库。实验中算法实现采用JAVA语言编写,推荐规则的存储采用Mysql5.5数据库,实验运行时的硬件配置为Intel(R) Core(TM) i5-6200U CPU @ 2.30 GHz (4 CPUs),8G内存,256G 固态硬盘,操作系统为Win10。
3.2 评价指标
评价好友社交平台采用召回率(Recall) 、准确率(Precision)和F1度量(F1-measure)三个指标进行评估,召回率主要用于观察推荐算法推荐的好友集合Urc与实际可推荐好友集合Ureal交集中好友数量占实际可推荐的好友比率
(1)
准确率主要用来衡量算法的正确性、可行性,反应推荐出的准确好友数所占推荐好友数的百分比,越高准确性越好,计算如下:
(2)
F1度量(F1-measure)将准确率和召回率的调和平均数作为一个评价标准。F1度量综合考虑了推荐系统的性能,其表达公式如下:
(3)
3.3 实验结果与分析
在本次实验中,将FP-Growth算法和Apriori算法在好友推荐的实例中进行对比实验,主要通过以下三个方面:
1)设定支持度为20,从微博用户关注数据集中生成1 k、2 k、3 k、4 k、5 k、6 k、7 k 、8 k数据集,比较算法运行效率如图5所示。
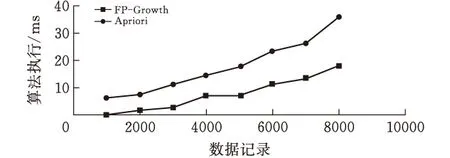
图5 FP-Growth算法和Apriori算法数据增大时执行时间比较
从图1 FP-Growth算法和Apriori算法数据增大时执行时间比较所示,在相同支持度的情况下,随着数据量的增大,FP-Growth算法在执行时间上总是优于Apriori算法,由于FP-Growth利用FP-Tree树的数据结构进行存储和计算数据,不需要频繁扫描数据库,利用计算机内存计算,大大减少了计算数据时间。
2)设定恒定的用户关注数据集,通过调整最小支持度为10、20、30、40、50、60、70、80比较算法运行效率如图6所示。

图6 FP-Growth算法和Apriori算法支持数数增大时执行时间比较
本次实验从数据集中筛选2k数据量,通过调整不同的支持度比较FP-Growth算法和Apriori算法执行时间,从图表中可以看出FP-Growth算法执行效率较高。随着最小支持度增大,候选项集将会相应减少,两种算法运行效率都会相应提高。
3)为了验证本文FP-Growth好友推荐模型的有效性,本实验将其与现有的社交网络好友推荐模型:基于关系的两阶段好友推荐模型[12](简写为M1模型)、以及基于协同过滤的好友推荐模型[13](简写为M2模型)进行对比实验,推荐目标用户Top10,Top20,Top30,Top40好友,并且比较、观察三个模型在不同推荐好友数量下的F1度量值随推荐好友数量变化的结果见图7。

图7 对比实验结果图
从实验结果看出FP-Growth好友推荐算法在推荐好友数量为30时,F1值达到最高,在准确率和召回率上都相对优于其他两种模型。
4 结论
FP-Growth算法利用内存运算比较Apriori算法在执行时间上有明显的优势,在准确率和召回率上这两个算法结果相同。本实验通过FP-Growth好友推荐模型与基于关系的两阶段好友推荐模型、基于内容的好友推荐模型作比较,其FP-Growth好友推荐算法相较于其他两种算法具有较高的F1度量,同时由于FP-Growth关联规则算法,是根据用户间的关注关系进行数据挖掘,在实际应用场景推荐中,更具有可信度,在社交网络中可以很好为用户提供好友推荐序列,提高用户交友体验,但是基于FP-Growth算法本身是基于内存的计算,对于大数据运行还是需要采取并行化计算,同时由于本文只是对所有的用户关注关系进行数据挖掘,并没有涉及用户文本,推荐结果比较多样,所以在今后的研究工作中还需要抽取用户文本主题,通过对主题聚类更加精确地给目标用户推荐好友。
猜你喜欢
辽宁大学学报(自然科学版)(2022年1期)2022-04-26
青岛大学学报(自然科学版)(2020年3期)2020-09-30
计算机技术与发展(2019年7期)2019-07-23
小雪花·初中高分作文(2019年10期)2019-02-12
杂文月刊(2017年20期)2017-11-13
中国新通信(2016年17期)2016-11-17
电脑知识与技术·经验技巧(2016年1期)2016-03-14
电脑爱好者(2015年24期)2015-09-10
小雪花·成长指南(2009年10期)2009-12-04
