
依赖单形向量机的启发式网络安全态势预测
2020-03-26 06:15:18黄振晗
湖南工程学院学报(自然科学版) 2020年1期
黄振晗
(福建广播电视大学莆田分校,莆田 351100)
在信息技术快速发展的背景下,网络安全技术开始从之前的被动防御逐渐升级到主动防范.而在诸多主动防范技术中,安全预测技术无疑是其中极为重要的一环,通过安全预测技术能够实现提前预警并能对安全走势进行动态评估.网络安全态势预测能够对今后的安全发展脉络有着更加清晰的认知,并为主动式安全管理提供极大的支持,可以显著减少安全所带来的诸多损失,因此深受社会各界瞩目.当前海内外诸多学者提出了基于不同算法的安全预测模型,譬如时间序列、证据理论法等,这些模型的预测结果往往只能对安全相类性、周期性的发展态势进行预测,并不能对随机性或者突发性安全问题进行预测.为此部分学者开始将这种问题转化成时间序列的回归预测问题,然后借助于人工智能算法,例如灰色模型、SVM、BP神经网络等完成该安全预测的建模,得到较佳的效果.SVM是一种典型的以高斯模型为核心的非线性预测技术,它能够在大量数据中挖掘出网络安全潜含的规律.为了进一步提升该安全走势的预测精准度,在本次研究中对SVM参数使用遗传算法进行优化,由此创制相应的安全预测模型.这样就能更好利用遗传算法的全局搜索能力对SVM参数加以合理优化,使之更为精准的进行网络安全态势的预测.最后对此方法进行仿真验证,得出本次优化的模型在该安全态势预测领域颇具效果.
1 网络安全态势预测的原理
“态势”的基本概念起源于军事领域,其内涵就是某个被研究对象状态综合表现,而此对象存在着范围大、结构复杂、影响要素众多的特点.其中战场态势最为典型.在网络安全研究中,该态势的引入有助于创制更具可行性的体系,从而对该安全状态进行全面与深入的认知.该预测管理需要结合相应的安全事件发生参数进行加权处理,譬如发生频次、受威胁程度等.将大量安全信息进行融合,进而获得相应的态势值来更加精准的了解当前安全水平,然后在综合当前与历史态势值来预测今后的安全趋势.该态势在采集数之时需要按照时间先后次序来开展,因此在具体处理之时能够将其视作一个时间序列,而预测模型输入变量则能遴选前段时间序列态势值,而输出则是下一个时间的安全态势值.将具有安全态势值的时间序列进行如下设置:
x={xi|xi∈R,i=1,2,…,L}
(1)
由此对网络安全态势的预测从本质上就是对前N时间节点的态势值加以分析,进而对后续不同时间节点的态势值进行预测.其实现流程为:第一,训练对应训练集,构制该态势预测模型.第二,借助于该模型对今后一段时间的网络安全态势进行预测.该网络安全态势能够展现出随机性与不确定性,因此需要对预测结果的准确性进行提升,而不能简单的使用传统的预测模型.在此处可以借助于SVM来对该态势进行预测.这项技术的核心可以对系统的随机性与不确定性有着较强的自适应学习能力.以下就基于SVM来对网络安全态势进行建模,然后对今后的安全态势进行预测.
2 网络安全态势预测模型
2.1 支持向量机算法
1995年,Vapnik和Cortes在研究中首次提出支持向量机这种用以统计学习的机器学习方法,如今SVM已经成为机器学习的主流预测模型.它能够对n维欧式空间Rn的两类基本问题进行解决,亦即分类与回归问题.可以概括成:获取Rn中的实值函数g(x),然后对任意输入值x借助于决策函数f(x)=sgn[g(x)]来获取相应的输出值y.
在此过程中g(x)函数形式较难明确,主要采用的方式就是创制与原始问题具有等价关系的对偶问题并加以计算.而这种问题通常为非线性规划问题,也就是将原欧式空间Rn中的变量x借助于转换φ完成至Hibert空间的转换,进而得到线性规划问题并进行求解.对应的变换φ为:
Rn→Hilbert,x→x=φ(x)
(2)
在此SVM中,实现φ变换的方式为核函数的内积转换,亦即:
K(x,x′)=φ(x)φ(x′)
(3)
而Rn空间之中的决策函数为:
f(x)=sgn[wTφ(x)+b]
(4)
上式中的权重与阈值分别用w与b表征.
若是相应的问题具有线性不可分属性,那么就很难运用SVM来进行计算,目前较为可行的方法就是引入非负松弛因子,然后将其进行转换使之成为二次优化问题,亦即:
s.t.yi(w·φ(x)+b)≥1-ξi
ξ≥0,i=1,2,…,n
(5)
在上式中展现了典型凸二次规划问题,所以可以借助于拉格朗日乘子来对其进行转换,使之形成对偶问题,亦即使得计算最小化问题转换成最大化求解,具体如下:
C≥ai≥0,i=1,2,…,l
(6)
上式中的拉格朗日算子为ai,通过对其进行计算,就能得到w的权向量,是为:
w=∑aiyiφ(xi)φ(x)
(7)
为此支持向量机的分类决策函数为:
f(x)=sgn[aiyiφ(xi)φ(x)+b]
(8)
在相应的高维空间之中展开相应的点积操作无疑有着颇大的难度,所以将其使用核函数来进行取代,那么该函数就能用下式表示:
f(x)=sgn[aiyik(x,xi)+b]
(9)
该SVM核函数会导入新参量,所以可以将RBF应用该支持向量机的核函数,前者的形式为:
(10)
于是该函数的最终表征形式为:
(11)
2.2 支持向量机网络安全态势预测过程
利用SVM对网络安全态势进行预测,其过程为:
(1)对当前的网络安全态势数据进行采集,包括其中的处理不良与异常数据.
(2)分析该态势数据,因为对其影响的因素整体较多,容易产生较大的差异,其中SVM预测模型对(0,1)之间数据有着较高的敏感度,为此需要将原始数据进行归一化,使之处于0至1之间,具体方法为:
(12)
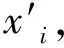
(3)将一维网络安全态势数据转化成多维数据,实现机制就是利用嵌入维数与时间延迟来实现.在本次研究中该时间延迟为1,而嵌入维数依次为2,3,…,借助于初步的试凑,于是获得嵌入的m维数.如果该一维态势数据用{X1,X2,…,Xn}表征,那么便能获得以下多维该态势数据,具体如下:
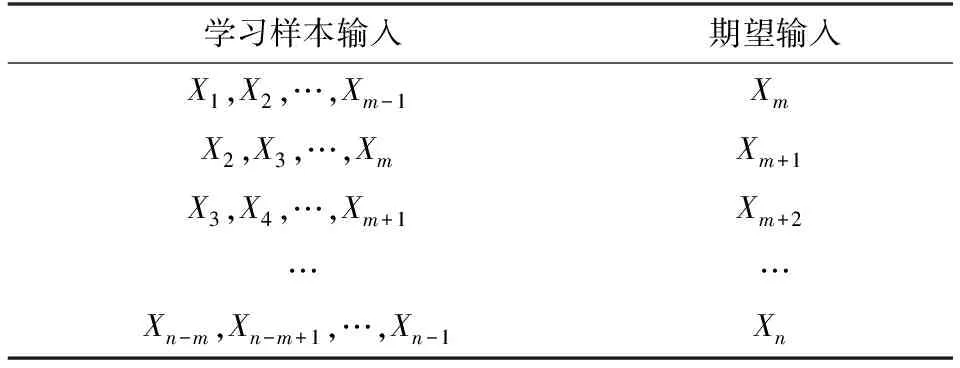
表1 多维网络安全态势数据
(4)将网络安全态势数据细分成两个模块,亦即训练与测试集,SVM可以利用训练集进行学习,进而对SVM模型的参数进行最优解寻找,具体可以通过遗传算法来实现,这样就能够使得该预测模型参量具有最优性.
(5)借助于该预测模型来对预测集进行分析,并输出相应的结果.接着利用反归一算式将该结果转换成具体安全态势值,最后就可以据此对当前的网络安全态势进行准确判断与预测.
3 网络安全态势预测实例分析
3.1 网络安全态势数据
为了对设计模型进行效果验证,将实验室入侵检测开发组的测试环境用作实验环境,而该入侵检测的系统都统一的独立于相应的互联网局域网之中,局域网内含WEB与FTP服务器,普通计算机10台,还有两台攻击模拟机.实验设备都配置了相应的入侵检测系统探头,选择2019年4月1至4月30日的边界安全监测数据,按照日采样4次频率,总共获取120个态势值,具体数据可参见下图.将前面的90个态势值用作SVM的训练样本,而后30个则是该SVM的测试集,而相应验证试验选用了matlab 9.1系统.
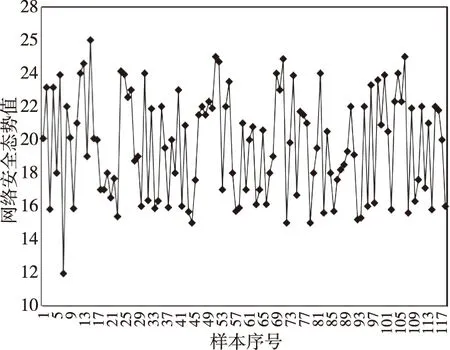
图1 网络安全态势样本数据图
3.2 模型的实现
首先将该态势时延设定为1,然后利用以上的试凑法不断提升嵌入的维数,通过分析获得8维,对应的SVM为7个输入变量与1个输出变量,该态势数据的重构就可以利用该时延与嵌入维数来实现,然后完成该SVM的训练与测试样本集.随后基于前者数据集来进行SVM学习,同时利用遗传算法对此模型参量加以优化.设置的参量包括进化代数、初始种群、变异与交叉概率,它们的值依次为100、40、0.01、0.05与0.95.该系统在运行至50.55 s之时出现目标误差,此时的SVM完成的训练步数达到5000,借助于该态势的适应度曲线可以得知,在30代遗传之后,该染色体的适应度开始逐渐稳定,据此就能得到该预测模型的最优参量:亦即高斯核函数宽度、不敏感损失函数与惩罚参数,依次为5、0.001与100.随机对该安全态势进行相应的预测,得到图2的适应度曲线.分析该图可知通过约30代的遗传,该染色体适应度开始渐稳,由此得到该模型的最优参量为:c=100,ε=0.001,σ=5.借助于该预测模型就可以得出预测误差整体较小,预测精度得到了明显的提升.
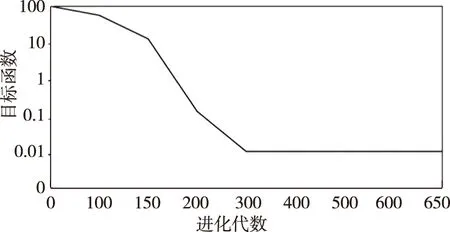
图2 SVM参数优化过程
3.3 网络安全态势预测
在使用最优参量c=100,ε=0.001,σ=5构筑相应的安全态势预测模型时,可以选用最优模型对这30个态势值进行预测,并得到图3的结果,而通过图3给出的预期曲线可以得知该预测模型整体预测误差较小,有着较高的预测精度.
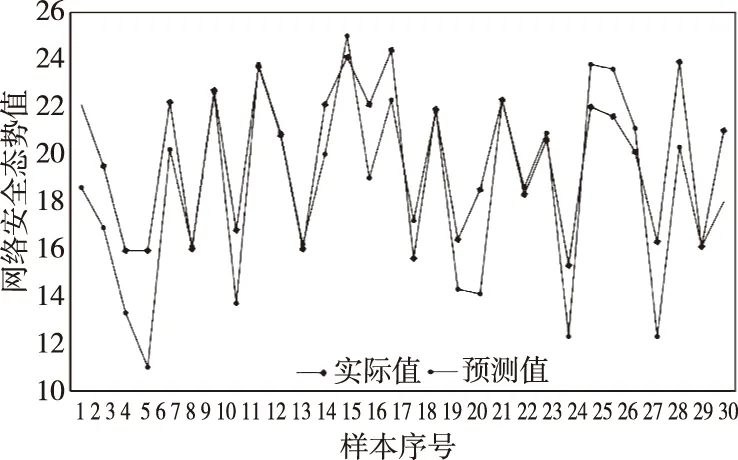
图3 SVM网络安全态势预测结果图
为了进行对比分析,运用BP与RBF这两种神经网络算法来进行预测,并借助于均方(MSE)与平均相对误差(MAE)来用作模型的评价指标,得到表2对比结果.
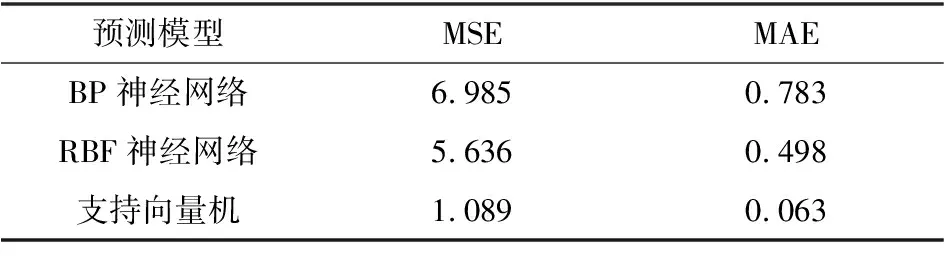
表2 三种算法的预测性能分析表
通过表2对于三种算法的预测性能分析可知,SVM在预测速度、精度与所需时间上相较与另外两种算法都有着较为明显的优势.造成这种差异的原因是该SVM相较于RBF以及BP算法而言有着更多的优势,况且前者还进一步使用了遗传算法对其参量加以优化.装使之能够在整个空间中找到最优解,有效规避另外两个算法容易陷入局优解、收敛速度慢等问题.为此SVM无疑在网络安全态势预测方面,无疑具有快速、高精度、高可靠性的优势.
4 结语
随着信息网络中各种新型技术的广泛运用,网络安全感知技术随之诞生,这种感知技术可以细分成相应态势要素的提取、评估与预测.其中预测则是这项技术的核心,通过预测可以为相应的管理人员提供当前以及过去的相应网络安全状态,同时还能在已有的数据基础上挖掘与预测今后一段时间的网络安全态势,从而显著较少管理者的数据分析工作量,所以该技术开始在安全研究领域受到极大重视.在本次研究中针对这种预测算法进行了分析,并提出以SVM为基础的网络安全态势预测模型,对此模型设计与实现进行概述,并利用仿真技术来对本次的模型设计进行验证,得出该模型相较于传统预测算法更为精准,并能对网络安全态势的整体变化情况进行准确的反应,与此同时预测的结果也更加有利于网络管理人员对今后网络的安全演化进行判断,并能提前准备更为合适的解决策略.
猜你喜欢
汽车与安全(2020年1期)2020-05-14 13:27:19
中国外汇(2019年19期)2019-11-26 00:57:36
中国化肥信息(2019年5期)2019-06-25 00:52:28
中国生殖健康(2019年10期)2019-01-07 01:21:04
信息安全研究(2018年12期)2018-12-29 11:01:46
小学生必读(中年级版)(2018年4期)2018-07-05 06:00:48
中国卫生(2015年2期)2015-11-12 13:13:58
物理实验(2015年9期)2015-02-28 17:36:51
声屏世界(2015年7期)2015-02-28 15:20:13
数学年刊A辑(中文版)(2014年4期)2014-10-30 01:50:32
