
基于维基百科信息框的本体信息提取
2020-03-25 09:12徐星羽
吉林大学学报(理学版) 2020年2期
陈 刚, 徐星羽
(武汉大学 国家网络安全学院, 武汉 430079)
维基百科(Wikipedia)是一个内容自由开放式的网络百科全书协作计划, 其储存了大量由作者编辑的维基列表. 在每篇成员文章中都有可能包含一个维基百科信息框. 维基百科信息框是一个格式一致的表格, 存在于某一主题的文章页面中[1].
目前, 对本体匹配或维基百科本体构建的研究已有许多成果, 但对维基百科信息框的研究较少. 传统方法利用信息框属性寻找合适的表格概要属性, 基于一组候选特征如类别与列表的信息框中属性频度、 信息框属性以及列表文本描述的相关度训练分类器, 寻找信息框属性中可作为列表统一表格概要的属性[2-3]. 本文研究基于给定维基百科类别下的维基列表及其成员文章提取信息框中本体结构信息(类关系), 将维基百科信息框中提取出的属性及其数据作为实验数据, 并将其均视为本体类[4](并未严格遵循本体规则). 采用3种本体类关系研究维基百科类别中的属性, 定义一组候选特征判断特定的关系是否存在. 本文使用Word2Vec计算属性对之间在特定文本域的余弦相似度, 并分析属性间的相关程度.
1 问题描述
本文主要考虑构建本体信息描述类(信息框属性及部分取值)之间的关系. 维基百科信息框中的内容并不一定是格式完美、 语义无歧义的, 有些问题出现在信息框的属性与取值中[5]. 例如, 使用不同的属性名称描述相同的概念和属性取值未定义清晰的取值范围. 本文以维基百科中一个主要概括美国各州大学或学院信息的类别为例, 该类别为Category: Lists of universities and colleges by U.S. state, 提取该类别中的列表与文章信息, 结果列于表1.

表1 维基百科“大学”类别信息
本文基于对网络本体语言的研究, 将问题总结为三方面, 并讨论这三方面问题在维基百科信息框中的表现形式.
1.1 相等关系
维基百科信息框属性的相等关系(equivalent relationship)有两种可能性[6]: 一种情形是同一个单词的单复数形式, 在一篇文章创建信息框时, 不同作者针对同一条属性的同一用词可能会采用不同的单复数形式, 或者都包含在内; 另一种情形则是两个不同的单词在当前语境或上下文条件下, 是对同一个概念进行描述的一组同义词. 两种情形中都可人工判断出两个属性是否具有相等关系.
本体语言中定义两个不同类描述所对应的元素集合是同一个集合, 则判定两个类为等价类. 表2列出了3组存在于维基百科信息框属性中的相等关系, 每行均为一组人工标注的等价类本体信息.

表2 信息框属性相等关系示例
1.2 包含关系
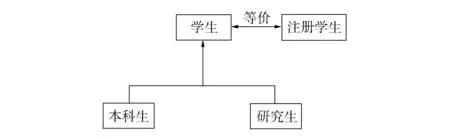
图1 包含关系示例的本体结构
包含关系在维基百科信息框中的表现形式为一个或多个属性所描述的概念及内容是某个属性所描述概念内容的组成部分. 符合这种情形的属性组合拥有某一方向的包含关系.
在本体语言中, 两个类C1和C2, 如果满足C1描述所对应的元素集合是C2元素集合的子集, 则C1是C2的子类. 这种包含关系可称为类之间的父子关系. 特别地, 一个类必然是它自己的子类; 如果两个类互为父子类, 即互相包含, 则这两个类是等价类.
表3与图1给出了包含关系在信息框属性中的本体结构示例. 在包含关系示例中, 存在一种新的类关系, 即兄弟类, 图1中本科生和研究生即为兄弟类, 它们共享同一个父类“学生”. 在研究互斥类关系时, 兄弟关系将是重要的依据和参考条件.

表3 信息框属性包含关系示例
1.3 互斥关系
互斥关系较复杂, 如果两个类所包含的数据元素都不是同一数据类型, 则探讨这两个类是否具有互斥关系无意义. 因此, 互斥关系仅出现在兄弟类之间. 本体语言中定义两个类为互斥类需满足元素集合无交集的条件. 所以判断互斥关系时可能需要用到包含关系的判断结果. 兄弟类的定义即将共享父类的各子类判定为兄弟类[7]. 表4中所列的示例与包含关系中的示例是同一组, 在包含关系中, 本科生和研究生都作为学生的子类, 它们互为兄弟类的同时也互斥, 其所描述的元素集合无相同元素, 符合定义的互斥关系. 图2更直观地描述了该组数据中的包含关系和互斥关系结构.

表4 信息框属性互斥关系示例

图2 互斥关系示例本体结构
另一方面, 在维基百科的信息框中, 某些特殊的属性可能隐含着独特的结构信息, 该属性的取值可能在维基百科中也有相应的文章页面或列表. 这些特定属性的所有取值, 也将构成一组兄弟类, 而这些兄弟类之间可能存在互斥关系.
在“美国大学”这个研究示例类别中, type属性是该情形下标准的样本案例. 通常在维基百科信息框中, 属性type表征该篇文章在特定类别下的具体分类. 表5列出了7个来自属性type的取值, 其中有两对互斥类和3个单独的类.

表5 Type属性互斥关系示例
在实际应用中, “美国大学”类别的维基列表里, 多数表格概要都将“公众/私有”和“盈利/非盈利”从type取值中抽取出来, 新建了一个概要属性control表示这两对取值的含义. 在列表表格概要中也有一项名为type的属性, 其中只包含了信息框属性中type内容的一部分. 这种将属性type分割的行为可认为是受取值出现的频率所影响, 因为“公众/私有”和 “盈利/非盈利”这两对取值占据了多数type在信息框中的实例.
2 本体构建流程
2.1 特征提取
类的相似度是类关系的有效表现特征. 本文定义5个相似度特征帮助构建本体结构信息.
2.1.1 取值集合相似度 在维基百科每篇文章的信息框中, 每行都包含一条属性及其取值[8]. 本文对类别中每个属性在所有信息框中的取值进行收集汇总, 所有取值对应属性形成一个集合, 即属性的取值集合. 在判断两个属性间关系时, 计算两个属性对应取值集合的Jaccard相似性系数. Jaccard相似性系数在数据挖掘和机器学习领域中是一个常见的评价指标, 主要用于比较有限样本集之间的相似性与差异. Jaccard相似性系数越大, 样本相似度越高. 根据取值集合相似度特征, 可寻找类之间的相等关系和包含关系. 本文将取值集合记为
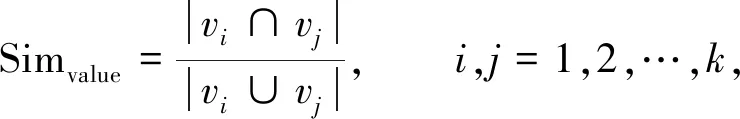
(1)
其中:vi表示数据属性值;vj表示相似数据属性值.
2.1.2 首段集相似度 维基百科文章页面内的文本内容包含了大量有价值的、 适合进行数据挖掘文本分析的数据, 特别是每篇文章的第一个段落[9]. 本文将文章中的第一段落作为寻找类之间相等关系和包含关系的一项重要参考. 收集提取相应维基百科类别下所有文章的第一个段落, 汇总成一个文本语料库. 利用Word2Vec训练文本, 为每个属性生成对应的词向量, 计算属性在文本空间中的余弦相似度, 作为两个属性类之间的首段集相似度. 余弦相似度衡量了两个向量在向量空间中的夹角大小, 本文属性所对应的词向量在语料库向量空间中的余弦相似度越大, 他们之间的关联度就越高. 本文将首段集相似度特征记为

(2)
其中:vacci表示余弦数据属性值;vaccj表示余弦相似数据属性值.
2.1.3 模版相似度 在维基百科中, 多数类别有特定的信息框模板, 为作者在当前类别下的文章创作信息框时提供参考. 该信息框模板的模板结构和模板描述都可显示创建此类维基百科信息框的细节[10]. 本文利用维基百科的信息框模板(如果存在)页面提取文本数据, 帮助预测类之间的相等关系和包含关系. 处理维基百科类别的信息框模板, 作为Word2Vec的训练文本, 使用属性词向量在模板页面训练后的语料库向量空间中的余弦相似度作为判定类关系的候选特征, 记为

(3)
其中:vaccit表示属性词向量数据值;vaccjt表示属性词相似向量数据值.
2.1.4 信息框内位置 信息框内位置表示两个属性在同类维基百科类别文章信息框中相对的位置关系. 如果同类文章中两个属性在信息框实例里出现的相对位置概率相近, 则这两个属性在类关系上就有很大可能性是相等或是包含关系, 甚至有可能是互斥关系. 本文将两个属性的相对位置距离特征记为

(4)
其中:pi表示相对位置数据属性值;pj表示相对位置相似数据属性值.
2.1.5 名称相似度 每个属性在维基百科的信息框中都对应一个名称. 如果两个属性的属性名称在文本上有很强的相似关系, 则他们有较大的可能性是拥有相等关系和包含关系, 在计算名称相似度特征值时, 本文采用欧氏距离衡量两个属性名称的相似程度, 记为
Simname=lena,b(i,j).
(5)
2.2 构建等价类本体
寻找等价类(equivalent class)时, 对于每个已经提出并定义的候选特征, 本文都将先计算两个类之间相应的特征值, 再对特征值进行排序. 假设给定属性类A, 其余所有非A属性类与A计算单一特征值, 按特征值从大到小的顺序排列所有候选属性类, 即形成了A属性类某一特征的特征值排序序列, 该序列表示在某一特定特征下, 与属性A最相似的属性类排序. 在每个特征下,A属性都要形成一个特征值排序序列. 检查已经排序的5个特征值序列中的属性名称排序, 找出人工标注相等关系的标准答案在序列中的位置, 评估单一特征在判断类之间相等关系上的正确率或正确范围. 因为单一特征的特征值计算结果排序, 正确的答案可能并不在序列的前段, 该情形属于某一特征未发挥效果的样本案例. 如果某单一特征在寻找类的等价类时正确性低于其他特征, 则在综合考虑所有特征推断等价类关系式, 就需要降低这一特征的权重参数; 反之, 若某个单一特征在判断等价类关系时的准确率远高于其他特征, 则需要在综合考虑提升这一特征的重要性.
评估完单一特征寻找等价类的表现后, 需要整合5个特征决定2个类最终是否为等价类. 由于研究时间所限, 本文研究在确认单一特征的表现后, 并不调整5个特征在最终计算时的特征权重向量参数, 而记作W1=(1,1,1,1,1)的形式, 计算5个特征值的算术平均数作为判定等价类的最终依据, 将该平均特征值作为等价类特征值(equivalent class feature score), 记做Simer. 同理, 对每个属性, 都为其列出相对应的等价类特征值排序, 排名越靠前的属性, 越有可能为其等价类. 本文选取排名第一的属性(top-1 similar attribute)作为寻找到的当前属性类的等价类[11].
2.3 构建父子类本体
寻找一个属性类的父类所用特征与寻找等价类时相同, 所用方法也接近. 因为在逻辑学上, 一个类本身也是该类的子类, 当子类与父类足够相似时, 子类与父类即成为等价类. 但当一个子类内容过少时, 可能无法察觉其与父类之间的包含关系.
与寻找等价类时相同, 首先对5个单一特征值在特定属性上排序, 检验单一特征在寻找某类的父类时的准确率或准确范围. 虽然不会因为单一特征在寻找父子类时与其他特征的表现差异而调整整体权重参数, 但要与寻找等价类在算法上有所区分. 不同点则是针对了单一的特征属性的名称相似度(name similarity). 在名称相似度的特征中包含了一种特殊的情形, 称为名称的字符串包含(name string inclusion). 例如, school和law school这两个概念分别指代学校与法律类学校, 两者之间存在一种包含关系, 即law school是school的子类, 而不是等价类的关系. 这种特殊情形的表现特征是一个类A的名称字符串覆盖了另一个类B, 即类B的名称字符串是类A字符串的一部分, 将会导致名称相似度的特征值计算升高而影响最终结果. 所以名称相似度这一特征在推断包含关系时要比推断相等关系时权重大. 前提条件是, 在进行名称相似度特征前, 已经通过去主干(stemming)等文本处理方法将单词的单复数、 英文名称加数字等影响因素都提前排除掉. 因此, 在综合汇总所有特征值数据进行综合判断寻找父类时, 本文设定各特征的权重参数向量为W2=(1,1,1,1,3), 该综合特征值成为父类特征值(parent class feature score), 记为Simsr. 得到每个属性的其他属性父类特征值排序后, 暂时假设排名第一的属性记为当前属性类的父类[12].
在判定等价类和父类时, 维基百科信息框中大部分的属性可能不涉及到相等关系或包含关系, 如表6所示. 因此, 设置限制性参数t分割特征值序列,t=0.5. 只有等价类特征值或父类特征值超过参数t的特征值序列排名第一的属性才会被保留, 其余均按无相关关系判定.

表6 维基百科“美国大学”类别内关系数据
下面给出判定等价类与父子类的流程. 假设当前属性类为类A, 在对类A的等价类特征值及父类特征值作计算排序后, 得到类B为其等价类特征值序列第一位, 特征值为Simer, 类C为父类特征值序列第一位, 特征值为Simsr. 下面对特征值是否符合限制条件t做出判断:
1) 若等价类特征值不满足Simer>t, 则判断类A没有等价类;
2) 若父类特征值不满足Simsr>t, 则判断类A没有父类.
限制条件1)和2)判断都满足后, 首先检查类B与类C是否为同一个类, 若仅有一个类满足则只考虑满足那一类的后续流程.
3) 若类B与类C不是同一个类, 则检查类B的等价类特征值序列, 若类A位列第一, 则类A与类B互为等价类, 否则类A没有等价类;
4) 若类B与类C是同一个类, 则检查类B的两个特征值排序, 若类A在任意一个特征值排序中位列第一, 则类A与类B互为等价类, 否则类A为类B的子类.
2.4 构建互斥类本体
本文所定义的5个特征仅可帮助推断相等关系和包含关系. 互斥的两个类并不适合用相似度判断, 因为互斥的类既可能高度相关, 也可能关联程度较低, 甚至可能无相似性. 通过一般的特征提取无法发现隐藏在维基百科文章和信息框中的互斥关系, 所以元素集合没有共享元素个体的两个兄弟类. 根据定义可能出现如下两种情形:
1) 特殊属性取值所构成的类. 在该情形下, 将检索对应维基百科类别中的所有文章, 提取出每个取值类在所有文章中的实例分布, 不包含同一个实例文章页面的两个取值类可判定为互斥关系; 反之, 有任意一篇文章同时出现在多个取值类的实例分布中时, 这些取值类就不能成为互斥类.
2) 拥有相同父类的属性类情形很难通过检索实例分布确定互斥关系, 现阶段无法从实验数据中取得足够的证据来证明类之间的互斥关系, 所以这些拥有相同父类属性类之间的类层次结构就只能暂时停留在兄弟关系[13].
3 实验与评估
实验数据来源是维基百科(英文), 需要提取维基百科某类别下所有维基列表及其成员文章. 在本文实验中, 提取了Category: Lists of universities and colleges by U.S.state这一类别下的所有列表和文章数据, 共有39篇列表和2 274篇成员文章, 并从中抽取出了列表描述、 列表表格、 文章文本和文章信息框等模块数据. 研究采用人工标注的方法确定黄金准则, 为维基百科“美国大学”类别中提取出的854个信息框属性逐条标记可能的相等关系、 包含关系和互斥关系.
3.1 单一特征表现评估
5个特征分别用单特征值计算数据举例描述其效果, 其中: (F)表示父类的正确答案; (E)表示等价类的正确答案. 结果分别列于表7~表9. 由表7~表9可见, 对5个特征的单项特征提取表现评估精度较高, 且各属性关系较明确, 效果较好.

表7 取值集相似度单特征表现示例

表8 首段集相似度单特征表现示例

表9 模版相似度单特征表现示例
3.2 综合特征值评估
本文实验完成对5个特征的单项特征提取表现评估后, 综合5项特征, 对属性间是否具有相等关系或者包含关系做出判定, 表10和表11分别列出了部分示例的特征值计算判定结果, 其中: (E)表示等价类的正确答案; (F)表示父类的正确答案; (W)表示判定错的答案.

表10 相等关系的特征值计算结果示例排序

表11 包含关系的特征值计算结果示例排序
由表10和表11可见, 本文在判定两种关系时可以发现正确答案, 但也在部分属性上判断不准确, 所以需通过整体的准确率检验方法的效果.
3.3 全局实验评估
在列举并分析部分样本属性案例的数据结果后, 下面对本文实验的全局性能进行统计学上的评估. 本文采用精确率(precision)、 召回率(recall)和F1值评估在寻找属性类之间相等关系和包含关系的实验效果. 在维基百科“美国大学”类别数据集中, 有信息框属性854个, 拥有等价类属性的56个, 拥有父类属性的77个. 通过实验的特征提取、 特征值排序和类关系判断后, 总精确度数据信息列于表12. 由表12可见: 在寻找相等关系(即寻找等价类)的实验中, 精确率为0.667, 召回率为0.607,F1=0.636; 在寻找包含关系(即寻找父类)的实验中, 精确率为0.523, 召回率为0.584,F1=0.552.

表12 “美国大学”类别实验总精确度评估
因此本文方法是可行的, 但不高效. 在寻找属性之间的两种关系时做出了正确的判断, 但也因为算法的局限性而误判、 漏判了一些属性关系.
3.4 实 例
表13列出了学生这一组相关的属性类, 在相应的等价类特征值排序和父类特征值排序中位列第一的两个属性及其取值. 根据表13中的数据可按照算法规则逐条推断各属性间的类关系: 学生和注册学生是互为等价类; 研究生和本科生互为等价类; 研究生、 本科生和其他学生为学生的子类; 博士生与其他属性类之间无相应的类关系. 通过推断的结论, 可构造出这一组属性类的本体结构.
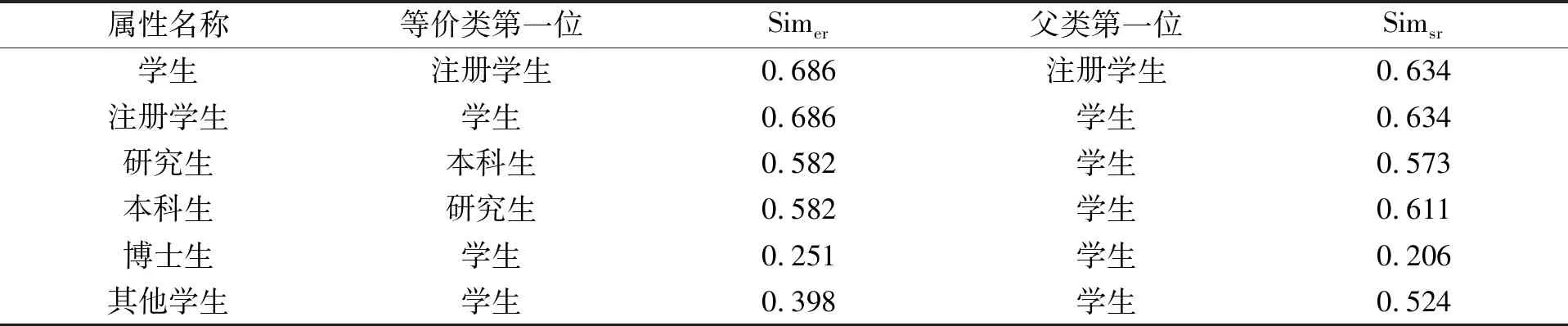
表13 学生组示例的特征值数据
根据人工标注构建的本体结构, 可清晰地提炼出包含的类关系仅有一对等价类(学生与注册学生), 4个以学生为父类的属性类(研究生、 本科生、 博士生与其他学生). 在实验中对学生组属性类关系作出错误判断的关系有两个: 1) 研究生与本科生并不是等价类的关系, 实际上是互斥类的关系; 2) 博士生应为学生的子类. 分析原因可知: 属性类研究生和本科生在各自的等价类排名上以0.582的等价类特征值排在第一位, 出现该现象的原因与首段集相似度和模板相似度这两个特征有重要的关联. 在维基百科“美国大学”类别的文章中, 研究生与本科生出现在第一段落的情形并不常见, 但他们总是捆绑在一起同时出现, 信息框模板中也如此. 尽管这两个属性类是互斥的, 但其紧密程度极高, 同时在文本数据中的相似度也很高, 超过了各自与学生的文本相似度, 做等价类特征值计算时排在前端, 所以在判断等价类关系时, 本文方法错误地将这两个属性判定为等价类. 属性博士生与学生在其他相似度特征上有较大差距, 所以在父类特征值的计算结果中, 博士生被误判为没有关系的属性类.
3.5 判断取值类互斥关系
互斥关系在本文的定义中有两种表现形式: 1) 属性类之间的互斥关系, 本文对这种互斥采取的方法是确定父子关系后, 共享父类的各子类维持在兄弟类这一关系层面上, 不再继续深入推进; 2) 属性的取值有自己的维基百科类别或列表, 这些取值有实际的含义, 在其类别或列表中有成员文章. 这种取值类包含了类之间的互斥关系.
实验将type的所有取值单独从数据集中抽取出来, 针对该组取值类, 检索数据集中所有成员文章的信息框, 提取出所有取值类在数据集中的实例分布, 表14列出了其中一部分属性及对应的页面数量. 在表14中, 数字表示两个取值类在数据集中拥有相同成员文章页面的数量. 由表14可见, 公众与私有没有共享的文章页面, 盈利与非盈利没有共享页面, 商业、 法律和艺术互相没有共享页面. 因此, 公众与私有互斥, 盈利与非盈利互斥, 商业、 法律和艺术两两互斥. 而其他至少拥有一篇成员文章是共有页面的取值类, 将不能被判定为互斥关系, 如盈利与艺术.

表14 属性类型的取值实例分布
综上所述, 为了解决传统方法从维基百科信息框中提取本体信息精准率较低的问题, 本文提出了一种从维基百科信息框中提取本体信息构建结构化类层次的方法. 首先, 将该问题转化为寻找维基百科信息框属性和取值之间可能的3种类关系, 提出一种可行且有效的方法; 其次, 以维基百科的类别数据集为基础进行实验, 分析了该方法的优缺点. 实验结果表明, 该方法能有效解决传统方法提取本体信息精准率较低的问题.
猜你喜欢
新高考·高三数学(2022年3期)2022-04-28
数学物理学报(2021年6期)2021-12-21
数学物理学报(2021年5期)2021-11-19
英语文摘(2021年8期)2021-11-02
数学物理学报(2021年3期)2021-07-19
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
中文信息(2017年12期)2018-01-27
中央民族大学学报(自然科学版)(2015年2期)2015-06-09
读者·原创版(2015年11期)2015-03-01
郑州大学学报(理学版)(2014年2期)2014-03-01
