
考虑环境及装配特征的船舶装配工时估算研究
2020-03-22 02:58:22邵家伟
江苏科技大学学报(自然科学版) 2020年6期
邵家伟,张 浩,苏 翔
(江苏科技大学 经济管理学院, 镇江 212100)
近年来,船舶运输由于载量大、价格低等优点颇受企业追捧,各类船舶的需求量迅速增加.在需求的推动下,国内外订单量不断飙升,世界船舶制造企业得到迅猛发展,生产和管理技术都获得了显著的提升.然而国际船舶制造业的发展也是中国造船业面临的巨大机遇,因此,国内船舶制造企业抓住时机,改革创新,发展迅速,到2016年,我国制造行业新接和手持订单量均位居世界第一,份额分别为65.2%和43.9%[1].在整个船舶制造过程中,船体装配过程繁杂,且装配工时占了建造总工时的1/2左右,可见其对整船工期影响较大.而工时是船舶制造企业的核心数据,作为纽带贯穿于生产管理系统,工时测算不准确将影响整个生产管理活动,例如计划制定、生产调度、劳务结算等.但是当前国内船舶制造企业在工时测算方面由于过度依赖人工经验和定额手册,导致测算结果不准,与实际情况脱节.致使企业管理粗放,并阻碍对生产潜力的挖掘,最终给船舶制造企业带来无法估量的损失[2].因此,对船舶分段装配工时定额估算的研究对于促进我国船舶制造企业精细化管理意义重大.
国内外很多学者对工时定额进行深入研究.在船舶制造方面:文献[3]对工种进行细分,并建立工时定额测算模型,通过BP神经网络算法对工时进行智能测算;文献[4]基于案例推理法(case-based reasoning,CBR)对铁舾件细分工种安装的相似性,采用神经网络算法推算出铁舾件舾装工时定额;文献[5]基于产品相似性检索规则,采用神经网络获取产品工时规律,并开发了船舶装配工时智能测算系统;文献[6]从事物特征表的相似零件识别出发,提出一种基于案例推理和事物特征表的零件工时估算方法;文献[7]对设计工时中的图纸作业和非图纸作业进行研究,建立图纸作业工时模型和非图纸作业神经网络预测模型;文献[8]从能量守恒思想出发根据焊丝(焊条)物理特性,建立相应的知识库或者推理机,实现了焊接工时的智能化测算;文献[9]在深入分析管系设计数据特征的基础上,构建设计物量自动化抽取模型,并用知识库逻辑推理实现工时定额的精确测算;文献[10]研究作业工序特征,并运用测算模型对作业工时进行误差分析;文献[11]基于工作和基元理论研究,建立了工时估算模型,优化工时定额测算步骤;文献[12-14]运用BP算法进行船舶制造工时的测算,实现了工时定额的智能测算;文献[15]通过重置物料清单(bill of material,BOM)结构实现了装配BOM的高效转换.在其他制造型行业:文献[16]面向零件特征层,从零件的拓扑结构复杂度和工艺属性复杂度出发,针对作业要素层和操作者认知层,引入信息熵评价生产要素复杂度和操作认知复杂度;文献[17]将装配工时按特性分为取料时间、定位时间和连接时间,提取影响各部分工时的关键因素,通过计算样本与基准零件的装配相似系数,结合在MATLAB中构建拟合的工时曲线,在函数关系式和GM(0,N)模型中分别预测定位时间和连接时间;文献[18]以案例推理理论为基础,研究零件相似度与工时之间的内在关系,提出了零件相似度的工时估算新方法.
因此,文中针对船舶装配工序,考虑环境因素及特征相似性,为船舶装配工时的计算提供一种客观有效的估算方法.
1 船舶装配工时估算路径和模型构建
1.1 船舶装配工时影响因素分析
船舶装配以装配设计图纸为标准进行规范操作,其作业步骤和流程有着严格的要求.船舶相同位置且结构相似的分段所含有的装配组成相同或者相似,这也就意味着其所采用的装配工艺也相同或相近.因此,这些结构组成相同或相似的分段装配消耗应具有一定的规律以及可学习性.为了准确、快速地计算分段装配总工时,对船舶结构组成特点以及工艺特征进行综合分析,最终得出影响装配工时的主要因素有:
(1) 装配件的长度L.装配件长度越长,装配所需的定位焊数目也就越多,所需时间越长;此外,长度越长,工人操作时的不稳定性增加,时间越长.
(2) 装配件的宽度D.宽度越宽对工人装配时身位的阻碍越大,增加工人移动的困难程度,所以时间越长.
(3) 装配件的质量W.装配件质量越大,增加了吊运的负荷和不稳定性,同时装配件在翻身的过程中耗费的时间越长.
(4) 装配件所需螺栓数目B.螺栓数目越多,所需工人操作的次数越多,时间越长.
此外,装配工作是一个涉及人、机、料、环、法的过程,在工时测算过程中环境因素往往直接被忽略,但根据专家的经验,环境对于装配工时的影响依旧很大.环境是指工人在工作时所处的工作环境和自然环境,工作环境主要包括技术条件、生产管理水平、企业人文、员工职业技术能力等;自然环境主要是自然温度、噪音、震动、不可抗力因素等.而船舶装配基本上都是人工操作,身处自然和工作两大环境当中,冷暖等问题时有发生,所以必不可少会受到环境因素的影响.例如一个工人身处自动化程度高的作业环境,较好的技术条件可以极大提高工作效率;相反,如果技术条件落后,生产效率必将受到限制.
1.2 研究线路
(1) 依据船舶制造企业基本编码体系编写智能抽取编码,形成基于工序特征的智能抽取编码体系,实现对作业工序的精确定位.
(2) 以工序作业对象特征为起点,利用相似算法计算出对象特征不同属性值的相似度,并汇总成特征总相似度,为智能抽取数据提供可靠性保障,保证抽取数据的有效性.
(3) 结合熵权法和群决策理论计算环境系数,并以此对抽取的相似历史数据进行环境系数修正,得到修正后的工时数据.
(4) 运用SPSS软件对修正后的工时数据进行线性回归分析,拟合装配特征与工时之间的函数关系,结合环境系数得到最终的装配工时估算公式.以Z船舶制造企业数据为例,将实际工时与文中方法计算出的工时对比,验证该方法的有效性.考虑环境因素及特征相似性的船舶装配工时估算方法技术路线图如图1.

图1 考虑环境因素及特征相似性的船舶工时估算方法技术路线Fig.1 Technical route of ship man hour estimation method considering environmental factors and feature similarity
1.3 数据抽取模型
文中基于编码技术对装配工序进行编码分类,并在历史数据库中进行编码匹配,对相同船型的相同工序进行精确定位,以获取相似装配工艺特征的历史数据,为拟合装配特征及装配工时之间的关系奠定数据基础.国内船舶制造企业的编码标准繁多,而且大多数并不统一,文中只做示意性介绍,以解释每个部分代码的涵义,如图2.
工序编码一共分为7部分,分别是船型、分段号、施工阶段、工序、施工类型、施工区、工种划分.第一部分是对船型的确定,每一艘船都有固定且唯一的船型编号;第二部分是定位分段;第三部分是对施工阶段的划分,主要分为9个施工阶段;第四部分是确定工序,工序包含主工序、辅工序;第五部分是界定施工类型,包括常规、修改、杂项、工程四大类,其编码均以首字母表示;第六部分是划分施工区,包括7个区域,如机舱区域、货舱区域、上层建筑区域等;第七部分是对工种的划分.可以看出编码的主要目的是为了对相同船型相同工序的定位和特征信息的确定,以保证抽取数据的可靠性.编码分类如表1.

表1 示意编码分类Table 1 Schematic coding classification
例如A-101-03-A-C-E-04表示散货船船体阶段101分段加工阶段机舱结构件装配工序.数据抽取结束之后,再依据从企业历史库中抽取历史案例的工序特征数据计算相似性.
1.4 相似性算法
一般案例推理(case-based reasoning, CBR)中常见的相似性检索方法包括模板检索法、知识引导法、最近相邻策略法以及归纳法等方法[19],但是没有现成的模板,以及缺乏大量的数据,因此在已知工时影响因素时,最适合文中方法是知识引导法.
在运用编码对工序进行分段、施工阶段、工种等对象的确认后,计算装配零构件每道工序特征信息的相似度.如果影响此零构件装配工时的因素是宽度、长度和重量,那么就利用相对应的数据计算宽度、长度和重量的相似度,然后对所有特征信息的相似度进行加权求和,得到整个工序的总的相似度,如Ta、Tb分别为相似工序A和B同属性特征值,则其特征相似度S为:
(1)
但是在每道工序中,每个影响因素对工时的影响程度有大有小,如果每个影响因素的权重都是一样,那么测算出来的相似度有失准确度.因此,文中采用专家打分法按重要性对每个影响因素进行打分,并赋予每个影响因素相应的权重ω,从而有效区分影响因素之间的差别,且赋予的权值满足ω1+ω2+…+ωn=1.
例如装配件A、B特征信息为长度L、宽度D和重量H,这3个因素对工时的影响程度不一,所以需要专家对其性进行打分,并分配权重ωL、ωD、ωH,且ωL+ωD+ωH=1,则该工序3个影响因素的相似度SL、SD、SH分别为:
(2)
最后,工序A、工序B的相似度为所有影响因素相似度的加权总和,即S=SL+SD+SH.根据求得的总相似度在抽取的数据中匹配最具相似性的多组数据,为数据处理和拟合做好数据准备.为保证相似数据的有效性,设定相似度阈值为0.9和1.1,只有满足S∈(0.9,1)∪(1,1.1)时,规则才会触发,即数据被选取.
2 环境系数评价体系
2.1 环境影响大小衡量
环境可以定义为员工在进行某项作业时所处的作业环境,是外力因素,包括工作环境和自然环境:工作环境主要包括技术条件、生产管理水平、企业人文、员工职业技术能力等;自然环境主要是自然温度、噪音、震动、不可抗力因素等.环境评价指标如表2,其中f1~f5为工作环境影响因素,f6~f9为自然环境影响因素.根据船厂技术人员总结经验,环境对员工作业的影响主要体现在舒适度上,越舒适的环境影响因素越小,就越接近标准操作的环境[20].

表2 环境评价指标Table 2 Evaluation indexes of environment
2.2 确定环境系数指标权重
熵值法能够有效地规避人员主观因素对评价所带来的偏差,便于反映评价指标熵值的效用,因此,由熵值法得到的评价指标权重可信度比赋值法等可信度更高[21].
2.2.1 数据标准化
设由n个评价对象以及k个评价指标,评价专家给出的评价矩阵为B=(bij)n×k,bij为评价专家对评价指标i的第j个评价对象的评价值.标准化矩阵R=(rij)n×k.
(3)
(4)
2.2.2 评价指标熵值的定义
设指标i的熵值为:
(5)
式中:pj为第j项指标的熵值,j=1,2,…,k;hij为第j项指标第i个方案所占的比重.
2.2.3 评价指标熵权的定义
设评价指标i的熵权为:
(6)
2.3 确定评价专家权重
2.3.1 计算评价结果的接近程度
采用两个向量夹角的余弦来求解两个不同的评价人员对于同一对象同一指标评估值的接近程度,余弦表示为:
(7)
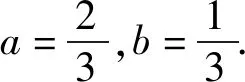
2.3.2 一致性指标的定义
(1) 定义群体一致性指标
(8)
(2) 定义个体一致性指标
(9)
式中:m为评价专家总人数;T为评价指标集合;μ(i,j)、φ(i,j)分别为评价评价专家i和j对于同一对象同一指标评价结果的接近程度.若cosθij
2.3.3 计算评价专家权重
评价专家权重为:
(10)
2.4 确定环境系数
工作环境系数为:
(11)
式中:I为环境系数;n为评价专家的人数;m为评价指标的个数;ωj为指标j的权重;ρi为评价专家i的权重;cij为评价专家i对评价指标j的评价结果.
3 应用分析
Z船舶制造企业是国内一家集产品设计、制造为一体的船舶制造企业,具有悠久的历史.但由于船舶制造不可控因素较多,生产计划变动较大,尤其在装配工程中,严重影响企业的生产管理和计划安排,导致生产紊乱.为了准确有效地进行生产管理,Z企业需要快速提升生产工时测算的准确性.多年的生产制造下,Z企业积累了大量的船舶装配工时数据,为研究提供了条件.
如表2,选用装配阶段槽钢的安装工序进行案例说明,首先由编码体系通过TRIBON软件抽取出相同安装工序的作业数据.抽取部分数据如图2.

图2 抽取数据Fig.2 Extracted data
然后根据式(1)求解总相似度的方法和待求数据(表3第13号数据)从抽取数据中挑选出最具相似度的案例数据(表3第1~12号数据).同时邀请5位专家对环境影响因素进行评价打分,计算环境系数,并用环境系数修正数据,将环境影响因素剥离,然后运用SPSS软件进行回归拟合训练,结合环境系数得出最终装配工时函数,最后将新的具有相似性的事例数据带入,求解出装配工时,并与实际反馈的工时进行对比,验证准确性.
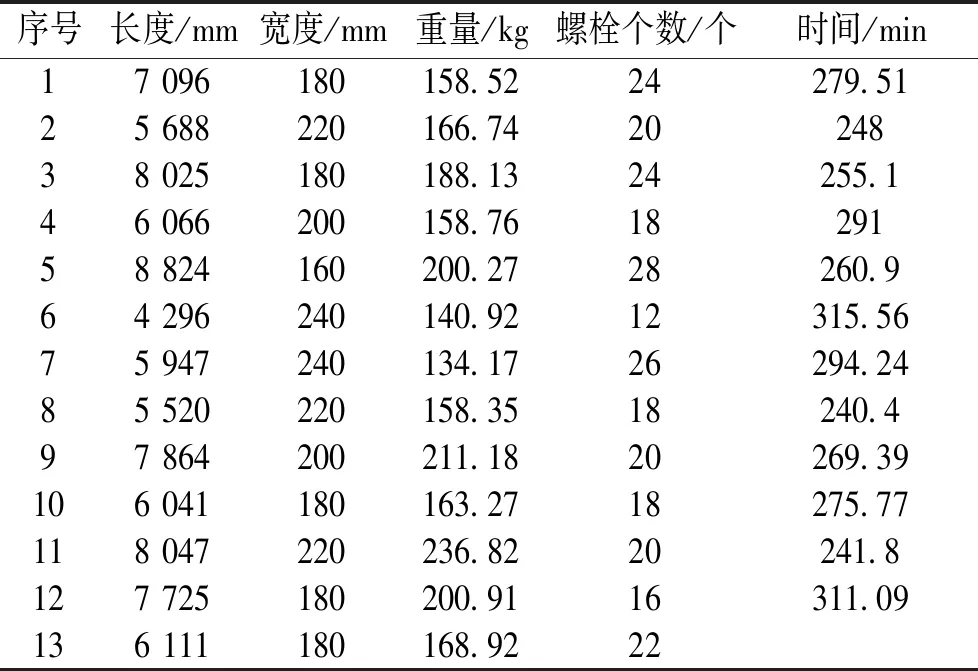
表3 相似数据Table 3 Similar data
由专家根据企业自身情况选出影响装配工时最主要的因素(作业技术条件、生产管理水平、工人职业技术能力、风雪等不可抗力因素、温度),分别给出5位专家对于12组数据中5个评价指标的评价矩阵B,并求出其对应的标准化评价矩阵R.其中一位专家的数据如下:
评价矩阵

标准矩阵为:
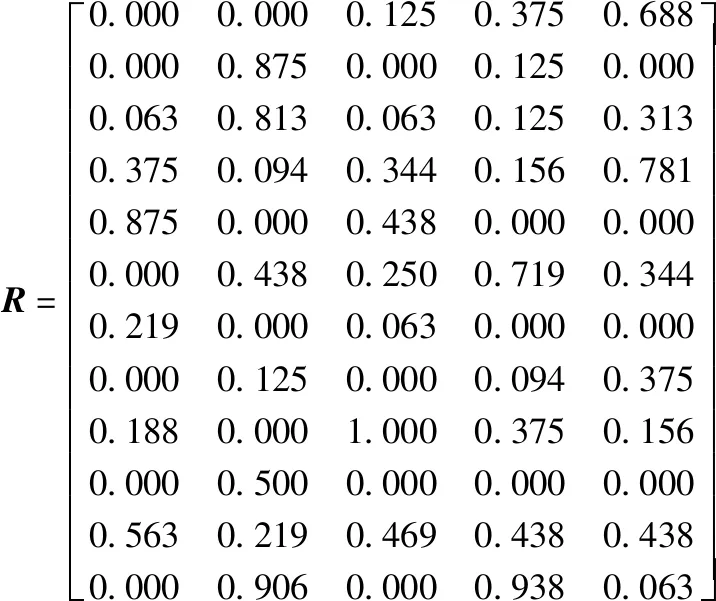
熵值为:
Pi=(0.042,0.068,0.050,0.062,0.059)T
ωi=(0.203,0.198,0.201,0.199,0.199)T
最终,得到评价指标的熵权为:0.203、0.198、0.201、0.199、0.199.
根据如上对专家权重的计算,依次计算5位专家的评价结果和权重,最终得到12组数据的环境系数分别为1.1、1、1、1.2、1、1.4、1.2、1、1.1、1.1、1、1.3.并将环境因素剥离,得到修正后的工时为表4.
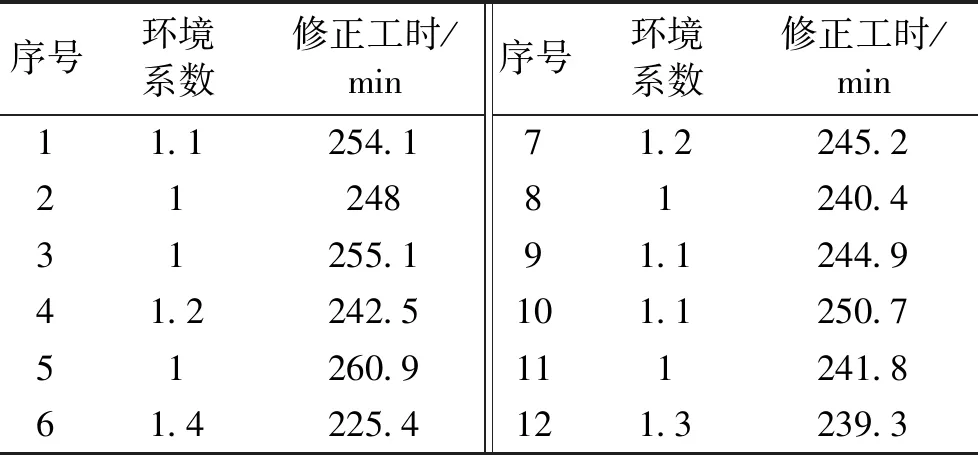
表4 工时修正表Table 4 Time correction table
此时,运用刚刚修正的工时与装配特征建立关系,采用SPSS软件进行线性拟合,得出的结果显著性sig、关系数R、可决系数R2等值均符合要求,最终得到工时拟合函数为:
T1=275.14-0.009×L-0.3×W1+0.231×W2+2.387×B
结合环境系数的工时函数为:
T=T1×I=(275.14-0.009×L-0.3×W1+0.231×W2+2.387×B)×I
式中:I为环境系数;L为长度;W1为宽度;W2为重量;B为螺栓个数.
将拟合的工时函数运用于具有相似性的装配工时预测,表5中Time1为实际运作反馈的工时数据,Time2为文中拟合的线性关系估算的工时,通过对比可以看出,两者误差最大为5.3%,最小为0.2%,表现出较高的准确性.
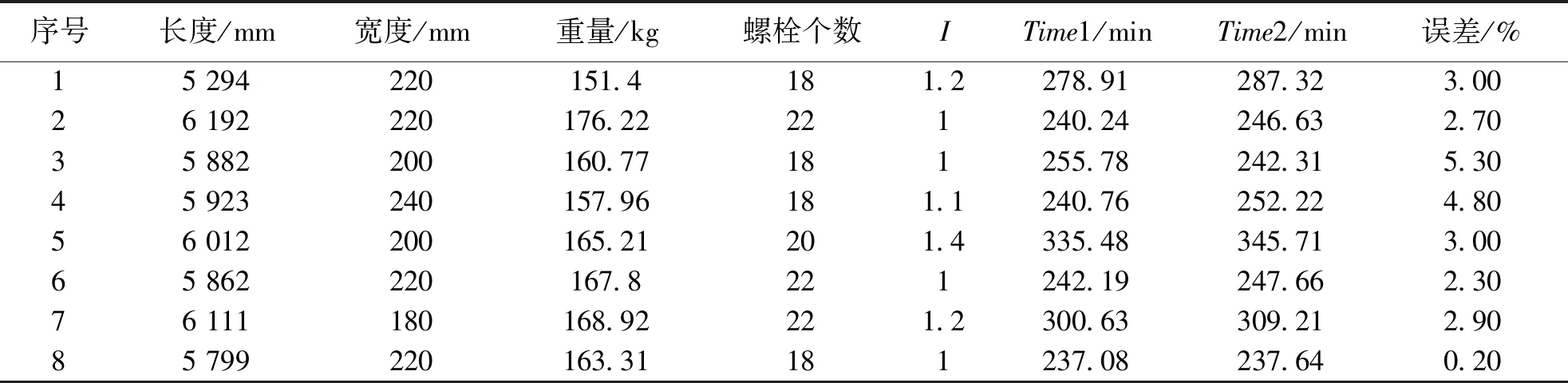
表5 工时估算结果Table 5 Work hour estimation results
4 结论
根据船舶装配工时计算的特点,提出一种基于环境系数以及装配特征参数的工时计算方法.首先根据相似性抽取历史数据,再结合历史数据根据熵权法和群决策理论计算环境系数,并对工时进行系数修正,最后再利用SPSS软件将装配特征参数与工时进行线性拟合,找出之间隐藏的知识.该方法计算方便,准确性高,是对工时计算方法的改进,但其涉及到专家打分等环节,具有一定的主观性,因此以后需要研究的方向为结合物联网等技术,实时获取温度、噪音等生产环境客观数据,以避免环境系数确定的主观性.
猜你喜欢
航空制造技术(2022年18期)2022-12-09 04:10:28
昆钢科技(2022年2期)2022-07-08 06:36:14
军民两用技术与产品(2021年6期)2021-10-14 07:40:58
石材(2020年4期)2020-05-25 07:08:50
哈尔滨轴承(2020年4期)2020-03-17 08:13:40
职工法律天地·上半月(2020年1期)2020-03-02 07:45:06
建材发展导向(2019年10期)2019-08-24 06:24:30
经济技术协作信息(2018年32期)2018-11-30 01:43:18
初中生(2018年15期)2018-06-01 02:14:35
工程建设与设计(2016年1期)2016-02-27 10:50:23
