
一种改进YOLOv3-Tiny的行车检测算法
2020-03-18 03:44刘力冉仇男豪
计算机与现代化 2020年3期
刘力冉,曹 杰,杨 磊,仇男豪
(1.南京航空航天大学电子信息工程学院,江苏 南京 210016; 2.南京航空航天大学无人机研究院,江苏 南京 210016)
0 引 言
图像的分类、定位、检测以及分割是计算机视觉领域的4大重要研究方向。其中目标检测的目的是寻找图像中所有的目标物体,并且确定目标物体的位置[1]。由于光照的影响、遮挡物干扰以及图像中的各类物体本身形状各异,导致目标检测一直是最具有挑战性的问题。
目前目标检测主流算法主要是基于深度学习模型,分为下述2大类:
1)Two-stage检测算法。此方法包括2个阶段。首先产生Region Proposal(候选区域),在此基础上对候选区域进行分类[2]。这类算法的代表是基于候选区域的R-CNN系列算法,如R-CNN、Fast R-CNN、Faster R-CNN等。
2)One-stage检测算法[3]。除去Two-stage算法的候选区域阶段,直接得出物体的位置坐标值以及类别概率,代表性的算法如YOLO和SSD。
精度和速度是目标检测中2个重要的性能指标。随着近几年研究发展,这2类算法在速度和精度上都得到了提升。
R-CNN、Fast R-CNN、Faster R-CNN同属于R-CNN系列,算法的精度较高且发展成熟,目前已在许多行业中应用。YOLOv2和YOLOv3算法[4]在速度上得到很大提升,但是在实际的应用中需要耗费较大的GPU显存。针对速度、精度、GPU显存[5]3个问题,本文选用YOLOv3-Tiny算法,并对其作出改进,使得网络可以在保证精度和速度的同时不占用过多的GPU显存。
1 YOLOv3-Tiny网络
1.1 目标检测评价指标
目标检测技术应用场景丰富,但在实际场景中环境较为复杂,包括目标的形变、相似目标的干扰等,导致各类算法性能参差不齐,此时需要引入相关参数来评价评价参数[6]。本文主要选用IOU、mAP作为评价指标。
目标检测需要定位出图像中物体所在区域,这个区域称为bounding box,译为候选框。针对候选框的定位精度,引出定位精度评价公式:IOU(Intersection-over-Union,交并比)。
IOU[7]定义2个候选框重叠度,将真实框记为A,预测框记为B。重叠度IOU计算公式为:
(1)
IOU代表2个矩形框重叠面积与两者并集的面积之比,SA代表A框的面积,SB代表B框的面积,SA∩B代表A框与B框交集部分的面积,IOU的值在0~1之间,通常来说值越接近于1,代表重叠度越高,相应的候选框更精确。
Average-Precision简称AP[9],即平均精度。精度表示在识别出的图片中被正确识别出的比例,召回率是测试集中所有正样本样例中被正确识别为正样本的比例。AP表示Precision-Recall曲线下面的面积,如果召回率值增长的同时,精度的值保持在高水平,表示分类器的性能比较好,AP值越高。mAP称为均值平均精度,表示多个类别AP的平均值,“mean”意思是对每个类的AP再次求平均值。mAP大小在[0,1]区间内,值越大分类器性能越好。
1.2 基础网路结构
YOLOv3-Tiny算法是YOLO系列的简化版,具有更少的卷积层同时检测速度较快。具体网络结构如图1所示。
YOLOv3-Tiny的主干网络主要有7个大小为3×3的卷积层[10](Convolution)以及6个池化层(maxpooling)。6个池化层中的前5个层的步长是2,最后一层的步长是1,整体网络的输出大小为13×13。在卷积神经网络中,通常输入图像大小不同,输出大小也各不相同。YOLOv3-Tiny网络由浅层网络以及深层网络构成。具有浅的卷积层的深度网络,更容易表征小目标物体;与之相反地,具有深的卷积层的深度网络,更容易表征大目标物体[11]。YOLOv3-Tiny采用的即为这种思想,利用两尺度预测的方式:1)在卷积神经网络之后再连接一个卷积层,这时尺度为13×13,这种方式易于检测大目标物体[12];2)在第1种方式中的倒数第二层进行上采样,得到的特征与上一层得到的26×26层特征相加再通过卷积层输出[13],这时尺度为26×26,该方式易于检测小目标物体。

图1 YOLOv3-Tiny网络结构
2 改进的YOLOv3-Tiny算法
YOLOv3-Tiny算法计算量小、速度快,针对多种目标有较好的检测效果[14],但是并不完全适用于行车的检测,对此本文对YOLOv3-Tiny算法的网络提出改进:
1)改变网络输入图片像素值大小;
2)改进YOLOv3-Tiny网络结构。
2.1 输入图像像素值优化
在对车子的识别研究中表明,车辆信息在水平方向上分布较多,相对地在竖直方向上的信息较少。本文采用改变输入图像尺寸的方式,使得横向信息特征得到更好的表征。具体将输入尺寸从416×416改为672×224,可以保证提取横向信息的同时不影响算法的速度。目标检测算法会将检测图像划分成小图像块,目标的中心在其中某个小图像块之内,则此小图像块负责预测目标。输入图像像素值优化就是涉及小图像块的数量变化。

图2 输入图像示例
本文选用KITTI数据集中的图片,输入图像示例如图2所示,该数据集中图片像素值大小为1238×375,当图片输入到YOLOv3-Tiny网络中,像素值将被调整为416×416,同时检测图像划分成13×13个小图像块。

图3 YOLOv3-Tiny网络输入图像示意图
输入图像在进入YOLOv3-Tiny网络后,网络的横向信息被压缩,具体如图3所示,这样不利于该网络对行车目标信息的学习。对此,本文提出改进思路,将小图像块的数量从13×13改为21×7,改进后的小图像块示意图如图4所示。

图4 改进后的YOLOv3-Tiny网络输入图像示意图
通过图4可以看出,改进后的小图像块数量,基本上维持了原输入图像的形状比例大小,将小图像块的数量对应到图像像素的大小,得出输入图像的像素改为672×224,基于小图像块须保持正方形的比例,提出改进输入图像像素的思路,这样使得输入图像的横向信息尤其是行车目标的信息得到更好的表征,为改进后网络的训练提供帮助。
2.2 聚类分析
在计算机视觉中基于图像的目标识别技术指将目标从图像中检测并标注出来,判断目标物体的类别、位置以及大小。在现实生活中实际目标识别的过程中发现预设候选框[15](anchor)的大小以及个数的选定,对目标识别速度和精度有重要影响。在训练网络的过程中调整边界框宽高维度可以得到预测框[15](bounding box)。对此提出一种思路,在训练阶段时选择较好的预设候选框,为网络预测准确的位置提供帮助。
本文对YOLOv3-Tiny算法在anchor方面做出调整,通过维度聚类确定出最优anchor个数及宽高维度[16]。以KITTI数据集中行车的数据集为例,使改进后的网络结构对车辆类(car)的识别更为精准。处理输入图像时采用网格对其进行分割,在每个网格中设置k个参考anchor,训练以GroundTruth(真实框)作为基准计算分类与回归损失[16]。k个anchor boxes对应k个不同尺度,都具有独立分类结果,优化了网络的准确率,找到最优anchor宽高维度和最优k值[17]。维度聚类分析采用k-means算法,步骤如下:
1)数据集中随机选取k个聚类中心点;
2)遍历数据集中所有数据与每个中心点的距离,将每个数据分别划分到距离最近的中心点所在的集合中[18];
3)求每个聚类集合的所有数据各个维度[19]的平均值,求得的值作为新的聚类中心;
4)重复步骤2、步骤3,直到聚类中心位置不再发生变化。
k-means算法的距离函数如下:
(2)
实验过程中选取k值的方法采用爬山法[20],随着k值大小的增加,目标函数d在某拐点之后变化趋于平缓[21],此处的k值就是聚类个数。其中i表示聚类的类别数,j表示数据集的数据,Box[i]表示每个聚类中心预设框的尺寸大小,Truth[j]表示数据集中行车框的尺寸大小。图5展示的是利用k-means算法对KITTI数据集聚类的结果图,具体是交并比IOU随聚类数目k值的变化曲线图。

图5 IOU与k的关系图
在本文实验中识别的物体只有一类物体,如果出现样本点在空间中混杂在一起时,可以通过改变k值的大小选取最适合的k值进行聚类。依据图5所示,在k值大于6之后,曲线的变化相对平缓,故选取k的值为6,即该聚类为6类,代表初始候选框有6种。初始候选框(预设候选框)的具体数值大小如表1所示。
表1 初始候选框具体数值大小
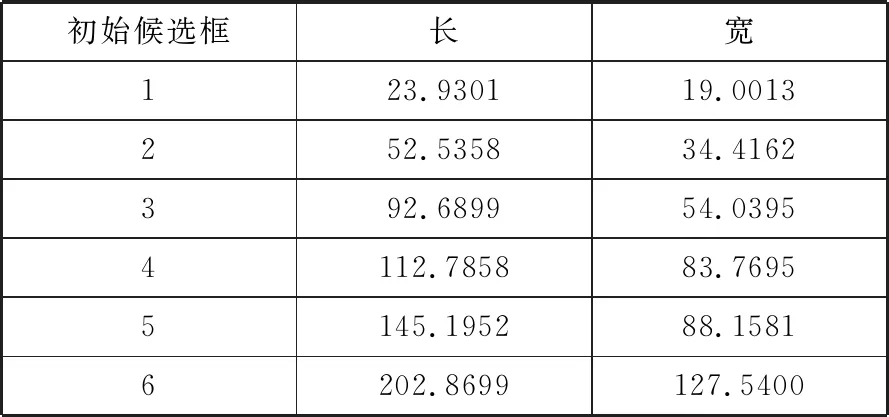
初始候选框长宽123.930119.0013252.535834.4162392.689954.03954112.785883.76955145.195288.15816202.8699127.5400
2.3 改进的YOLOv3-Tiny网络结构
YOLOv3-Tiny网络结构中有7个卷积层,在一定层面上对某些目标物体的特征提取有限,在实际的应用场景中对检测的精度有一定的要求。一般来说,层次越深的网络结构对特征提取的效果会更好,针对YOLOv3-Tiny网络卷积层较少的问题,本文提出增加卷积层的改进方式。

图6 改进的YOLOv3-Tiny网络结构
常用的卷积核大小有3种类型:3×3、5×5、7×7,2个大小为3×3的卷积核堆叠可以替代5×5的卷积核,3个大小为3×3的卷积核堆叠可以替代7×7的卷积核[13]。网络的层数过深存在梯度爆炸或者梯度消失的问题,网络层数过浅则不能充分学习目标的特征,改进的网络结构是在原来的主干网络基础上增加3个3×3的卷积层,达到加深网络的效果。由于网络层数的增加会导致网络的运算量以及模型参数的增加,改进的网络中引入大小为1×1的卷积层[22],目的是减少模型参数并提高网络的学习能力。改进的YOLOv3-Tiny网络结构图如图6所示。
3 实验结果及分析
3.1 实验环境
实验依据实际需要,硬件设备包含计算机和无人机。无人机底部配备摄像头,利用无线图传技术,可实现距离2~7 km内的720 p分辨率实时图传。
系统的搭建同样依赖于软件平台的数据处理。表2是本文实验电脑配置情况。
表2 实验电脑配置
名称相关配置操作系统Windows 10中央处理器(CPU)/GHzIntel Core i5-7500内存/GB8GPU1060GPU加速库CUDA 9.1,CUDNN 7.1深度学习框架Darknet
3.2 图像获取
本文采用无人机获取图像,用到的无人机是四旋翼无人机,型号采用掠食者680,机载单目摄像头型号是飞莹8s,像素大小为1280×720。本文利用无线图传技术将无人机机载摄像头实时拍摄的图像传输至电脑中,图像显示在PC端,运行程序可以实时接收无人机机载摄像头拍摄的图像信息。
3.3 数据集选取及网络模型搭建
本实验选择的数据集是KITTI数据集中的行车数据集,包含了训练集(样本5984张)和测试集(样本748张)。KITTI行车数据集背景也较为复杂,存在车辆遮挡等情况。为了使KITTI数据集适用于YOLOv3-Tiny算法,对数据集进行格式转化,首先将KITTI的行车数据集转化为VOC格式的数据集,在此基础上转化为适用于改进网络的数据集格式。
完成数据集格式转换之后,在深度学习框架Darknet上搭建改进的YOLOv3-Tiny模型。Darknet是应用较为广泛的框架,对多种格式的输入图片均可适用。本文采用的KITTI行车数据集是PNG格式,像素大小是1238×375。
3.4 实验结果
本文分别使用YOLOv3-Tiny算法和改进的YOLOv3-Tiny算法对KITTI行车数据集进行训练和测试。首先利用聚类算法对数据集进行聚类分析,本实验中通过k-means算法得到的聚类值是6类,然后进行模型训练,训练大约经过10 h,通过训练得到了新的模型,利用模型对KITTI数据集中的测试集进行测试,并对测试的结果进行对比分析。采用的评价指标是均值平均精度召回率,实验结果如表3所示。
表3 KITTI行车数据集测试结果

检测方法mAP/%Recall/%YOLOv3-Tiny84.7883改进的YOLOv3-Tiny87.9785
可以发现,本文改进的YOLOv3-Tiny算法的mAP为87.97%,比YOLOv3-Tiny算法提高了3.19个百分点,召回率提高了2个百分点,大大提高了目标识别的精度。

图7 行车检测P-R曲线图
图7是2种网络的行车检测P-R曲线图(Car Detection P-R Curve),其中纵坐标表示精度(Precision),横坐标表示召回率(Recall),虚线表示YOLOv3-Tiny算法检测结果,实线表示本文改进的YOLOv3-Tiny算法检测结果。由此可看出图中实线较虚线精度更高,即本文改进的YOLOv3-Tiny网络精度较高。
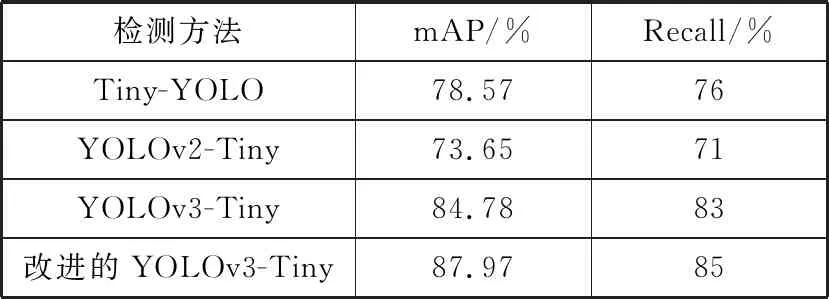
为了对改进后算法的识别精度作更为严谨的评价,引入YOLO系列的简化版本中的其他2种算法的实验数据进行对比分析,具体结果如表4所示。
表4 4种算法在KITTI数据集上的测试结果
检测方法mAP/%Recall/%Tiny-YOLO78.5776YOLOv2-Tiny73.6571YOLOv3-Tiny84.7883改进的YOLOv3-Tiny87.9785
通过表4中的数据可以看出,改进后的YOLOv3-Tiny算法的mAP值比Tiny-YOLO算法高出9.4个百分点,比YOLOv2-Tiny算法的mAP高出14.32个百分点;在召回率Recall方面,改进后的算法较Tiny-YOLO算法提高9个百分点,较YOLOv2-Tiny算法提高14个百分点。与此同时可以发现,原算法YOLOv3-Tiny在mAP和Recall上也均高于Tiny-YOLO算法和YOLOv2-Tiny算法。本文改进后的算法提高了原算法的均值平均精度以及召回率,进一步提高了原算法对行车目标识别的精度。
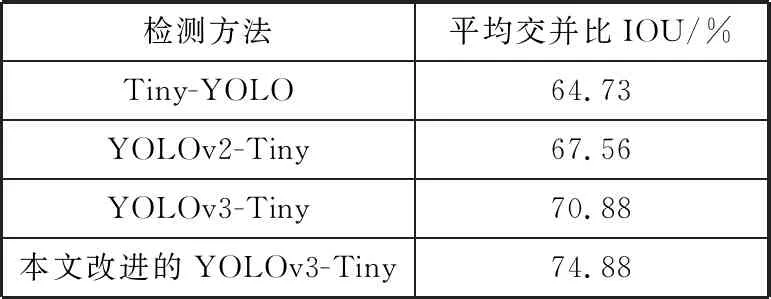
本文将平均交并比IOU作为评价指标,用来评价本文改进网络的定位精度,并以YOLOv3-Tiny算法、Tiny-YOLO算法、YOLOv2-Tiny算法的IOU作为比照,结果如表5所示。
表5 平均交并比测试结果
检测方法平均交并比IOU/%Tiny-YOLO64.73YOLOv2-Tiny67.56YOLOv3-Tiny70.88本文改进的YOLOv3-Tiny74.88
结果显示,对比YOLOv3-Tiny网络,本文改进的YOLOv3-Tiny网络交并比提高了4.00个百分点。表明在测试集上,本文改进的网络产生的预测框和真实框(GroundTruth)的重叠率更高,对目标车的识别精度更高。与此同时改进后的YOLOv3-Tiny算法比Tiny-YOLO算法的交并比提高了10.15个百分点,比YOLOv2-Tiny算法的交并比提高了7.32个百分点。通过这3组数据的对比结果表明,改进后的YOLOv3-Tiny算法提升了算法在检测框上的定位精度
由于要将本文改进的YOLOv3-Tiny网络应用于无人机的实时目标检测,本文使用720 p的视频检测网络的速度,视频的分辨率为1280×720。以YOLOv3-Tiny网络做对照,以Tiny-YOLO算法和YOLOv2-Tiny算法结果作为补充说明,实验结果如表6所示。
表6 检测速度测试
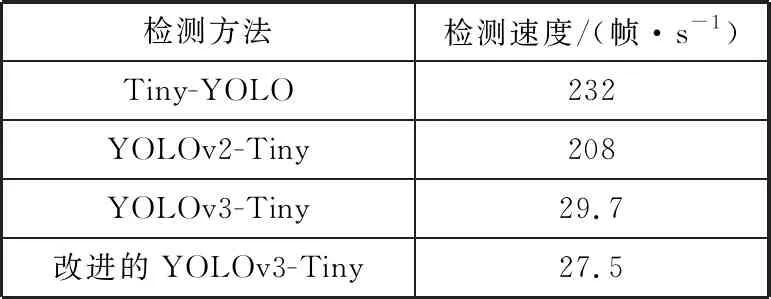
检测方法检测速度/(帧·s-1)Tiny-YOLO232YOLOv2-Tiny208YOLOv3-Tiny29.7改进的YOLOv3-Tiny27.5
在通常情况下检测速度在25帧/s以上即可达到目标识别实时性的要求,实验结果表明,本文改进的YOLOv3-Tiny网络在检测速度上较原网络有所下降,速度为27.5帧·s-1,这是由于改进的网络结构增加了网络层数,但改进后的算法可以满足对无人机图像实时检测的要求。结合表4、表5和表6的数据,可以看出Tiny-YOLO算法和YOLOv2-Tiny算法虽然在检测速度上有较大的优势,但是2种算法的检测框定位精度与识别精度较低。综合算法性能来看,改进后的YOLOv-Tiny算法可以在保证目标识别速度的情况下提高识别的精度,由此本文改进的算法适用于实际目标识别的场景中。
为了验证本文改进的YOLOv3-Tiny算法在实际应用中的效果,对该算法的性能有更加直观的理解,本文选取无人机拍摄的几幅图像,包含小目标、目标互相遮挡等情况,选取KITTI行车测试数据集中的图像作为补充,得到的检测结果如图8所示。

(a) KITTI数据集测试图片a

(b) KITTI数据集测试图片b

(c) KITTI数据集测试图片c图8 KITTI测试集测试结果
在实际应用中,目标检测存在检测物体的被遮挡的难点,在车辆相互遮挡的情况下,信息会丢失和不完整,有很大的可能性导致检测算法对目标物体的漏检。

(a) 无遮挡情况测试图

(b) 小目标情况测试图

(c) 有遮挡情况测试图图9 无人机拍摄图像测试
本文对3幅无人机拍摄的图像应用本文改进的网络检测算法进行检测,图9中(a)图像为无遮挡情况,(b)图像为大目标和小目标情况,(c)图像为遮挡情况。可以发现运用无人机拍摄的图像进行测试,效果较好。检测小目标物体时,检测结果精准,但检测大物体和遮挡物体时检测框出现了部分偏移,没有KITTI测试集检测出的效果好,基本可以满足检测的要求。
由于本文选取的KITTI数据集样本的分辨率为1238×375,相比较无人机机载摄像头拍摄图片的分辨率1280×720,KITTI数据集的图像形状更扁,横向信息更为丰富。故用本文改进的检测算法对无人机拍摄的图像进行检测大目标物体和遮挡物体时,检测框出现了部分偏移,但是检测小目标物体精度依然较高,并且运行速度较快,依然能满足目标检测实时性的要求。
4 结束语
本文基于YOLOv3-Tiny算法提出了改进的行车目标检测算法。针对目前深度学习目标检测算法存在的实时性差、硬件要求高等问题,本文在YOLOv3-Tiny算法的基础上,对数据集进行聚类,改变网络输入图像尺寸大小并改进网络的结构,使得网络更加容易学习车辆的特征信息。依据实验结果可以发现,本文改进的检测算法运用在KITTI数据集上有很好的检测效果,有较好的精度、实时性和定位精度。对比改进之前的YOLOv3-Tiny算法,交并比IOU提高了4.00个百分点、均值平均精度提高了3.19个百分点、召回率提高了2个百分点,实验数据表明改进的YOLOv3-Tiny算法提高了检测的性能。
综合性能对比实验、KITTI数据集测试集检测结果、无人机拍摄图像测试结果,本文改进的YOLOv3-Tiny算法较原算法,在保证检测识别速度的情况下,提高了识别精度,且对硬件设备要求不高,可满足现实场景中目标识别的要求。
猜你喜欢
一重技术(2021年5期)2022-01-18
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
铁道通信信号(2019年6期)2019-10-08
电子制作(2019年11期)2019-07-04
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
电子制作(2018年11期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20
雷达学报(2017年6期)2017-03-26
