
基于信息传递的谣言源检测新算法
2020-03-18 04:46:18刘祖根
计算机与现代化 2020年3期
刘 彻,刘祖根
(云南财经大学信息学院,云南 昆明 650032)
0 引 言
人们因为学习、生活与工作等需要而身处社会网络、生物网络、技术网络等不同类型的复杂网络系统中[1]。社交媒体自其诞生以来就吸引了很多使用者,在不到20年的时间里,全球的社交媒体已经拥有了几十亿的用户。在当今这个信息大爆炸的时代里,随着网络技术的快速发展,以及移动设备的飞速更新,使得社交网络无处不在,社交网络俨然已经成为人们生活中无法缺少的一部分,无论是工作、学习,还是生活、娱乐都离不开社交网络。人们不仅可以与家人和朋友保持联系,还可以随时了解当前正在发生的实事和最新消息。而且人们在社交网络中的角色发生了变化,不再仅仅是接受者,同时也是信息内容的创造者、传播者。许多新闻媒体将自己的宣传媒介放在社交网络上,发布实时新闻,普通用户也能够通过社交网络从个人的角度发表自己的观点和看法,媒体和用户为了尽快地发布信息,信息内容的可信度就受到了威胁,当各大媒体之间出现竞争意识的时候,发布正确的、可信的信息变得尤为困难。假新闻对民主话语可信度的影响以及普遍的错误信息的广泛传播,学者和评论家对其表现出了极大的担忧[2]。据最近的一份报告显示,当前有15.9亿Facebook用户,他们的平均分离程度只有3.57[3]。也就是说,如果几个人在社交网络上发布一个谣言,那么在短时间内会有很多人被其影响。更是有调查显示,平均而言,65岁以上的用户分享假新闻的文章数量几乎是最年轻群体的7倍[4]。
在社交网络中,由于谣言传播过程的复杂性、数据的实时性以及网络的动态变化,如何快速准确地检测出谣言的来源是一项非常具有挑战性的任务。近年来,许多基于Web的系统被开发用来检测和评估谣言,包括:1)TwitterTrails.com[5],一个允许用户确定谣言传播特性的系统;2)TweedCred[6],一个瞬时判断Twitter推文可信度的系统;3)Hoaxy[7],在一个社交网络中跟踪错误信息的平台;4)Emergent.info[8],一个实时的谣言追随者,专注于互联网上的热点事件;5)Snopes.com[9]、Factcheck.org[10],存储一些奇异事件或城市传说。这些谣言检测系统的真实性检测性能验证了网络谣言的真实性,从完全自动化到半自动都有。但是,这些系统没有跟踪或观察扩散过程,也没有检测到所有可能的谣言源。所以在社交网络上发现虚假信息、检测谣言源是一个亟需解决的问题,但在技术上也是一个具有挑战性的问题,因为人们无法使用眼睛直观地判断哪些是虚假信息,哪些是真实信息,甚至在思考之后也无法抉择信息的真假,更无法想当然地猜测谣言的来源。
Shah和Zaman[11]首先提出了谣言源在树状网络中的识别工作,将谣言中心性度量用于信源估计,考虑了信息扩散的SIR模型。节点的谣言中心被描述为从源节点开始的若干确定的传播路径。谣言中心度较高的节点是信息传播的源头。谣言中心测度的有效性在文献[12]中得到了进一步的分析。Dong等[13]利用同样的方法和结果,利用局部谣言中心度量对源进行识别。Yu等[14]将易受影响的节点考虑为有限节点,并将端点(接收谣言但不转发的节点)作为边界节点,利用谣言中心性度量进行源检测。他们考虑了一个有限图用于源检测,并使用消息传递方法来减少顶点搜索以获得最大似然估计。
本文的谣言传播模型以及算法模型,是在Shah等人[11]研究算法的基础之上加以改进。通过真实网络数据的SI(Susceptible-Infected)模型传播仿真,并分析比较本文提出的算法与之前算法的效率结果,实验结果表明,新算法检测谣言源的准确率更高,相同的检测任务,其实际执行时间更短。
1 相关研究及算法模型
1.1 谣言传播模型
流行病模型主要用于寻找病毒性疾病的起源,由于人群中的流行病类似于谣言在社交网络中的传播,所以流行病模型可以用于寻找谣言的来源。在模型中,节点通常具有3种状态:易感状态(Susceptible, S)、感染状态(Infected, I)以及恢复状态(Recovered,R)。每一个节点只能具有其中一种状态,不能同时具有2种或2种以上的状态。当前最为常见的流行病模型有4种:
1)SI模型。最初,节点是易感状态,并且可以被SI模型中传播的谣言感染。易感染的节点是未受感染的节点,如果它们的邻居节点受到了感染,它们被感染的可能性更高,而受感染的节点将永远受到感染。在社交网络谣言传播方面,受感染节点就是已经收到谣言的节点,易感节点是没有收到任何谣言的节点,但是由于相邻的受感染节点,易感节点在收到谣言后可以被感染。
2)SIS模型。在SIS模型中,节点的状态仍然只有易感状态和受感染状态,但在这个模型中,当易感节点受到感染后,它们可以在一段时间后恢复到易感状态。
3)SIR模型。在SIR模型中,节点具有3种状态,易感状态、感染状态和恢复状态。SIS和SIR模型之间唯一的变化是,在SIS模型被感染节点可以变回易感状态,而在SIR模型中被感染节点可以通过忽略消息或者不将消息传递给邻居的方式变为恢复状态。恢复的节点可以一直保持恢复状态。在社交网络中,恢复的节点相当于是知道谣言的节点。
4)SIRS模型。在SIRS模型中,恢复后的节点可能再次成为具有一定概率的易感节点。
所有这些基本的流行病模型都得到了相应的解释,它们用于描述网络节点的感染和恢复过程。作为该领域的另一个基础,不同的模型在寻找传播源时涉及不同的场景,如SI用于检测感染源[15];SIS用于识别谣言源[16]和有影响力的节点[17];SIR用于信息源[18]和网络论坛话题传播[19];SIRS模型用于分析网络中的僵尸网络交互[20]。
假设一个节点网络模型为无向图G(V,E),其中V是模型中的节点数,E是模型中的边数。在最初的情况下,只考虑一个节点V作为谣言源。本算法将采用SI模型作为谣言在网络中的传播仿真,一旦节点Vi是感染状态,将不会变为易感状态或者恢复状态,并且,它可以使邻居节点Vj成为感染状态。
1.2 谣言源极大似然估计器
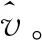
(1)
其中P(GN|v)是在SI模型下观察GN的概率,假设v是源v*。因此,想对所有v∈GN求P(GN|v)的值,然后选择其中值最大的一个。
1.3 谣言中心性


图1 示例图
R(v,GN)
(2)
(3)
再次以图1为例,节点1的谣言中心性为:
2 算法模型
2.1 MPA算法模型

(4)
(5)
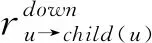
2.2 IMPA算法模型
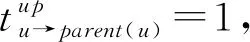
2.3 评估模型

3 实验与分析
3.1 数据集
选用3个网络拓扑结构完全不同的真实社会网络数据集进行仿真实验,具体的数据集信息见表1。
表1 数据集

数据集名称节点数边数平均度数直径Facebook[21]40398823421.88P2p-Gnutella08[22]6301207773.39Wiki-Vote[23]711510368915.67
3.2 实验配置
所有的实验均是基于Python2.7版本完成的,运行平台是PyCharm,计算机的内存是16 GB。
3.3 实验分析
3.3.1 准确率

(a) Facebook
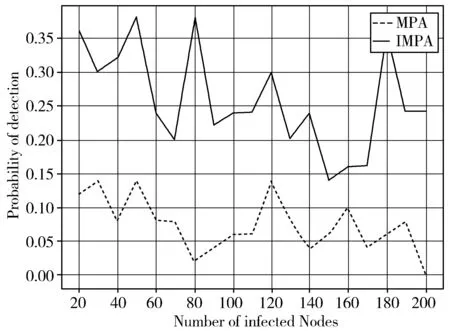
(b) P2p-Gnutella08

(c) Wiki-Vote图2 3种数据集的准确率
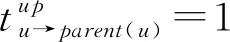
3.3.2 运行时间
实验结果如图3所示,实线代表着IMPA,虚线代表着MPA。从谣言源检测的时间来看,在不同数量的感染节点情况下,IMPA所示时间都要少于MPA所用时间,这就说明了先找到叶子节点,并进行信息的层层传递,比一个个单独判断是否为叶子节点要更快。在需要计算父节点的谣言中心性时,能够直接进行计算,省去相应判断叶子节点的时间,在实际的算法中就相当于减少了犹豫的过程,从而缩短了IMPA的执行时间,提高了算法效率。而且,随着感染节点的增加,2种算法所需时间都随之上升,虽然2种算法的时间复杂度都为O(N),但是IMPA的时间增长速率比MPA增长幅度小。因此,在时间方面,MPA的表现还是要比IMPA略逊一筹。
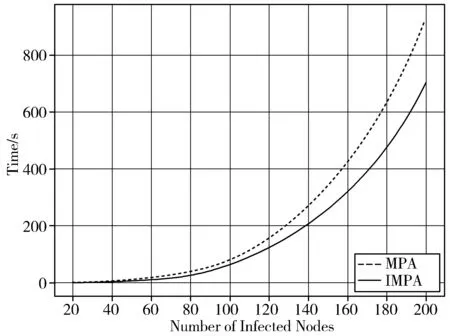
(a) Facebook
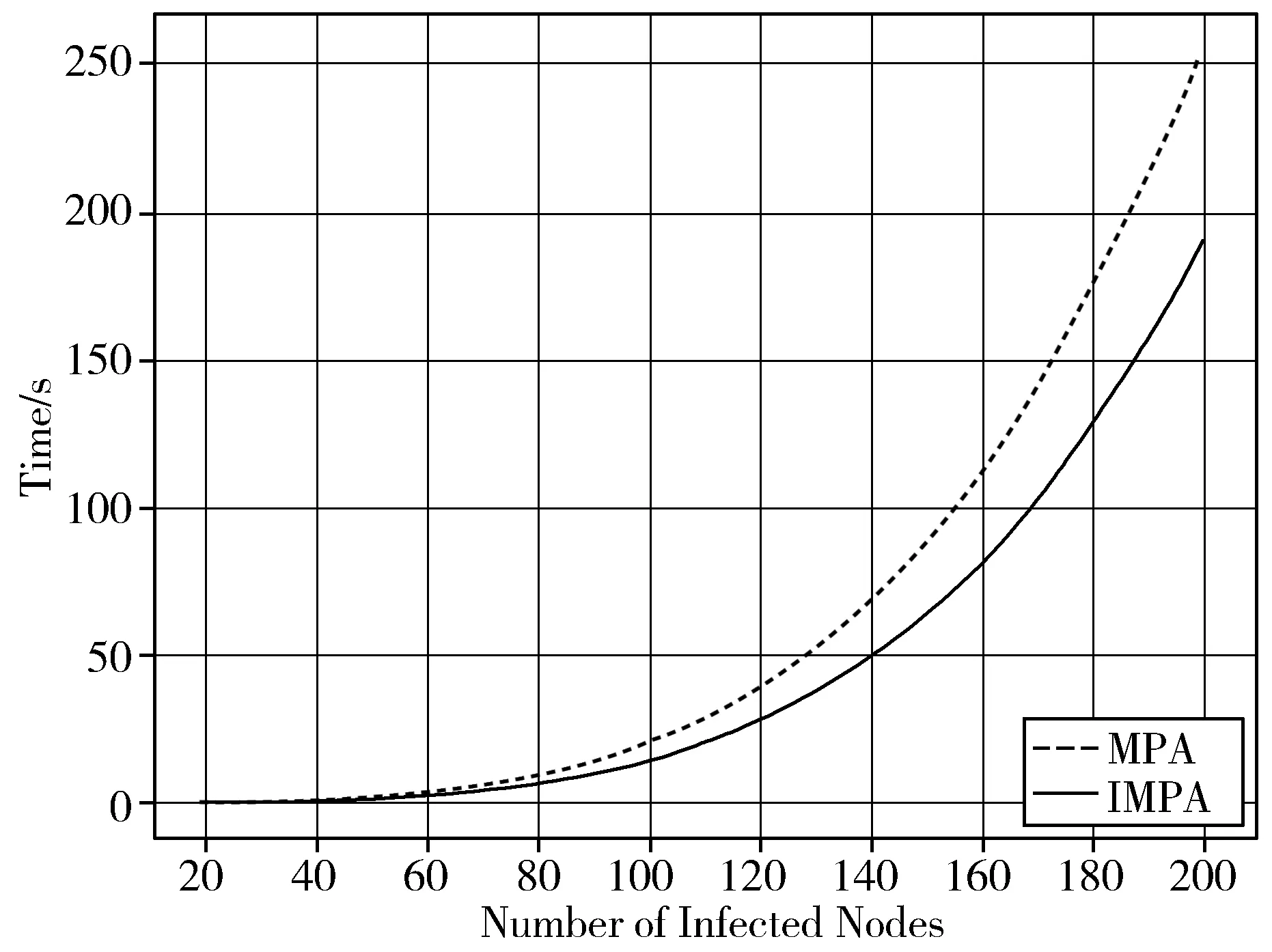
(b) P2p-Gnutella08
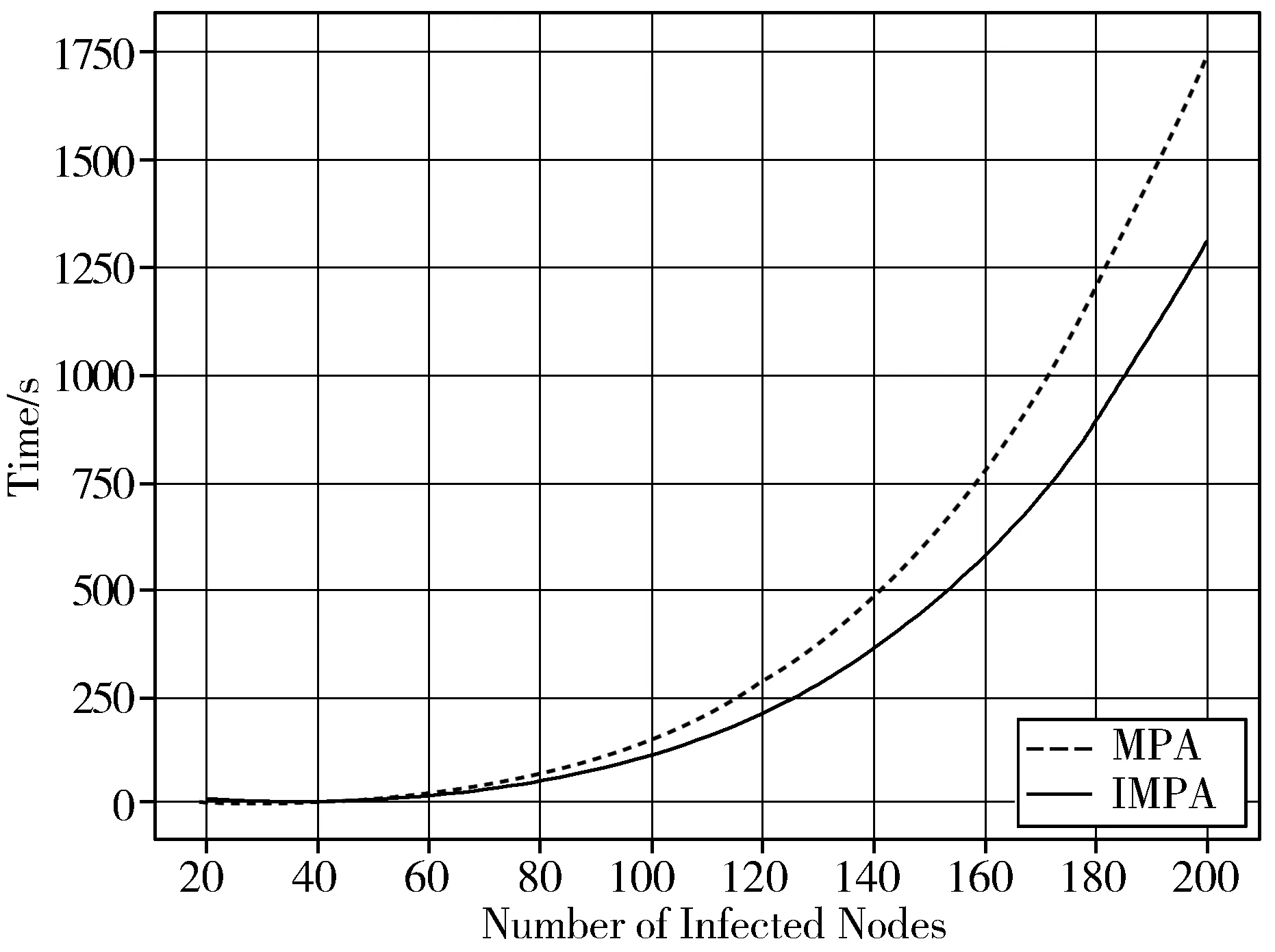
(c) Wiki-Vote图3 3种数据集的运行时间
4 结束语
准确高效地发现社交网络中有谣言传播源,具有非常重要的理论和现实意义。近年来,如何检测谣言以及如何发现谣言的源头受到了多领域学者的广泛关注。相对于谣言检测方法,谣言源检测更具有难度和挑战性。本文通过改进传统的谣言源检测算法MPA,在3种真实网络数据上通过SI模型得到的仿真实验结果表明,IMPA能够在准确率方面略有提升。谣言源并不是一直不变的,谣言传播的路径也会根据事件动态地变化而改变。因此,下一步将研究在SIR模型或SIRS模型中的谣言源检测,并尝试从理论上开展一定的工作。另外,本文工作是针对静态的简单网络进行的研究,进一步工作将扩展到动态网络的研究。
猜你喜欢
英语世界(2023年6期)2023-06-30 06:28:28
意林彩版(2022年2期)2022-05-03 10:25:08
环球时报(2022-04-13)2022-04-13 17:16:04
第一财经(2020年4期)2020-04-14 04:38:56
小学生作文(低年级适用)(2019年5期)2019-07-26 00:45:10
中国盐业(2018年17期)2018-12-23 02:16:56
文苑(2018年17期)2018-11-09 01:29:28
读友·少年文学(清雅版)(2018年12期)2018-04-04 05:16:40
民间文化论坛(2016年2期)2016-12-01 05:41:46
学生天地(2016年32期)2016-04-16 05:16:19
