
基于融合特征的LSTM评分预测
2020-03-18 04:46张尚田
计算机与现代化 2020年3期
张尚田,陈 光,邱 天
(南昌航空大学信息工程学院,江西 南昌 330063)
0 引 言
评分预测问题是当前推荐系统的一个热点研究问题。目前研究较为广泛的评分预测算法包括协同过滤算法(Collaborative Filtering, CF)[1-4]和隐语义模型[5](Latent Factor Model, LFM)等。其中,隐语义模型通过矩阵分解建立用户和对象的交互关系来预测用户对于对象的喜好程度。
许多学者对隐语义模型进行了深入研究。文献[6]提出了贝叶斯分层核概率矩阵分解模型,对数据矩阵的单行进行高斯先验综合,在矩阵的多行上用高斯过程先验。文献[7]提出了因子分解机模型,能够处理大规模数据,同时具有较好的泛化性。文献[8]提出了一种基于概率的隐语义模型,从而预测用户对物品的评分。李晓菊等人[9]提出了一种变分循环自动编码器的协同过滤方法,将商品文本信息变成特征向量,加入到概率矩阵分解模型中。燕彩蓉等人[10]提出了广义高斯分布的贝叶斯概率矩阵分解方法,用高斯分布作为先验分布,可准确获取数据中的信息,但增加了计算复杂度。Liu等人[11]基于LFM,用特征名词代替LFM,增强了可解释性。为解决冷启动问题,Lin等人[12]提出了一种基于用户和物品属性可动态调整参数的LFM模型。传统的CF仅考虑用户评分,未考虑用户偏好和属性,文献[13]在LFM的基础上,通过聚类算法对用户矩阵聚类得到用户潜在属性,再根据用户历史评分计算对象相似度,最后与用户相似度融合得到最终相似度。
伴随社交网络的兴起,许多学者将社交特征数据加入到隐语义模型中,缓解数据稀疏和冷启动问题。王智强等人[14]提出了一种融合信息的概率矩阵分解模型,最终实现社交网络的链路预测。考虑到社交网络中用户间的信任与不信任因素,文献[15-16]将信任机制加入到概率矩阵分解(Probabilistic Matrix Factorization, PMF)中,构建用户-信任评分矩阵,再用概率矩阵分解提取特征,相比之前PMF可以更加真实地为用户推荐,推荐精度得到较大提高。随着深度学习的火热发展,很多学者将深度学习应用于推荐系统的研究[17-18]。文献[19]将宽线性模型和深度神经网络相结合,提出了Wide&Deep learning模型。杨苏雁[20]将外积深度神经网络框架与概率矩阵分解相结合,有效解决了网络结构复杂带来的问题。
隐语义模型(LFM)是一种提取用户和对象特征的行之有效的方法。本文结合深度学习,运用LFM所提取的有效特征,并考虑用户和对象的其他一些标签特征信息,提出一种基于融合特征的LSTM评分预测模型(F-LFM-LSTM),该模型能够较好地提高预测准确度。
1 相关知识
1.1 LFM模型
LFM是通过构造2个低秩矩阵来近似目标矩阵R,以评分预测问题为例,P∈R|U|×f表示用户特征矩阵,其中f表示特征空间的长度,Pu对应于特定用户u,Q∈R|I|×f表示对象特征矩阵,其中qi对应于特定对象i,通常fmin (|U|,|I|)。将用户u对于对象i的评分转换为相应特征向量的点积,如公式(1)所示:
(1)

(2)
其中,‖‖F为Frobenius范数;1(u,i)是指标函数,如果用户u对于对象i进行了评分,则1(u,i)=1,否则1(u,i)=0;λ是正则项的权重参数;(P,Q)是具有局部最小值的二次函数。根据随机梯度下降,求解特征矩阵的参数。首先,用随机正态分布对P和Q进行初始化;其次,通过迭代,每次迭代计算和真实评分rui的误差,如公式(3)所示:
(3)
然后,利用公式(4)更新相应的特征向量:
(4)
其中,γ表示学习率。经过多次迭代,提取到用户特征矩阵P和对象特征矩阵Q。
1.2 LSTM网络介绍
由于循环神经网络(Recurrent Neural Networks, RNN)在训练时会产生梯度消失或梯度爆炸问题[21],1997年Hochreiter等人[22]提出了长短期记忆网络(Long Short-Term Memory, LSTM),有效解决了此问题。在介绍LSTM网络之前,先介绍循环神经网络RNN,其结构图如图1所示。
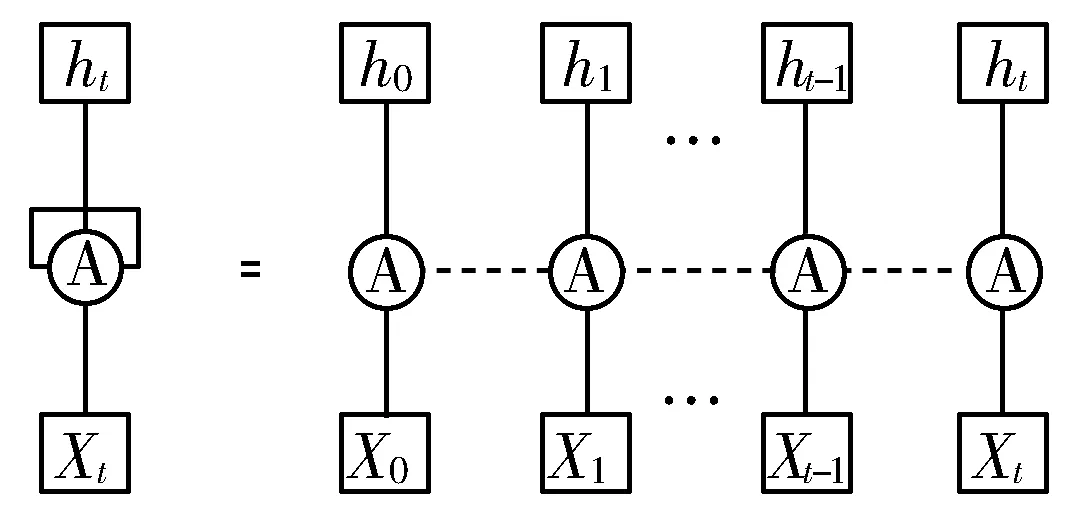
图1 单层单向循环结构
图1单层单向循环结构是循环神经网络中的一种基本结构,可以理解成对一个运算单元单向多次使用。其中,等号左边为RNN的整体结构,等号右边为RNN整体结构展开图;A表示运算单元,每一次运算单元使用的权重和运算规则相同,即A的参数是共享的。
LSTM与RNN的区别在于LSTM在算法中加入了一个用来判断信息有用与否的处理器,此处理器被称为cell。cell由遗忘门、输入门和输出门组成。当信息进入LSTM网络中,根据规则判断信息是否有用,若信息有用则留下,否则被遗忘。具体的LSTM神经网络基本结构如图2所示。
图2中,Ct-1和Ct是LSTM的单元状态又称为长期记忆,ht-1和ht为短期记忆。符号σ代表Sigmoid层,由sigmoid函数实现;从左到右,依次为遗忘门、输入门和输出门。LSTM的工作流程可分成4个步骤:
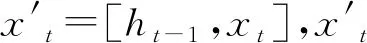
ft=σ(Wf·[ht-1,xt]+bf)
(5)
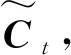
it=σ(Wi·[ht-1,xt]+bi)
(6)
(7)
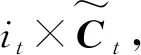
(8)

ot=σ(Wo×[ht-1,xt]+bo)
(9)
yt=ht=ot×tanh (Ct)
(10)
上述公式(5)~公式(10)中,Wf、Wi、WC和Wo分别表示相关的权重向量;bf、bi、bC和bo分别表示相关的偏差向量。
2 基于融合特征的LSTM评分预测模型
本文提出一种基于融合特征的LSTM评分预测模型(F-LFM-LSTM)。首先,运用LFM模型,提取用户和对象的有效特征;然后,融合用户的职业、年龄、性别标签和对象类别标签等辅助信息;最后,训练LSTM得出预测评分。模型的结构如图3所示,具体分为5步实现:收集数据、用户和对象的有效特征提取、建立训练样本集、训练LSTM模型并产生预测结果、评估模型优劣。

图3 F-LFM-LSTM网络模型结构
1)收集数据。本文采用MovieLens100k数据集来验证F-LFM-LSTM模型的实验结果。
2)用户和对象的有效特征提取。首先,初始化用户和对象的随机特征,使其服从正态分布(0,0.02);然后,通过LFM对用户和对象的初始随机特征进行多次迭代,得到用户和对象的有效特征。
3)建立训练样本集。利用第2步得到的用户和对象的有效特征,对其进行合并得到LSTM的样本数据X,如图4所示。

图4 样本数据建立过程图
4)训练LSTM模型,并产生预测结果。首先,对样本数据X进行零均值标准化处理,可加快网络的收敛速度,如公式(11)所示;然后,用处理后的样本数据X*训练LSTM,得到最优的LSTM网络参数。最后,将测试集中的数据用LSTM网络进行预测。
(11)
其中,μ和δ是原始数据集中的均值和标准差;X为原始数据,X*为零均值标准化后的数据。
5)评估模型优劣。将测试集中真实数据和预测数据进行比较,采用均方根误差和平均绝对误差2个评估指标来评价模型的预测效果。
图3所示的是F-LFM-LSTM评分预测模型框架。首先对每个用户和对象的有效特征进行初始化,通过LFM得到每个用户和对象的有效特征;然后通过图4的方式建立输入LSTM的样本数据,从而确定LSTM输入层大小;最后训练LSTM,得出本次实验数据的最佳网络参数。
从图4可知,输入到LSTM网络的样本数据是由用户和对象的有效特征合并所得。
由于LFM模型只考虑用户-对象评分信息,并没有考虑用户和对象的标签信息,因此,本文又融合了用户和对象标签信息到F-LFM-LSTM模型扩展区中。用户的标签信息考虑年龄、职业和性别;对象的标签信息考虑电影的类别,如爱情片、动作片、科幻片等。将标签信息与有效特征相结合得到新的样本数据,再用LSTM进行训练,最后预测评分。
在实验过程中,对于其中的参数设置,特征向量的初始值服从正态分布(0,0.02),通常参数值λ太小或太大会导致测试数据集的性能降低,因此本文将LFM的正则化参数λ设置为0.01,同时将学习率γ也设为0.01。LSTM网络的优化器选择Adam,损失函数选择MSELoss,网络的学习率LR=0.0001,每批次训练样本大小batch_size=10。实验采取五折交叉验证法,最终结果为5次实验结果的平均值。
3 实验结果与分析
3.1 数据来源
MovieLens100k(ML100k)数据集(https://grouplens.org/datasets/movielens/)包含943个用户对1682个对象进行100000个评分,ML100k中评分矩阵的稀疏度为6.30%。评分范围为1~5分。MovieLens look数据集细节如表1所示。
表1 MovieLens100k数据集细节
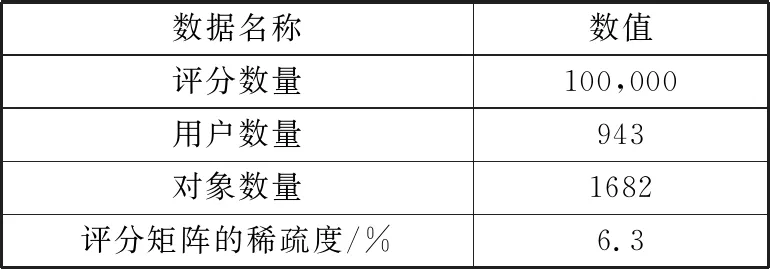
数据名称数值评分数量100,000用户数量943对象数量1682评分矩阵的稀疏度/%6.3
3.2 评价指标
本文采用均方根误差(Root Mean Square Error, RMSE)和平均绝对误差(Mean Absolute Error, MAE)作为评估指标,来衡量F-LFM-LSTM模型的优劣。指标值越小,则预测精度越高。
(12)
(13)

3.3 结果分析与比较
为检验F-LFM-LSTM模型的预测效果,本文研究了LSTM隐藏层特征数量(hidden size)对RMSE和MAE的影响。图5和图6为LFM特征长度为100时,LSTM隐藏层特征数量对RMSE和MAE的影响。从图5和图6可知,LSTM的隐藏层特征数量为256时,RMSE和MAE值较小,模型有着较高的预测准确度。
为进一步研究LFM模型所提取特征的特征长度对F-LFM-LSTM模型预测的影响,本文研究了在LFM的不同特征长度f的情形下,F-LFM-LSTM模型的预测结果,如图7和图8所示。相比于单一的LFM模型,F-LFM-LSTM模型在不同特征长度f下都较为显著地提高了预测准确度。
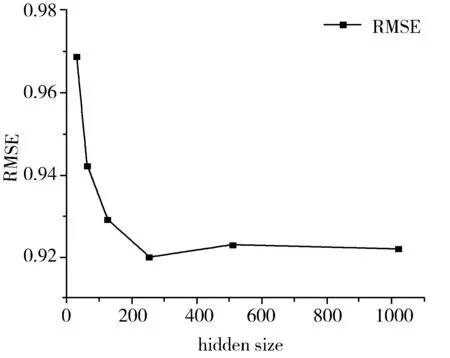
图5 LSTM隐藏层特征数量对RMSE的影响
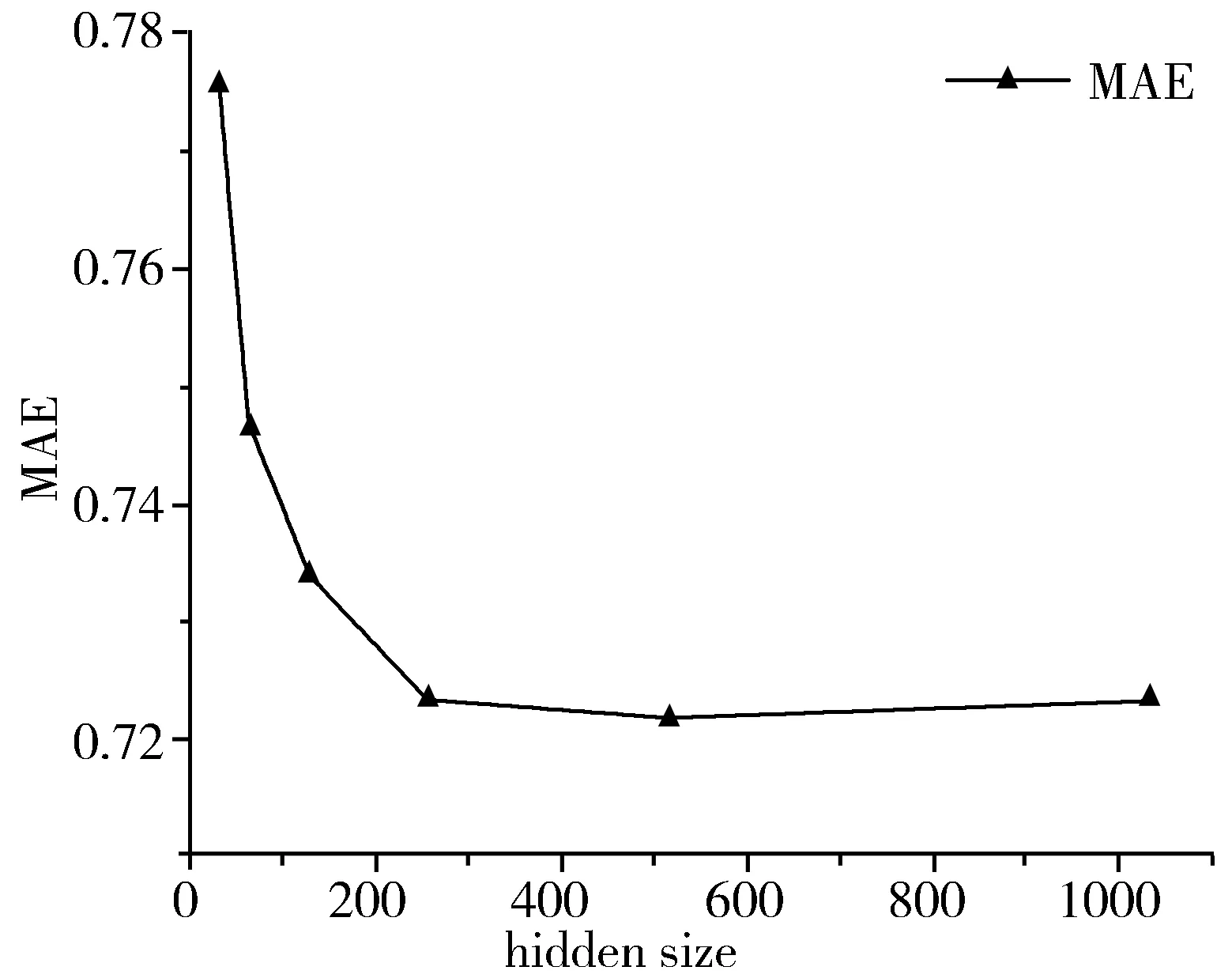
图6 LSTM隐藏层特征数量对MAE的影响

图7 特征长度f对RMSE的影响
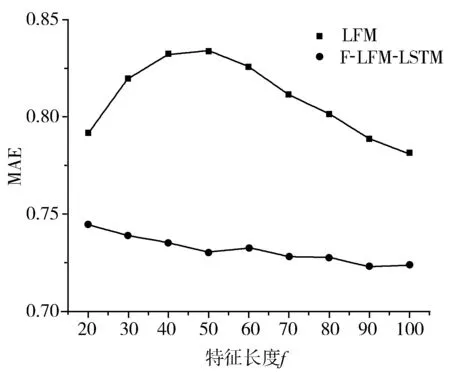
图8 特征长度f对MAE的影响
此外,F-LFM-LSTM模型有较好的可扩展性,在模型的扩展区可通过添加用户和对象不同的标签信息,进一步研究哪些标签信息有助于改善模型的预测效果。本文研究了用户的职业、性别、年龄和对象类别等标签信息以及这些标签信息的不同组合对模型预测结果的影响,实验结果如表2所示。
表2 标签信息对实验结果影响
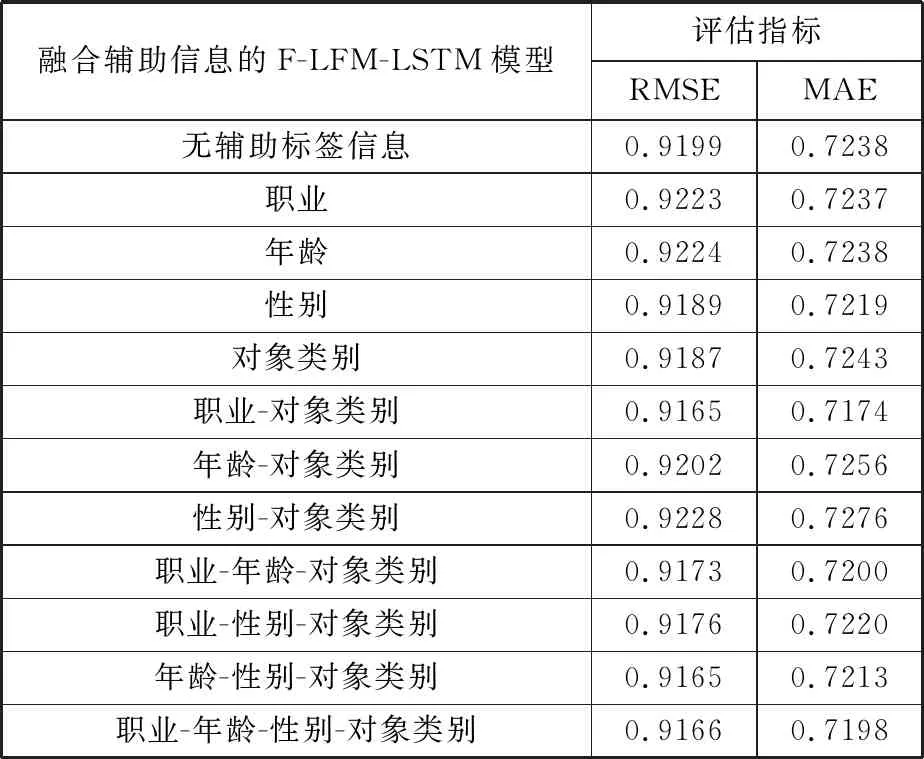
融合辅助信息的F-LFM-LSTM模型评估指标RMSEMAE无辅助标签信息0.91990.7238职业0.92230.7237年龄0.92240.7238性别0.91890.7219对象类别0.91870.7243职业-对象类别0.91650.7174年龄-对象类别0.92020.7256性别-对象类别0.92280.7276职业-年龄-对象类别0.91730.7200职业-性别-对象类别0.91760.7220年龄-性别-对象类别0.91650.7213职业-年龄-性别-对象类别0.91660.7198
从表2可知,在F-LFM-LSTM模型扩展区中添加用户和对象的标签信息可以提高预测效果,但是部分标签信息并没有提高预测精度,如只考虑用户年龄信息,其预测效果反而变差。同时,实验表明,并不是添加的标签信息越多,预测效果就越好,如考虑职业-性别-对象类别这3种标签信息的预测效果反而没有只考虑职业-对象类别这2种标签信息的预测效果好。
最后,将F-LFM-LSTM模型与单一的隐语义模型LFM、均方差(Mean Square Difference, MSD)算法[23]和加权斜率(Weight Slope One, WSOA)算法[24]进行比较,实验结果如表3所示。
表3 基于MovieLens100k的5种算法比较

算法评估指标RMSEMAELFM0.99790.7813MSD0.94700.7453WSOA0.94430.7419F-LFM-LSTM(无辅助标签信息)0.91990.7238F-LFM-LSTM(职业-对象类别)0.91650.7174
从表3可知,相比于LFM、MSD和WSOA算法,本文所提出的F-LFM-LSTM模型能够取得更好的预测效果,其中,融合了职业-对象类别标签信息的F-LFM-LSTM相较于无辅助标签信息的F-LFM-LSTM模型预测效果更优。
4 结束语
随着深度学习不断发展,将深度学习与推荐系统相结合的研究越来越广泛。本文提出了一种基于融合特征的LSTM评分预测模型,融合了LFM模型能够提取用户和对象的有效特征的优势,并考虑了用户与对象标签等辅助信息的影响。实验结果表明,相较于几种较为广泛研究的算法,本文所提出的F-LFM-LSTM模型能够取得更好的评分预测准确度。在所融合的标签辅助信息中,融合职业-对象类别标签信息的表现更优。
猜你喜欢
湖南税务高等专科学校学报(2021年4期)2021-08-30
中学生数理化·中考版(2020年10期)2020-11-27
车迷(2018年11期)2018-08-30
民族古籍研究(2018年1期)2018-05-21
海峡姐妹(2018年3期)2018-05-09
意林(2018年3期)2018-03-02
西夏学(2016年2期)2016-10-26
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
