
基于Spark的出租车轨迹处理与可视化平台①
2020-03-18 07:54杨卫宁邹维宝
计算机系统应用 2020年3期
杨卫宁,邹维宝
(长安大学 地质工程与测绘学院,西安 710054)
由于城市化进程加剧以及汽车数量增加,城市交通问题日益严重[1],通过分析各种空间数据解决交通问题是当前研究的热点.出租车提供广泛且灵活的交通运输服务,是城市交通的重要组成部分.出租车轨迹数据记录了城市道路与居民的流动信息,对出租车轨迹数据的挖掘分析有助于城市智慧交通[2,3]的建设,有利于制定合理的城市交通政策、合理配置城市公共交通、缓解城市交通拥堵.
随着经济进步与空间信息技术的发展,出租车轨迹数据的规模呈指数级增长.为了存储和分析生成的大量数据,需要一种新的架构来处理出租车轨迹数据.大数据技术的发展,为快速、有效地处理大规模空间数据提供了可能.Spark 是Hadoop 生态系统中新兴的杰出分布式计算框架,具有高容错性和高可扩展性.利用Spark 框架的并行存储、并行计算与内存计算的优势,可以精确有效地分析和研究城市交通问题,实现大数据驱动的智慧交通.
高效益的驾驶员拥有丰富的驾驶经验与运营策略[4],获取高效益的出租车轨迹数据对研究更有意义.本文提出一种效益指数模型用于对出租车效益进行量化排序,提取高效益出租车作为研究对象.在此基础上设计了一个基于Spark 的出租车轨迹处理与可视化平台,可以快捷有效地对高效益出租车的运营模式与载客策略进行可视分析.该平台开发对出租车轨迹数据处理和可视化具有以下贡献:
(1)将Spark 与GeoTools(Java GIS 工具包)相结合实现对出租车轨迹数据的快速处理与空间分析计算;
(2)设计了基于蜂窝形格网与DBSCAN 算法的出租车载客热点可视化方法,通过时间约束,多视角展示载客热点的变化趋势;
(3)提出基于缓冲区的交互式轨迹查询算法,该算法通过时间与空间约束,将符合查询条件的轨迹数据信息可视化.
1 相关工作
1.1 出租车轨迹研究
基于位置的服务(Location Based Services,LBS)的快速发展,通过出租车轨迹数据能够很好的反映出出租车的运营规律、城市交通状况以及居民出行特征.不同领域的研究人员对出租车轨迹进行了各种研究.
在出租车运营分析方面,Weng JC 等[5]提出基于浮动车数据的出租车运营分析模型(包括载客里程、里程利用率、驾驶员工作强度等参数).Liu L 等[4]通过分析出租车GPS 数据了解出租车的运营模式,对驾驶员进行分类,揭示收益高的出租车的运营时空特征.Zhang DQ 等[6]通过挖掘出租车GPS 轨迹,从寻客策略、载客运营策略以及服务区域偏好三个角度研究出租车服务策略.
在出租车热点分析方面,Liu DY 等[7]开发了SmartAdP可视化分析系统,利用出租车轨迹数据用于确定广告牌放置的热点区域.Chang HW 等[8]预测与时间、天气和出租车位置相关的载客需求分布,通过K-means、层次聚类和DBSCAN 进行热点分析,改善出租车运营管理.B-Planner 系统[9]使用出租车轨迹数据提取乘客上下车热点用于杭州市夜间公交路线规划.
在可视分析方面,Wang ZC 等[10]设计了一个基于GPS轨迹的城市交通拥堵的交互式可视化系统,用于探索和分析城市的交通状况.牛丹丹等[11]通过处理出租车轨迹数据,从时间、空间维度对乘客出行特征进行可视分析.Huang XK 等[12]提出的可视化方法TrajGraph,通过图结构存储和可视化出租车轨迹记录的交通信息,研究城市的交通模式.
1.2 大数据技术应用研究
大数据技术的应用,可以快速、有效地处理大规模空间数据.近些年出现了许多处理空间数据的分布式计算框架,如基于Hadoop 扩展的SpatialHadoop[13]与Hadoop-GIS[14],基于Spark 扩展的GeoSpark[15]、LocationSpark[16]与Simba[17]等.但Hadoop MapReduce计算模型会将中间结果输出到磁盘上,产生大量I/O操作,难以实现大规模空间数据处理.Spark 框架的性能要优于Hadoop 框架,通过使用RDD,其基于内存的并行计算架构性能更优.
在城市交通领域,谭亮等[18]基于Spark Streaming和Kafka 构建了一个实时交通数据处理平台,处理双基基站采集的数据,用于解决城市交通问题.段宗涛等[19]通过Spark 框架挖掘出租车乘客出行特征.Mao B 等[20]基于Spark 处理、挖掘时空数据,提出了一种基于八叉树的时空数据三维体绘制可视化框架,对纽约市2009-2015 年的出租车轨迹数据进行了可视化.
针对上述研究成果,本文结合Spark 框架的优越计算性能设计开发出租车轨迹处理与可视化平台.
2 框架与模型研究
2.1 Spark 分布式计算框架
Spark 是一个类Hadoop 的开源分布式计算框架,扩展了广泛使用的MapReduce 计算模型,用于构建大型的、低延迟的数据分析应用程序.其主要特点是能够在内存中进行读写计算,提升计算性能.
弹性分布式数据集(Resilient Distributed Dataset,RDD)是Spark 中的基本数据抽象,代表一个只读、可分区、可并行计算的数据集合.RDD 可以全部或部分地缓存在内存中,在多次计算中重用;通过实时分发任务到所有节点,可以保证计算的并行性.RDD 支持两种类型的操作算子:转化操作与行动操作.转化操作会由一个RDD 计算生成一个新的RDD,行动操作会对RDD 计算出一个结果并将结果输出Spark 系统.
Spark SQL 是Spark 用来处理结构化数据的一个模块,在数据存储上采用列存的方式优化数据存储[21],可以更便捷地处理出租车轨迹数据.Spark SQL 的核心编程抽象为DataFrame,一种以RDD 为基础的分布式数据集,记录有数据的结构信息.同时提供SQL 语句对数据进行操作与管理,以DataFrame 形式返回结果.
2.2 效益指数模型
当前城市中频繁出现的出租车拒载、空载等现象,导致出租车运营成本增加,城市公共交通运行效率低下,乘客出行需求得不到满足.针对这一问题,如何筛选出高效益的出租车满足本文研究的数据需求,是当前所要解决的问题.
Qin GY 等[22]发现缩短搜索时间并提高行驶速度有利于增加收入,孙飞等[23]发现出租车单次里程长对应着单程收入高,但若要效益高同时还要考虑寻客时间内的开销.本文将单次载客轨迹与相邻前一段寻客轨迹相结合作为一次有效行程,建立了出租车效益指数模型.效益指数F是关于出租车的单次行程收入I、单次里程利用率K1与单次寻客时长T0(min)的函数,有利于对出租车效益进行量化排序:

出租车的单次行程收入I根据某城市的出租车计价标准确定:

其中,VS表示出租车起步价格;V表示出租车超里程单价(RMB/km);DS表示出租车的起步里程(km);D1表示出租车载客里程(km).
里程利用率K1是指载客里程与现实里程之比:

其中,D0表示出租车寻客里程(km).
一般情况下,寻客时间越长,认为此次载客的效率越低,本文采用寻客时长的倒数即T0对效益计算加以时间控制.可以得到效益指数的计算公式:

计算某辆出租车一天的效益指数如下所示:

其中,n表示当天该出租车的载客次数.
3 平台设计与实现
3.1 平台架构
由于浏览器软件具有高扩展、易维护、不需要安装特定软件等优势,本文采用B/S 软件技术架构进行平台构建,开发了一个集大数据处理、可视化和交互于一体的“出租车轨迹处理与可视化平台”,平台架构如图1 所示.

图1 平台概览图
在大数据处理阶段,平台基于Spark 框架处理原始数据,经过数据预处理及效益指数模型计算后提取出高效益出租车轨迹数据,计算高效益出租车特征数据作为后续可视化的数据源.
可视化阶段由3 部分组成:(1)运营特性分析将高效益出租车特征数据进行统计计算以图表形式进行可视化;(2)载客热点可视化结合地图数据与载客点数据,允许用户使用蜂窝形格网与DBSCAN 算法对不同时段高效益出租车载客点进行热点可视化;(3)对于轨迹查询与可视化,提取高效益出租车单条载客轨迹的轨迹相关因子并在地图上进行轨迹可视化.
3.2 基于Spark 的轨迹大数据处理
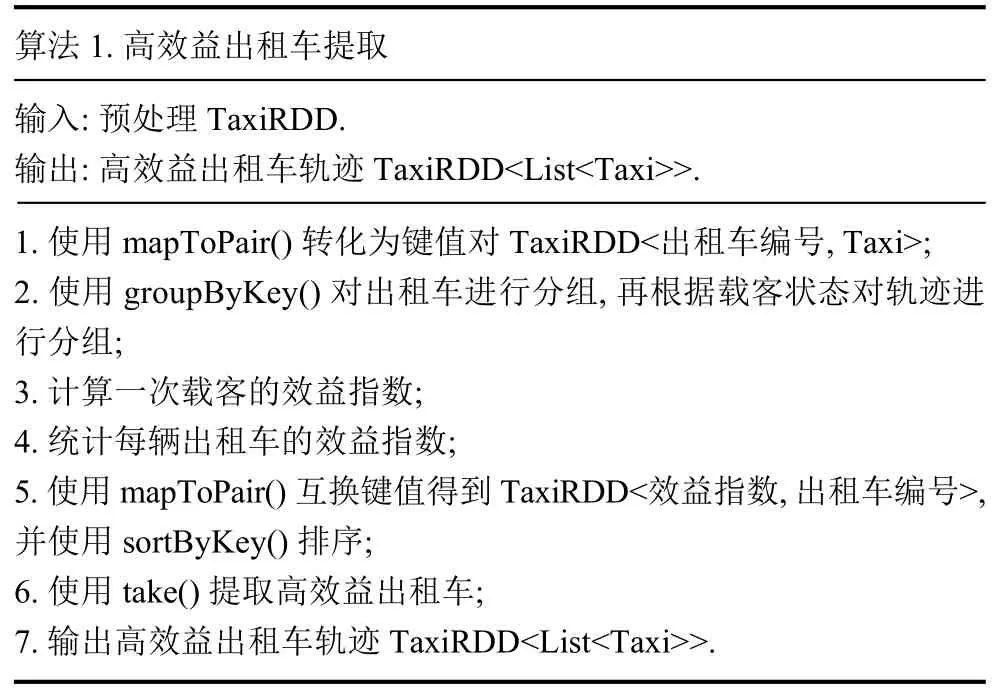
本文利用Spark RDD 和Spark SQL 处理出租车轨迹大数据,处理流程如图2 所示,包括数据读取与封装、数据预处理、高效益出租车提取以及可视化特征数据集计算.
数据读取与封装,将某一天的出租车轨迹数据以字符串形式读取至RDD 中,构建Taxi 类进行封装,扩展RDD 为TaxiRDD,将初始RDD 转化为TaxiRDD.
数据预处理,将TaxiRDD 导入建立的Spark SQL数据表中,Spark SQL 会根据TaxiRDD 自动分配字段名称及数据类型,使用SQL 语句对数据进行预处理,包括剔除异常数据、数据去重等操作.
高效益出租车提取,将预处理完成的DataFrame导出为TaxiRDD,运用Spark 提供的转化算子计算出租车效益指数并排序,提取高效益出租车并输出高效益出租车轨迹数据TaxiRDD<List<Taxi>>.计算过程如算法1 所示.

图2 Spark 处理流程图
?
可视化特征数据集计算,对高效益出租车轨迹数据TaxiRDD<List<Taxi>>中轨迹点计算得到高效益出租车可视化特征数据集.数据集保存至本地文件夹作为后续可视分析的数据源.
3.3 运营特性分析功能
对高效益出租车的运营特性进行分析,可以为广大出租车驾驶员的运营策略提供帮助.运营特性主要包括高效益出租车每小时载客量分布、单次寻客时长分布、单次载客时长分布、单次载客距离分布等特性.平台提供日期范围选择,允许查询任意日期范围的高效益出租车运营特性.利用Spark 读取选中日期的可视化特征数据集,进行统计计算,计算结果以JSON 格式传输至前端,使用ECharts[24]在浏览器界面实现交互式图表展示.
3.4 载客热点可视化功能
本功能提供日期范围选择与时间范围选择,支持蜂窝形格网与DBSCAN 空间聚类算法计算高效益出租车载客热点.
格网结构有利于分析大型空间数据集,而蜂窝结构是覆盖二维平面的最佳拓扑结构,六边形也是边数最多的无缝多边形.本文采用蜂窝结构的格网可视化载客点分布状况,实现过程如下:
(1)利用ArcGIS 构建蜂窝结构图层;
(2)利用GeoTools 将蜂窝单元读取为若干Polygon几何对象,将载客点读取为若干Point 几何对象;
(3)使用Spark 对Polygon 与Point 进行“Contains”空间拓扑运算,计算结果生成shp 文件(图3(a));
(4)将shp 文件使用ArcGIS Server 进行发布,即可在浏览器上进行可视化(图3(b)).

图3 蜂窝形格网载客热点可视化
但基于网格的载客热点计算在一定程度上降低了热点计算的准确性.故在此基础上实现了DBSCAN 算法计算载客热点.DBSCAN 是基于密度的空间聚类算法,能够将具有高密度的区域划分为簇,并可在带有噪声的空间数据中发现任意形状的聚类.设定合适的Eps 邻域和最小包含点数MinPts 进行聚类是DBSCAN算法的核心.根据文献[25]对出租车热点区域范围的定义,将Eps 设定为50 m.在Eps 参数确定的情况下,MinPts取值过小将会产生过多类簇,反之将会忽略大量非噪声对象.结合本文研究数据,经过多次试验,发现MinPts 设置为20 最为合适.
本文在Spark 中实现了基于KD-Tree 最邻近搜索的DBSCAN 空间聚类算法,用于改进由于数据量较大造成聚类时间长的问题.设定参数Eps:50 m,MinPts:20,计算得到聚类结果后,将聚类结果中的每个类中心作为核心聚类点,进行逆地址解析.
3.5 轨迹查询与可视化功能
城市交通中,不同区域间通常存在多条可达路径,各路径蕴含丰富的信息[26],可用于城市道路交通分析.本功能提供某一天的轨迹查询请求,同时设置空间约束,提出了基于缓冲区的交互式轨迹查询算法.计算过程如算法2 所示.

?

?
采用多视图协同交互的方法,当鼠标悬停在地图上某一区域,单击并拖动鼠标在地图上绘制O/D点缓冲区(图4),拖动过程中控制面板文本框会显示当前绘制的O/D点坐标与缓冲区距离.将控制面板中文本框内容作为输入数据.查询结果使用天地图JavaScript API 进行轨迹可视化.
4 实验结果与分析
4.1 数据描述
实验用到的数据集为成都市2014 年8 月17 日至23 日共13 000 辆出租车的运营轨迹,每天的数据记录时间为6:00-24:00,数据总量为18.3 GB.数据集以天为单位并采用txt 格式进行存储,每个轨迹点包含以下属性:出租车编号,纬度,经度,时间,载客状态.载客状态是出租车是否载有乘客的标签(1 表示载客,0 表示空驶).
经过效益指数模型计算,选取Top 20%的出租车作为高效益出租车共计807 267 条轨迹,提取高效益出租车可视化特征数据集,并据此分析高效益出租车的运营规律.
4.2 高效益出租车运营特性分析
对7 天的高效益出租车进行运营特性分析.如图5所示,统计各小时内的载客量,分析高效益出租车在一天内不同时段载客量的变化特征.在6:00-9:00 时段载客量急剧增加,到10 时达到早高峰,在13 时达到午间需求高峰.从13:00-16:00 呈现缓慢下降趋势,在19:00-22:00 载客量又开始迅速增加,并在21 点达到晚高峰.另外工作日与休息日的载客量分布略有不同.在工作日,13:00-18:00 载客量呈下降趋势,并在18 时载客量最少;而在休息日,13:00-18:00 载客量分布较均等.

图4 查询缓冲区绘制

图5 高效益出租车每小时载客量分布图(8 月18-22 日为工作日,8 月17 日与23 日为休息日)
将7 天的数据作均值计算,得到高效益出租车的寻客时长、载客时长以及载客距离的分析结果.图6展示了高效益出租车单次寻客时长分布结果,发现高效益出租车寻客时长相对较短,60%的驾驶员会在2 min内寻找到乘客,说明高效益出租车驾驶员对客源分布与道路状况非常熟悉.图7 展示了高效益出租车的单次载客时长分布结果,图8 为单次载客距离分布结果.高效益出租车的主要服务时长在20 min 内,其中15 min以内的载客次数占总数的66.2%,为高效益出租车主要服务时域.76.1%的高效益出租车的单次载客距离多集中在8 km 以内,为高效益出租车主要服务半径.

图6 高效益出租车单次寻客时长分布图

图7 高效益出租车单次载客时长分布图

图8 高效益出租车单次载客距离分布图
4.3 高效益出租车载客热点可视化分析
蜂窝形格网可视化可以宏观地展现城市不同时间的载客热点变化趋势与空间分布趋势,便于观察高效益出租车载客分布的动态过程.DBSCAN 空间聚类算法可视化可以发现高效益出租车的核心聚类点,更细致地得到高效益出租车载客中心位置.
图9 展示了7 天6 个时间段的蜂窝格网载客热点分布,由绿到红代表载客密度的不断增大.可以看出,高效益出租车的载客分布大致在二环路内,随着时间的推进向南三环路扩展.载客热点主要分布在市中心、商场、医院、旅游景点及重要交通枢纽等地块.
图10 展示了21:00-24:00 时段的DBSCAN 聚类载客热点分布,五角星代表计算得出的核心聚类点.点击五角星,弹窗会显示当前核心聚类点的地址信息.可以发现,机场(图10Ra)、旅游景点(图10Rb)、春熙路商业区(图10Rd)、火车站等都属于客流集中区域.此外,载客热点还包括大学周边(图10Rc)、休闲娱乐场所(图10R)等区域.
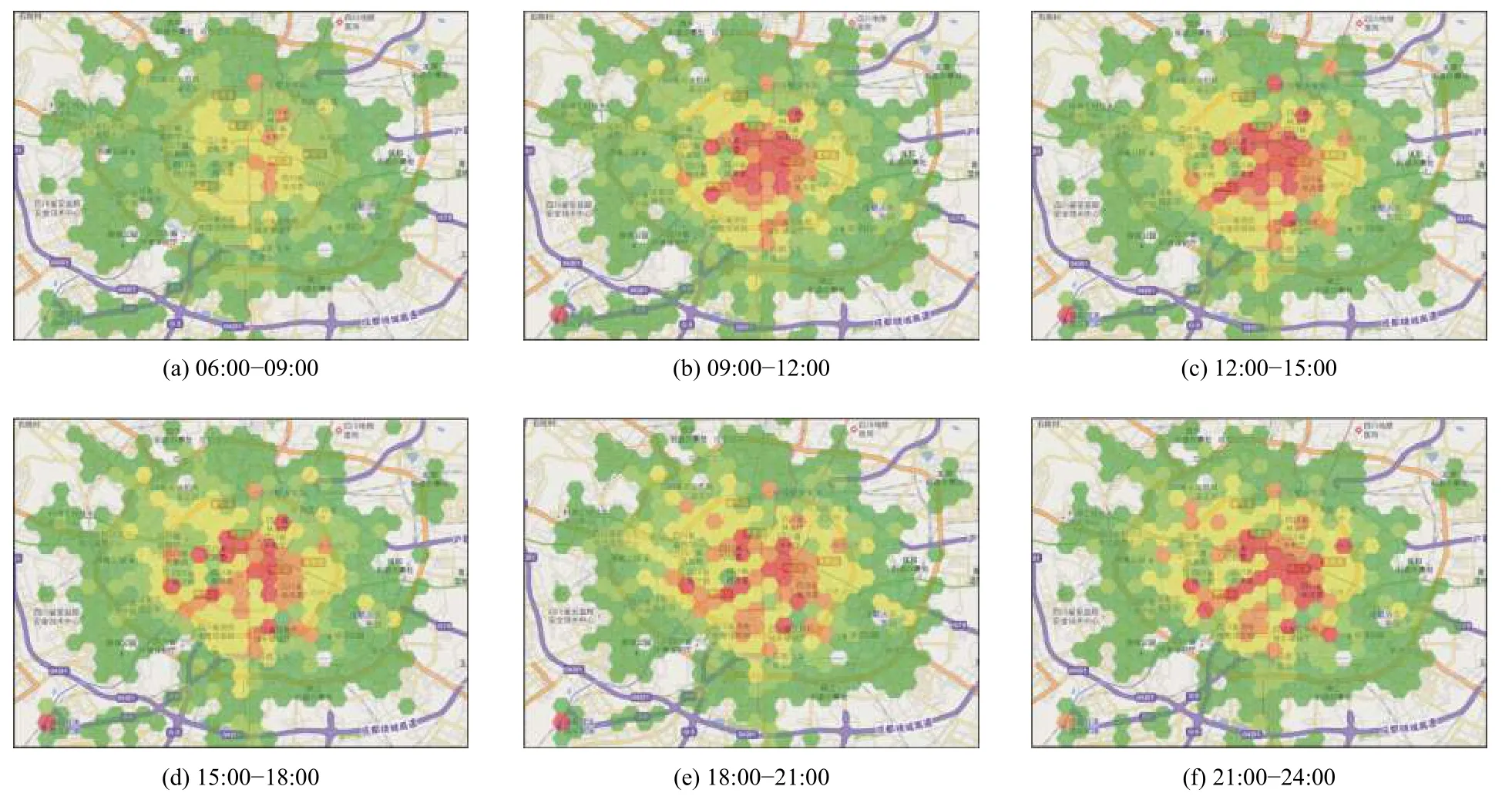
图9 各时段蜂窝形格网载客热点可视化

图10 DBSCAN 聚类结果可视化
4.4 高效益出租车轨迹查询与可视化
通过在地图上绘制起点缓冲区OB 与终点缓冲区DB,可视化起点缓冲区与终点缓冲区中的多条轨迹,并提取轨迹相关因子.选取8 月17 日与23 日的数据,将OB 设置在春熙路地铁站附近,缓冲区半径为155 m,将DB 设置在宽窄巷子长顺上街附近,缓冲区半径为260 m.共查询出31 条轨迹,图11 展示了部分轨迹可视化结果.其中,轨迹a、b、d、e 为高效益出租车频繁选择路径,轨迹c、f 只出现过一次,为特殊路径.
轨迹可视化结合轨迹相关因子,可以了解当前区域的道路交通状况与分析驾驶员的路径选择行为.表1展示了图11 中轨迹a 在不同时段的轨迹相关因子,发现a2 的运营时长最长,a3 的运营时长最短,说明a 路径在午间车流量较大,较为拥堵,晚间车流量较小,驾驶速度较快.图11 中轨迹d、e、f 为相同时段选择不同路径的轨迹,表2 罗列了其轨迹相关因子,发现轨迹d 行驶距离最短但运营时长最长,轨迹f 行驶距离最长但运营时长最短.可以发现当前时段d 路径较为拥堵,想要较短时间到达目的地需要选择绕行避开拥堵区域.

图11 轨迹可视化(A 标注为起点,B 标注为终点)

表1 针对图11(a)中轨迹a 不同时段相同路径的轨迹相关因子表
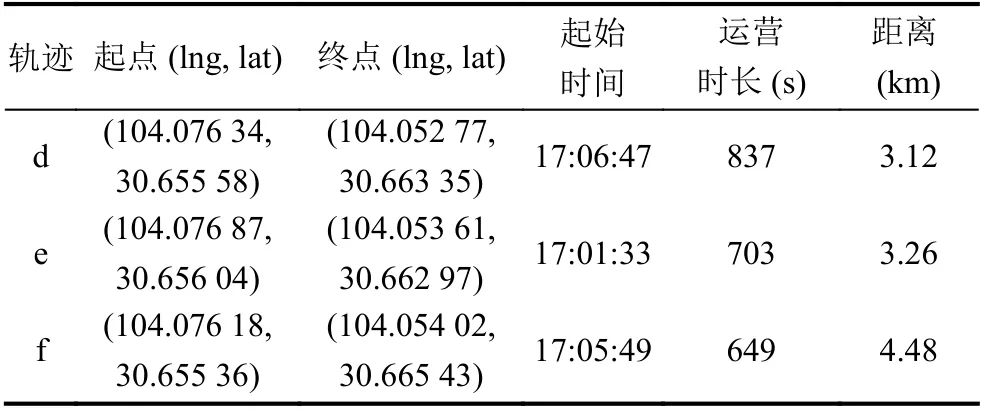
表2 相同时段不同路径的轨迹相关因子表
5 结束语
本文实现了一个基于Spark 的出租车轨迹大数据处理与可视化平台,设计效益指数模型提取高效益出租车用于可视化分析.运营特性分析,对研究高效益出租车运营模式、提升出租车效益具有重要意义.对载客热点进行分析,有利于合理配置城市公共交通、提高载客效率.轨迹查询与可视化,可用于城市道路交通分析、研究轨迹相关因子对路径选择行为的影响.以成都市出租车轨迹数据作为研究实例,验证了平台的有效性.
在未来研究中,将继续完善平台功能,如添加三维可视化、提供寻客推荐功能、实现实时出租车数据分析服务.同时希望平台可以应用于不同地区,比较不同地区出租车运营模式与载客策略的异同.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
商用汽车(2021年4期)2021-10-13
计算机应用与软件(2021年7期)2021-07-16
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
快乐语文(2018年7期)2018-05-25
高校招生(2017年1期)2017-06-30
互联网天地(2016年1期)2016-05-04
中学科技(2008年12期)2008-12-26
