
基于LSTM多特征联合的缺血性脑卒中诊断模型
2020-03-18 09:42骆轶姝邵圆圆陈德华
智能计算机与应用 2020年10期
骆轶姝, 邵圆圆, 陈德华
(东华大学 计算机科学与技术学院, 上海 201620)
0 引 言
近年来,人工智能在疾病诊断中的应用不断延伸,缺血性脑卒中疾病的临床辅助诊断也得到越来越多关注。缺血性脑卒中作为一种急性脑血管疾病,占中国脑卒中约70%左右[1];且随着人们工作压力及生活方式的改变,呈现发病率高,发病原因复杂的发展趋势,为临床医生带来诊断压力[2]。因此,基于人工智能的缺血性脑卒中辅助诊断问题的研究,对医生和患者来说,均具有重要意义。
本文以上海市某医院的真实患者电子病历为基础,考虑缺血性脑卒中疾病的发病原因,选取当前病历数据中的超声、生化以及个人基本信息作为源数据,在LSTM模型基础上搭建双向LSTM多特征提取子模型,实现了多特征联合的缺血性脑卒中的辅助诊断。相对传统诊疗模式强化了客观因素,为医生对该疾病诊断提供有效辅助。
1 相关工作
国内外学者关于疾病智慧医疗辅助诊断开展了大量研究。有些学者在支持向量机、决策树等机器学习模型下,实现对疾病数据的线性学习,但该类方法难以捕获复杂特征学习问题。近年来,以LSTM模型为基础的疾病诊断方法受到广泛关注,可以建立增加了特征序列输入的学习模型,例如实现基于LSTM模型的心脏病诊断[3]、脑血管疾病诊断对疾病时序检查特征的学习等[4]。也有学者在此基础上综合后向特征计算,提出双向LSTM模型[5],该方法在文本分类问题中表现较好,例如融合前向和后向特征的双向LSTM模型实现对心血管疾病病历数据挖掘的辅助诊断[6]。
基于上述研究,本文提出LSTM多特征联合的缺血性脑卒中辅助诊断模型,运用数据预处理方法,设计从不同特征提取子模型中提取信息并进行向量融合,降低不同类型检查数据间差异所带来的模型学习能力;另外,模型中多特征层次上自注意力机制的特征加权,弥补不同特征间存在的信息关联性,提升模型分类性能。
2 模型建立
2.1 多特征联合建模
基于LSTM多特征联合的缺血性脑卒中诊断模型包括输入层、特征提取层、分类层和输出层。模型总体结构如图1所示。
其中输入层由预处理的超声指标、生化检查指标和基本信息组成;特征提取层经3个双向LSTM搭建的子模型学习特征信息;分类层的各特征向量,是在模型特征融合的基础上,增加自注意力机制分配获得;输出层用于输出疾病诊断结果。
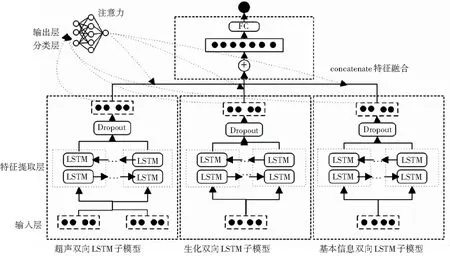
图1 模型总体结构
2.2 特征提取
双向LSTM建立的3个特征提取子模块分别为超声特征提取、生化检查特征提取及基本信息特征提取。
(1)超声特征提取。将患者结构化后的颈动脉超声指标作为该超声特征提取模块的输入,提取超声中有关影响疾病的重要信息。超声特征提取子模块的设计如图2所示。
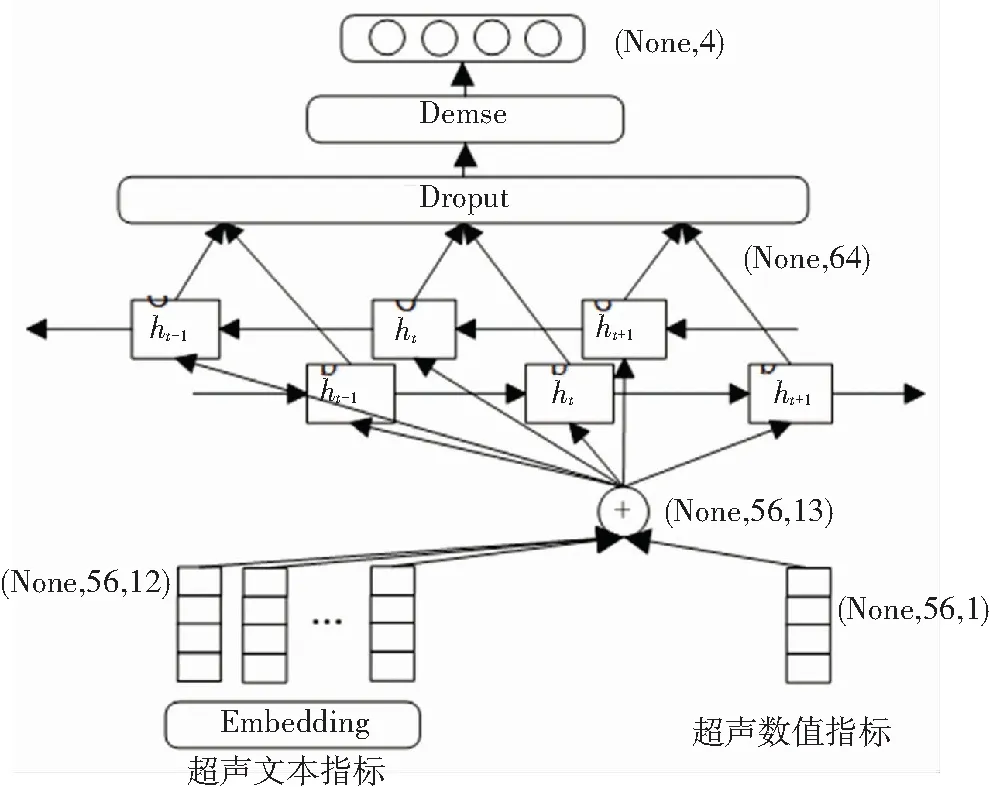
图2 超声特征提取子模块
由图2可知,针对超声中的文本指标,采用神经网络中Embedding层加载Word2vec模型实现向量化;并将超声中的数值指标填充为相同形状的1维特征;融合后输入双向LSTM模型中进行信息提取,其中t时刻前向隐藏层特征信息的计算如式(1)~(6)所示。
ft=σ(Wf[ht-1,xt]+bf),
(1)
it=σ(Wi[ht-1,xt]+bi),
(2)
(3)
(4)
ot=σ(Wo[ht-1,xt]+bo),
(5)
ht=ot×tanh(Ct).
(6)
式中:Wf、Wi、Wc、Wo为共享权值参数矩阵,bf、bi、bc、bo为偏置值,通常随机初始化。由t-1时刻输出的特征向量与当前时刻输入特征的计算,得到t时刻隐藏层的ht的特征信息。最后由该时刻的两个隐藏单元的输出向量连接构成该时刻输出。计算如式(7)~式(9)所示。
(7)
(8)
(9)
由Dropout以一定概率丢弃神经元个数,减少模型复杂带来的过拟合问题。最后经一个Dense全连接层将该模块提取的特征向量做非线性映射转化为(None,4)形状的特征向量。
(2)生化检查特征提取。生化检查特征提取子模块的设计如图3所示。首先,直接利用预处理的生化指标转化为三维特征,由双向LSTM模型中神经元计算生化检查中特征的前向和后向特征,充分提取特征中具有的信息;其次,连接Dropout网络丢弃层,由一个Dense全连接层将高维的特征压缩为(None,4)形状的特征向量。

图3 生化检查特征提取子模块
(3)基本信息特征。提取基本信息特征子模块的设计原理同生化指标模型设计,仅输入特征形状为(None,12,1),故此处分析省略。
2.3 疾病分类
疾病分类模块将各子模块提取的形状相同的特征向量连接自注意力机制[7],分配特征权重,实现多特征联合的诊断模型训练学习。其中自注意力计算如式(10)所示。
(10)
式中:α(xt,xt')表示特征向量中的每个特征与该特征向量之间加权值,突出各类型特征的重要程度。最后经两层Dense全连接层由Sigmoid激活函数作为分类器,输出结果。其中Sigmoid计算如式(11)所示。
(11)
3 多特征数据预处理
3.1 多特征数据
患者病历中3种多特征数据通过医疗卡号和住院号实现关联。
(1)超声数据。作为缺血性脑卒中发生常见的原因之一,颈动脉超声一定程度上可以反映缺血性脑卒中发生与否及严重程度。结构化后的指标数据组成的超声数据,见表1。

表1 超声数据
其中斑块狭窄率根据美国超声会议中标准转化可输入数据预处理形式[8]。
(2)生化检查数据。生化检查对临床中疾病的筛查验证具有重要意义。本文选取的生化指标共计8个,包括CHOL(总胆固醇)、CRP_1(C反应蛋白)、GLU1(空腹血糖)、APOA(载脂蛋白A)、APOE(载脂蛋白E)、MO#(单核细胞计数)、TG-B(甘油三酯)以及UHDL(高密度脂蛋白)。生化检查数据见表2。

表2 生化检查数据
(3)基本信息数据。病历数据中患者基本信息包含性别、出生年月、身高、体重、sbp收缩压、dbp舒张压等。出生年月转化为年龄,身高体重转化为BMI(身体质量指数,衡量人体是否健康及胖瘦的一个指标)。同时高血压、糖尿病及高血脂常伴随缺血性脑卒中患者,因此也作为缺血性脑卒中研究的指标之一加入患者的基本信息中。基本信息数据见表3。

表3 基本信息数据
3.2 多特征数据预处理
(1)Word2vec。Word2vec,一种词向量化技术,能够实现语义空间信息到向量空间上的映射。本文使用Skip-Gram思想计算词的上下文概率分布,由建立Word2vec模型对语料库编码,神经网络中加载实现词向量化。Word2vec词向量化示意如图4所示。
图4 Word2vec词向量化示意
(2)one-hot。one-hot是一种通过N位状态寄存器对N个状态编码,实现离散特征映射到欧式空间的独热编码方式,将模型特征中非连续性数值,即离散型数据通过编码的方式进行转换。一方面提高模型的计算特征之间距离的效率,另一方面对数据特征维度上起扩充作用。以性别、高血压为例,经one-hot独热编码后,由0,1二进制形式表示。性别与高血压向量化见表4。

表4 性别与高血压向量化
(3)归一化。当实验数据作为同一水平的输入变量输入模型中时,存在纲量不一致问题,不仅影响数据之间的可比性,还会导致分析结果存在偏差。采用离差标准化归一化方法,通过线性变化,将所有指标数值进行压缩,计算如式(12)所示。
(12)
式中,X.Min为指标X数据中的最小值;X.Max为指标X数据中的最大值。以APOE数据为例,线性归一化处理如图5所示。由图5可知,横坐标为APOE原数据形式,范围为[2,15.3],由归一化将其映射到[0,1]之间;其中数据仍保持原特征,提升模型训练收敛速度和精度。
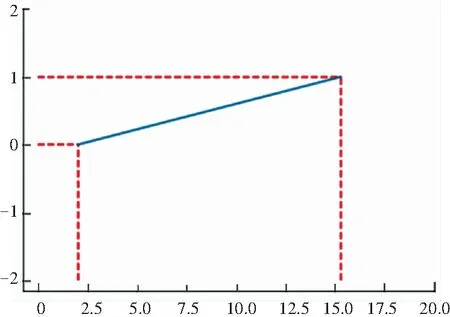
图5 APOE线性归一化处理
4 模型训练与结果分析
4.1 实验数据
实验数据来自上海某医院真实病历数据。数据集中筛选处理797条缺血性脑卒中患者正样本数据。为进行实验对比,选取962条非缺血性脑卒中患者的数据作为实验负样本。模型训练过程中分为训练集和测试集,其中训练集占80%,测试集占20%。
4.2 模型训练
实验中采用交叉熵损失函数计算模型预测值与真实值间误差,并设置Adam优化器反向优化学习,使得损失最小时,模型训练达最优。多特征联合的缺血性脑卒中辅助诊断模型训练实现如算法1所示。
算法1缺血性脑卒中辅助诊断模型训练实现
E: 迭代次数
B: 批大小数据集
Llearning_rate: 学习率
Dtrain、Dtest: 训练集、测试集
N: 神经元个数
n: 特征子模型个数
Vn: 第n个子模型输出的特征向量
V: 特征联合向量
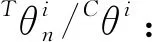
TLn/CLloss: 第n个特征子模型网络误差/分类模型网络误差
ForiinE:
BDtrain←GetMiniBatch(Dtrain,B)
Forjinn:
End For
V←concatenate(Vn)
A←Self-attention(V)
Lloss←ModelClassify(A,Cθi)

12. End for
13. Evaluate(Dtest,Tθ1,Tθ2,......Tθn,Cθ)
14. End
模型在训练中,确定了learning_rate=0.001,dropout=0.5,epoch=100时,性能达最优。
4.3 结果分析
实验中采用准确度(Accuracy)、灵敏度(Sensitivity)、特异度(Specificity)、阳性预测率(PPV)、阴性预测率(NPV)以及F1_Score的作为评估标准。计算如式(13)、(14)、(15)、(16)、(17)和(18)所示。
(13)
(14)
(15)
(16)
(17)
(18)
其中涉及基本概念的混淆矩阵表示,见表5。

表5 混淆矩阵表示
本文实验首先对比了基于LSTM多特征模型(MLSTM)、基于双向LSTM和LSTM组合的多特征模型(MBLSTM-LSTM)以及基于双向LSTM多特征模型(MBLSTM)。不同模型下实验结果对比见表6。由表6可知,MBLSTM模型优于其他两种模型。从网络模型结构上看,LSTM实现对输入特征的单向计算,双向LSTM综合输入前向和后向的信息,提升了模型分类性能。
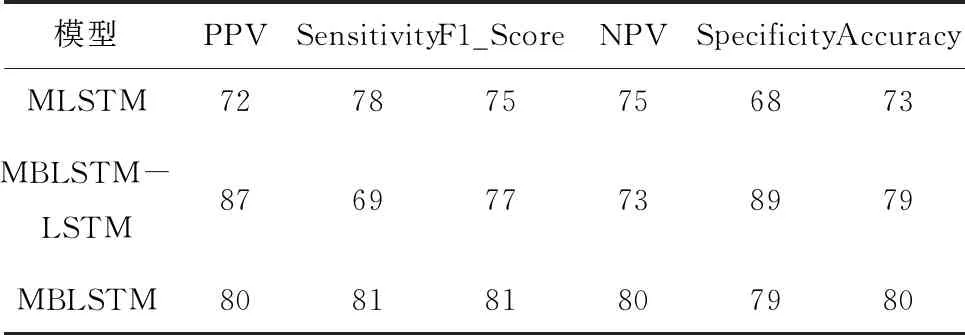
表6 不同模型下实验结果对比
为进一步验证文中提出多特征模型的有效性,实验对比了单个超声LSTM(LSTMc)/双向LSTM(BLSTMc)、生化LSTM(LSTMs)/双向LSTM(BLSTMs)、基本信息LSTM(LSTMj)/双向LSTM(BLSTMj)诊断模型。各单独特征模型与多特征模型结果见表7。
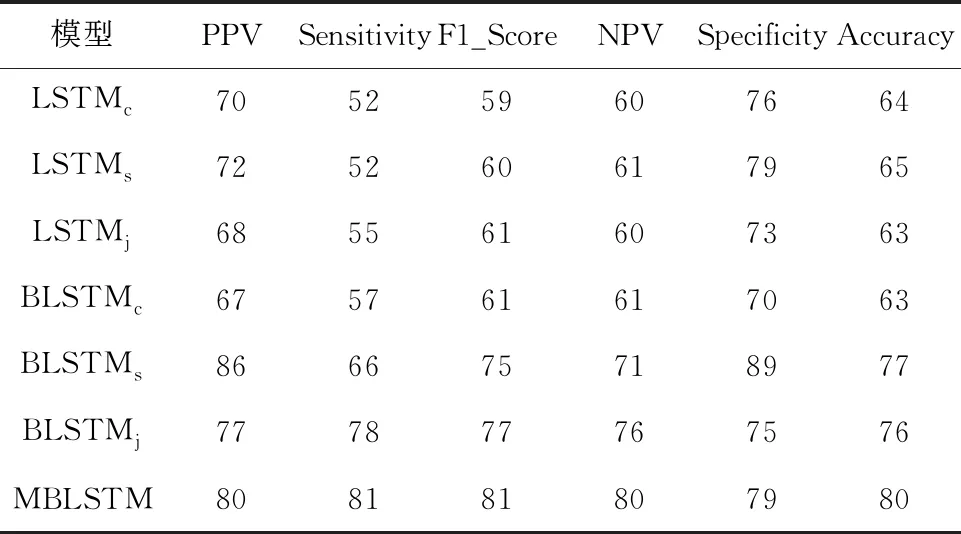
表7 单独特征模型与多特征模型结果对比
由表7可知,较单独特征LSTM诊断模型、双向LSTM诊断模型,多特征诊断模型有效地联合多特征间的信息,提升模型诊断预测结果,模型整体准确度为80%左右,发挥了不同类型特征信息对疾病诊断的作用。
考虑到注意力机制对关键特征加权的影响,在多特征模型基础上增加自注意力机制。各模型对比增加注意力机制模型的准确度结果对比如图6所示。

图6 模型对比增加自注意力机制模型的准确度结果对比
由图6可知,各多特征模型对比有无自注意力机制上,准确度均保持稳定或者有所增加,说明自注意力机制增加了对各特征子模型输出的特征向量权重的计算,并分配了相应的权重值。
5 结束语
本文提出基于LSTM多特征联合诊断模型,利用Word2vec、one-hot及归一化等数据预处理方法,获取高质量输入数据,加速模型训练的收敛速度;联合患者当前多种检查数据,在建立的双向LSTM子模型下提取特征信息;自注意力机制学习特征间的关联并分配权重,增强模型学习性能,提升分类结果。实验结果表明,该模型诊断效果良好,在准确度、灵敏度、特异性、阳性预测率、阴性预测率以及F1_score中性能总体达84%,且自动辅助诊断降低了主观因素影响,在缺血性脑卒中辅助诊断研究中具有一定的价值,为临床医生缺血性脑卒中疾病诊断提供决策参考。
猜你喜欢
汽车实用技术(2022年9期)2022-05-20
中国典型病例大全(2022年7期)2022-04-22
保定学院学报(2022年2期)2022-04-07
综艺报(2022年4期)2022-03-04
中学生理科应试(2021年11期)2021-12-09
科学与财富(2021年35期)2021-05-10
华人时刊(2020年21期)2021-01-14
数学学习与研究(2018年15期)2018-11-12
人大建设(2018年7期)2018-09-19
分析化学(2017年12期)2017-12-25
