
基于CNN-LightGBM模型的高速公路交通量预测
2020-03-16 05:17曾献辉
网络安全与数据管理 2020年2期
张 振,曾献辉,2
(1.东华大学 信息科学与技术学院,上海 201620; 2. 数字化纺织服装技术教育部工程研究中心,上海 201620)
0 引言
准确的交通量预测是当今智慧交通的重要基础,是交通状况判别的重要基石之一[1]。人们从上个世纪开始就在交通流预测领域做了很多交通预测研究,截止目前为止常见的交通量预测方法主要包括基于统计的预测方法、基于时间序列的交通量预测方法、基于神经网络的交通量预测方法以及基于机器学习的交通量预测方法几种。
基于统计的交通量预测方法较多,比如多元线性回归法、卡尔曼滤波器[2-3]和K近邻算法[4]等,这些方法主要根据历史流量数据预测未来交通流量分布,但是这些方法无法精准地预测道路短期拥堵的情况。基于时间序列的交通量预测方法如差分自回归滑动平均模型[5],主要是将历史的流量数据按照时间排列成为时间序列,根据时间序列分析数据流的变化趋势从而预测未来的交通流量,但是这种算法的缺点是在处理数据量较大、维度较高的数据时效果一般,推广能力较差。基于神经网络交通量预测方法如GRU[6]和LSTM[7-8],这些模型存在着计算过程中收敛速度慢、计算时间较长、容易过拟合等缺点。基于机器学习的交通量预测方法如GBDT模型[9]、Xgboost模型[10]和随机森林模型[11],这些模型对交通流时空挖掘效果不大理想。
单一预测模型往往存在一定的缺陷,影响模型预测精度。由于高速公路交通流量变化很容易受到外界环境的影响,在空间上上下游监测点和开放路段的出入口交通流量变化对该路段交通量变化有一定的影响。深度挖掘交通流量的时间和空间特性不仅可以降低外界环境对交通流变化的影响,还可以考虑到相邻监测点和出入口之间的因果关系,提高模型的预测精度。CNN模型主要优势是可以进行特征提取[12],深度挖掘高速公路待预测监测点和周边检测点之间的时空上的联系。LightGBM算法使用集成学习的方式[13],可以快速实现梯度提升,具有较快的运行速度和较高的预测精度。本文结合这两种模型的优点提出了CNN-LightGBM组合模型的方式进行交通量预测。
1 基于CNN-LightGBM交通量预测模型
1.1 基于CNN的特征矩阵构建
卷积神经网络(Convolutional Neural Network,CNN )模型最早可追溯至1980年由FUKUSHIMA K等人提出的Neocognitron模型[14],于1998年正式由LE CUN Y等人提出[15]。CNN主要由输入层(input)、卷积层(conv)、池化层(pool)、全连接层(fc)和输出层(output)构成[16],这种模型结构可以有效地减少权值的数量,简化网络模型,同时也可以将数据直接用作网络输入,有效地减少了特征的提取和数据重构的复杂性,该模型如图1所示。目前CNN模型大多应用于图像领域,在交通量预测方面,由于CNN模型具有比较差的泛化能力,如果在实际交通量发生突变的情况下,之前建立的模型可能会出现完全失效情况[17]。但是CNN模型具有很强的特征提取能力,大多应用于模型特征提取。

图1 CNN模型整体结构
高速公路的交通流量数据可以从时间和空间两个角度做出区分,在时间上,当前时刻交通流量数据是对上一时刻的数据的继承与对下一时刻数据的延伸;在空间上,对于开放的高速公路路段来说,当前监测点的交通量变化不仅仅与上下游的交通量有关,还会受到高速公路出入口交通量变化的影响。根据CNN捕捉的时空信息的特点,构造包含时间和空间信息的二维矩阵。
空间上监测点在t时刻的交通流量数据为:
S={xp,t,xp1,t,…,xpn,t}
(1)
其中,xp,t表示目标监测点p在t时刻的交通流量数据;xpn,t表示周边检测点pn在t时刻交通流量数据。
构建时空特征矩阵为:
(2)
其中,xp,t-m表示监测点p在当前时间前m个时间统计单位的时刻交通流量数据。本实验中m取值为5。
1.2 基于CNN-LightGBM模型的交通量预测
LightGBM模型于2016年由微软亚洲研究院提出[18],是GBDT模型的变体,主要用于解决GBDT在处理大量数据时遇到的问题。由于LightGBM是GBDT算法的提升,其基本原理与GBDT原理基本一致。GBDT算法属于一种Bossting Tree算法,Boosting算法可以表示为决策树的加法模型:
(3)
其中,T(x,Θn)表示第n棵决策树,Θn表示其参数;N为树的棵数;x表示输入样本。
GBDT采用前后向分布算法的方式进行优化求解,其模型为:
fn(x)=fn-1(x)+T(x:Θn)
(4)
其中,fn-1(x)为经过n-1步训练的提升树模型,T(x:Θn)为第n步需要学习的决策树。前向分布算法希望将T(x:Θn)和fn-1(x)相加后能够使fn(x)在训练集上的经验误差最小。Bosting Tree算法在每个步骤都会生成一个弱决策树模型,并将其累积在整个模型中,从而将模型的经验误差降至最低。GBDT模型就是沿着当前模型误差函数的负梯度方向生成每个弱决策树模型。
LightGBM是在GBDT模型的基础上结合了Gradient-based One-Side Sampling(GOSS)算法和Exclusive Feature Bundling(EFB)算法以增强梯度。GOSS算法主要用于对训练样本进行采样,能够在保留大梯度样本的同时减少小梯度样本的数量,从而降低决策树生成的复杂性,同时GOSS算法能够提高泛化性能。EFB算法用于减少较高特征维度下稀疏数据要素的数量,并从要素角度优化算法复杂度。
结合CNN挖掘交通流空间特性与LightGBM快速高效预测的特性,本文构造出CNN-LightGBM交通量预测模型的整体结构,如图2所示。
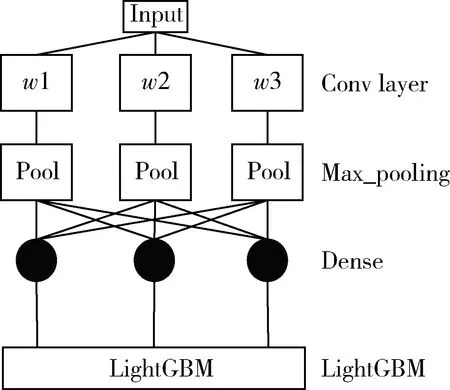
图2 CNN-LightGB的预测模型结构
整体思路可以分为以下4步:
(1)统计各个监测点的交通流量数据,并对交通流量数据进行预处理;
(2)将交通流量归一化后放入CNN模型进行训练,由CNN模型提取交通流时空特征;
(3)将CNN模型提取的特征向量输入到LightGBM模型;
(4)使用LightGBM模型对交通量进行预测。
2 高速公路交通量预测应用研究
2.1 数据来源
本文实验数据来源自某省交通管理局提供的某高速公路路段道路中心监测点、收费站口监测点以及服务区监测点对机动车监测的真实数据,监测点位置分布如图3所示。监控点记录每一辆通行车辆的车牌号、通行监测点的时间、机动车通行方向与汽车类型等。本实验采用2018年11月1日到2018年12月20日共计300多万条监测数据,首先根据监测点记录的机动车类型,根据国家机动车当量折算标准,将不同机动车交通量按照不同的折算系数转换成标准车型的当量交通量,当量交通量比单纯地统计汽车个数更加具有实际意义。由于短时交通流的时间跨度并没有非常标准的定义,本实验以15 min作为最小时间单位,统计道路每15 min汽车当量交通量,得到4 800条数据。其中,以2018年11月1日到2018年12月15日时间段的交通当量数据作为训练样本,以2018年12月16日到2018年12月20日时间段的交通当量作为测试样本,共计得到4 320个训练样本,480个测试样本。
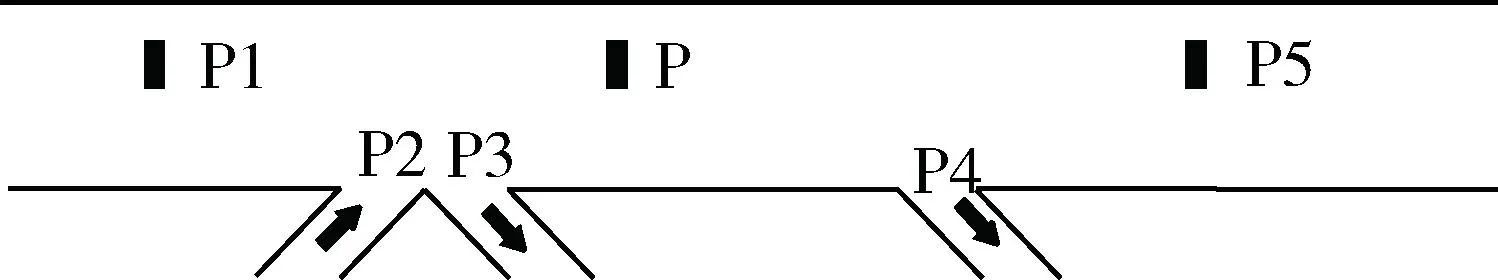
图3 监测点位置图
2.2 数据预处理
由于高速公路监测点对数据进行实时监测传输时可能会由于监测器异常、网络异常或者存储异常等因素导致数据存在重复、缺失或错误等问题,严重影响数据的真实性,因此需要对这些数据进行合理有效的处理。
首先对监测点数据进行处理。监测点数据主要存在数据重复和数据缺失问题。对于数据重复问题,根据重复数据记录的时间排序,保留第一次出现的车辆数据,其他的重复数据进行删除处理。数据异常指的是数据库记录的数据有部分缺失,如果需要的关键数据没有缺失则不做处理,如果有缺失则做删除处理。
对处理后的监测点数据进行统计,根据我国《公路工程技术标准》[19]的规定,对各种类型的车型进行机动车当量折算,将不同的机动车车型转换为标准的机动车车型。当量能够体现出机动车在道路上的占有情况。然后根据监测点记录的机动车通行时间以15 min为最小时间单位,对机动车数量进行统计。
由于监测点数据缺失和数据异常问题会对统计数据造成影响,需要对统计出来的数据再次进行处理。考虑到高速公路机动车数据具有周期性、连续性和重复性的特点,采用历史值填充和平均值法进行数据填充。对于少量数据缺失问题,采用平均值填充的方式对数据进行补充。如果有大量数据缺失,则根据道路数据周期性特点,采集之前一些天数相同的时间数据进行加权平均,将缺失数据进行填充。
2.3 CNN-LightGBM模型设计
从图3可以发现,待预测监测点P的交通流量与上游监测点P1、出入口P2和P3、下游出口P4和监测点P5都有较大的关联性,上下游的交通量变化会影响到P监测点的交通量变化。在模型建立前,首先对数据进行归一化处理,让数据映射到一定的范围之内,这样可以减少数据范围对预测效果的影响。CNN-LightGBM组合模型训练过程主要分为CNN特征提取和LightGBM预测两个部分。
(1)使用CNN提取特征。CNN特征提取使用两次卷积和两次池化。第一次CNN模型利用3×3的卷积方式将数据转换成[2,6,6]的特征图,池化之后得到[2,3,3]的特征图。第二次CNN使用3×3的卷积将数据转换成[4,3,3]的特征图,池化之后得到[4,2,2]的特征图。之后使用Reshape对数据重组,将二维矩阵转换成一维向量。使用全连接方式将数据变成128维度数据。实验中CNN使用MSE作为损失函数,卷积核大小为3×3,步长为1,padding为1,第一次卷积核的个数由1变成2,第二次卷积核由2变成4。池化的窗口大小为3×3,步长为2,padding为1。
(2)将高维特征向量输入到LightGBM模型进行预测。将CNN模型得到的特征向量作为输入传送给LightGBM模型,由LightGBM进行交通量预测。LightGBM模型学习率为0.1,最大深度为8,num_leaves为50,其他均使用默认值。
CNN-LightGBM模型设计流程如图4所示。

图4 CNN-LightGBM模型设计
2.4 模型评价标准
为了验证模型的有效性,实验采用了均方根误差(Root Mean Squart Error,RMSE)、平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)和平均绝对差值(Mean Absolute Error,MAE)作为评价标准[20],用于判断预测交通当量数据的准确性。
(5)
(6)
(7)

2.5 研究结果
为了验证高速公路空间特性对交通量的影响,本实验将考虑空间特性的LightGBM-1模型与未考虑空间特性的LightGBM-2模型作对比,如图5所示。通过表1对比发现考虑到空间特性的LightGBM-1模型比未考虑到空间特性的LightGBM-2模型的MAPE降低了12.75%,RMSE降低了16.20%,MAE降低了16.91%。说明考虑空间特性的LightGBM-1模型预测效果更好,这表明,挖掘交通流的空间特性可以降低预测误差。

图5 LightGBM-1与LightGBM-2模型预测结果
将CNN提取的特征向量全连接后得到CNN预测模型,将CNN的预测结果与真实值进行对比,如图6所示。结合CNN模型与LightGBM模型优势的CNN-LightGBM模型的预测结果如图7所示。由表1可知,考虑到时空特性的CNN-LightGBM与未考虑交通流空间特性的LightGBM-2相比,MAPE降低了28.28%,RMSE降低了30.87%,MAE降低了33.56%。CNN-LightGBM模型与考虑交通流空间特性的LightGBM-1模型相比,MAPE降低了17.80%,RMSE降低了17.51%,MAE降低了20.04%。CNN-LightGBM模型与单独CNN模型相比,MAPE降低了23.69%,RMSE降低了15.69%,MAE降低了21.53%。这表明基于深度学习的CNN-LightGBM模型可以更加深入地挖掘交通流的时空特性,相比于组合中的单一模型,可以明显降低预测误差。

图6 CNN模型预测结果
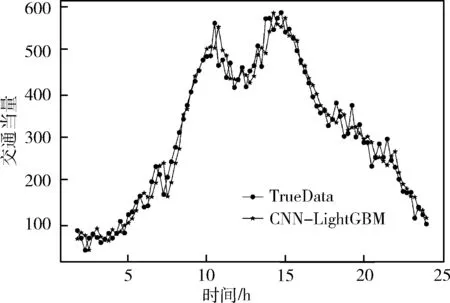
图7 CNN-LightGBM模型预测结果
同时,为了体现该模型与其他组合模型的优越性,本实验同时还利用了同类CNN-Xgboost模型与CNN-LightGBM模型作对比,如图8所示。由表1可以看出,同样挖掘交通量的时空特性,在本实验中,CNN-LightGBM相比于CNN-Xgboost,MAPE降低了2.89%,RMSE降低了2.26%,MAE降低了1.63%。同时在本实验中,以CNN提取的特征向量作为输入的Xgboost模型运行时间为18.6 s,LightGBM模型运行时间为3.9 s,LightGBM模型运行速度远高于Xgboost模型。在本实验中CNN-LightGBM的预测效果优于CNN-Xgboost模型。

图8 CNN-LightGBM模型与CNN-Xgboost模型预测结果
为了更一步验证模型的有效性,本实验还与传统的Xgboost模型、KNN模型、神经网络模型和SVR模型作对比,如图9所示。结合表1的预测误差,综合以上所有模型对比结果发现,考虑时空特性影响的CNN-LightGBM模型在本实验中可以明显降低预测误差。

图9 其他模型预测结果
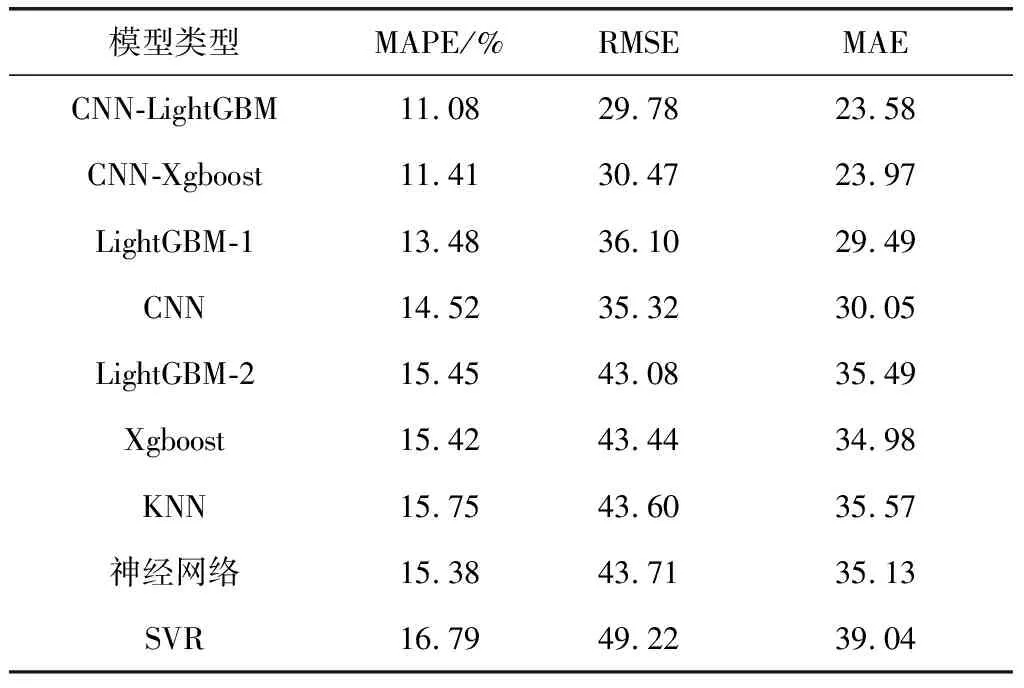
表1 实验结果对比
3 结束语
在高速公路系统中,相比于传统的车辆数量预测,交通当量的准确预测对交通控制具有重要的意义,可以反映出道路的实际占有情况,有助于居民出行和物流流通,对交通监管部门道路规划和交通判别具有很大参考价值。本文选取某高速公路某路段监测点数据,采用CNN-LightGBM算法对交通当量进行预测,结合上下游交通量与附近高速公路出入口交通量变化,使用卷积神经网络对交通当量提取空间维度数据特征,利用具有快速、低内存、高准确率特点的LightGBM模型对卷积神经网络提取的高维特征向量进行处理预测,可以获得较高的预测效果,相比于单独的机器学习模型和其他组合学习模型具有更低的预测误差。该模型具有很强的实用性与可靠性。但是由于采用的是高速公路某路段进行预测,并没有考虑到高速公路各级关联道路路网的复杂性,下一步将结合路网情况进行预测分析,使得模型更加具有通用性。
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
中国交通信息化(2022年5期)2022-07-23
中国交通信息化(2022年4期)2022-06-17
中国交通信息化(2022年2期)2022-04-26
运输经理世界(2021年20期)2021-05-19
北方交通(2021年3期)2021-03-31
建材发展导向(2019年11期)2019-08-24
计算机系统应用(2019年6期)2019-07-23
科技资讯(2017年19期)2017-08-08
北方交通(2016年12期)2017-01-15
