
改进的基于嵌入式SoC卷积神经网络识别模型
2020-03-13 10:56肖金球顾敏明
计算机应用与软件 2020年3期
孙 磊 肖金球 夏 禹 顾敏明
(苏州科技大学电子与信息工程学院 江苏 苏州 215009) (苏州科技大学苏州市智能测控工程技术研究中心 江苏 苏州 215009)
0 引 言
利用FPGA并行计算的特点可以加速网络的运算,但是需要消耗较多的逻辑资源。RTL的设计方法即使在资源配置和计算性能上有一定的优势,但开发周期长、难度大、门槛高。Venieris等[1]设计了一种将卷积神经网络映射到FPGA平台的自动化设计方法,大大减少了设计难度。卢冶等[2]提出一种面向边缘计算的嵌入式FPGA平台的构建方法,与多种平台比较显现出优势和可行性。仇越等[3]提出了基于Zynq加速器的实现方法,并利用高层次综合技术和嵌入式SoC对卷积神经网络进行优化设计。Stornaiuolo等[4]提出快速部署Overlay的设计方法,以Xilinx公司的Vivado套件和PYNQ(Python Productivity for Zynq)为实验平台进行高层次综合设计,进一步加快了深度学习网络在嵌入式SoC上的部署速度。
本文以PYNQ为硬件实现平台,将卷积神经网络进行离线训练得到权重、偏置参数的模型文件,并设计定点数量化的算法;在嵌入式系统下调用FPGA资源,设计卷积神经网络和加速计算,对已有的加速器进行改进和优化,将实验数据与ZynqNet[3]实验方法比较得出了更佳的效果,与单CPU处理器计算卷积神经网络比较具有更快的计算速度。
1 卷积神经网络和嵌入式SoC
1.1 卷积神经网络模型
通常卷积神经网络包括卷积层、池化层、激活函数(非线性ReLU)和全连接层。它们依次作用于特征图,每一层从前一层读取、执行和输出。图1所示为经典LeNet-5手写识别模型。
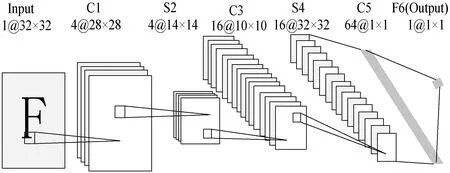
图1 LeNet-5手写识别模型
卷积层通过输入特征图和权重组成的卷积核进行二维卷积操作如式(1),输出通常直接连接到非线性单元,进行非线性激活。式(2)指池化层采用最大值采样或者均值采样,可以显著降低网络的计算复杂度。式(3)是全连接层在输入特征图和权重之间执行点积。全连接层被放置在网络的末端,并减小输出值。ReLU是执行线性激活,阈值为0。ReLU在卷积神经网络中应用广泛,可以显著加快随机梯度下降的收敛速度,减少训练时间,如式(4)所示。
(1)
(2)
(3)
foutput=MAX(fin,0)
(4)
根据链式法则和反向传播原理,以损失函数的方式对输入、输出和准确值进行对比评估,从而对权重、偏差等参数进行调整。本文采用先经标定好的数据集进行训练,卷积神经网络模型的权重和偏置参数是离线预训练得到的。因此前向传播过程是本文设计实现目的。
1.2 嵌入式SoC的设计方法
基于FPGA的传统RTL设计方法,有难度大、周期长等缺点。藉此提出的高层次综合技术是以C、C++等语言编写高级接口程序,并将其转换成HDL代码进行FPGA部署的一种设计方法。在此技术上,为了提高效率和简化难度,利用嵌入式系统的优势引入具有高度可读性的Python解释器语言,并且利用Web服务器基于浏览器的工具包进行访问,其中就包含了结合开源框架Jupyter-notebook在ARM处理器上运行交互式Python内核实现SoC编程操作的设计方法。
本文根据卷积神经网络层与层之间的数据依赖关系,对前向传播的卷积神经网络以同步数据流方式进行设计;对32位浮点数进行量化压缩,在精确率可接受的情况下实现16位定点数转换;最后利用Overlay的设计方法部署FPGA部分,协调使用嵌入式SoC的逻辑资源。
2 模型设计
2.1 系统设计
本文设计的整体架构为ARM处理器部分和FPGA逻辑资源部分。带有Python解释器以及Jupyter-notebook工具包的Linux系统,可以调用高级接口来控制特征图加载到DDR内存上,经过卷积神经网络模型计算后的数据交换由AXI_DMA模块负责,并将输出结果显示在电脑上。
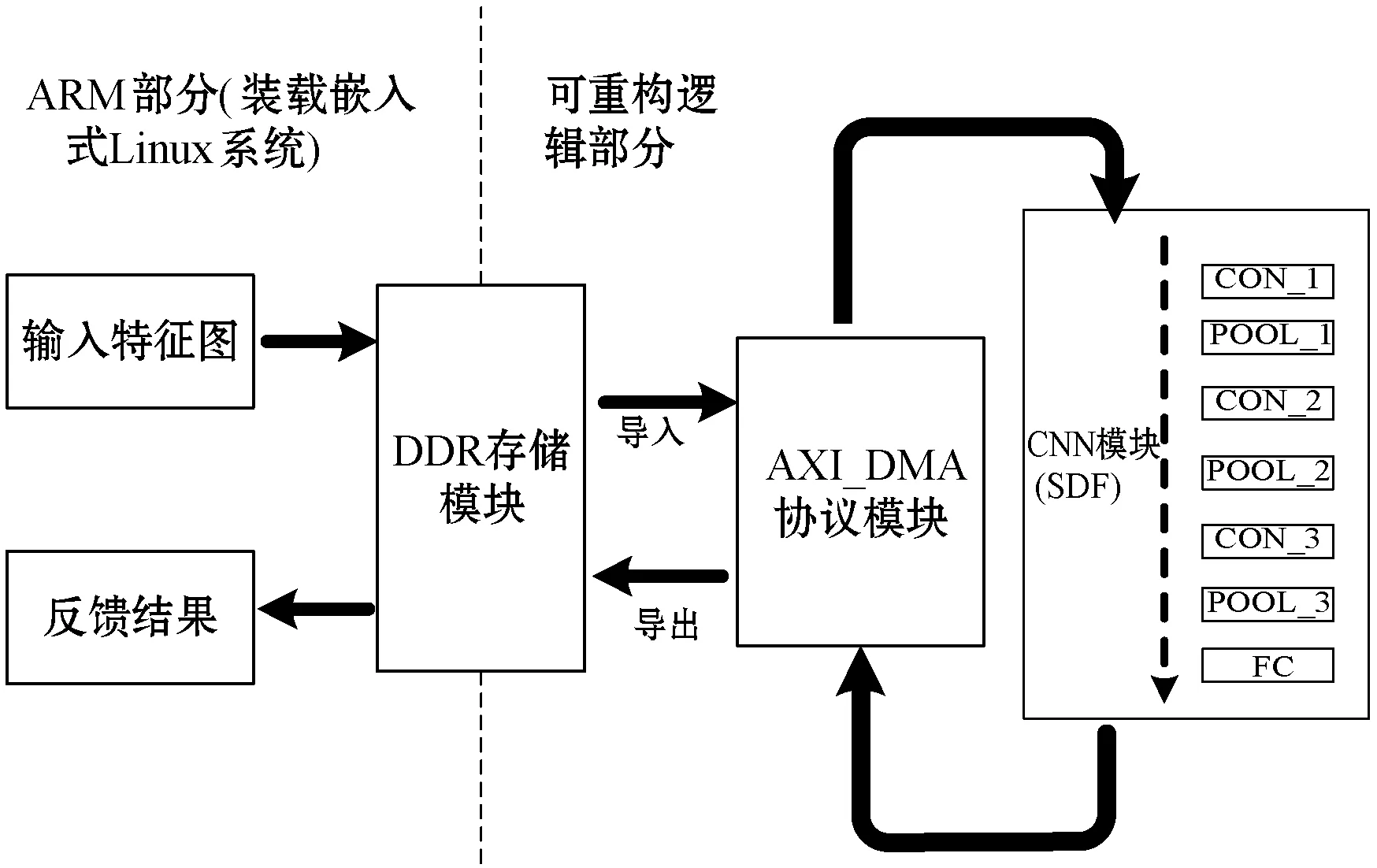
图2 系统整体结构框图
2.2 定点数量化
Han等[5]提出的深度压缩即通过裁剪训练量化和霍夫曼编码实现方法,实现难度大,不适合小规模计算样本。蔡瑞初等[6]设计了动态定点量化小数位数和精确率之间的平衡的方法,即反向传播时对网络进行微调,计算量有一定减少,但对于识别网络的计算模型研究缺乏。以上量化方法对于嵌入式SoC下的卷积神经网络的计算没有较好的解决方法。本文分析了文献[7]在嵌入式SoC平台下实现一个卷积层时消耗资源情况,如表1所示,可以看出这样的设计在目前的硬件平台上不可能实现整个卷积神经网络。

表1 浮点数卷积层消耗资源展示
本文继续研究发现,通常用位宽、步长和动态范围3个参数来表示浮点转定点的依赖关系:
Range≈Stepsize·2Bitwidth
(5)
于是提出当给出定点的位宽后,在大的动态范围下和小的分辨率之间权衡量化误差关系是解决问题的关键的想法。文献[8-9]给出了各种输入分布的最优对称均匀量化器的步长表,分析表中内容可知随着输入分布的峰值增加量化效率降低,和高斯分布具有相似性。所以在对预训练的浮点数据分析后,确定每层的权重、偏置和激活函数,本文提出一种浮点数量化为定点数的方法:
s=ξ·Stepsize(β)
(6)
n=-og2s
(7)
式中:Stepsize(β)对应量化位宽的最佳步长,ξ是量化有效标准差(因为在理想零均值高斯分布下量化值的标准偏差为σ,并且ξ≥σ,本文采用ξ=3σ的准确率数值),s是计算所得的步长,n表示小数位数。式(7)以2为底计算对数,应用舍入函数取舍,计算小数位数,对最终结果进行移位操作将32位转换成16位。
在实验中得出与32位浮点算法相比,FPGA上的定点算法需要较少的DSP和LUT,并且简单的定点算法操作可以在一个时钟周期内执行完成。
2.3 卷积层设计和数据流优化
将复杂的卷积运算转换成乘加法运算,可以在FPGA中有效执行。为了减少缓冲区的使用和提高计算的吞吐量,本文提出一种交错计算的方法,如图3所示。
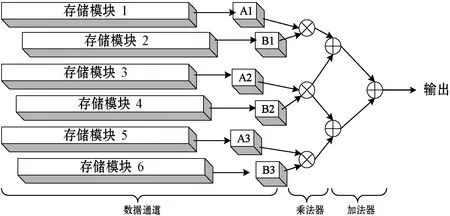
图3 FPGA实现矩阵乘法原理图
在3×3的划窗操作后,本文设计将特征图提取在存储单元奇数模块,权重值提取到存储单元偶数模块。在每个时钟周期的激励下,将运算数串行输出到寄存器Ai和Bi中。普通单个矩阵乘法器负责9个卷积数和9个权重数的乘加树计算,因此计算会消耗较多的DSP资源。本文提出不改变滑窗计算过程并且减少DSP使用个数的乘加树计算方法。图3可理解为单个计算单元设计了6个DSP组成的3层乘加树。第1层是3个乘法器将权值和卷积数进行乘法计算。第2层则是级联第一层的计算结果,并且共享中间的计算值进行累加计算。第3层单一的加法器负责将上一层输出的两个值求和。最终结果由ReLU函数激活送至特征图缓冲区。如此在有限的类似设计单元中完成卷积计算。而且在FPGA中每个阶段都是由寄存器组成,不需要等待当前计算完成后将内存的数据提取到通道A或B,所以在每个时钟周期同时进行输入和输出操作大大加速了运算过程。
考虑到把所有数值都提取到BRAM上进行计算是不实际的,但将数据从外部存储提取再计算会影响计算速度,所以本文提出在设计当中将输入的特征图值存储在基于LUT的存储模块中,权重值存储在BRAM的存储单元里,如此可以加速计算和节省资源。伪代码如下:
staticap_int
#pragmaHLS RESOURCE variable=A
core=RAM_S2P_LUTRAM
#pragmaHLS RESOURCE variable=B core=RAM_S2P_BRAM
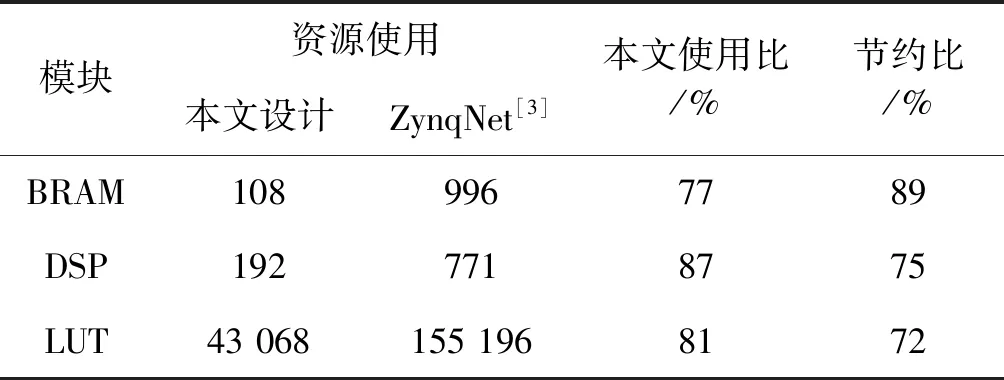
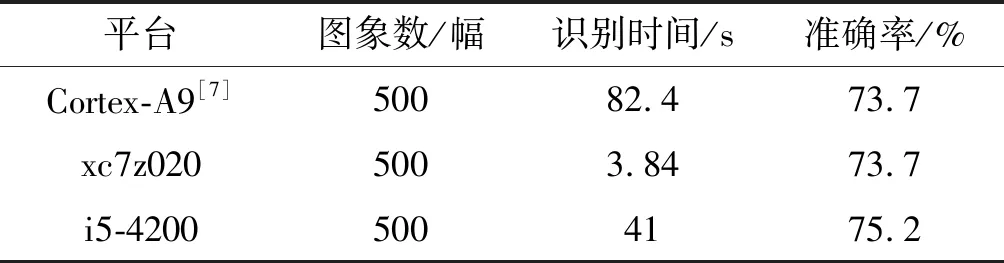
for(int ia=0;ia for(int ib=0;ib for(int ic=0;ic for(int id=0;id sum += A[ia][id*B_ROW_MAX/FACTOR+ic]* B[ib][id*B_ROW_MAX/FACTOR+ic]. 通常卷积神经网络表示为一系列的层,这些层构成一个有向无环图模型,这些层的连接是通过高级描述方案完成。所以本文研究了将有向无环图模型映射到硬件的模型即同步数据流模型。类似于搭积木将每个层例化成模块后相互连接。实验表明计算过程实现了不间断流水操作,并且输入即输出的节点运算方法一定程度上提高了系统的鲁棒性,因为每个层的设计都是独立地驱动数据流,从而形成异构流模式,这种输入输出模式,输出数据立即流出,而不是缓冲在片上存储器上,节省整个网络的内存占用。 实验采用Xilinx PYNQ-Z2嵌入式SoC实验平台,该平台搭载的是xc7z020clg400SoC FPGA芯片,片上有双核Cortex-A9处理器。FPGA部分主要有BRAM、DSP以及LUT可编程阵列[10]。实验中的硬件编程环境为Vivado 2017.4,高层次综合系统Vivado高层次综合技术2017.4;卷积神经网络的训练和执行采用Theano框架。实验的测试数据集是CIFAR-10中的500幅图片,每幅图片大小为32×32×3。对比实验中,采用Intel i5-4200U低功耗的CPU。在Windows 10操作系统下,以Google Chrome浏览器执行与嵌入式系统的可视化交互编程。 在主频为100 MHz的工作频率下,该方法优化了对片上资源的使用,设计实现了16位定点量化,虽然有一些分类精度的损失,但是比Zynqnet的设计节约了88%BRAM、75%的DSP和73%LUT。本文设计对比ZynqNet中对资源使用如表2所示。 表2 资源消耗以及对比分析 在3个计算平台下,对500幅32×32×3大小的图片进行识别,计算速度如表3所示。可以看出,相同工作频率下ARM处理器的识别速度提高了42倍,本文方法的准确率可达73.7%,对比使用CPU计算浮点数的准确率75.2%,这是可以接受的。 表3 不同平台的实验数据对比 本文提出一种改进的基于嵌入式SoC卷积神经网络CIFAR-10的识别模型。该模型使用的资源少,功耗低。为了提高FPGA加速方案的准确率和性能,未来将优化FPGA的部署和训练更精确的网络模型,以及研究卷积神经网络针对层的优化设计。3 实验与结果分析
3.1 实验环境
3.2 实验结果
4 结 语
猜你喜欢
汽车实用技术(2022年13期)2022-07-19中学生数理化(高中版.高考数学)(2022年4期)2022-05-25心理学报(2022年5期)2022-05-16今日农业(2021年21期)2021-11-26家庭影院技术(2021年7期)2021-08-14教育周报·教育论坛(2021年21期)2021-04-14当代陕西(2020年17期)2020-10-28电子制作(2019年15期)2019-08-27电子制作(2019年7期)2019-04-25人大建设(2018年5期)2018-08-16
