
适用于嵌入式平台的E-YOLO人脸检测网络研究
2020-03-11 13:15阮有兵徐海黎
计算机应用与软件 2020年2期
阮有兵 徐海黎 万 旭 邢 强 沈 标
1(南通大学机械工程学院 江苏 南通 226019)2(南京蓝泰交通设施有限责任公司 江苏 南京 210019)
0 引 言
人脸检测技术是计算机视觉中图像处理的一个重要分支,无论是在日常生活中常见的监控相机,还是高铁机场安检时的人证比对,通常都需要对相机采集的视频流中人物进行辨别,这就需要对人脸进行检测。人脸检测需要检验出图像中是否含有人脸,并获得信息,诸如人脸在图像中的位置、倾斜角度以及姿态等。传统的人脸检测方法包括基于知识规则方法、统计模型方法以及模板匹配的方法,如支持向量机(SVM)和Adaboost框架等。传统检测方法,比如结合Haar-like特征的Adaboost分类算法[1-2],在速度上具有一定的优势,可以达到实时检测,但是在实际使用中,光照变化以及人脸姿势表情变化因素下鲁棒性较差。近年来,随着深度学习技术的日益完善,深度学习逐渐被运用在众多领域,并获得巨大的应用价值。基于深度学习的检测方法已经成为目前人脸检测的趋势。如Li等提出的Cascade CNN算法、Redmon等在2015年提出的YOLO(You Only Look Once)算法以及R-CNN、SPP-net、Fast R-CNN、Faster-R-CNN等经典的目标检测算法[3-6]。
Cascade CNN算法是对Violajones算法的深度卷积网络实现,人脸检测速度较快,但是在第一级窗口过滤时采用基于密集滑动窗口的方式,对识别高分辨率中存在大量小人脸的图像有一定的限制。YOLO算法的思想是将目标检测作为回归问题,将整幅图作为网络输入,在输出层回归出边界框的位置及属性[7-8],算法识别速度快,但是在识别小人脸时存在缺陷,精确度较低。R-CNN主要步骤有三步,首先是对输入的图像进行扫描获得2 000个预选区域,然后将这些区域通过卷积神经网络提取特征,最终将特征输入支持向量机和线性回归器进行分类计算和目标定位计算。Fast R-CNN是R-CNN的升级版本,只需要训练一个神经网络,相比而言,计算速度更好。这些深度网络模型运行在配置有GPU的PC客户端上时,这类平台的计算和处理能力较强,可以处理相应的人脸检测算法,基本可以达到对人脸的实时检测,但对于基于嵌入式系统的移动设备,将人脸检测应用于移动端时,由于嵌入式平台的处理能力和资源的限制,GPU处理器性能的差异,即使采用实时效果较好的Fast R-CNN,效果也不是很理想,只能达到1 FPS以下的帧率,不能够达到实时检测的效果[9-10]。
在移动端的目标检测上,为了提高检测的速度,研究者们提出了一些小型化的网络模型,如SSD和YOLO,为了解决在嵌入式平台上目标检测性能下降的问题,Redmon提出了tiny-yolo网络模型,通过减少YOLO模型上卷积层的数量来减少模型大小,同时减少了算法中浮点运算的次数,以达到在嵌入式平台上实时检测,但这样检测精度也大幅下降[11]。
为了兼顾人脸检测的快速性和准确性,同时减小模型体积,本文基于YOLO算法提出一种轻量化的人脸检测网络模型结构E-YOLO(Enhance-YOLO),摒弃YOLO算法中的全连接层,采用K-means聚类获取基准区域,采用基准区域来预测边框,提升检测的精度。通过降低卷积神经网络中的网络层数和卷积核数目,以达到降低模型大小的目的,使网络模型轻量化。
1 YOLO算法基本原理
图1为YOLO算法模型。
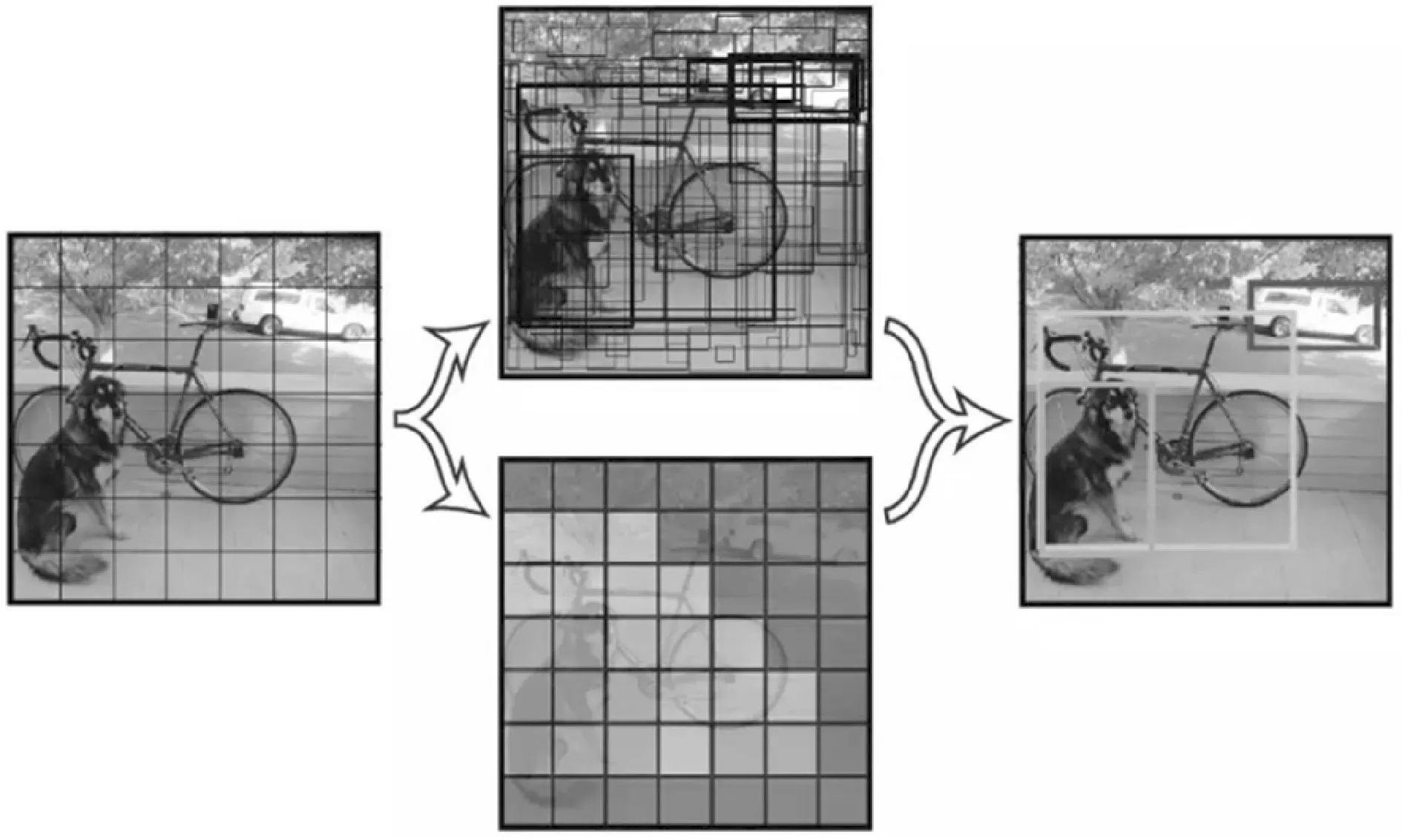
图1 YOLO算法模型
2 改进YOLO网络结构
2.1 精准化
文献[13]提出Fast Yolo模型,为了降低模型大小以及处理功耗以用于嵌入式平台的检测,指出:并非所有捕获的视频帧中都包含唯一信息,因此不需要对所有视频帧进行深度推断。模型中通过运动概率图判断是否需要进行深度推断,这种方式可以降低功耗,但会导致模型的精准度不高,同时影响识别的帧率。
YOLO检测网络模型中包括24个卷积层和2个全连接层,通过卷积层得到卷积特征后,经过最后的2个全连接层得到7×7×30的特征向量,其中输出的特征向量中每个1×1×30的特征向量都与原始图像中每个单元格存在映射关系,然后利用生成的1×1×30的特征向量来预测目标的位置和相关属性。但是通过这种方式,在经过全连接层时会丢失很多图像的空间信息,造成定位精度下降。
本文提出的网络模型借鉴Faster R-CNN算法,Fast R-CNN算法中使用基于基准区域和分类的检测方式,有较好的目标检测效果。E-YOLO网络模型采用基准区域来预测边界框,具体做法为去掉卷积网络中最后的两个全连接层,在最后一层卷积层上进行基准区域预测,以减少图像中目标信息的丢失,同时将输入图片的尺寸缩小为416×416,在每个单元格上利用五个基准区域预测,最终在每个单元格上预测出五个候选框,然后利用候选框直接预测目标的坐标和宽度、高度以及置信度。在Fast R-CNN算法中,获得基准区域的方式是采用人工设定的方式,手动随机选择基准区域的个数和大小,以这种方式获得最终的区域需要重复筛选,耗时较长。本文提出的网络模型采用K-means聚类以解决获取基准区域的问题,采用统计学的思想,对数据集中人工手动的标定框信息进行统计分析、聚类,然后依据分析的结果得到基准区域个数和宽高等参数信息。
2.2 小型化
为了能够在嵌入式平台上对人脸进行实时检测,需要对现有模型进行精简,由于使用场景是人脸检测,只需要将图片中的人脸和背景进行分类,不需要如此深的网络结构。E-YOLO在YOLO的基础上减少了卷积核的数目,在YOLO网络模型中,卷积核的数目和网络层数呈正相关关系,随着算法中网络层数的增加,卷积核也呈现递增的趋势,通过减少每层的卷积核数量,使网络模型变得轻便。具体做法为将网络中卷积层的卷积核数目减少一半,但池化层中卷积核数量以及卷积层最后一层的数量保持不变。同时为了进一步降低在嵌入式平台的大小问题,对输入的图片进行处理,在训练过程中采用多尺度训练,将不同的图片裁剪为统一的大小,通过1×1的卷积对图像进行降维处理,将处理后的特征用于人脸检测,进而加快在嵌入式平台上的处理速度。改进后的网络模型如图2所示。
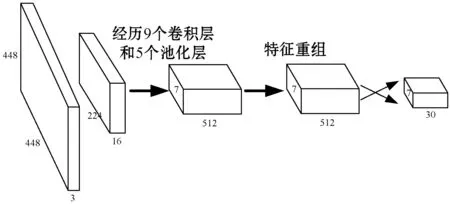
图2 E-YOLO网络模型示意图
3 实验与分析
3.1 实验数据集及训练平台
为了测试本文提出的E-YOLO网络模型性能,采用FDDB以及WIDER FACE人脸数据集进行测试,模型训练是在NVIDIA GTX1080显卡的工作站上进行。FDDB(Face Detection Data Set and Benchmark)是一款针对人脸检测算法的评判标准,在人脸检测领域具有较大的权威性,该数据集共提供了包含5 171个人脸的2 845幅图片,人脸的状态特征多样化,包含遮挡、低分辨率、不同姿态等情况,颜色包含彩色图像以及灰度图。WIDER FACE是由香港中文大学提供的人脸检测数据集,它比其他数据集更广泛,该数据集共有32 000幅图像,包含39 000个人脸数据,数据集中有非常多的小尺度人脸图像,并且背景复杂,对于人脸检测的评估更具有权威性[15-16]。图3是FDDB和WIDER FACE数据集中的示例图片。

图3 FDDB和WIDER FACE数据集的示例图片
3.2 评价标准
实验中用准确率(Precision)、召回率(Recall)以及速度三个参数作为检测结果的评价指标。
准确率(Precision)为数据集中实际检测出的正样本数与数据集中检测出所有的正样本的数的比值:
召回率(Recall)为数据集中实际检测出的正样本数与数据集中预测的样本数的比值:
式中:TP为数据集中实际为正例,同时被分类器标记为正例的样本数;FP为数据集中实际为负例,同时被分类器标记为正例的样本数;FN为数据集中实际为正例,同时被分类器标记为负例的样本数。
检测速度(Speed)的定义为每秒钟处理的图片数量,单位为FPS。
3.3 实验结果及分析
为了测试本文提出的网络模型人脸检测的效果,对网络模型进行训练和实验,由于本文提出的网络是针对于嵌入式平台,所以选择TINY-YOLO和Fast YOLO网络模型[13]作为对比模型。分别使用E-YOLO、TINY-YOLO以及Fast YOLO在WIDER FACE和FDDB数据集上训练和测试。测试结果如表1所示,在FDDB和WIDER FACE数据集上的PR曲线如图4所示。
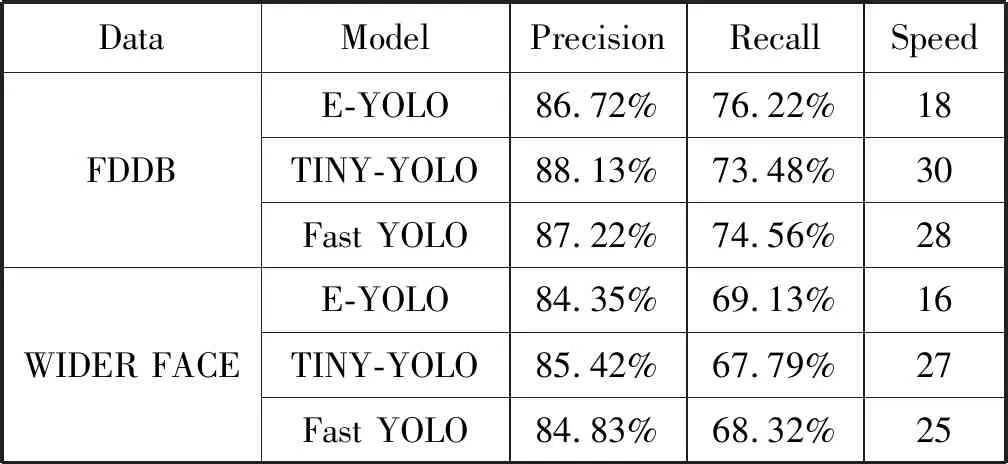
表1 使用FDDB和WIDER FACE数据集实验测试结果
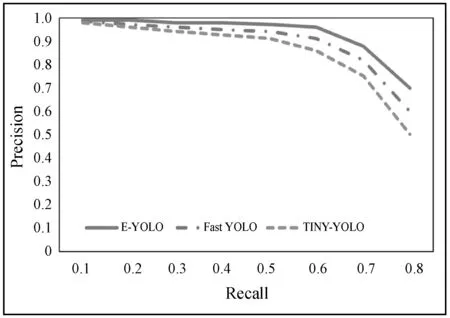
(a) FDDB数据集
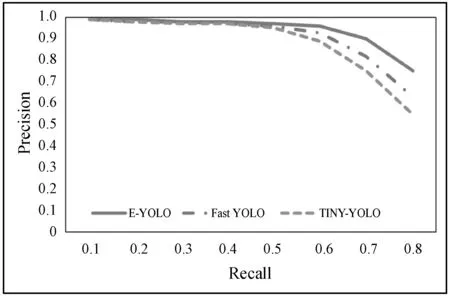
(b) WIDER FACE数据集图4 在数据集上人脸库 PR 曲线
由表1可知,本文提出的网络模型E-YOLO和TINY-YOLO、Fast YOLO在检测的准确度上差别不大,但是相比TINY-YOLO和Fast YOLO模型,E-YOLO模型的召回率要高。因此本文提出的网络模型相比TINY-YOLO和Fast YOLO有更高的平均精度,在recall-precision方面能达到一个更好的平衡状态,其次在检测速度方面E-YOLO要明显优于另外两个网络。
随后将E-YOLO、TINY-YOLO以及Fast YOLO分别移植到嵌入式平台上中,测试其速度和模型大小。本文选择的嵌入式处理器为NVIDIA Jetson TX1,它是英伟达公司推出的第二代嵌入式平台开发组件,体积只有身份证大小,有256个CUDA核心,采用计算机视觉技术、深度学习技术以及GPU计算图像处理技术。
在实验中,将E-YOLO、TINY-YOLO以及Fast YOLO分别移植到TX1嵌入式平台中,输入300帧640×480的视频数据,对输入的视频进行帧采样,对每帧图像进行预处理然后输入到三个模型中,对每帧图像进行人脸检测,检测结果如表2所示。
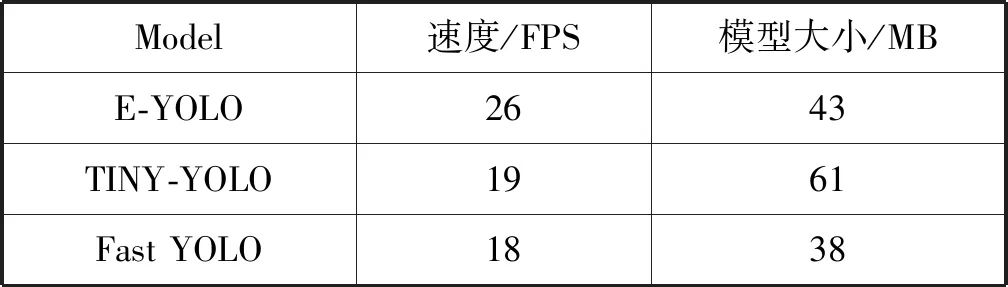
表2 在TX1平台上不同模型对比结果
由表2可知,TINY-YOLO的模型大小为61 MB,E-YOLO的模型大小为TINY-YOLO模型大小的70.5%,为43 MB,相比Fast YOLO模型稍大,但在检测速度方面,TINY-YOLO的检测速度为19 FPS,Fast YOLO检测速度约为18 FPS,而目前市场上大多数摄像机的帧率为25 FPS,均达不到对摄像机视频数据的实时检测,而E-YOLO模型的检测速度为26 FPS,是TINY-YOLO检测速度的1.37倍,基本可以实现在嵌入式平台下的实时人脸检测。图5是不同模型在数据集中测试的结果示例图。

图5 模型在FDDB和WIDER FACE数据集上测试效果图
4 结 语
为了解决嵌入式平台计算能力弱、资源有限、不能部署深度学习人脸检测网络的问题,提出了一种改进E-YOLO网络,模型的主体思想沿用YOLO算法的方案,在YOLO的基础上简化模型,减少卷积核的数目,使得模型可以应用于嵌入式平台,同时去掉全连接层,保留全连接层丢失的信息,提升检测的准确度。实验结果表明,本文提出的算法在模型大小、检测速度以及检测精度上均优于TINY-YOLO模型算法,在准确率和召回率之间取得一个较好的平衡状态,同时移植到嵌入式平台上能够对图像进行实时检测。
下一步的研究工作是将E-YOLO人脸检测网络应用于工业领域,如无人驾驶、智能安防等新产品的开发中。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
汽车实用技术(2022年13期)2022-07-19
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
少儿美术·书法版(2021年9期)2021-10-20
计算机系统应用(2021年9期)2021-10-11
家庭影院技术(2021年7期)2021-08-14
奥秘(2021年5期)2021-06-15
米娜·女性大世界(2016年8期)2016-08-17
奇闻怪事(2014年5期)2014-05-13
