
基于附加间隔Softmax特征的人脸聚类算法
2020-03-11 12:51王锟朋高兴宇
计算机应用与软件 2020年2期
王锟朋 高兴宇
1(中国科学院微电子研究所 北京 100029)2(中国科学院大学 北京 100049)
0 引 言
近年来研究人员在深度学习研究上的重大突破推动了人脸识别算法的快速发展。通过大量有标签的人脸数据进行监督学习,训练出的人脸识别模型不断刷新多个人脸识别数据集,如LFW[1]、MegaFace上的最好成绩。但随之产生了另一个问题:当处理大量无标签的人脸数据时,如何更快更准确地将这些数据按照个体身份(ID)进行分类。这样的应用场景涵盖了社交媒体、安防、执法、大数据分析等多个领域:在社交媒体Facebook中,日均图片上传量达到350万幅;在视频网站YouTube中,每分钟有300小时视频被上传;在中国大约有1.76亿监控摄像头被安装在包括机场、火车站、街道在内的公共和私人领域,每月产生的视频数据量达到EB级别。上述领域产生的数据包含了大量的无标签人脸数据,当企业需要分析自己的用户群体,或发生公共安全事件需要排查人员身份时,我们既无法了解人脸的身份,又无法知道数据中包含的人数,因此使用无监督人脸聚类算法对这些无标签人脸数据进行有效的处理,可以带来巨大的经济、社会价值。无监督人脸聚类算法通常面对以下挑战[2]:1) 数据量巨大,达到十万甚至百万级别;2) 类别多:包含几千甚至上万个个体身份;3) 真实类别数未知;4) 样本数量不均衡;5) 类内变化多,人脸照片在无限制环境下获取,同一人的人脸照片在姿态、光照、分辨率等属性上相差很大。
本文提出附加间隔Softmax损失[3]与Inception-ResNet-v1[4]结构结合的人脸特征提取模型,采用CASIA-WebFace[15]人脸数据集作为训练集,在LFW[1]人脸数据集上取得了99.08%的识别准确率和95.01%(FAR=0.1%)的验证率,超过了Softmax模型和中心损失模型;然后使用基于附加间隔Softmax模型提取的128维人脸深度特征在LFW人脸数据集、LFW与视频模糊人脸的混合数据集上分别对比分析了k-means算法、DBSCAN算法和近似等级排序[5]聚类算法,实验结果表明近似等级排序聚类是更适合处理人脸数据的无监督聚类算法;最后对比了基于Softmax模型、中心损失模型与附加间隔Softmax模型的人脸特征应用在近似等级排序算法上的聚类效果。实验结果表明基于附加间隔Softmax特征的近似等级排序算法是鲁棒性较强的人脸聚类算法,有较高的应用价值。
1 相关工作
在过去几年中,研究人员将在ImageNet大赛上取得突破性进展的VGGNet[6]、GoogleNet[7]、ResNet[8]等深度神经网络结构用于人脸识别研究,并获得了巨大的成功。在此基础上,DeepFace[9]使用精准的三维人脸对齐算法对人脸数据进行预处理,然后使用大量人脸数据训练深层的卷积神经网络进行识别;FaceNet[10]将三元组损失函数用于人脸识别模型的训练。至此对于人脸识别任务已经形成了一个通用的范式:首先使用人脸检测算法检测人脸,然后使用深度神经网络模型提取人脸特征,将人脸验证、识别等问题放在特征空间进行处理。
聚类算法是一种无监督的数据分析方法,被广泛应用于模式识别、统计以及机器学习领域。在深度学习普及之前,研究人员通常使用手工特征,如HOG特征、SIFT特征,对图像进行聚类。深度学习被广泛应用于计算机视觉之后,将图像的深度特征用于聚类可以取得更好的效果。聚类过程如图1所示。
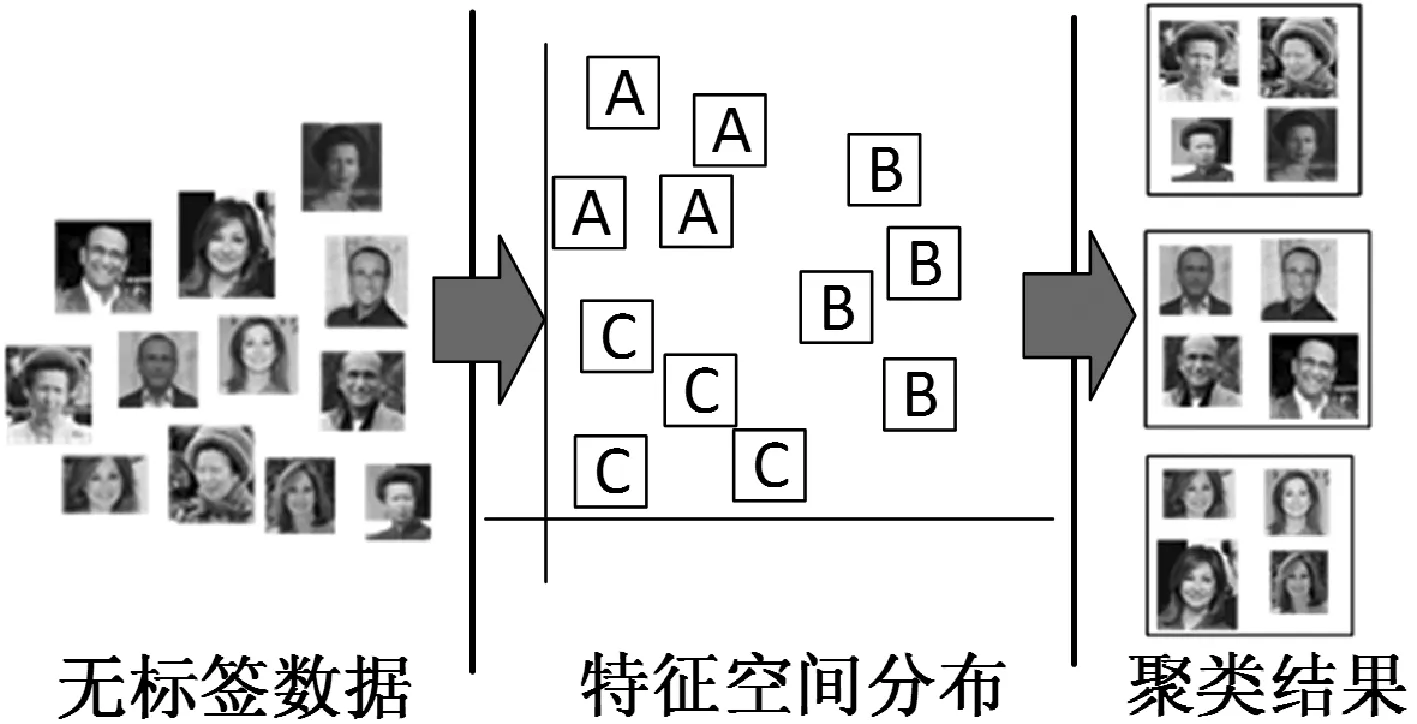
图1 人脸图像聚类流程图
图像聚类的效果不仅取决于聚类算法本身,而且图像特征和相似度度量方式也起着重要的作用。文献[11]提出一种基于卷积神经网络和K-means的图像聚类算法,首先用卷积神经网络学习图像的高阶特征,然后用哈希方法将高维特征映射为低维二进制哈希码,最后利用K-means算法完成聚类。文献[12]提出一种针对人脸数据的无监督聚类算法,该算法使用等级排序来重新定义特征间的相似度,本质上是一种自下而上的凝聚层次聚类算法。
2 附加间隔Softmax特征
2.1 Softmax损失函数
深度学习为人脸识别任务提供了一种端到端的解决方案,将人脸识别任务作为分类任务来处理[13],如图2所示,CNN模型的输入是人脸图片,模型最后的Softmax层输出人脸类别的预测结果。但是由于人脸识别任务中个体身份(ID)数量的不可预测性,以及测试集中的ID种类与训练集没有重叠,所以在人脸识别算法的推断过程中通常采取如下做法:首先移除模型最后的Softmax层,保留倒数第二层的全连接层,全连接层的信息是人脸图片在特征空间的映射,即深度人脸特征(deep face features);然后通过如欧氏距离、余弦距离等度量方式比较人脸特征之间的相似度,完成人脸识别。而模型依然可以按照分类任务进行训练。
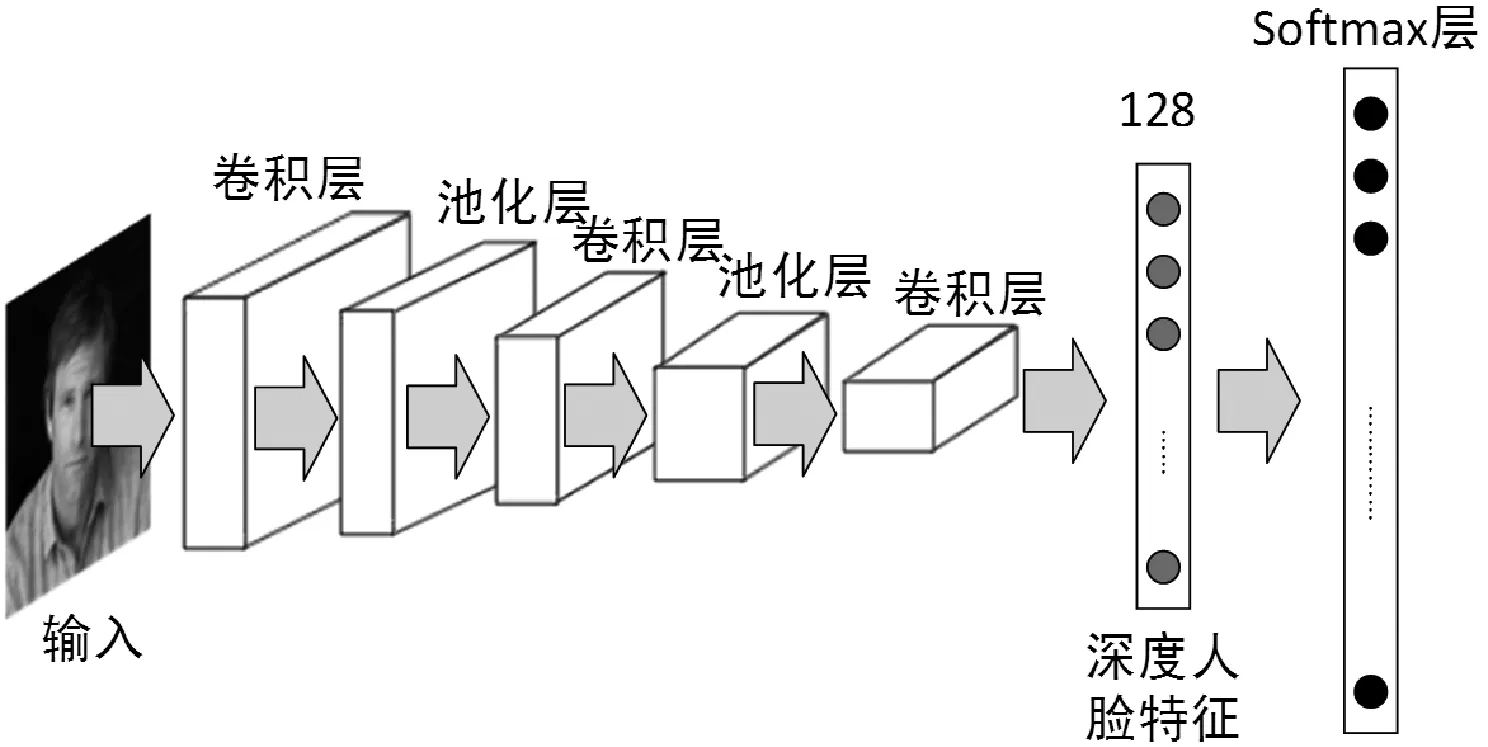
图2 基于Softmax的人脸识别模型示意图
分类模型的训练中最常用的损失函数是Softmax损失函数,主要用于解决多分类问题。Softmax的输出代表分类图像被分到每一类的概率,如图3所示,对于一个n分类器,则输出一个n维向量,向量中所有元素的和为1。对于一个含有m个样本(x为训练样本,y为对应标签)的训练集{(x(1),y(1)),(x(2),y(2)),…,(x(m),y(m))},Softmax输出的每一个样本的n个估计概率如下:
(1)
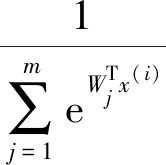
对于整个训练集,Softmax损失函数如下:
(2)
式中:Wj为权值向量,fj为输入x(i)的特征向量,二者的夹角为θj,二维可视化效果如图3(a)所示(图中二维向量分别属于9个不同类别)。
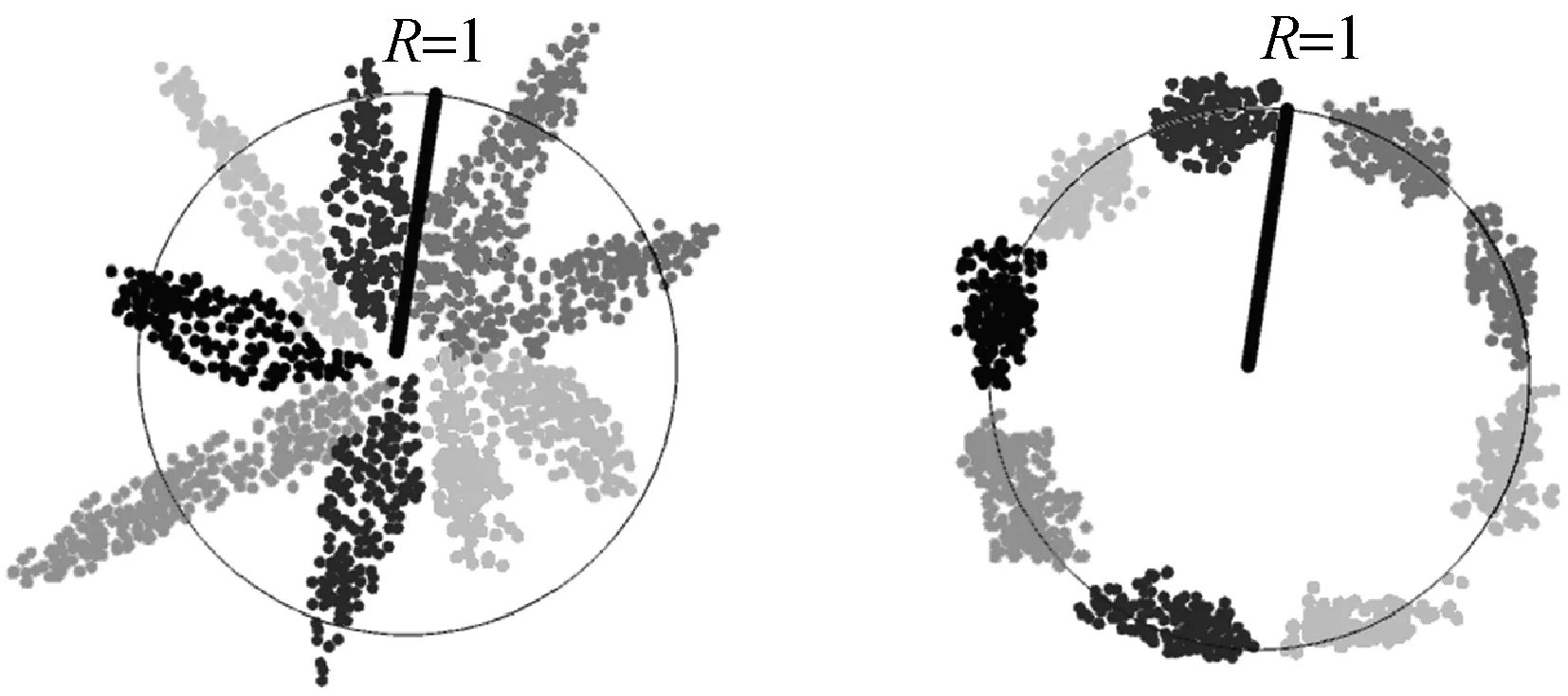
(a) 没有经过权重归一化 与特征归一化处理 (b) 经过权重归一化与 特征归一化处理
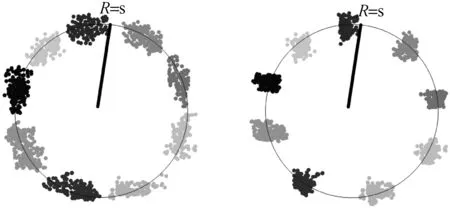
(c) 权重归一化和特征归 一化后乘尺度因子s (d) 权重归一化特征归一化后乘 尺度因子s并添加间隔m 图3 二维特征向量在二维球面的可视化
2.2 附加间隔Softmax损失函数
本文使用附加间隔(Additive Margin)Softmax[3]损失函数来优化模型,使属于同一类别的权值向量Wj与特征向量fj之间的夹角θj更小,不同类别的特征向量fj与fk(j≠k)之间夹角θj更大。首先归一化特征向量Wj与特征向量fj使得特征向量固定映射到半径为1的超球上,即‖Wj‖‖fi‖=1,二维可视化效果如图3(b)所示;然后乘以尺度因子s(s>1),即s·‖Wj‖‖fi‖=s×1=s,超球的半径变为s,特征可以表达在更大的超球上,如图3(c)所示;最后添加附加间隔m,使属于同一类别的权值向量Wj与特征向量fj之间的夹角θj更小,不同类别的特征向量fj与fk(j≠k)之间夹角更大,二维可视化效果如图3(d)所示。因此附加间隔Softmax损失函数表达式如下:
(3)
使用附加间隔Softmax损失函数训练模型的过程与使用Softmax损失函数相同,模型训练完成后,移除附加间隔Softmax层,提取模型倒数第二层的取深度人脸特征。
2.3 模型结构
本文使用Inception-ResNet-V1[4]作为特征提取网络进行训练,其结构如图4所示,它包含了主干网络模块,A、B、C三种Inception-ResNet模块[4]以及A、B两种缩减(Reduction)模块[4]。Inception-ResNet-V1结合了Inception结构[7]与ResNet网络[8]的优点,并且拥有比Inception-v3更快的收敛速度和比Inception-ResNet-v2[4]更少的计算成本。
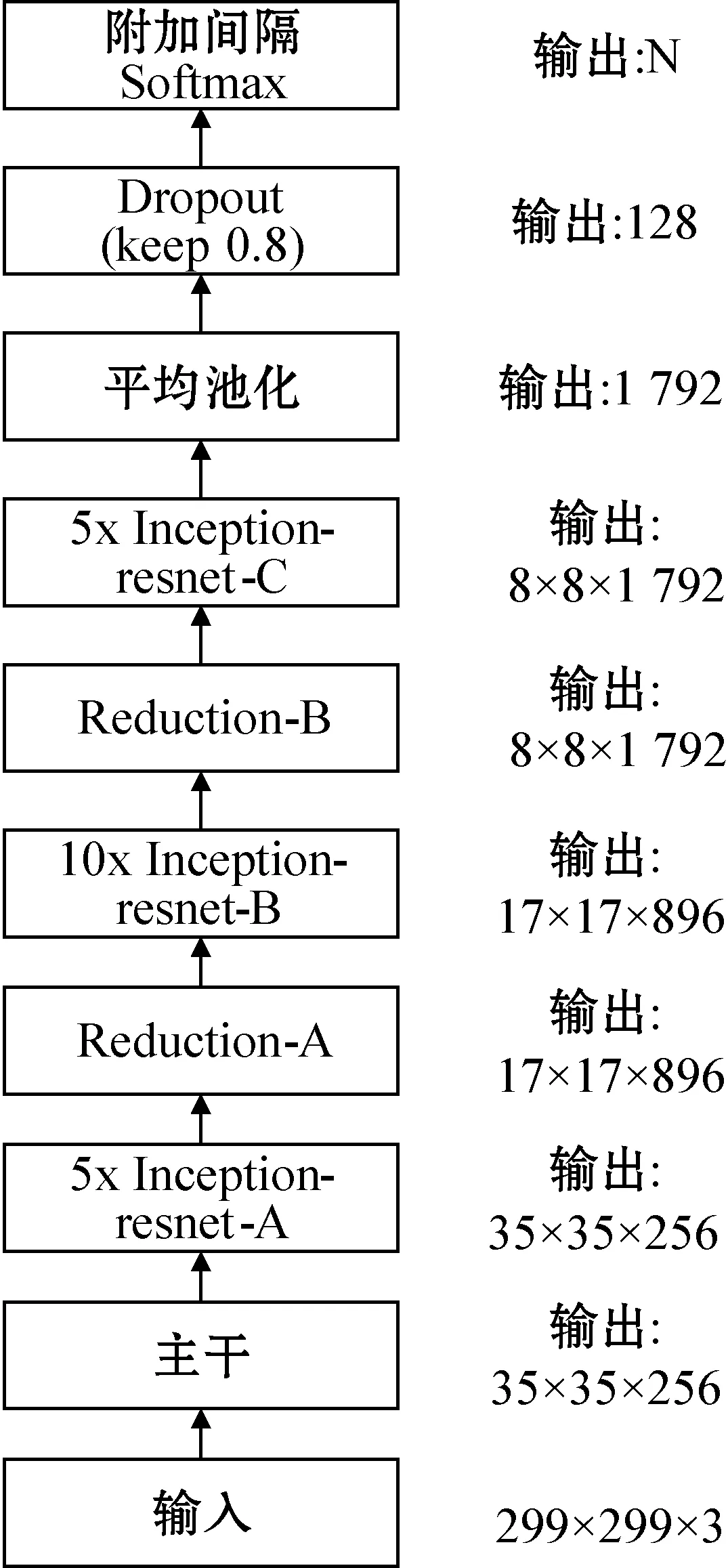
图4 Inception-ResNet-V1[4]架构图
3 无监督人脸聚类算法
在无监督学习中,训练样本的标记信息是未知的,无监督学习的目标是通过对无标记样本的学习来揭示数据的内在性质及规律。无监督学习中最有效的是聚类算法。聚类将数据集中的样本划分为若干个子集,每个子集称为一个“簇”。通过这样的划分,每个“簇”对应一些潜在的概念或分类。人脸聚类算法通过学习数据集中所有人脸样本在特征空间中的分布规律,将整个数据集划分为若干个“簇”,每一个“簇”对应预测一个ID。人脸聚类算法可以在只获得人脸特征而没有任何标签和先验信息的情况下,对大量人脸数据进行分类。
3.1 DBSCAN算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,该算法从样本密度的角度定义样本间的相似性,并基于相似样本不断扩展“簇”的规模,最终得到聚类结果。DBSCAN通过一组邻域参数(Eps,MinPts)描述密度的概念,其中Eps表示样本d的邻域范围(度量方式可以是欧式距离、曼哈顿距离等度量方式),MinPts表示样本d的邻域至少包含MinPts个样本。图5给出直观解释,图中虚线表示邻域Eps的范围,d1是核心对象,d2由d1密度直达,d3由d1密度可达,d3由d4密度相连。DBSCAN的“簇”定义是:由密度可达关系导出的最大密度相连样本的集合。
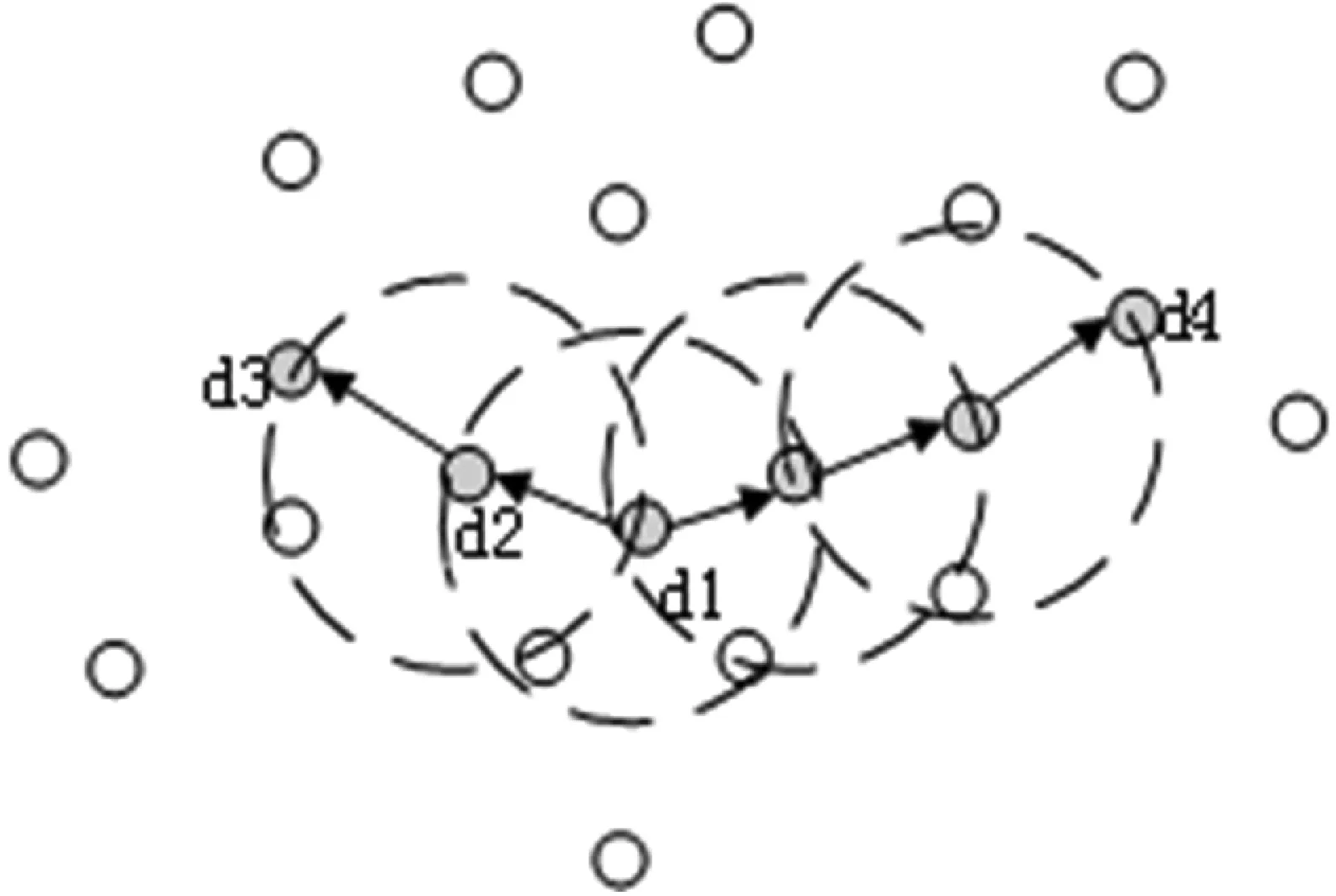
图5 DBSCAN定义的基本概念(MinPts=3)
邻域参数(Eps,MinPts)是影响聚类效果的两个重要超参数,减小Eps与增大MinPts会使样本特征满足“簇”的定义更加困难,不满足“簇”定义的样本(离群值)被记作噪声。因此通过调整超参数(Eps,MinPts),可以使该算法的聚类结果可以包含更少的噪声。当MinPts=1时,则表示单个样本也可以满足“簇”的定义,此时聚类结果中没有噪声;当Eps足够大,所有样本被定义为一个簇,此时聚类结果中也没有噪声。
该算法具有类别数k不需要预先设定、可以处理非凸数据的优点。但是由于DBSCAN算法的邻域参数(Eps,MinPts)固定,当样本集D中不同簇Ci的稀疏程度不同时,相同的判断标准可能会破坏聚类的自然结构,即较稀疏的簇会被划分为多个簇或密度较大且Eps较小的簇会被合并成一个簇。
3.2 近似等级排序聚类
近似等级排序(Approximate Rank Order)聚类[5]改进了等级排序(Rank order)聚类[11]。等级排序聚类利用每个样本的最近邻样本来刻画样本间相似度,是一种自下而上的凝聚层次聚类算法。不同于K-means聚类算法,等级排序聚类算法无需预设类别数;并且不同于欧氏距离、余弦距离、曼哈顿距离等直接的相似度度量方式,等级排序聚类算法提出一种间接的相似度度量方式——等级排序距离,如下式所示:
(4)
式中:fa表示样本a的相似度排序列表,它是按照数据集中所有样本与样本a的相似度关系递减排列的,fa(i)表示样本a的相似列表中的第i个样本,Ob(fa(i))则表示样本fa(i)在样本b的相似列表中的排序位置。这是一个非对称距离,d(a,b)表示了样本a以及样本a相似度列表中比样本b更靠前的样本在样本b的相似度列表中的位置,d(b,a)则相反,通常二者是不等的。在此基础上,使用一个对称距离更好地刻画样本a、b之间的相似度,如下式所示:
(5)
式中:min(Oa(b),Ob(a))是一个归一化因子,它的目的是使样本间的距离可比较,只有当a靠近b,且b又靠近a时,距离D(a,b)的值最小。
若采用线性方法计算每个样本的相似度列表,则需要O(n2)的复杂度,因此近似等级排序(Approximate Rank Order)聚类提出使用FLANN库中的随机k-d树算法[14]计算出相似度列表的前k个样本,只使用相似度列表中的前k个样本进行距离计算。此外重新定义了如下式所示的样本距离:
(6)
(7)
式中:Ib(x,k)是一个指示函数,当x在b的相似度列表的前k项中出现时,其值为0,否则为1。这就意味着样本a、b的相似度列表中共同的相似样本出现频次的重要性高于共同样本排序位置的重要性。算法流程如算法1所示。
算法1Approximate Rank-Order算法
输入:
人脸数据的深度特征F={f1,f2,…,fN},阈值t,相似近邻数量k
过程:
1. 初始化簇C={C1,C2,…,CN},将每个样本作为一个“簇”,即C1={f1},C2={f2},…,CN={fN};
2. 随机k-d树计算fi(i=1,2,…,N)的前k个近邻,记作Ofi,k;
3. 对C中所有的fi、fj,根据对应的Ofi,k与Ofj,k计算dm(fi,fj)与Dm(fi,fj),即Dm(Ci,Cj);
4. 如果Dm(Ci,Cj) 5. 将〈Ci,Cj〉作为候选融合对; 6. 对所有候选融合对进行传递融合(如果〈Ci,Cj〉与〈Ci,Cj〉都是候选融合对,则合并为一个簇) 输出: 簇:C={C1,C2,…,Cm} 为了能够更好地评价人脸聚类算法对无标签数据的分类能力,本文使用改进F1度量[5]对聚类结果进行评价,如下式所示: (8) 式中:Ppair称为成对准确率(pairwise precision),它定义为所有簇中的正-正样本对数量之和与所有簇中的正-正样本对、正-负样本对数量之和的比;Rpair称为成对召回率(pairwise recall),它定义为所有簇中的正-正样本对数量之和与数据集中所有正-正样本对数量之比。当每个样本都被聚类为单独一个簇时,将会得到一个高的准确率,但是召回率会很低,反之将所有样本聚类为一个簇时,会得到很低的准确率和高的召回率,因此F1度量将准确率与召回率有机结合起来,只有在准确率与召回率都取较高值时F1度量才能取得较高值。 实验在Ubuntu16.04系统下进行,CPU为Intel(R) Core(TM) i9-7900XCPU@3.30 GHz,GPU为Nvidia Titan XP,内存为64 GB DDR4 RAM,实验环境是基于Linux的TensorFlow框架,实验在GPU模式下运行。 4.1.1训练数据集 本文使用CASIA-WebFace[15]人脸数据集对模型进行训练,剔除与测试集LFW[1]重复的3个ID后,该数据集包含10 572个ID的约50万幅人脸图片,部分数据如图6(a)所示。训练之前对所有人脸图片进行人脸对齐、裁剪处理,裁剪后的图片大小为112×96像素。 (a) CASIA-Webface部分数据 (b) LFW部分数据 (c) 视频模糊人脸部分数据图6 人脸识别数据集实例 4.1.2测试数据集 本文使用人脸识别领域广泛使用的LFW数据集对特征提取模型和人脸聚类模型进行测试,该数据集包含5 749个ID的13 233幅人脸图片,其中4 069个ID仅包含一幅图片,部分数据如图6(b)所示。测试之前同样对所有人脸图片进行人脸对齐、裁剪处理,裁剪后的图片大小为112×96像素。LFW的测试协议包含了6 000组人脸验证测试对,其中3 000对为相同ID,3 000对为不同ID,本文测试了模型在6 000组人脸对上的准确率,以及0.1%误识别率(FAR)下的验证准确率。 本文使用从视频中采集的模糊人脸数据集对人脸聚类模型进行测试,该数据集包含了500个ID的约15 000幅人脸图片,其中多姿态的清晰人脸图片约8 000幅,多姿态的模糊人脸图片约7 000幅,平均每个ID含有30幅图片,部分数据如图6(c)所示。先进行与LFW数据集同样的预处理;测试时将该数据集与LFW数据集混合,组成数据量大、类别数多、样本数量不均衡、数据属性差异大的混合测试集,混合测试集中的数据与真实应用场景更加接近,测试结果能更准确地反映出算法的鲁棒性和应用价值。 使用附加间隔(Additive Margin)Softmax损失函数,Inception-ResNet-V1网络,对齐并裁剪后的CASIA-WebFace人脸数据集,训练人脸特征提取模型。训练前对训练数据进行随机镜像预处理,训练时设置附加间隔softmax损失的超参数m=0.35、s=30,每批数据大小(batch size)为256,人脸特征维度128,权重衰减系数5e-4,起始学习率0.1,依次在第18 000、30 000、33 000次迭代后衰减为前一次的十分之一,最终迭代次数为35 000。 然后分别使用Softmax损失函数、中心损失[16](center loss)函数训练人脸识别模型作为对比实验。中心损失体现了度量学习的思想,目的是为每个类别学习一个中心cyi,并通过特征与类别中心之间的欧式距离将每个类别的特征fi拉向对应的类别中心,其公式如下: (9) 通常将中心损失与Softmax损失联合使用,如下式所示: (10) 式中:λ为超参数,本文中λ取0.02。 Softmax模型与中心损失模型同样采用Inception-ResNet-V1网络与对齐并裁剪后的CASIA-WebFace人脸数据集从零开始训练。实验结果如表1所示。 表1 人脸特征提取模型在LFW测试集上的比较 实验结果表明,基于附加间隔Softmax的人脸识别模型在LFW数据上具有更高的识别准确率和验证准确率(FAR=0.1%)。 使用基于附加间隔Softmax模型提取的深度人脸特征对比经典的K-means算法、基于密度的DBSCAN算法以及近似等级排序算法,结果如表2所示。在LFW数据集上,近似等级排序聚类取得了0.801的高分,远高于其他算法的F1度量得分,并且聚类得到的簇的数量非常接近真值;K-means与DBSCAN算法得分接近,K-means算法设置超参数K等于真值,因此得到的簇数等于真值;DBSCAN算法得到的簇数与真值也较为接近。 表2 基于附加间隔softmax特征的聚类算法 在LFW数据集上的结果比较 如表3所示,LFW与视频模糊人脸混合集的数据量与数据复杂度较LFW大幅增加,三种算法的F1度量得分都显著降低,近似等级排序聚类得分仍然明显高于K-means与DBSCAN算法;K-means算法得分略有降低,DBSCAN算法得分接近0,近乎失效;但聚类得到簇的数量大约是真值的两倍,这可能是由于模糊人脸数据的引入造成人脸特征类内差异增大,实际属于同一ID的数据被误分为多类。计算复杂度方面,近似等级排序聚类用时最少,分别是K-means算法的0.14倍和DBSCAN算法的0.45倍,这是因为随机k-d树的使用极大降低了算法的时间复杂度。 表3 基于附加间隔softmax特征的聚类算法 在混合数据集上的结果比较 实验结果表明近似等级排序聚类更适合处理较大规模的复杂人脸数据。 使用基于Softmax模型、中心损失模型与附加间隔Softmax模型的128维深度人脸特征测试近似等级排序聚类算法。如表4所示,三种特征在LFW数据集上的测试结果差距不大。如表5所示,当数据集规模与复杂度增加,三种特征的测试结果差距变大,附加间隔Softmax特征取得最高分。实验结果表明附加间隔Softmax特征具有较强的鲁棒性。 表4 基于不同人脸特征的近似等级排序聚类算法 在LFW数据集上的结果比较 表5 基于不同人脸特征的近似等级排序聚类算法 在混合数据集上的结果比较 针对数据量巨大、类别多、真实类别数未知、样本数量不均衡、类内变化多的无标签人脸图像分类问题,本文提出了基于附加间隔Softmax特征的近似等级排序人脸聚类算法:首先使用附加间隔Softmax损失结合Inception-ResNet-V1网络训练人脸识别模型,然后使用该模型提取深度人脸特征应用于近似等级排序聚类。本文在LFW数据集、LFW与视频模糊人脸的混合数据集上进行实验,通过分析识人脸别准确率、验证率(FAR=0.1%)、F1度量得分、算法复杂度等指标,说明基于附加间隔Softmax特征的近似相似度排序聚类算法具有较强的鲁棒性,在处理复杂度的大规模无标签人脸数据方面具有应用价值。 本文使用的所有人脸数据仅用于科研目的,不做商业用途。3.3 聚类算法评价方法
4 实验结果与分析
4.1 人脸识别数据集



4.2 人脸特征提取
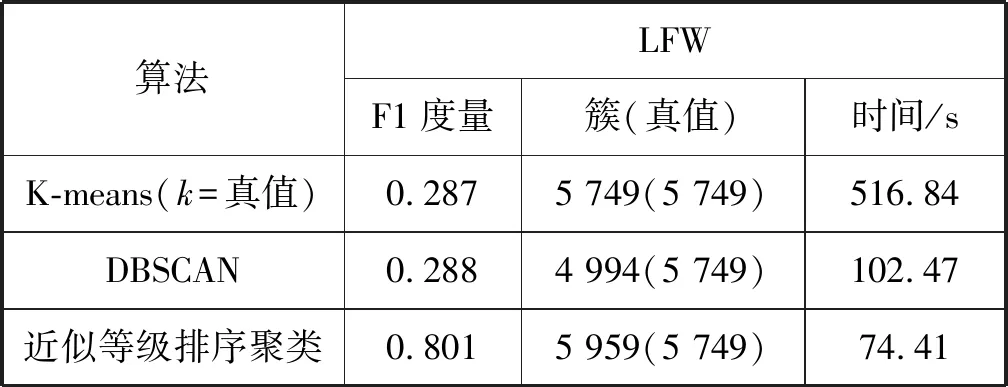
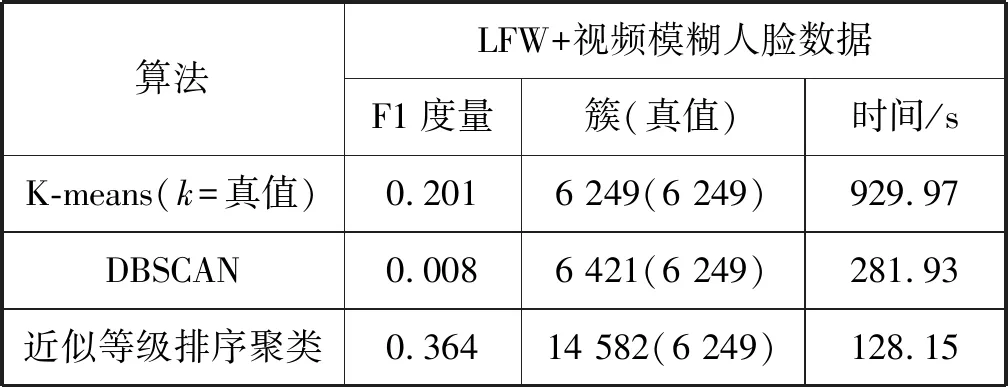
4.3 人脸聚类算法分析
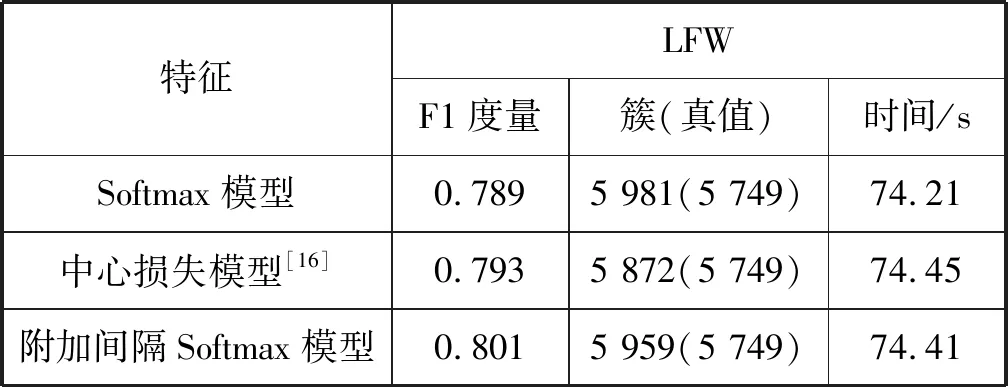
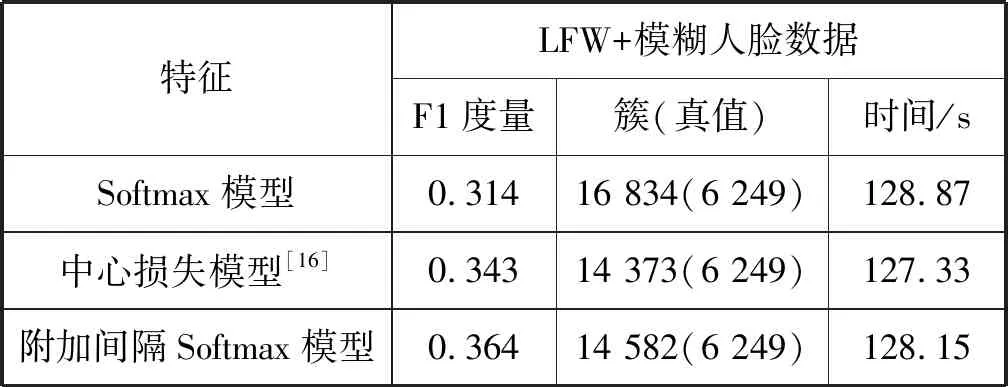
4.4 人脸特征鲁棒性分析
5 结 语
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
奥秘(2021年5期)2021-06-15
名家名作(2021年4期)2021-05-12
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
米娜·女性大世界(2016年8期)2016-08-17
新东方英语(2016年4期)2016-04-06
读写算·小学低年级(2014年4期)2014-07-24
奇闻怪事(2014年5期)2014-05-13
小雪花·成长指南(2009年10期)2009-12-04
