
基于边界跟踪测量麻纤维横截面参数的算法研究与应用
2020-03-10 08:28:20张铮烨辛斌杰邢文宇
纺织学报 2020年2期
张铮烨, 辛斌杰, 邓 娜, 陈 阳, 邢文宇
(1. 上海工程技术大学 电子电气工程学院, 上海 201620; 2. 上海工程技术大学 服装学院, 上海 201620)
纤维图像分析技术是用计算机图像处理和分析技术对纤维图像进行特征分析和测量的一种数字化表征手段,目前被广泛应用于纺织行业中的纤维质量检验。由于用纤维的二值图像提取特征参数更加方便和准确[1-3],所以多年来学者大都通过改进预处理效果、阈值分割算法来增加阈值分割的精度[4-6],其中:吴兆平等[7]利用最大熵二值化获取良好的羊毛纤维横截面图像,然后进行参数提取;徐步高等[8]在原有图像分割算法的基础上提出了双阈值分割算法,通过融合高阈值和低阈值图像提高阈值分割的精准度;陶伟森等[9]通过提轮廓处理提取羊毛、羊绒纤维的纹理特征和形状特征。
综上所述,研究者通常借助纤维二值图像进行纤维的表征和识别,纤维几何特征可通过纤维二值图像分析方法提取相关信息[10-12]。纤维的轮廓外型及形态的准确测量对于纤维品种的鉴别至关重要[13-15]。因预处理会影响纤维边缘的真实性,故本文将纤维横截面原图像灰度化后,用边缘检测算子直接提取纤维横截面边缘,在此基础上进行纤维横截面的周长和面积的计算[16],有效削弱了滤波、阈值分割操作带来的误差。
1 硬件系统及图像采集
目前获取纤维横截面样本需要对纤维进行切片。常用的切片方法需要先将纤维放入介质中进行包埋制样。市售贮麻纤维的3例原始图像如图1所示。可见,用于包埋的介质具有一定的黏稠度,包埋时会产生包埋痕迹,对麻纤维树脂包埋样品进行切片时会保留刀切的痕迹,这些痕迹对参数测量造成的误差无法通过一般图像处理手段进行消除。

图1 麻纤维的原始图像(×20)Fig.1 Original image of hemp fibers(×20)
边缘增强图像融合算法虽然能够解决上述问题,使处理后的图像更清晰,但会使得纤维边界不真实,所测量纤维横截面的周长和面积误差较大,从而导致根据周长面积公式计算出的纤维横截面圆度误差较大。
针对上述问题,本文提出基于边界跟踪测量麻纤维横截面参数的算法,首先将麻纤维横截面图像进行灰度化处理,然后提取麻纤维横截面边缘的轮廓线,再利用孔洞填充算法填充麻纤维横截面区域,获得完整的麻纤维横截面外形,在此基础上,采用相同模板对处理后的图像进行腐蚀和膨胀操作,去除断裂纤维的边缘及伪边缘,利用边界跟踪算法标记麻纤维并获得麻纤维横截面边缘的坐标,最后计算出麻纤维横截面周长和面积。本文算法包括 3个部分:1)图像硬件系统的搭建; 2)图像处理与提取算法的开发;3)实验数据分析。
用于纤维横截面分析的CX41计算机辅助显微镜系统(奥林巴斯株式会社OLYMOPUS),由1台 U-TV0.5XC 型三目显微镜,1台PDS50型数码相机和 1台三轴机动平台组成。三轴载物台在x,y方向上传送样品载玻片,并在每个(x,y)位置调整图像在z轴上的焦点,从而捕获清晰的纤维横截面图像。
2 图像处理
麻纤维横截面图像处理的目的是从采集的图像中提取纤维边缘、形状等信息,为进一步的图像分析提供数据。本文麻纤维横截面图像处理主要分为以下4个步骤:边缘提取,孔洞填充,腐蚀操作,边界跟踪。
本文用计算机辅助显微镜系统采集的图像为RGB格式,为加快算法运算速度,减少无关数据量,增强有关信息的可检测性和最大限度地简化数据,首先将采集的横截面图像转换成灰度图,然后进行后续操作。A#样品的算法对比图如图2所示。

图2 算法对比图(×220)Fig.2 Comparisons of algorithms(×220). (a)Direct binarization;(b)Algorithm in this paper
由图2可以看出,由于原图像背景模糊,直接对预处理后的原图像进行二值化无法获得纤维的有效信息;同时预处理会影响纤维的真实边缘,因此本文将麻纤维截面边缘提取后,利用孔洞填充算法填充纤维闭合的区域,重建麻纤维横截面,之后直接利用算法进行纤维横截面周长和面积的测量,并将计算出的周长、面积和圆度数据保存在数据矩阵中,图像处理效果见图2(b)。
2.1 Canny算子边缘提取
本文选用Canny算子进行纤维边缘提取,Canny算子可以检测到弱边缘,且获得的边缘很细,没有强弱之分,具有很好的边缘监测性能。其基本步骤如下。
步骤1:用二维高斯滤波模板进行卷积以消除噪声,卷积公式为
S(x,y)=G(x,y,σ)*I(x,y)
(1)
式中:*表示卷积;I(x,y)表示原图像;G(x,y,σ)表示高斯滤波模板;S(x,y)表示高斯滤波后图像;x表示横坐标,像素;y表示纵坐标,像素;σ表示高斯滤波器宽度,像素。
步骤2:利用导数算子计算水平方向和垂直方向的偏导数(Dx,Dy)。
Dx(x,y)≈
(2)
Dy(x,y)≈
(3)
相当于与模板进行卷积运算:

(4)
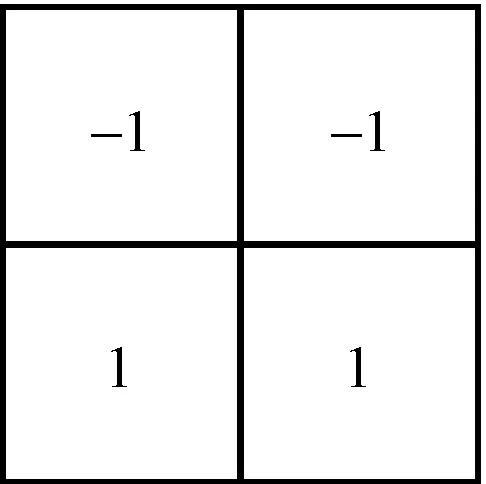
(5)
步骤3:求出梯度M(x,y)和梯度方向θ(x,y)
(6)
θ(x,y)=arctan(Dy(x,y)/Dx(x,y))
(7)
步骤4:对图像中的每个像素进行上述操作,并保留梯度方向上的极大值点。
步骤5:使用累计直方图计算高低阈值,灰度值大于高阈值的一定是边缘,小于低阈值的一定不是边缘,介于之间的,通过已确定的边缘点,发起8邻域方向的搜索,图中可达的点是边缘,不可达的点不是边缘。
利用Canny算子得到的C#样品边缘检测图如图3所示。可知,麻纤维中腔中的弱边缘被很好地检测出来,同时纤维边缘较细,没有粗边缘。图像预处理后介质包埋痕迹、刀痕清晰地显示出来(即那些除纤维边缘外的黑线,就算改变了边缘检测的敏感度阈值也无法清除这些痕迹。这些痕迹大多数位于纤维边缘附近,极大影响了边缘检测的准确性。不同敏感度下,Canny检测出的边缘数量不同,尤其是对弱边缘和伪边缘的检测。其中敏感度阈值设为0.3时,检测出的弱边缘较多,同时检测出的伪边缘较少,因此本文将敏感度设为0.3进行边缘检测。

图3 Canny算子边缘检测图(×220)Fig.3 Edge detection graph of canny operator(×220). (a)Adaptive sensitivity;(b)Sensitivity is 0;(c)Sensitivity is 0.3; (d)Sensitivity is 0.5
2.2 8邻域边界跟踪
在检测出原图中的纤维边缘后,利用孔洞填充算法填充闭合区域,去除了部分边缘断裂的纤维和伪边缘。8邻域方向码如图4所示。

图4 8邻域方向码Fig.4 8 Neighborhood direction code
可见,去除离散噪声后利用8邻域边界跟踪函数检测边界完整的纤维并进行标记。首先找到位于图像左上角的纤维边界点作为搜索起点,按逆时针方向,自上而下,从左至右,搜索该点的8邻域,找到下一个边界点,然后以此点为当前点继续搜索,不断重复上述过程,直至回到搜索起点。
B#样品单纤维边界跟踪图如图5所示。可知,白色线为搜索路径,当1个纤维的边界搜索完成后,形成闭合区域,就对该区域进行标记,然后再进行下一个目标的边界跟踪,直至标记出图像中的所有边缘完整的麻纤维。由于采用的是8邻域跟踪,因此采用欧氏距离计算跟踪路径,即计算目标横截面周长。

图5 单纤维边界跟踪图Fig.5 Single fiber boundary tracking chart
在图5基础上预处理及边界跟踪图像如图6所示。可见,预处理后图中共有5根麻纤维,其中只有左上角的 1根麻纤维横截面边界是完整的。由图6(b)可见,直接从灰度图中提取麻纤维横截面边界,然后进行边界跟踪操作,图中部分因预处理导致横截面边缘断裂的麻纤维能够被检测出来。

图6 预处理及边界跟踪图像(×220)Fig.6 Preprocessing (a) and boundary tracking(b) image(×220)
麻纤维横截面原图灰度化后,灰度图中只能观察到纤维和杂质。图7示出C#样品的多纤维算法处理效果对比。

图7 多纤维算法处理效果对比图(×220)Fig.7 Comparison of multi-fibres treatment effects. (a)Common algorithms;(b)Algorithm in this paper
由图7可见,原图像经滤波操作直接进行阈值分割的常用算法,使得灰度图中观察不到的树脂浇灌的痕迹可清晰地展现在二值图像中,同时切片中的杂质也被二值化。本文算法处理的效果图如图7(b)所示。对比原图像可知,被标记出的目标大部分是横截面边缘完整的麻纤维,错误目标数量极少,且错误目标的形态与麻纤维的形态差异较大,因此可以根据测得的数据进行错误数据剔除。
3 数据提取与分析
本文采用欧式距离法计算麻纤维横截面的周长,采用像素累积法统计麻纤维横截面的面积。上述方法计算出的参数与原来的参数有一定误差,因此本文通过计算直径分别为20、50、150像素的圆的数据,计算实际的偏差。测试圆的统计数据见表1。可看出,利用上述方法计算的直径为20和50像素的圆的周长偏差较小,而直径为150像素的圆的周长偏差较大,3个测试圆的面积偏差都稍大,但是 3个测试圆的圆度参数误差很小。根据本文算法测得麻纤维的周长和面积大致与直径为50像素的圆类似,因此用本文算法测得的麻纤维形态参数偏差较小。

表1 测试圆的统计数据Tab.1 Statistics data of test circles
图8示出麻纤维横截面参数。可知大部分数据聚集在一个区域(图中黑色的点)内,图中8个周长大于140像素的点与大部分数据偏差较大,离大部分黑色点较远,因此这些点为错误数据的概率极高,造成的原因可能是由于麻纤维黏连导致数据偏大。

图8 麻纤维横截面参数Fig.8 Cross-sectional parameters of hemp fibers
图9示出200个样本的麻纤维圆度统计。麻纤维的圆度大部分位于0.6~0.95之间。圆度低于0.6的数据可能是因为麻纤维横截面缺损导致的,圆度大于0.95的数据可能是气泡或者细小的杂质。

图9 麻纤维圆度统计Fig.9 Roundness statistics of hemp fibers
4 结束语
文章用边界跟踪算法定位和标记目标,测量麻纤维横截面的周长和面积参数,提取多目标参数,提高了纤维横截面参数提取的速度和效率。本文算法尚无法分辨纤维黏连的情况,无法测量边缘断裂纤维的参数,而纤维黏连和横截面破损会影响测量数据的准确性,纤维横截面边缘的断裂会影响测量的效率,在这方面本文算法还有待提高,测量数据的精确度也有待提高。
FZXB
猜你喜欢
数学小灵通·3-4年级(2020年12期)2021-01-14 00:58:44
小学生学习指导(中年级)(2020年12期)2021-01-08 02:50:08
纺织科学研究(2020年1期)2020-02-25 00:38:01
数学小灵通·3-4年级(2017年12期)2018-01-23 03:38:05
纺织科学研究(2017年6期)2017-07-03 12:14:28
通信产业报(2016年44期)2017-03-13 08:41:45
读写算(中)(2015年11期)2015-11-07 07:24:35
现代纺织技术(2015年5期)2015-02-24 04:57:03
现代纺织技术(2015年1期)2015-02-24 00:57:59
雕塑(1999年2期)1999-06-28 05:01:42
