
基于DBM-LSTM的多特征语音情感识别
2020-03-07 12:48张雪英黄丽霞李宝芸
计算机工程与设计 2020年2期
高 帆,张雪英,黄丽霞,李宝芸
(太原理工大学 信息与计算机学院,山西 太原 030024)
0 引 言
语音是人与人之间交流的手段,同时也是传递情感的媒介,因此语音渐渐成为了人机交互中大多数研究者所期待的最方便、自然的交互方式。语音情感识别(speech emotion recognition,SER)过程如图1所示,包括预处理、特征提取和情感识别模块。这3部分的性能对识别系统的性能都有一定影响。本文的研究主要针对后两项,即特征提取和识别模型构建。目前,传统的语音情感识别特征有韵律特征、Mel频率倒谱系数(mel-frequency cepstral coefficients,MFCC)[1]等;识别模型主要有支持向量机(support vector machine,SVM)[2]和深度神经网络(deep neural network,DNN)[3]等。

图1 语音情感识别
SER使用传统特征和识别模型虽然取得了一些进展,但是语音信号本质是非平稳信号,使用传统方法进行情感认知存在一定的局限性。因此本文提取情感语音信号的韵律、MFCC、非线性属性
[4]
和非线性几何特征
[5]
,使用深度信念网络
[6]
(deep belief network,DBN)的基本单元深度受限玻尔兹曼机(deep-restricted Boltzmann machine,DBM)进行特征融合与降维,通过加入非线性特征和融合网络有效地改善了传统的单一特征在表达情感信息方面的不足。最后以长短时记忆单元
[7]
(long-short term memory,LSTM)作为识别模型,弥补了传统模型非线性变换能力和表征能力弱的缺陷。我们将本文提出的基于深度学习的特征提取和识别网络称为基于DBM-LSTM的混合神经网络,通过实验验证了该模型的有效性。
1 特征提取与识别模型
构建多特征融合模型和识别网络是本文的关键。首先,由文献[8]可知受限玻尔兹曼机(restricted Boltzmann machine,RBM)擅长学习数据的高层特征,RBM堆叠形成DBM,DBM具有多层非线性变换结构,能够完成复杂非线性函数的模拟。其次,由文献[7]可知LSTM善于对时间序列分析,而且具有长时记忆功能,能够有效利用前后帧相关信息进行分析。
1.1 深度受限玻尔兹曼机
RBM结构如图2所示,其工作原理是基于能量函数使用对比散度快速学习算法[9](contrastive divergence,CD)对特征进行重构,形成新的特征向量,该特征向量充分描述了特征的相关性。可视层与隐藏层分别用v和h表示,偏置分别用a和b表示,W代表权重矩阵,对于状态 (v,h),能量公式为
(1)
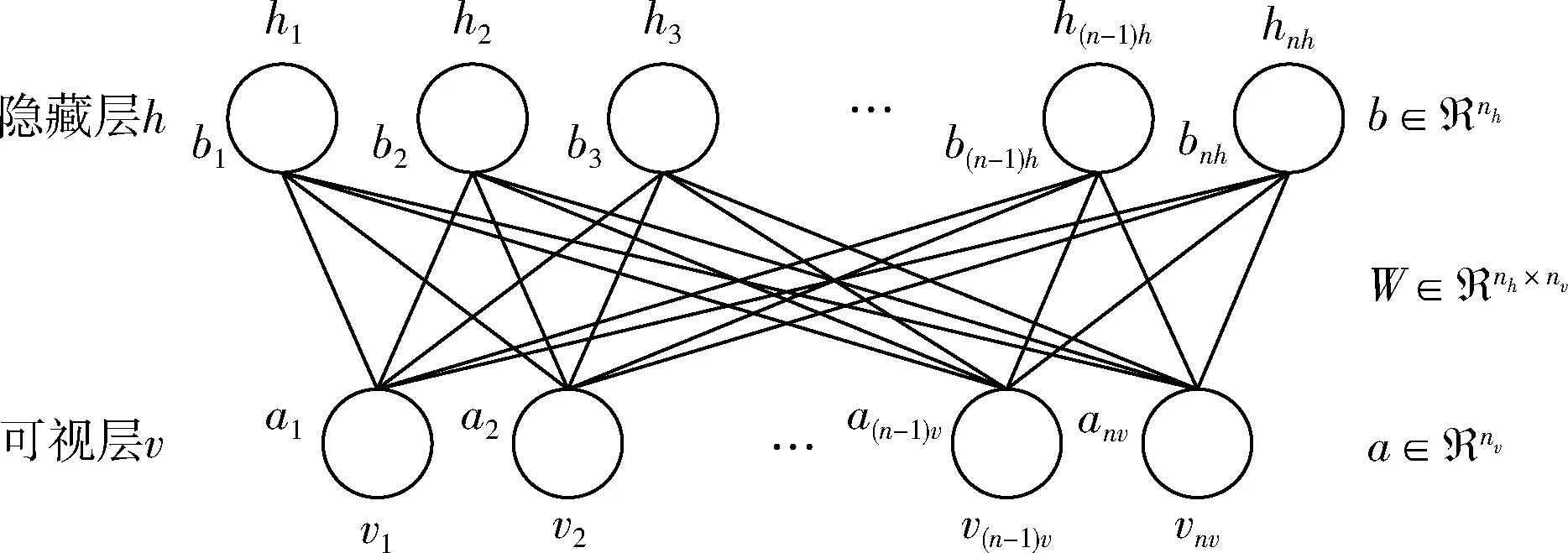
图2 RBM结构
LSTM通过特殊的设计克服了RNN的梯度消失问题,它不仅能够存储较长一段时间的有用信息,而且能够优化时间序列的分类任务[10]。语音信号就是由一系列时间帧构成的,因此将LSTM用在语音识别中应该能展现出比传统模型更优异的性能。LSTM单元展开如图4所示,其中各个门的输出按式(6)进行更新
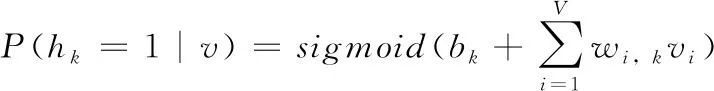
(2)
传统RBM服从伯努利-伯努利分布(Bernoulli-Bernoulli),是一种二值分布(0-1分布)。Bernoulli型节点难以模拟情感语音等非二值分布数据,因此本文使用高斯-伯努利分布(Gaussian-Bernoulli)的RBM,自下而上逐层堆叠,下层输出作为上层输入形成DBM,结构如图3所示。该方法通过引入高斯噪声来模拟真实数据,其能量函数与条件概率为
(3)
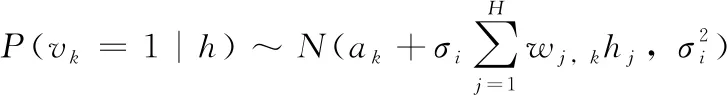
(4)
识别网络结构如图6所示,这是一个多层LSTM加一层softmax层结构,神经元数目及网络层数见表4。

图3 DBM结构
二是加快完善流域水利规划体系。进一步完善流域综合规划体系,海河流域综合规划获得国务院批复,独流减河口综合整治规划治导线调整报告、拒马河流域综合规划通过水规总院审查,流域水中长期供求规划、滹沱河、蓟运河、滦河等工程规划取得阶段性成果。
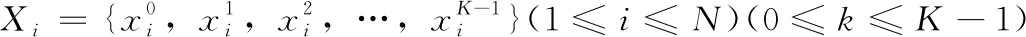
(5)
步骤1 初始化(Initialization)
LSTM识别网络能够综合考虑时序问题前后帧特征之间的关联性,网络当前时刻的输入是将当前帧与前后相邻几帧的特征连接起来;当前时刻的输出是由当前时刻的输入和前一时刻的输出共同决定。最终,LSTM层的输出通过softmax层,输出每一类情感的概率。
(2) 指定参数k。
综上所述,在新课程教学改革的背景下,借助信息技术开展教学,锻炼学生的综合能力以及综合素养已经成为教师新的教学重点。在开展数学教学的过程中,结合微课教学手段能够有效地激发学生的学习热情以及学习欲望,促进学生学习质量以及自主学习能力的提升,使其能够主动自主学习,进而促进学生的全面发展。
(4) 初始化权值W,偏置a、b,高斯标准方差σ。
步骤2 训练(Training)
(1) 调用CD-k算法训练每一个RBM。
本文主要采取以下3种优化方式:
(3) 将多个RBM连接构成DBM,上一个RBM的隐藏层即为下一个RBM的可视层,上一个RBM的输出层即为下一个RBM的输入层。
(4) 最后一个RBM的隐层输出向量h即为输入特征的深层表示。
1.2 长短时记忆单元
当给定可视层(或隐藏层)的所有神经元状态,则隐藏层(或可视层)的某个神经元被激活(状态为1)的概率表示为
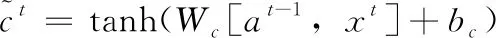
(6)

图4 LSTM单元基本结构
2 基于DBM-LSTM的情感语音识别
本文首先将原始特征经过主成分分析(principal component analysis,PCA)后输入DBM。然后DBM通过多次特征重构将能量、基频、频谱等低层次特征的统计特征映射为更适合情感识别的深度特征。最后为充分利用LSTM分析时间序列的优势,将深度特征输入到多层的LSTM中进行识别。
2.1 DBM特征提取
DBM输入特征见表1,网络每一层的输出为下一层的输入,网络结构如图5所示,这是一个多层RBM叠加,其中每一个子块都是四层结构,其神经元数目见表2。

表1 输入特征
输入特征变化见表3,特征提取按以下步骤进行:
第一步将经过PCA处理的韵律特征、MFCC特征、非线性几何特征、非线性属性特征输入到DBM-1层中进行第一次深度融合与降维,得到隐层输出为特征1、特征2、特征3、特征4。
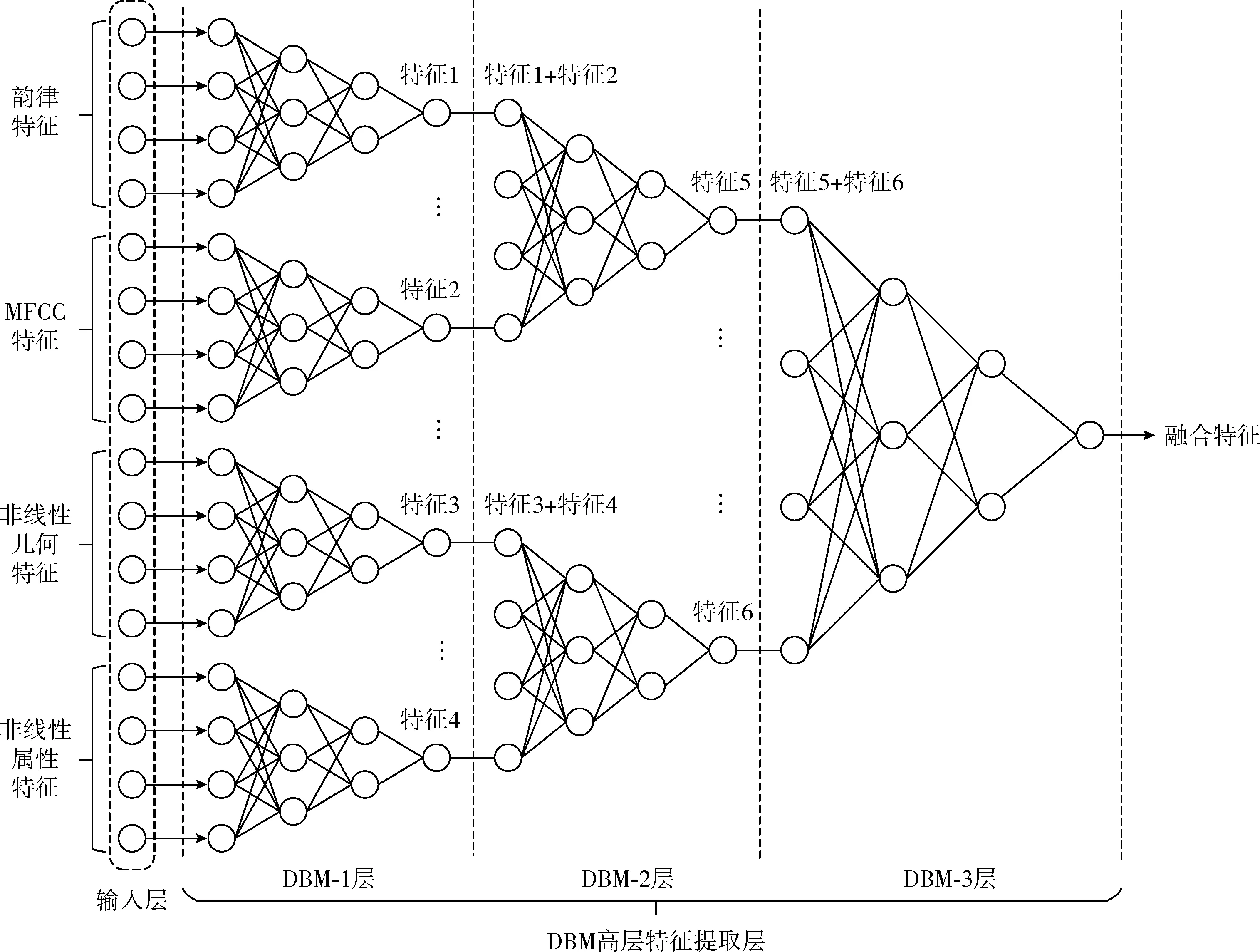
图5 DBM网络结构
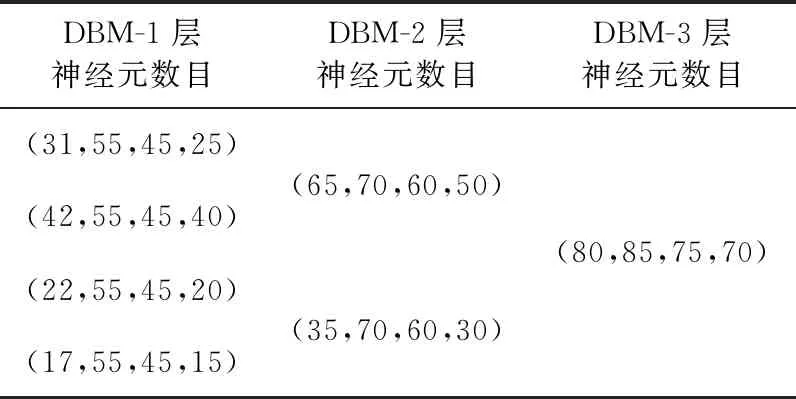
表2 DBM网络结构
第二步根据特征的属性,将特征1与特征2,特征3与特征4分别线性拼接,输入DBM-2层进行第二次深度融合与降维,得到隐层输出特征5与特征6。
第三步将特征5与特征6线性拼接,输入DBM-3层进行第三次深度融合与降维,得到隐层输出融合特征。
2.2 LSTM识别网络
vi和hj分别表示可视层与隐藏层第i个神经元和第j个神经元的状态,ai和bj分别表示其偏置,Wij表示可视层中第i个神经元与隐藏层中第j个神经元之间的连接权重,σ是高斯函数的标准方差,W,a,b,σ所构成的参数集合为θ=(W,a,b,σ)。

表3 特征变化

图6 LSTM网络结构

LSTM层特征类型神经元数目融合特征(70,80,60,5)
第三,本文主要使用了dropout[11]技术来防止训练过程中的过拟合,在DBM和LSTM层均使用了dropout。它主要通过在每个训练批次中忽略掉一半的特征检测单元,减少特征检测单元的相互作用,让某些神经元的激活值以一定的概率p停止工作,这样可以使模型的泛化能力更强,不会依赖某些局部特征。
2.3 基于均方误差和交叉熵的代价函数
目前神经网络使用最广泛的代价函数是均方误差代价函数和交叉熵(crsoss-entropy)代价函数,人们在设计模型的时候希望输入数据通过识别模型能最大程度地映射为其所属的标签,最后一层神经元的输出与目标值越接近越好,由此人们引入了均方误差损失函数,表达式如式(7)所示。xi代表第i个语音数据,y代表第i个语音数据对应的标签,a代表第i个语音数据输入到网络中的实际输出值,n代表数据的总数 (1≤i≤N)
(7)
使用仿真软件,输入扩孔钻头的结构参数、钻进参数及岩石参数,将扩孔钻头的切削齿和井壁离散化,如图4所示,再模拟、分析在导向钻井及复合钻井等条件下新型扩孔钻头的切削力学性能与稳定性能。
(8)
2.4 优化方式
综上所述,将任务打包[10]发布可以让会员同时接到多个由公司设计好的最优任务包,能够让会员在最短的时间内完成较多的任务.并且将任务打包发布可以将单个任务价格适当调低,既能保证会员的收入又能减少公司的费用.通过对原定价模型的修改使一些“冷门”任务得以完成,将任务的执行情况进行了优化,提高了任务的完成度.
第一,DBM和LSTM层主要使用反向传播算法 (backward propagation,BP)进行梯度计算。BP算法拥有较强的非线性映射能力,可以不断地调整神经网络中的参数,以达到最符合期望的输出。
乞求皮特发慈悲的想法让我怒从胆边生,冲动之下,我抬脚朝皮特的侧身踢去。事与愿违,他抓住我的脚,向前一拽,我一下失去了平衡,背部着地,仰面朝天狠狠地摔在地上,只好把脚抽回来,挣扎着站起身。
(1) 给定训练集x。
3 实 验
3.1 数据集
本文使用柏林技术学院W.Sendlmeier教授课题组录制的EMO-DB柏林情感数据库进行验证,主要情感包括悲伤、愤怒、高兴、害怕、中性等5类情感,数据构成见表5。

表5 数据库
3.2 特征选取
本文在课题组之前的研究成果背景下,主要使用4类180维特征进行语音情感识别,由于初次提取后的特征存在一定信息冗余,本文对其进行了PCA融合降维。
3.3 网络参数设置
本文以DBM-LSTM网络结构为例,通过多次实验确定网络参数:minibatch为32,学习率为0.001,dropout为0.09-0.11,当输入为融合特征时最大迭代次数30-100次,参数取值情况见表6,情感识别结果随参数变化情况如图7所示。
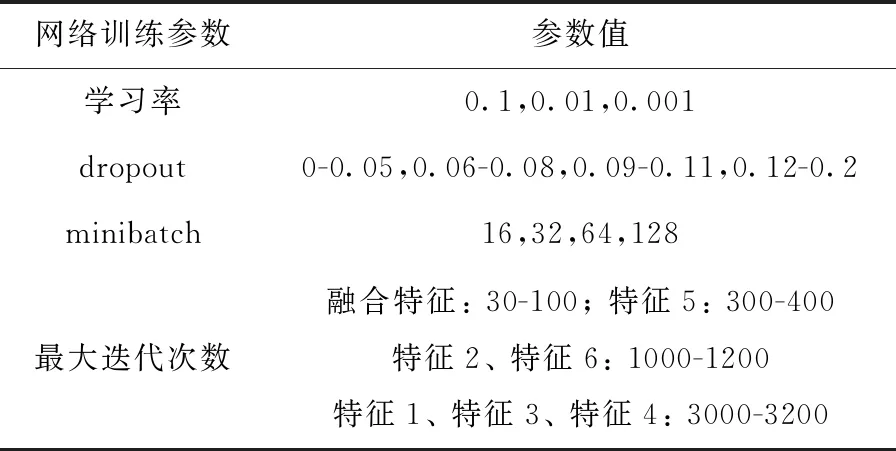
表6 训练参数
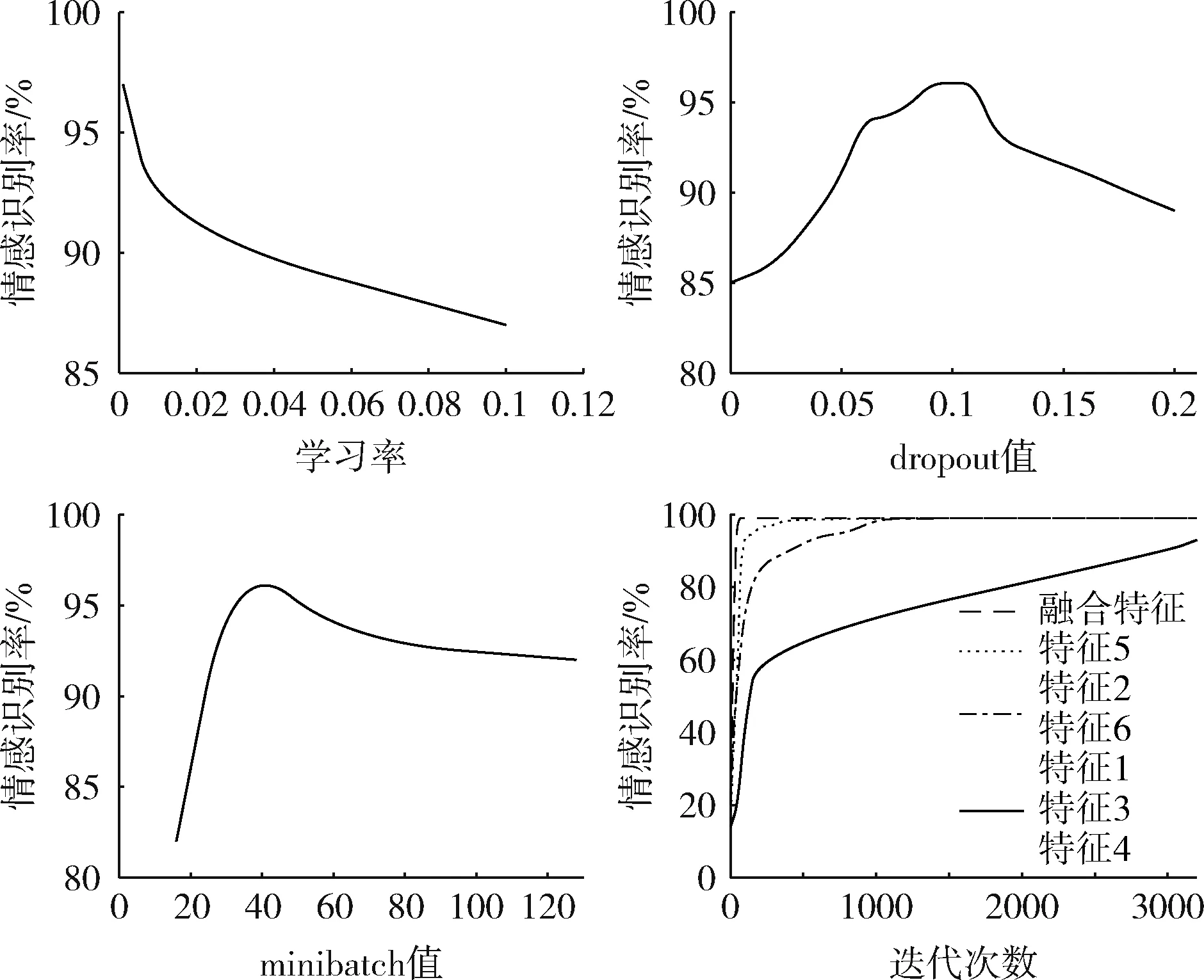
图7 参数对识别结果影响变化曲线
为了验证本文提出的DBM-LSTM结构的有效性,本文设置了多组对比实验,其中对比实验网络结构包括SVM,DNN。
3.4 实验分析及结果
表7统计了4类特征在第一次深度提取前后分别通过SVM、DNN、LSTM等分类器的识别结果。
由表7可知,在单一特征的对比中特征2(MFCC特征深度提取后)取得了最优的识别结果,表8将其与两特征融合(特征5、特征6)和四特征融合(融合特征)进行了对比。

表7 深度提取前后实验结果对比
对数据进行可视化处理如图8所示,经分析得出以下结论。

图8 情感识别结果对比折线
第一,由表7可知,经过DBM第一次深度融合降维后的特征,在各分类器上都表现出了更好的性能,其中通过LSTM分类器时获得了最优的性能,且高于传统分类器SVM。
第二,由图8可知,融合特征在各分类器上的识别结果均高于最优单一特征(特征2)。由此可知,DBM-LSTM有助于多特征融合,且融合后的特征性能更优。
4 结束语
针对传统单一特征在语音情感识别过程中表征能力不足和传统识别模型非线性变换能力较差的问题,本文提出了一种基于DBM-LSTM的混合神经网络,DBM主要用于情感语音的深层特征提取和多特征融合,LSTM主要用于情感语音识别,成功解决了多情感分类的难题。结果显示,在输入特征相同的情况下,与传统识别模型相比,DBM-LSTM模型在处理情感语音信号的分类问题上具有更好的性能。本研究尚未引入脑电信号作为辅助信号进行语音情感识别,同时在今后的研究过程中,拟利用不同情感之间的关联性改进LSTM网络的代价函数。
猜你喜欢
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
现代装饰(2018年5期)2018-05-26
自动化学报(2017年11期)2017-04-04
系统工程与电子技术(2016年7期)2016-08-21
系统工程与电子技术(2016年7期)2016-08-21
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
智能系统学报(2015年4期)2015-12-27
中国生化药物杂志(2015年4期)2015-07-07
弹箭与制导学报(2015年1期)2015-03-11
