
利用卷积生成式对抗网络生成中文汉字
2020-03-07 06:35
网络安全技术与应用 2020年2期
(讯得达国际书院 广东 518000)
虽然中文汉字的文字生成已经在许多年前就有人做过,并且训练出了很成熟的模型,但是以前从来没有利用卷积生成式对抗网络来达成这个目的。所以,我们利用卷积神经网络和生成式对抗网络来进行实验,在经过数百个小时的训练之后成功地训练出了一个可以自主生成100 种随机字体的中文汉字的模型。
1 绪论
早在二十世纪初期,随着连接主义学习的卷土重来,世界掀起了深度学习的热潮,狭义地说就是“很多层”的神经网络。在机械学习被开发出来之前,人们使用非机械学习创造出来的模型都需要人工手调参数,这无疑是一项很大的工作量。现在,归功于深度学习,人们大大地降低了模型的操作难度,机器学习者们对其应用的门槛也变低了,使得对机器学习技术的发展带来了巨大的便利。在深度学习的领域当中,人们普遍开始运用卷积神经网络来对图片和影视进行分析,并且已经取得了很大的成果,例如将其运用在医学领域,对病人的病变进行检测,或者对于文字的识别和生成。
阅读和书写一直以来都是人们在生活以及学习中最基本的两个技巧,用来帮助我们获取以及传达信息。文字已然成为人们生活中不可缺少的一部分,并且不同的字体能给读者在阅读时带来不同的感受,所以字体在传递信息和情感上起着非常大的作用。而中文,作为全世界使用人数最多的一门语言,其重要性和影响力更是可想而知。早在之前,微软公司就曾花费数亿美元的资金并且耗时很长时间才打造出了一款全世界汉字使用者都在使用的字体:微软雅黑。不只是微软,还有其他很多互联网巨头都曾花费巨资打造了自己的中文汉字字体,人们运用神经网络于中文文字的生成这一领域已经取得了巨大的成就。然而,虽然目前市面上已经有了很多成熟的中文字体,但是打造所花费的金钱和时间都是巨大的。所以,为了要找到一个更加节省资源和时间的方法,我们这次将利用卷积神经网络以及生成对抗网络一起进行试验,完成我们目的中的一个小目标:通过我们自己制作的数据集,生成正确的中文汉字。经过了超过一百小时的训练以后,我们成功地利用卷积生成式对抗网络训练出了一个能够自主随机地生成100 种不同字体的中文汉字的模型。假如在将来能将我们这次实验训练出来的模型继续深入发展,对这个模型做更进一步的改善,那么它将能生成不仅仅是中文,而可能生成随机字体的世界上任何一种文字。有了这个模型,人们可以很轻松地解决现在人们面对创造新的字体需要花费大量的人力和物力的这一巨大困难。
2 相关研究
人工神经网络一般简称为神经网络或连接模型。神经网络是一种通过应用类似于人类的大脑神经连接结构对信息进行处理的数学模型。神经网络因为其复杂程度,通过调整网络中无数节点直接连接的关系来处理信息[1]。
卷积神经网络作为深度学习的代表算法之一,是一种具有深度结构,包含卷积计算的前馈神经网络。由于卷积神经网络具有极高的学习能力,可以按其阶层结构对输入的信息进行平移不变的分类,它也被称为“平移不变人工神经网络”。目前卷积神经网络被大量运用在图像和视频领域[3]。
生成式对抗网络是近年来在复杂分布上最具有前景的无监督深度学习模型。模型通过两个主要的模块:判别和生成模型两个模型互相不断地博弈进行学习并且能产生相当好的输出[5]。
截止到今天,机器学习和人工智能已经发展到了较为成熟的阶段,人们也将神经网络运用到了字体生成的领域当中并且取得了很大的成就。比如:从20 世纪50年代起,许多欧美国家为了将数量日渐增长的各种报刊或资料报表等文字材料输入进电脑里进行处理,他们对西文OCR Optical Character Recognition 光学字符识别技术进行了研究用于代替手工键盘的输入。又或者是在70年代以来诸多日本学者对印刷体汉字的识别做出了许多具有代表性的研究,例如东芝在1977年研制的单体印刷汉字识别系统就可以识别2000个汉字;日本武藏野电气研究所研制的汉字识别系统可以识别2300多个汉字字体,在20 世纪80年代初期代表了当时汉字识别的最高水平。随着科技的逐渐发展,以及对神经网络的不断探索,汉字字体识别的混排识别率和稳定性都在近年来得到了很大的提高。但是,汉字识别领域仍存在着很多的问题和困难等待着人们去解决:对汉字识别的正确率,识别速度以及价格问题[2]。截止到目前为止人们都还没有找到一种有效的方法能够同时解决以上的三个问题,导致人们在中文汉字的识别和生成领域的发展遭到了很大的阻碍。对此,我们想到了一个方法:利用卷积神经网络(Convolutional Neural Network)和生成式对抗网络(Generative Adversarial Networks)两者相结合,训练出一个能够稳定的识别和生成中文汉字的模型。这两种神经网络都是目前在人工智能、机器学习领域最具前途并且运用最广的神经网络,而它们两者的结合卷积生成式对抗网络也有很广泛的运用,比如:图像识别,语音生成或者是疾病的分类等等。所以我相信在经过漫长的训练之后,我们也能得到一个较为成熟的模型用于解决目前人们在汉字的识别和生成领域上遇到的难题,并且为人们省下大量的资金和时间。
3 算法介绍
3.1 卷积计算
卷积计算是通过两个不同的函数生成第三个函数的一种数学运算,表征两个函数经过翻转和平移的重叠部分的面积。
设ƒ和是两个可积函数,做积分:
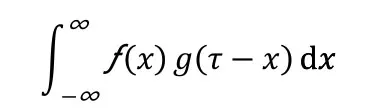
可以证明几乎关于所有实数x,都存在有上述积分。当x的取值不同,这个积分就有不同的函数h(x),称为函数f和g的卷积,记作
h(x)=(f*g)(x)。
在我们的实验里,我们的数据集输入的数据大小是跟MNIST数据集中的输入大小是一样的28*28的图片。当数据进入GAN 生成网络的时候,我们的生成网络中每一层都是一个卷积层,在卷积层中数据经过卷积运算计算出一个值,这就是我们的因变量。
3.2 卷积神经网络基本公式
输入:
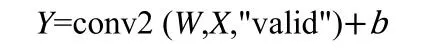
输出:
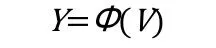
上述公式是卷积神经网络中每一个卷积层的输入和输出公式,W是每一个单独的卷积层都有自己不同的权重矩阵,W是权重,是个卷积核。
3.3 生成式对抗网络基本公式
3.3.1 KL 散度
(1)信息熵
信息熵是用来描述信源所有可能发生情的平均不确定度。
对于信源中的单个符号,它的熵为:
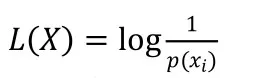
随机变量X可以取值为X={X1,X2,...,Xn},对应的概率为P(X=xi)(i=1,2,...,n),X的熵的定义为:
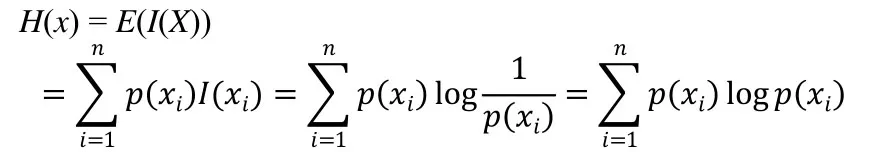
信息熵与事件的可能性数量有关,如果概率均等,存在的可能越多,信息熵越大,信息的不确定性也越大。
(2)相对熵
在一般情况下,P代表数据的真实分布,Q表示数据的近似分布。在一定程度上,熵能用来度量两个随机变量的距离。但因为KL 散度是非对称的,所以它不能真正的代表距离。KL 散度常用于衡量两个概率分布之间的相似度。设P(x)和Q(x)是X取值的两个概率分布,它们的相对熵是:
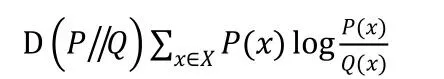
它的积分形式为:
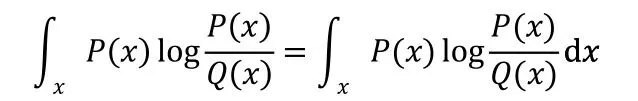
KL 散度是非负数因为对数函数是凸函数。
3.3.2 JS 散度
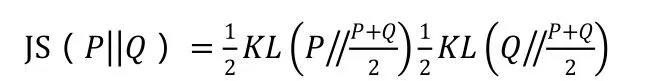
JS 散度是对称的,取值在0-1 之间,度量了两个概率分布的相似度。如果两个分布完全一样,那么JS 散度取最小值0;相反如果两个分布没有交集,那么JS 散度取最大值1[8]。
3.3.3 优化目标
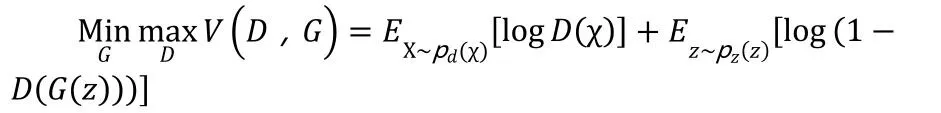
我们可以在求解的过程中把最大和最小分开,现在给定G的情况下把,最大化求解D。然后再把D固定,把,最小化去求解G[8]。
3.3.4 梯度下降和反向传播算法

卷积神经网络的卷积层和池化层都是通过梯度下降和反向传播算法来进行训练的。训练的目标是求出的表达式[7]。
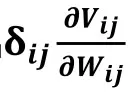
这里就定义了我们的误差方程,随着每一次的更新,权重更加偏近最小值,它的误差也会随着减小。
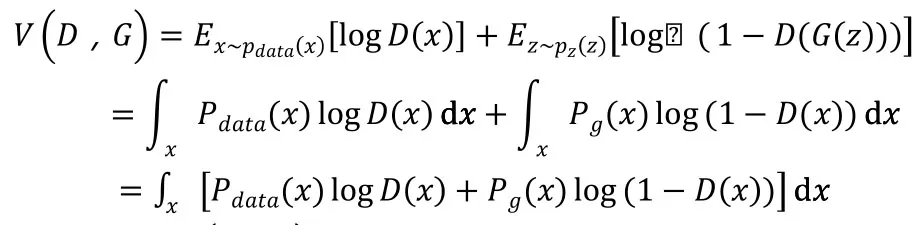
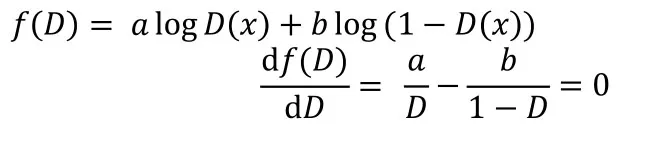
可以求出f(D)的二阶导数小于0,所以:
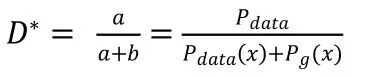
虽然最优的D在我们的实践中是不可计算的,但它的存在让我们可以证明最优的G是存在的,我们在每次训练中只要靠近最优的D即可。
4 实验过程
4.1 数据收集
我们的数据集是来自于网络上各种不同的字体,基于这些字体我们可以随机生成数据集中任何字体的中文汉字。这个数据集一共包含了100 种不一样字体的黑白中文汉字。首先我们把原本的字体大小从64*64 更该成了28*28,并且将他们从黑色调成了白色,然后最后再把数据集放进模型中进行训练(图1)。

图1 数据收集
4.2 实验步骤
首先我们在CNN-MNIST的基础上,将原有的MNIST的数据集更改成我们自己创建的中文汉字数据集。然后我们根据原本代码规定的输入的数据大小将数据集中的输入形状更换成64*64 大小的数据。
然后,我们使用了控制变量法,每一次只修改一个参数,将我们代码的batch size,learning rate,activation function,training epoch,以及网络的结构都修改过很多次,企图去找到效果最好的结果。最后,在经过上百次的调整参数以后,我们发现当我们使用leaky_relu 作为我们的activation function,将learning rate 调整为0.0002,并且将generator和discriminator的训练次数改为1:15,我们得到了嫩的出最好训练结果的一个模型。
4.3 实验结果
在经过超过1000个小时的训练以后,我们得到了一个能生成比较清晰的文字的模型(图2)。

图2 得到了一个能生成比较清晰的文字的模型
(1)Batch size对训练的影响(图3)

图3 Batch size对训练的影响
Batch size的大小决定了在每一个循环中每一组训练的数据数量的大小,生成的文字数量也会随之变化。
Batch size 越大,训练的数据数量就越多,相对的速度也会越快,但是对于电脑内存的占用也比较大。相反,如果Batch size 调小,那么训练的数据就会变少,相对训练的速度就会变慢(表1)。

表1 Batch size对生成数据的影响
(2)Learning Rate对训练的影响(图4)

图4 Learning Rate对训练的影响
在生成式对抗模型中,我们有生成器和判别器这两个模型需要训练,因此也可以调整两个模型的Learning rate。当我们单独把这两个模型中的任意一个模型Learning rate 提高以后,我们可以清楚看到这个模型在每次训练之后的loss都会减小,并且使得另外一个模型的loss 逐渐升高。
(3)网络结构对训练的影响(图5)

图5 网络结构对训练的影响
在我们的实验当中,最初generator和discriminator在一次训练中同样都只训练一次。但是我们发现这样训练出来的结果有很多缺点:generator的loss 很大导致很难生成出清晰的文字,并且图片的颜色也非常模糊。后来我们逐渐增加了每一次训练中generator的训练次数,虽然这会导致训练的时间增加,但随着generator的训练次数逐渐增加到10-15次时,我们发现generator的loss 也在减少,生成出的图片清晰度慢慢增加,并且也能在更早的epoch中生成出清晰可见的文字。
除了这些以外,我们还发现,笔画比较多的汉字要比简单的文字更加难生成出清晰的图片。
(4)其他影响(图6)

图6 其他影响
同时在实验过程中除了上述的几个因素以外我们还发现文字的复杂程度似乎对文字生成的结果也有着一定的影响。当汉字的笔画比较多,比较复杂时,同样的参数设定生成出来的图片要比笔画少的汉字生成出来的结果要差很多。
5 总结和展望
由于这一次的实验只是一次尝试,这次实验还存在着很多的不足:(1)数据集仅仅只有11个中文汉字;
(2)在训练过程中判别器的Loss 早早地就变成了0,但生成器的Loss 还在不断增加,这导致了在训练后期不能进一步生成更清晰的文字图片。
但是只要将来人们能在这个基础上再花一点点时间,继续增大我们的数据集和训练次数,我相信我们的这个模型一定可以解决人们能目前在中文汉字的识别和生成领域所面临的一系列的问题。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
娃娃乐园·综合智能(2020年2期)2020-03-12
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
大学教育(2016年2期)2016-03-08
科技创新导报(2014年11期)2014-11-05
小雪花·成长指南(2014年10期)2014-10-31
移动一族(2009年3期)2009-05-12
