
基于大数据的高校精准资助系统设计
2020-03-05 02:33:54
技术与市场 2020年2期
(西北工业大学电子信息学院,陕西 西安 710129)
0 引言
大学作为我国高等教育的主要场所,是扶贫政策实施的主要“战场”之一。由于各所高校的生源均来自全国各地,在校的贫困生情况也各不相同,传统的资助管理办法越来越难满足目前的精准资助要求,新的管理方法的提出就变得尤为重要。
1 资助方法现状分析
我国的高等教育普及程度越来越高,在校的贫困生数量也越来越多。由于学生众多,需要提交和审核的资料数量庞大,以往传统的提交纸质材料的申请方法以及通过审核人主观判断认定贫困生的方式,使得这项工作存在着材料造假、标准模糊、人为因素影响较大等问题,难以通过较为准确的定量分析方法,对学生的困难程度进行认定。
另一方面,部分家庭真正困难的学生内心存在自卑等情绪,不愿当面申请,从而导致一些资助不准确的现象,使一些真正需要帮助的同学不能得到及时的帮助,而家庭情况不错的同学反而受益,未能实现真正的资助公平。同时,目前的资助方法往往停留在资助金发放完成这一步,忽视了学生在获得资助款项后对资金的使用情况和具体表现,对于贫困学生后续的学习态度和生活情况并不能够及时知晓,无法得知资助金是否发挥了真正的价值。
借助大数据技术就可以避开这些人为因素,通过学生的消费行为等数据建立信息库,对数据进行分析,寻找真正需要资助的贫困生,提高资助的有效性。
2 系统对象分析
该系统的服务对象可分为学生、院级管理员、校级管理员、系统管理员四种。其中,学生的权限为可以查看个人消费信息,申请资助,查看、申请勤工助学岗位;院级管理员对应各学院的管理人员,可以查看本院学生的消费数据,完成困难学生审核,进行贫困认证验证,对于本学院提供的勤工助学岗位进行管理,对本学院学生的后期消费和学习情况进行监管;校级管理员对应学校层次的管理人员,校级管理员可以查看全校学生的消费数据,完成由学院递交的困难学生名单筛选,进行资助认证验证;系统管理员主要进行后台管理和维护系统数据。
3 系统需求分析
系统后台需要完成3大功能:困难学生筛选,勤工助学岗位推荐,贫困学生动态管理。
3.1 困难学生筛选
该功能是本资助系统最为主要,也是最为基本的功能,需要从学生的一卡通消费信息入手,对贫困学生进行筛选。
首先,系统通过一卡通信息中心获得学生的消费数据,读取有用的消费记录,将数据导入数据库,对于得到的消费记录进行分析,以学生为单位,按照月份存储到数据库中。接着进行年级总体资助标准设定和学生个人特征的提取。
3.1.1 年级总体资助标准设定
首先我们根据学生信息,得到全校学生的总人数,并根据学生学号检索学生性别和年级,计算各年级的男生人数和女生人数,将相同年级,相同性别的学生分为一组,统计各组的消费标准。学生信息分类大致分为30日日均消费,三餐平均消费,超市平均消费,运动平均消费,其他平均消费,平均就餐次数等。
3.1.2 学生个人特征
对每个学生的订单以月为单位进行处理,提取出有用的特征进行分析,大致包括总消费额,在校天数,总订单数,30日均消费额,三餐消费,三餐订单窗口,三餐平均消费,超市消费,其他消费等信息,并存入数据表中,作为每个学生的个人消费行为特征表。
3.1.3 筛选算法流程
以计算得到的年级总体资助标准为不同组别的评判标准,通过对学生个人特征的提取,进行资助名单筛选,大致整体流程如图1所示。
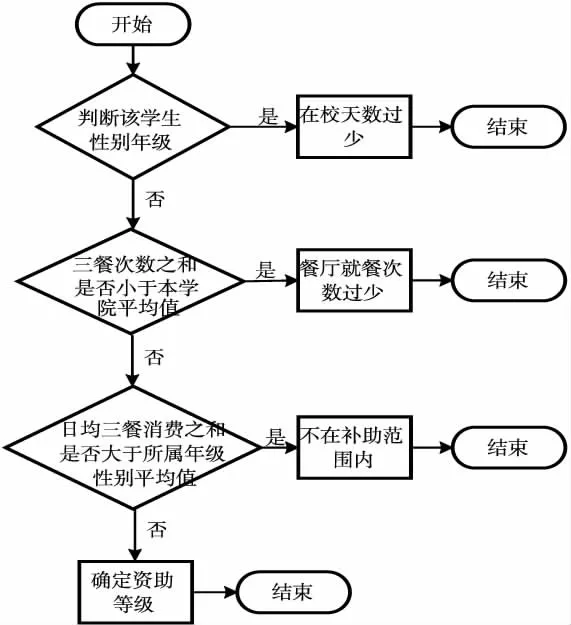
图1 资助名单筛选流程图
3.2 勤工助学岗位推荐
通过大数据,对学生一卡通信息的收集,不仅能得到学生的消费信息,还能得到其学习成绩、图书借阅、打卡记录等数据,从而可以分析得知其学习成绩、学习态度、生活规律、能力状况等信息。
同时通过大数据,可以收集各学院各部门勤工助学岗位的数量、薪资水平、能力要求、工作性质等信息,而通过深度挖掘各部门各岗位的历史用人数据,可以知道各个岗位与学生年级、专业、能力、意愿等之间的联系。将两者加以结合,就可以为每一个有勤工助学意向和需求的同学推荐适合他们的岗位,从而大大提高勤工助学效率。
3.3 贫困学生动态管理
传统的资助方法流程主要为学生申请-学校审核-资助金发放,而对于资助金后期的使用情况以及学生后期的学习态度并不了解,无法对学生进行适当的监督。同时大部分高校的贫困认定周期为一年一次,一旦确定资助名单,该年度的资助工作就会依据该审核结果直接展开,虽然这样有利于维护资助工作的稳定性,但是也会存在制度僵化的问题,存在某些家庭情况已经好转的同学继续享受国家资助,或者一些家庭遇到突发困难的同学无法及时 接受资助的情况,降低了资助的时效性。
基于大数据的精准资助系统,可以以季度甚至月份为单位,对学生的消费信息进行分析,及时发现“隐性”贫困学生,剔除“假性”贫困学生,使得资助更为精准化、及时化。根据学生的学习情况以及学习态度,还可以在一定合理范围内动态地调整资助金额,从另一方面促使学生认真学习,提高自我约束能力。
4 系统性能分析
1)真实性。由于该系统的数据来源均为学生的实际消费信息,而不是仅由学生上交的申请表进行认定,数据十分真实可靠。
2)有效性。根据该系统生成的贫困学生推荐资助名单,不仅仅依赖于学生提交的纸质申请材料,更基于学生的真实消费信息,减少了“暗箱操作”的可能,可以准确分析得到的贫困资助名单,实现精准资助。
3)便捷性。通过该系统,除了根据学生的消费信息自动生成推荐资助名单,学生也可以在网上进行资料的提交,不再需要特意前往固定地点办理,也减轻了老师审阅纸质材料的任务,同时未来该系统还可以与客户端相结合,实现实时实地办事。
4)隐私性。由于大数据的有效性,贫困资助名单的生成完全可以略去班级评议、学校公示等环节,贫困学生的资助信息仅学校老师和被资助者本人知晓,在发放资助经费时也可以悄然进行,避免了大张旗鼓进行资助活动给被资助的同学带来的困扰,极大程度上保护了被资助学生的隐私。
5 结语
本文设计的精准资助系统,基于数据库,实现了困难学生筛选,勤工助学岗位推荐,贫困学生动态管理三大功能。由于资助推荐名单的产生是基于对学生真实消费数据的分析,所以能实现精确地资助,同时减少了纸质申请材料的提交,使得贫困资助认证这一过程变得十分高效和便捷。后期的持续性数据更新,也使得资助工作更具有准确性和时效性。
猜你喜欢
大学(2021年2期)2021-06-11 01:13:28
今日农业(2020年24期)2020-12-15 16:16:00
电子产品可靠性与环境试验(2016年6期)2016-05-17 03:52:12
雷锋(2015年9期)2015-12-14 06:29:13
中国火炬(2015年2期)2015-07-25 10:45:24
中国火炬(2014年9期)2014-07-25 10:23:07
中国火炬(2013年11期)2013-07-25 09:50:23
中国火炬(2012年5期)2012-07-25 10:44:08
中国火炬(2012年10期)2012-07-25 10:10:40
中国火炬(2012年2期)2012-07-24 14:17:46
