
大数据技术综述
2020-03-05 07:24:08韩浦霞
天津职业院校联合学报 2020年12期
韩浦霞
(天津商务职业学院,天津 300350)
一、大数据概念
顾名思义,大数据技术的根本是对大量信息的处理。企业往往会将多种数据集中起来进行分析处理,数量级一般在PB规模左右。数据量级不仅指数据体量,也包括数据源个数和数据的种类。大数据特性往往从数据量、速度、类型、价值密度四个方面进行概括。
(一) 数据量巨大
对于当前各领域的数据集合,TB、PB的数量级单位已经不能满足,目前已经开始使用EB和ZB进行衡量。例如百度搜索2020年第26周的日均IP访问量为5833.93万,其VP的日均访问量为25653.98万。
(二) 数据速度快
一般指处理速度与产生速度。大数据往往和人工智能、物联网等行业结合应用,对数据的实时响应要求高。大数据的处理效率又称为“1秒定律”,即可以秒级时间内获取分析结果。
(三) 数据类型繁多
全球IT技术的不断发展催生出各种交互产业,各种类型的数据随之产生,区别于传统IT时期的结构化数据,现在整个大数据产业中充满了半结构化和非结构化的数据。
(四) 数据价值密度低
庞大的数据量,必定存在大量的非有效信息,因此数据的价值密度是比较低的。例如,城联网系统中的监控系统,每日的视频存储量惊人,但实际的有效信息仅为其中的数百兆。
大数据技术使得人们的思维方式发生了颠覆性改变,科研人员不在局限于小数据量级的精确性指标,更多的开始追求大数据量级下的普遍性规律。对于较复杂的事件,通过归纳与演绎的方式进行建模与推演,获得大概率的事件结果。
二、大数据采集技术
大数据技术包括数据采集、预处理、存储、可视化等。数据采集是众多流程环节中的第一步,重要程度不言而喻。大数据的采集一般是通过RFID、互联网交互、传感器等获取海量的数据,大数据采集方法与传统数据采集差异较大。
大数据采集面临的首要压力即为数据的并发性,同一时刻可能会产生数以亿计的数据信息,因此需要在采集端部署多个数据库进行采集,并且还需考虑各个数据库之间的负载均衡。基于以上特性,大数据采集方式主要分两种:MapReduce分布式并行处理模式和基于内存的流处理模式。
MapReduce分布式并行处理模式的基本思想就是分而治之。假如我们想知道一幅扑克的黑桃数量,分布式模式是将所有扑克分发给所有玩家,让每个玩家统计各自的黑桃数量,然后汇总数据,得出最终的结论。显然,该模式通过拆分的思想,可以迅速得到结果。MapReduce模型处理流程首先是针对数据集,将不具有依赖关系的数据进行并行处理,然后利用Map函数与Reduce函数实现高层的并行抽象模型。最后将分而治之的思想再提升至架构层面,统一架构方式为研发人员隐藏了大部分系统层面的处理细节。下图1为MapReduce模式的原理图。
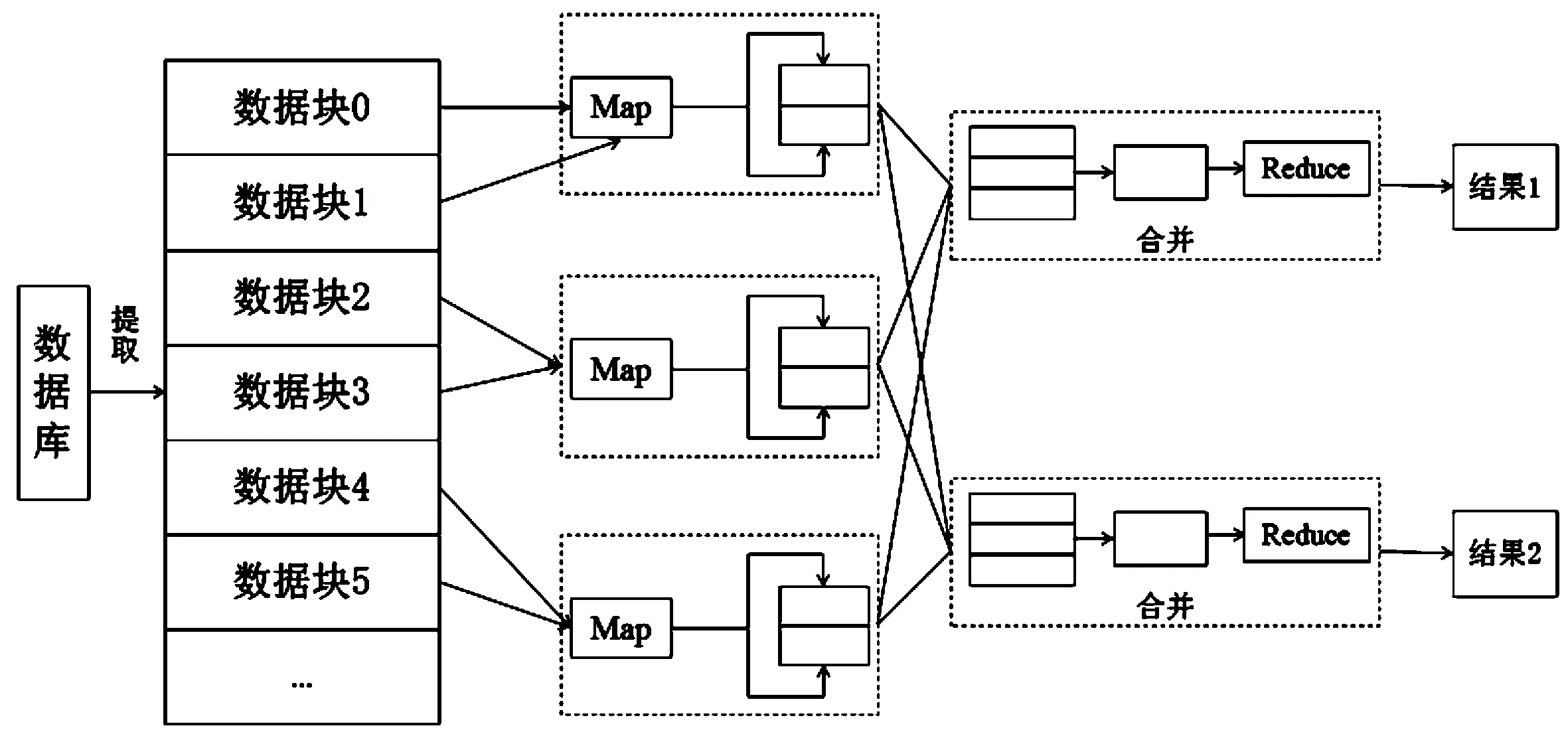
图1 基于MapReduce的并行计算模型
基于内存的流处理模式与批处理模式是截然不同的,它不需要针对整个数据集进行操作,而是对随时输入系统的数据进行计算。因此流处理模式的数据集是无止境的,除非明确停止计算。流处理模式单位时间内有且只可处理一条或很少量的数据,数据流经过此处就会被筛选过滤,获取有价值的数据,然后将其丢弃。伴随着近几年大数据技术迅猛发展,人们开始更多的关注数据处理的时效性,处理模式开始慢慢向流处理模式转变,例如阿里等电商的“双十一”,会要求以秒为计量单位的输出结果。
三、大数据预处理
随着数据量的不断增大,每秒产生的数据中绝大部分可能是无效信息,包括噪声数据、冲突数据和残缺数据等,如果不加区分而将这类数据也进行分析计算的话,势必会影响最终结果的准确性,因此为保证数据结果具有有效价值,需对收集到的数据集进行预处理。
大数据预处理包括数据的清洗、集成、转换、削减。这些处理环节可以有效检测出噪声数据、无效数据等,是大数据分析结果质量的保证。
(一) 数据清洗
数据清洗是针对残缺数据、噪声数据和不一致数据的处理。针对残缺数据常用的处理方法有以下几种:丢弃该遗漏属性值数据;利用默认值填补遗漏属性值;利用数据均值填补遗漏属性值;利用回归分析填补遗漏属性值;利用同类别数据集属性值填补该遗漏属性值。噪声数据一般是数据集出现随机属性值,常用的降噪方式有:对噪声点数据的周边数据进行平滑;通过聚类分析方法定位噪声点;寻找数据集的拟合函数进行回归。不一致数据处理往往是数据记录错误问题或者属性取名规范问题,可以通过人工进行修改。
(二) 数据集成
数据集成是将对各数据源的数据进行合并统一形成新的数据集,提升数据的完整性与可用性。目前数据集成面临三个问题:集成模式的问题;数据冗余问题;数据值存在检测冲突。
(三) 数据转换
数据转换是将数据进行转换或归并,形成适合数据处理的模式。常见的数据转换处理方法包括:平滑处理;泛化处理;合计操作;归一化处理与重构属性。转换后的数据有效的保证了数据的统一性。
(四) 数据削减
数据削减是指在保证数据集完整性的前提下对数据集的精简,进而提升数据分析的效率。常用削减方法有维度削减、数据立方合计、数据块削减、数据压缩、离散化等。
四、大数据存储技术
面对海量的数据资源,大数据存储就成了十分关键的问题。目前大数据领域主流方式为分布式架构,在分布式存储中,将大数据存储任务切分为小块,分配到集群中各机器去获取支持。常用的大数据存储技术包括:分布式文件系统HDFS和分布式存储系统HBase。
(一)HDFS
HDFS是分布式文件系统,分布于集群机器上,利用副本文件进行容错,确保可靠性。HDFS的设计原则是十分明确的,一般适用于存储非常大的文件,采用流式模式进行访问。
HDFS系统的主要组件有:NameNode、Block和Rack。其中NameNode是系统的主站,它对系统里的文件与目录文件系统树以及元数据进行管理,执行文件系统的操作。DataNode作为系统的从机,所有机器均会分布于各自的集群中,然后进行存储,并且根据客户端的读写请求,提供相应的服务。主节点NameNode会管理多个工作节点DataNode。
HDFS的写过程流程如下:主节点确认客户端请求信息,并记录文件名称和存储该文件的工作节点集合。然后将这些信息存放在文件分配表中。如下图2为客户端向主节点发送test.log文件写请求的响应流程图。
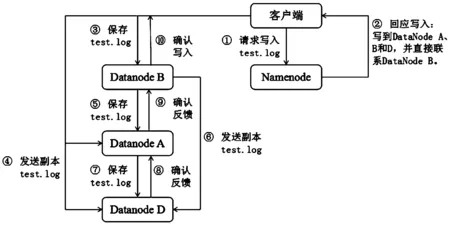
图2 HDFS写过程流程图
对于分布式文件系统而言,最重要的就是数据的一致性,当HDFS系统中,所有需要保存数据的工作节点均拥有副本文件,才会认为该文件的写操作完成。那么数据一致性就会确保客户端无论从任何工作节点进行读取,所得到的数据是一致的。
HDFS的读过程流程如下图3所示。其中数据块信息包括文件副本工作节点的IP地址、工作节点在本地硬盘查找数据块所需要的数据块ID。
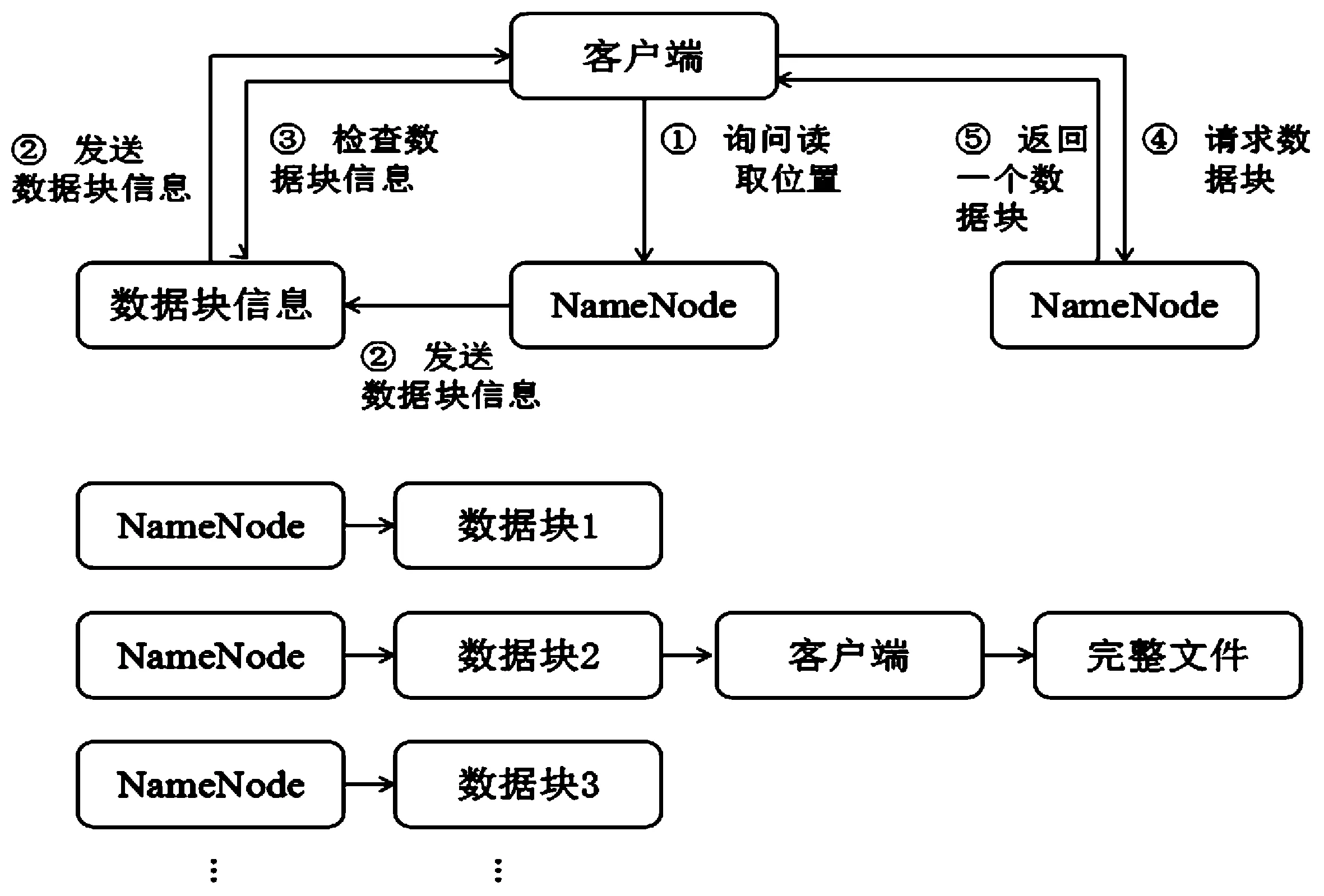
图3 HDFS读过程流程图
HDFS是目前被认为Hadoop系统兼容最好的文件系统,基于该系统的开源性,目前已经被广泛商用。
(二)HBase
HBase是面向列的非关系型分布式存储系统,可进行实时读写,并随机对大规模数据集进行访问,具有高可靠性与高伸缩性。
HBase具有以下特性:强读写一致性;自动的故障转移;HDFS集成;丰富的“简洁,高效”API;具有块缓存、布隆过滤器,可高效的列查询优化;提供了内置的web界面来操作,还可以监控JMX指标。
常见的HBase应用分三类:存储业务数据、存储日志数据和存储业务附件。其中存储业务数据包括用户的操作信息、设备访问信息等。存储日志数据包括登录日志、邮件发送记录、访问日志等。存储业务附件包括所包含的图像、视频和文档等附件信息。
HBase系统主要包括4个关键节点:Zookeeper、HDFS、RegionServer和Master。Zookeeper主要进行配置维护、分布式同步、组服务等,它的主要功能就是向用户提供简易、安全、高可用的封装系统。HDFS是HBase运行过程中的底层文件系统。RegionServer负责响应用户读写请求。Master是主服务器的实现,它负责实时监视RegionServer实例,也可作为元数据更改的接口,可以控制该节点的故障转移和Region切分。下图4为HBase系统架构图。

图4 HBase架构体系关系图
HBase应用于大数据高并发情况和数据的随机读写,例如淘宝指数就是利用该系统查询历史的交易记录。
五、大数据处理系统
在一定时间内,人类或者机器是无法通过常规数据软件对大规模数据进行获取、存储、管理以及处理的,需要专业的数据操作系统对其进行操作。大数据处理系统分为:批处理模式和流式处理模式。当前主流的批处理系统是分布式计算架构Hadoop,该系统可对完整的大数据集合进行分析,但无法获得实时数据,数据的迟滞高。流处理大数据系统代表:Spark Streaming、Storm,可对实时数据实现高效分析处理。
(一)分布式计算架构Hadoop
Hadoop包括分布式文件系统HDFS、任务调配YARN、大数据并行运算框架MapReduce。HDFS存储性与百度云、阿里云文件存储系统类似,同时它还涉及分布式计算等。HDFS作为分布式文件系统,实现数据的存储。YARN是该架构的资源管理器,为上层应用提供统一的资源管理与调度。MapReduce是针对大数据实现并行计算的编程模型,通过指定某映射函数,将一组键值对映射为新的键值对,然后指定并发函数,确保所有映射的键值对共享相同的键组。
(二)Spark Streaming
Spark Streaming框架具有实时计算、高吞吐量和容错机制的特性,可多元获取数据,接受HDFS等数据源的数据,经过处理后存储到相应系统。该框架的运行原理是:按照某一时间间隔,将实时数据进行划分,然后分批交由Spark engine引擎进行处理,获得结果。每批数据都将在spark内核对应一个弹性分布式数据集RDD,所有批次的RDD即构成离散流Dstream。
(三)Storm
Storm是分布式实时处理数据框架,具备不易丢失数据、低延迟、易扩展和高可用等特性,具备简单的编程模型,易于开发。Storm框架属于主从架构模式,Nimbus作为主节点进行资源的分配,ZooKeeper作为中间过度单元存放调度消息,supervisor作为从节点接收任务,产生对worker进程的响应。
六、大数据应用
随着我国大数据相关政策的普及,越来越多的行业开始考虑结合大数据技术实现本行业的创新与升级。目前我国大数据技术应用度较高的行业包括:电信、金融、政务、交通与医疗。
电信行业毋庸置疑是我国最大的数据信息源,中国联通利用大数据分析技术,对全国的移动用户进行画像,为客户的特性化服务以及整个市场运营提供了支持。金融行业比较典型的应用实例就是阿里小贷业务,是阿里巴巴、淘宝网以及支付宝三个平台合作提供交易数据,然后对平台提供用户近100天的数据进行分析,实时准确的把握用户的资金情况。政务领域继我国提出“大数据成为提升政府治理能力的新途径”论点后,开启政务治理新模式。例如身份证系统、网上办事窗口等,实实在在做到了便民服务。交通领域的数据资源丰富度高,实时性强。例如各交通运行的监控数据,高速公路、干线公路等的气象监测数据,城市公共交通、出租车等的定位数据,以及交通道路的费用数据。医疗领域依靠各个医疗机构每年都会产生PB数量级的数据信息,包括各种门诊就诊数据、住院数据、用药数据、手术数据、医保数据等,因此医疗数据在种类以及体量方面均满足大数据的要求。
2020年初国内爆发的新冠肺炎,大数据技术在疫情阻击战中得到了充分的应用,依据各省市的疫情情况,通过“大数据+网格化”方式进行判断分析,逐步指导各地因时因地有序复工复产。专家们依托大数据平台对感染患者分布、接触者追踪以及疫苗研发等进行实时有效的分析。研发人员广泛收集地图信息、遥感数据、卫健委发布的疫情数据、舆情数据、网页抓取的数据、共享单车轨迹等数据,绘制疫情地图,为全国各地的人们提供了实时准确的疫情信息。
七、结语
依托于大数据的背景,人们可以分析出数据背后的意义,获得更深层次的理解,服务于人类,形成新的技术变革之力。数据作为世界各国未来竞争的资源,其价值度不亚于石油、贵金属。大数据行业也必将成为未来国家之间竞争的领域之一。未来几年将会是我国大数据行业发展的重要时期,结合各行业的发展规律与特征,充分利用大数据技术有利于行业整体的品质提升与转型。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
国际眼科杂志(2021年9期)2021-09-15 03:24:42
装备制造技术(2020年2期)2020-12-14 03:09:16
河南科技学院学报(自然科学版)(2020年2期)2020-05-22 05:37:22
小型微型计算机系统(2020年5期)2020-05-14 07:09:24
能源(2017年7期)2018-01-19 05:05:03
能源(2017年10期)2017-12-20 05:54:07
制导与引信(2017年3期)2017-11-02 05:16:56
能源(2017年5期)2017-07-06 09:25:54
中国卫生(2015年12期)2015-11-10 05:13:34
