
基于去噪自编码器的微博传播流行度演化研究
2020-03-05 03:29:50段淑凤朱立谷
中国传媒大学学报(自然科学版) 2020年1期
段淑凤,朱立谷
(1.中国传媒大学 计算机与网络空间安全学院,北京 100024; 2.石家庄铁道大学 信息科学与技术学院,石家庄 050043)
1 研究背景
随着互联网的兴起和相关软硬件的高速发展,尤其智能手机的出现,全球的网民人数日益增多,而相关技术在近二十年也得到了快速提高,尤其Web2.0时代的到来,社交媒体快速兴起,信息传播开始步入自媒体时代,因此网络传播学作为传播学的一个分支应运而生。由于网络用户的结构复杂,并出于不同的传播目的,在传播过程中会产生大量的人为噪音,造成信息混乱。为达到稳定社会氛围,形成良性的传播影响的目的,从新闻的传播态势中析取实际的传播效果,并分析发现规律,始终是社交媒体网络传播研究的热点问题,而本研究的目标是基于微博事件的流行度演化过程挖掘网络传播过程的基本规律。
传播过程的定性分析主要包括宏观和微观两个角度。对整个传播过程宏观的分析,即单纯考虑传播结果,根据某个指标将传播过程量化,建立传播曲线,通过数学模型寻找指标间的规律,用于传播趋势的预测。比如,文献[1]中运用马尔可夫分析方法建立网络舆情热度趋势模型,即根据之前的流行度值预测当前的传播阶段,但是这种方法泛化性比较弱。而微观分析,则从动力学角度,基于网络特征,从成因角度建立数学模型,拟合最终的传播结果。传染病SIR模型[2]是最广泛应用的模型,其核心思想是S 定义为易感染节点,I定义为传染节点,R定义为免疫节点,节点之间相互转化,通过概率规则进行演化仿真。在此基础上一些改进模型,如SEIR[3]、SIRS[4]和SEIRS[5]等,通过融入潜在节点E或是改变节点感染流程进而获得改良。这些模型为理想化模型,网络结构和内容固定,并不适用于实际分析。此外,文献[6]中将Galton-Waston过程模型引入流行度分析中,该模型是一种分支随机过程,原用于模拟家族姓氏的演化和灭绝。而随着机器学习技术研究的流行,文献[7]中提出了一个多元线性回归模型,把流行度分成N种类别,根据用户活跃度及传播加速度进行预测。后两种方法建立了微观特征与宏观结果的联系,但是对数据的清洁度有很高的要求。
目前我们在分析过程中利用爬虫所获取到的数据,包含多种噪音成分,因此在进行实际分析时拟合和分类效果比较差,人工分析虽然能够提高准确度,但是耗费大量的人力物力。因此,本研究提出将去噪自编码器引入传播流行度分析,可直接使用粗糙数据集挖掘共性传播特征,感知异常节点,削减处理和分析工作量。
2 相关概念及原理
2.1 流行度演化概念
流行度是给定某则网络信息i和某时刻t,该信息的流行度yi(t)定义为人们在时刻t对其的关注程度,多数工作中,研究者通常将流行度量化为人们在某时刻采取在网络信息上的积极的网络行为(观看、点赞、转发、评论)的次数[8]。在本研究中,流行度的主要观测指标则是在该时刻人们针对该事件进行讨论所发布的相关微博的个数。
流行度演化则是某个新闻在微博上传播时,基于时间维度的流行度数值序列。流行度的演化过程反映了社会热点事件在网络中的传播态势发展,可以得知网络群体对该事件的关注程度的变化经过,对传播过程中趋势和规律的分析起着非常重要作用。
2.2 去噪自编码器原理
随着计算机的运算能力和并行处理能力的增强,人工神经网络模型由于其高度的并行性,良好的容错和学习能力,以及联想记忆功能等优点,已经成为当前的研究热门。自编码器[9]是神经网络的一种,同样是通过正向传播获取计算结果数据,用反向传播优化网络参数,只不过与用于一般用于识别和分类的神经网络不同的时,它是一种无监督的神经网络,分成编码和解码两个部分,编码部分即编码器用于从输入数据中提取特征,解码部分即解码器则根据特征还原输入数据,整个网络的输入和输出在数据结构上是一致的,并且输出和输入应该非常近似,网络参数的优化方向即使输出和输入的差值最小,其结构如图1所示。

图1 自编码器结构图
去噪自编码器是在自编码器的基础上,为了防止直接将输入转换成输出所提出的一种新型编码器,主要方法是在输入部分增加一些噪声,最终训练结果使输出更接近与原始输入。即去噪自编码器可以过滤噪声获得更为基础的特征表示,因此利用这一特性,本实验直接将包含噪声成分的流行度演化数据作为输入来获取真正的传播特征,并获取真实的传播效果。
3 数据集与算法模型
3.1 数据集说明
(1)训练集
训练集为利用爬虫技术在微博中采集的1446条新闻发帖数据,发帖时间从2015年1月2日到2017年7月12日之间,共计923天。其中包含娱乐、财经、政治、科技等多种事件类型,最少新闻发帖总量为2篇,最多总量为69528篇,每个新闻都是以小时为单位进行发帖数量的统计,在事件基本平息后进行采集。为了从中了解到基本的网络传播特征,分别对不同时间段的平均发帖量和时间的持续时间进行了统计,其结果如图2所示。
上图为发帖量的统计结果,横向坐标为小时,纵向为微博数目,不同颜色的曲线代表不同的周目。如图所示,在每周的不同日子里,随时间变化的数目均值曲线基本相似,只是具体数值会有区别,而在同一天变化则比较剧烈。右图为新闻持续时间统计,根据图可知,最短的持续时间为1天,最长的持续时间是142天,持续时间新闻数最多的是6天,在2-10天内完成的事件占74%,3-7天之内完成的事件占57%。


图2 基础传播特征统计
(2)测试集
发生在2017年1月1日到2017年9月16日之间的78条娱乐新闻相关详情数据,包含发帖人和发帖时间以及发帖内容。同样是在事件平息后进行采集,与训练集有33条新闻重合。最少新闻发帖数为12篇,最多为13114篇。最短持续时间为2天,最长为79天。
3.2 算法模型
(1)数据预处理
A.不同时值流行度指标标准化
不同时间微博在线用户数不同,导致微博发帖总量会产生很大的变化,而流行度应该反映出当前信息的影响能力,使事件的不同时间段待分析流行度值应该具有相同的意义,即表示在同等用户条件下所产生的微博数量。因此,为了进行一致性分析,以图2在对不同时间特点的发帖量统计结果为基准,最终分析的流行度是各自时刻的相对值。
B.横纵坐标归一化
为了方便对其进行统一训练,简化分析过程,需要将所有新闻在时间维度和指标维度上进行归一化。在指标维度上进行同步缩放,保持最大值为1。而为保证波形的完整形,对于持续时间较短的事件,用0进行填充,而对于持续事件较长的波形,则对相邻数据进行均值计算的方法获取实际波形。同时为了方便对比,并尽可能的保留细节信息,根据图2的持续时间统计结果,实验分别选择7天和10天进行时间方向上的归一化。
(2)去噪自编码器
本算法的去噪自编码器含有三个隐含层,除了必须的内部表示层之外,编码器和解码器均为包含一个隐含层的全连接神经网络,即在图1的基础上,在中间层的上下两侧各增加了一个隐含层。内部表示层的节点数目在本实验中设置为72,另外两个隐含层的节点个数设置为100,每一批的样本个数batch_size设置为64,随机从训练数据集中无重复选择,而训练轮数epoch设置为1000。参数利用Xavier[10]进行初始化,激活函数设置为softplus函数,损失函数选择平方误差,优化器是Adam,学习速率为0.001。
4 实验结果及分析
4.1 训练集噪声结果分析
训练损失即为噪声,计算噪声率,即噪音和信号的比值,根据结果分成了最低(<0.01)、低(<0.05)、高(<0.1)、最高(>0.1)四种类型,将实验结果根据分解效果、年份、持续时间等条件分别统计对应的新闻比例之后,再根据不同时间维度的归一化值进行统一对比分析,7天为高归一化程度,10天为低归一化程度。
(1)时间维度归一化对噪声提取影响分析
表1中的数据是在当前列所对应的归一化程度下,所对应的行代表的噪音率的新闻数量占所有数据集中新闻数量的百分比。从表中我们可以发现,随着归一化程度的降低,噪声率低的新闻数量开始增加,因为在时间维度高归一化程度的条件下,更多的新闻是通过降采样的方式获得训练数据,而降采样可以降低随机噪声。
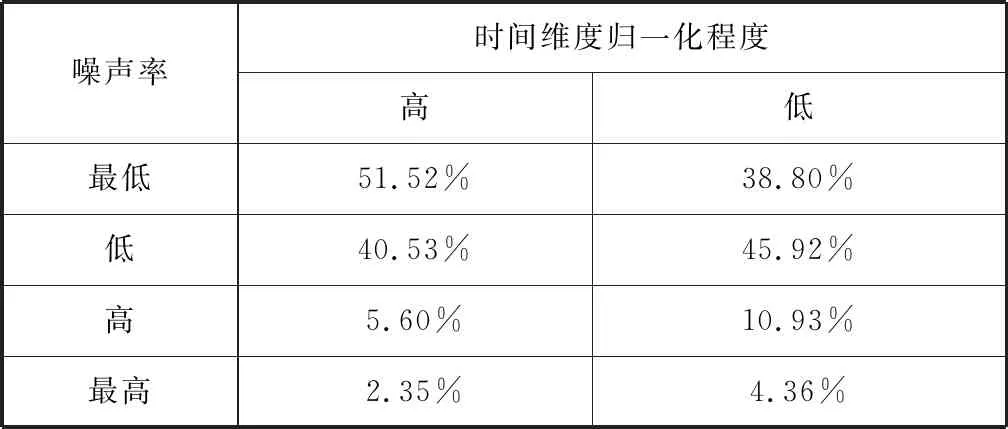
表1 时间维度归一化程度对噪声影响对比
(2)噪声在不同年份的对比分析
表2是在表1的基础上重新根据发生年份进行的细化,即显示的不再是在全部新闻中的比率,而是在当前行对应的年份中当前噪声率的新闻数的占比,用于观察不同年份的噪音情况。我们可以看到在同一归一化程度下不同年份的新闻,噪音率较低的占比有所下降,而其他噪声率都有所上升,这与我们实际的情况一致,越来越多的用户开始使用人为噪音来增加新闻的流行度。

表2 不同年份的噪声对比
(3)噪声与持续时间的关系分析
表3则是根据持续时间的不同而进行的分类统计,数值表示在不同的归一化程度下,不同持续时间的新闻具有对应行的噪声率的比值。从中可以看出,越长持续时间的新闻噪声率高的占比越多,越短持续时间的新闻噪声率低的占比越多,同样也符合实际的新闻传播情况。
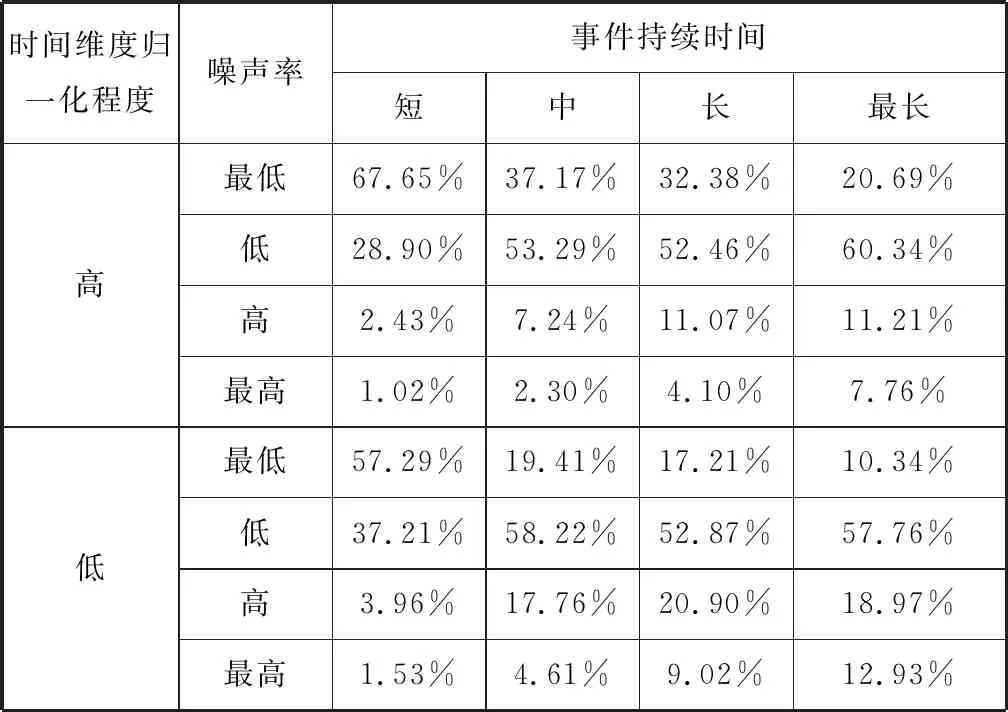
表3 噪声与新闻持续时间的关系对比
4.2 测试集噪声结果分析
(1)综合分析
以表2中2017年的全类新闻不同噪声率的占比作为基准,与测试集的噪声率占比情况做对比,从而综合分析娱乐类新闻的噪声特点。通过表4的对比结果可知,娱乐新闻的噪音率明显高于基准,说明娱乐新闻中人为推动因素较多。而且,时间维度归一化程度越低,具有最高噪音率的娱乐新闻增多越明显。
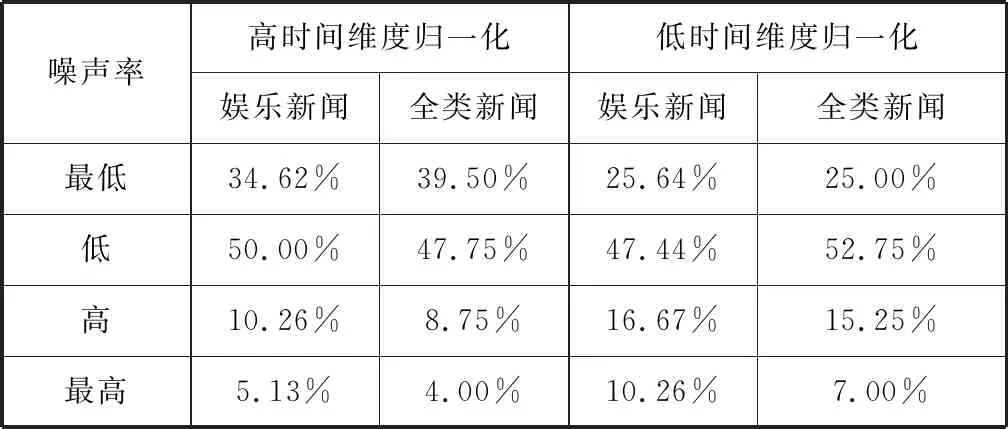
表4 测试集与训练集噪声率对比
(2)应用分析
将利用自编码器所生成去噪波形与原始波形进行对比,其中蓝色波形为预处理的原始训练波形,黄色波形为生成波形。分别在低噪声波形新闻和高噪声波形新闻中选择一个实例进行分析,每个实例会展示两个图像,左图将显示高时间维度归一化结果,右图显示低时间维度归一化结果,并对高噪声波形中差异明显位置进行噪声产生原因分析。
A.低噪声新闻波形
图3为林肯公园乐队主唱自杀相关微博流行度波形,该事件为测试集新增新闻,可以发现生成波形与原始波形基本匹配,包括相邻的双峰值。因此推断出该新闻的噪声较少,基本符合正常的新闻网络传播特征,人为有意介入的概率比较低。
B.高噪声新闻波形
图4为第36届香港电影金像奖颁奖典礼的相关新闻流行度波形,该事件为测试集与训练集重合新闻。从中可以发现中期的峰值波形匹配差异比较显著,根据时间维度的偏移值确定高峰值时间应该为2017年4月9日23时到2017年4月10日01时之间,通过查找细节微博数据并结合实际情况,确定因该时刻典礼结束,各公众号频发新闻而引发。

图3 低噪声新闻生成波形与原始波形对比图

图4 高噪声新闻生成波形与原始波形对比图
5 总结
本研究采用的去噪自编码器来分析流行度演化波形,在对数据进行标准化和归一化后,首先利用包含全类新闻的训练集数据优化网络参数,挖掘传播的基础特征,并通过对其此数据集的噪声结果分析,发现与实际传播特点相符,进而验证了该模型的泛化性和可行性。之后利用娱乐新闻的测试集数据,对当前模型进行应用测试,即综合分析挖掘出娱乐新闻的噪音特点,还利用生成结果,针对具体新闻对高异常噪音分析爆发原因,从而验证了该模型的可用性。只是当前自编码模型比较简单,并没有考虑过拟合问题,后续研究需要进一步改进的地方是,对神经网络结构进行调整,尤其考虑如何体现时间先后的流行度关联。
猜你喜欢
中国特种设备安全(2021年9期)2021-03-02 05:40:46
测控技术(2018年2期)2018-12-09 09:00:46
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
电子设计工程(2017年20期)2017-02-10 03:39:29
通信电源技术(2016年3期)2016-03-26 07:13:14
电子器件(2015年5期)2015-12-29 08:42:24
防灾减灾学报(2015年3期)2015-12-16 16:15:40
第二课堂(课外活动版)(2015年5期)2015-10-21 19:37:04
电测与仪表(2015年12期)2015-04-09 11:44:40
电测与仪表(2014年13期)2014-04-04 12:04:18
