
资源不均衡Spark环境任务调度优化算法研究*
2020-03-04 08:33胡亚红毛家发
计算机工程与科学 2020年2期
胡亚红,盛 夏,毛家发
(1.浙江工业大学计算机学院,浙江 杭州 310023;2.宁波银行股份有限公司,浙江 宁波 315100)
1 引言
随着各大数据中心、超算中心和互联网公司等机构设备的更新换代和高性能部件(如GPU等)的引入,集群中各节点逐步变得异构[1,2],因而各节点的综合计算能力出现较大的差异,整个集群处于资源不均衡的状态。这里的异构性是指计算节点在CPU、内存和IO等方面具有不同的性能而导致其自身的处理能力出现差异。由于集群中各节点的能力不同,相同任务分配到不同节点将对节点负载产生不同的影响。Spark默认的任务调度算法基于集群节点同构的理想化设计,并未考虑集群异构性及节点资源利用和负载变化的情况,因此无法满足资源异构模式下系统的效率和负载平衡等要求。
目前国内外学者已经提出了很多并行框架下的任务调度算法。文献[3]指出分布式集群通常存在负载均衡问题,并对Yarn的公平调度算法进行了改进。文献[4]指出MapReduce进行任务调度时未考虑Map和Reduce任务的差异以及集群的异构性,提出了一种针对Hadoop平台上截止时间约束的扩展MapReduce任务调度算法。文献[5]为了最大限度地减少计算机的资源争用,提出了可以感知节点资源的任务调度策略,即控制节点通过收集分析工作节点资源消耗情况来进行调度。考虑并行和分布式异构计算系统,文献[6]提出了基于启发式的任务调度算法,以进行任务优先级的确定和处理器的选择。文献[7]提出一种资源感知的Hadoop调度程序,它考虑了计算资源的异构性和云计算环境中任务分配的配置费用。文献[8]提出的算法可动态计算任务进度并自动适应连续变化的环境。提交作业时,该算法会将作业拆分为许多细粒度的Map和Reduce任务,然后将它们分配给合适的节点。文献[9]提出的算法通过滑动窗口技术动态监控系统中执行的作业数量,自适应地管理系统负载平衡,并为不同类型的作业划分差异化服务的优先级,使Hadoop原始的算法得到了改进。文献[10]针对Hadoop提出了一种新的基于数据局部性的调度器,它根据节点的处理能力分配需要处理的数据块。文献[11]根据异构Hadoop集群中各个计算节点的负载动态变化和不同任务的节点性能差异,提出了一种基于动态工作负载调整的自适应任务调度策略。在Spark方面,文献[12]提出了一种新的调度策略以优化Spark在异构集群中的表现。新策略引入了分层调度的思想,使Spark在调度时能综合考虑任务复杂度、节点性能及节点资源使用情况等因素,实现了更加高效公平的任务调度算法。文献[13]中,作者认为Spark没有考虑到异构环境下节点的性能差异,因此提出了一种自适应任务调度算法,可以通过检测节点负载和资源利用率来提高集群的运行性能。但是,该算法考虑资源影响因素不够全面,权值过于依赖设定的阈值,有一定的主观性。还有一些基于人工智能及生物信息的任务调度优化算法,如蚁群算法ACO(Ant Colony Optimization)[14,15]、遗传算法[16 - 18]等,这些算法能够进行多目标优化,优化效果比较显著。但是,这些算法的原理比较复杂,其实现计算量较大、非常耗时[19]。
现阶段的研究大多数是针对Hadoop进行优化,Spark异构环境优化方面的研究略有不足。因此,本文通过分析每个节点的计算能力,对Spark的底层调度算法进行优化,充分考虑节点的异构性、资源利用和负载等情况,以期提高Spark系统的运行效率,缩短任务整体运行时间。
本文的组织结构如下:第2节建立了节点性能评价体系;第3节介绍了节点优先级调整算法;第4节给出了基于节点优先级的Spark动态自适应调度算法;第5节对提出的算法进行了实验验证,并对实验结果加以分析;第6节对本文加以总结,并指出下一步的工作方向。
2 节点性能评价体系的建立
有效的节点性能评价是进行任务调度的基础。本文采用节点优先级反映节点能力的大小,优先级由节点的静态性能指标和动态性能指标计算得到。
2.1 节点优先级的定义
定义1节点优先级P:用于表示节点的计算能力,值越大代表节点计算能力越强,被选中执行任务的概率越大。第i个节点的优先级为Priorityi,简写为Pi。
定义2节点性能指标:用于描述节点性能的1组指标,包括静态性能指标S和动态性能指标D。静态性能指标是与任务执行状态无关的指标,其值由多个静态因素(如CPU核数、内存大小等)决定。动态性能指标则是指会随着任务执行状态而变化的指标,其值由多个动态因素(CPU剩余率、任务队列长度等)决定。第i个节点的静动态性能指标分别为Statici和Dynamici,简写为Si和Di。
节点优先级P与静态性能指标S和动态性能指标D的关系如式(1)所示,静态性能指标的计算如式(2)所示,动态性能指标的计算如式(3)所示。
Pi=αDi+βSi
(1)
Si=n1s1(i)+n2s2(i)+…+nksk(i)
(2)
Di=m1d1(i)+m2d2(i)+…+mjdj(i)
(3)

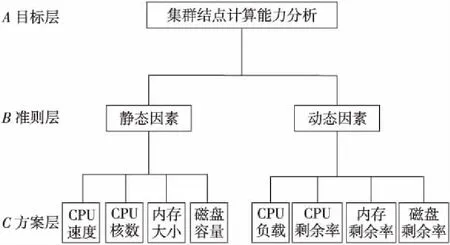
Figure 1 Node performance evaluation index system图1 结点性能评价指标体系
影响节点性能的静态和动态因素很多。经过分析,静态因素考虑CPU速度、CPU核数、内存大小以及磁盘容量等;动态因素考虑CPU负载、CPU剩余率、内存剩余率和磁盘剩余率等。
2.2 节点性能评价指标体系
节点性能评价指标体系如图1所示。
2.3 优先级因素的采集
静态因素可由机器已有配置得到,但是动态因素是根据任务运行状态变化的,因此需要实时关注集群资源利用情况以获取相关信息。本文采用Ganglia[20,21]来进行节点资源的采集。Ganglia是1个可扩展的分布式集群资源监控系统,能够实现对集群内存、CPU、硬盘和网络流量等信息的监控,并支持自定义的插件来实现对指定服务的定向监控。Ganglia资源消耗小,对节点的性能影响非常小。
本文搭建的实验集群中有5个节点,分别为Master、Slave1~Slave4。图2给出了Ganglia采集的各节点的静态因素值,图3显示了某一时刻各节点的动态因素值。

Figure 2 Static factor values of each node图2 采集的各节点静态因素值
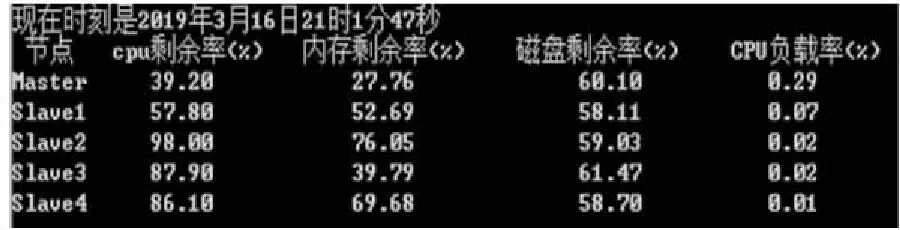
Figure 3 Dynamic factor values of each node collected for the first time图3 第1次采集的各节点动态因素值
根据图2和图3采集的静态和动态指标值,可以使用式(1)~式(3)计算得到当前系统中各个节点的优先级,如图4所示。

Figure 4 Priorities of the cluster nodes图4 系统中各节点的优先级
3 节点优先级调整算法
在集群工作过程中,参与计算的各个节点的优先级会发生变化。本文提出节点优先级调整算法NPAA(Node Priority Adjustment Algorithm),将根据节点资源的使用情况和节点的状态变化动态地调整节点的优先值。
3.1 节点优先级调整算法NPAA
NPAA的基本思想是实时监控系统中各个节点的动态因素指标,需要进行任务调度时Master节点计算出各Slave节点的优先级。算法1给出了NPAA的伪代码。
算法1节点优先级调整算法NPAA
输入:监控文件。
输出:集群节点优先级队列。
Step1集群启动时,触发监控启动心跳。
Step2各Slave节点监听检测端口,获取自身的参数配置信息,包括CPU速度、CPU核数、内存大小和节点磁盘容量。
Step3各Slave节点将Step 2中获取的信息上传给Master节点。
Step4Master节点对收到的信息进行归一化处理,使用式(2)计算出每个Slave节点静态性能指标S的值。
Step5Slave节点根据自定义配置利用Gang-lia对各自的CPU剩余率、内存剩余率、磁盘剩余率和CPU负载情况进行检测,获取相应的数据。
Step6Master节点对集群中每个Slave节点进行轮询,将得到的节点动态因素数据存入轮询数据库中。
Step7当集群发出节点排序请求时,Master节点取出轮询数据库中各节点当前的CPU剩余率、内存剩余率、磁盘剩余率和CPU负载,进行归一化处理,并使用式(3)得到每个Slave节点的动态性能指标D。
Step8根据每个Slave 节点的静态性能指标S、动态性能指标D和式(1),Master节点计算得到其优先级。
Step9Master节点输出节点优先级队列。
3.2 节点优先级调整算法实施架构
以包含3个Slave节点的集群为例,节点优先级调整算法实施架构如图5所示,整体架构由集群的主节点Master、从节点Slave和基于Ganglia的监控服务器3方组成。每个Slave节点上添加1个检测模块,利用Ganglia周期性获取节点的各种资源使用情况和任务队列长度。获取的信息被传输到Master节点进行存储和优先级计算。

Figure 5 Architecture for node priority adjustment图5 节点优先级调整架构图
集群启动后,各Slave节点根据本地配置文件定义的采集调度方案进行节点动态因素值的检测,监听数据时使用简单的监听/通告协议。Slave节点使用单播,将数据汇聚到Master节点。Master节点负责整合所有信息,它利用轮询器对每个Slave节点进行轮询,并将返回的数据存入各Slave节点对应的轮询数据库中。
4 基于节点优先级的Spark动态自适应调度算法
在集群节点资源不平衡的情况下,为保证任务的完成时间最短,需要准确地衡量各个节点的性能,从而选择出合适的节点进行任务分配。本文提出了一种基于节点优先级的Spark动态自适应调度算法SDASA(Spark Dynamic Adaptive Scheduling Algorithm)。
4.1 Spark动态自适应调度算法
基于节点优先级的Spark动态自适应调度算法运行在Master节点上,由计算节点优先级、优先级排序、分配任务到Slave节点、任务调度4部分组成。SDASA伪代码如算法2所示:
算法2SDASA
输入:任务集TaskSet,任务个数为m;集群节点集合WorkerOffer,节点个数为h。
输出:返回任务列表,即第i个任务分配在第j个节点上。
Step1检测集群有无节点更新,若有,根据NPAA重新获取各个节点的静态因素值,计算静态性能指标。
Step2根据NPAA,依次计算每个Slave节点的动态性能指标。
Step3依次计算每个Slave节点的优先级。
Step4根据各Slave节点优先级对节点集合WorkerOffer进行排序。
Step5从优先级最高的Slave节点开始,依次遍历每个节点。在每个节点轮流遍历TaskSet中的每个Task,循环执行Step 6。
Step6获取Task在节点上的本地化参数,并进行判断,如果参数是最大的,执行Step 7。
Step7分配该Task给该节点。
4.2 SDASA算法的设计架构
仍以包含3个Slave节点的集群为例,SDASA的设计架构如图6所示。其中每个Slave节点有1个信息收集模块,负责定期检测节点自身负载和资源剩余情况并传递给Master节点。当需要分配Task时,Master计算出每个Slave节点优先级的值,并对节点进行排序,选择排序靠前的部分节点进行任务分配。

Figure 6 Framework of SDASA图6 SDASA设计架构图
5 实验与结果分析
5.1 节点优先级调整算法实验
本节主要展示NPAA执行时节点优先级随动态性能指标而变化的情况。搭建的集群中有Master、Slave1~Slave4 5个节点。图2和图3分别给出了实验开始时系统的静态因素值和动态因素值。
向集群提交数据集大小为3 GB的WordCount任务。任务执行开始,系统进行动态因素值的采集。图7选取了系统运行17 s时第2次采集的各节点的动态因素值。图8给出了这个时刻的节点优先级。

Figure 7 Dynamic factor values of each node collected for the second time图7 第2次采集的各节点动态因素值

Figure 8 New priority of nodes after job running图8 任务运行后集群节点优先级
对比图3和图7中的数据,CPU剩余率和内存剩余量的值有所变化,而磁盘剩余量不变。这是因为在这17 s中,集群开始分解并执行WordCount,需要消耗CPU和内存。由于没有磁盘存储等操作,因而没有产生磁盘开销。将图8和图4进行对比,可以明显看出节点优先级随着动态性能指标的变化而发生了变化。
5.2 SDASA实验
本节分别使用Spark默认调度算法和SDASA进行任务调度,检测Spark集群的计算能力是否得到了提升。实验采用的节点配置如表1所示。

Table 1 Hardware configuration of cluster nodes表1 集群节点硬件配置表
实验中进行节点优先级计算时,静态因素和动态因素的权值分别为0.3和0.7;各静态因素的权值分别为:CPU速度0.05,CPU核数0.45,内存大小0.45,磁盘容量0.05;各动态因素所用权值分别为:CPU负载0.2,CPU剩余率0.1,内存剩余率0.6,磁盘剩余率0.1。
本文采用的负载来自于中国科学院计算技术研究所研发的基于大数据基准测试的开源性程序集BigDataBench[22]。它对5个典型且重要的大数据应用领域进行了模拟,包括搜索引擎、社交网络、电子商务、多媒体分析和生物信息学。BigDataBench总共包含了14个真实数据集和34个大数据工作负载。本文从BigDataBench基准测试套件中选择了3种工作负载,包括WordCount、Sort和K-means。
本文进行了2种不同类型的对比实验,即同种任务不同数据量和不同种任务同种数据量。为了避免其他因素导致的实验误差,每种实验分别进行10次并统计出任务在集群上的运行时间,最后取其平均值。
5.2.1 相同任务不同数据量
本实验处理的任务是WordCount程序,实验使用了规模不同的数据集,分别是2 GB,4 GB,6 GB,8 GB和10 GB。实验结果如图9所示,图中横坐标代表不同数据量,纵坐标代表完成整个任务所需要的时间。

Figure 9 Execution time comparison with different data volumes图9 不同数据量完成时间比较
由图9可以看出,在相同任务下,使用SDASA比使用默认算法整体效率有所提升。在5种不同的数据量下,性能提升最高为8.27%,最低为6.24%,平均6.99%。
5.2.2 不同任务相同数据量
本实验分别使用3种不同的任务,即WordCount、Sort和K-means,实验使用的数据量皆为4 GB。使用默认的任务调度算法和SDASA得到的实验结果如图10所示。

Figure 10 Execution time comparison with different applications图10 不同任务完成时间比较
由图10可以看出,运行WordCount、Sort和K-means任务时,使用SDASA比使用默认算法集群的运行效率分别提升了6.24%,7.06%,5.64%,平均6.32%。
从以上2个实验结果可以看出,与默认的任务调度算法相比,SDASA针对不同的数据量和不同类型的任务,都可以更好地发挥异构Spark集群的计算能力,从而提升集群的运行效率。
6 结束语
针对Spark资源调度设计的不足,本文提出了基于节点优先级的Spark动态自适应调度算法SDASA。通过在任务运行过程中实时更新集群中各节点的优先级,SDASA能为当前任务找到最优执行节点。实验结果证明了算法的有效性。
后续的研究内容主要包括:
(1) 针对任务的性质调整节点优先级评估体系中指标的权值,并通过实验进行验证,进一步增加评估的准确性。
(2) 任务类型多种多样,如CPU密集型、IO密集型等,不同类型的任务对节点性能有不同的需求。改进任务调度算法,增加对任务类型的考虑。
(3) 为了进一步验证SDASA的有效性,下一步将搭建更大规模的集群,增加数据集的数目进行更多的实验。
猜你喜欢
云南画报(2021年8期)2021-11-13
北京航空航天大学学报(2021年6期)2021-07-20
石油沥青(2021年1期)2021-04-13
空间科学学报(2020年4期)2020-04-22
数字通信世界(2020年3期)2020-04-06
制造技术与机床(2019年4期)2019-04-04
考试周刊(2017年7期)2017-02-06
制冷技术(2016年4期)2016-08-21
现代防御技术(2016年1期)2016-06-01
信息通信技术(2015年6期)2015-12-26
