
高速数据压缩及加密硬件加速电路研究*
2020-03-04 05:13尹晓华雷振江范赛龙
计算机与数字工程 2020年1期
王 飞 李 钊 尹晓华 雷振江 曹 智 范赛龙
(1.国网辽宁省电力有限公司信息通信分公司 沈阳 110006)(2.国网辽宁省电力有限公司科技信通部 沈阳 110006)(3.南京航空航天大学电子信息工程学院 南京 211106)
1 引言
随着云计算和物联网技术的飞速发展,数据爆炸式增长,数据压缩技术变得越来越重要,已经成为网络数据传输的关键技术。根据数据解压的结果,数据压缩可分为两大类,有损压缩和无损压缩。无损压缩的结果,其数据可以完全恢复,而有损压缩后的结果,数据不能完全恢复,但是它的压缩比通常高于无损压缩[1]。本文研究的LZ4数据压缩算法属于无损压缩,是一种最新的无损数据压缩算法,可对文本、音频等文件进行压缩,其数据可被完全恢复。
目前,信息安全威胁日益严峻,大量关键数据在网络上存储和传输,仅仅进行数据压缩,压缩后的数据将面临窃听和泄漏等信息安全风险。在许多关键领域,如智能电网和工业控制网络等,如果只压缩不加密,那么用户发送的信息就有可能存在被泄漏和篡改的可能,这样可能会对企业和用户造成严重的损失。
因此,对关键和重要数据进行数据压缩和数据加密就变成一个十分迫切的技术需求。但是,目前的压缩和加密算法通常都是在CPU上由软件来实现的,这样将会受限于CPU的处理速度,同时还会极大地消耗CPU的资源。当处理非常庞大的数据时,CPU将会一直满负荷运行,无法继续再处理其它事情。本文研究了在FPGA上同时实现LZ4数据压缩模块和AES数据加密模块的硬件加速,极大地提高了系统性能。在实现LZ4压缩时,本研究修改了部分数据格式以满足硬件数据连续输出的需求,在AES加密时,以面积换取速度,乒乓操作优化实现了数据连续的输入和处理。
2 LZ4算法分析和改进
无损数据压缩起源于霍夫曼编码[2]。其基于概率上的编码,需要先遍历全文,数据量较大时不易完成,后来Jacob Ziv和Abraham Lempel两位学者提出了LZ77和LZ78算法[3~4],奠定了词典编码的基础,后来人们又根据这两个算法创新,衍生出了一系列变体,被称为LZ77算法家族和LZ78算法家族。LZ4算法就是由LZ77算法衍生而来。
Yann Collet于2012年提出了LZ4算法[5],LZ4算法主要追求压缩和解压的速度,通常能够达到极高的单核压缩速度,并且支持多核系统。由于无损压缩算法的特点,其解压速度比压缩速度更快。
2.1 LZ4序列块
每个LZ4块都由序列组成,每个序列都以token开头,token用来预测不可匹配字符长度和匹配字符长度,token是一个字节,分成两个4位字段,每个字段范围是0到15;token高4位是不可匹配字符长度(literal length),它指出接下来复制的字符多少,如果字段为0,则接下来没有不可匹配字符,如果字段是15,则需要另一个字节来表示全长,每个附加字节表示0到255的值,当字节又达到255,则需要另加一个字节。例如:长度48表示为15+33,长度280表示为15+255+10,注意长度15表示为15+0,其中0不可缺少。token低4位是匹配长度(match length),指出最大匹配字符的长度减去4,超过15需要在块最后额外添加字节,采取的具体措施和literal length一样。token后接额外的不可匹配字符长度(可能没有),然后是不可匹配字符,再接着是偏移位置offset,由两个字节组成,最大值是65535,表示匹配字符间的长度,最后面是额外的匹配长度。具体如表1所示。其中,最小匹配是4个字符,小于4个字符则不认为是匹配,当不小于4个字符则判断为匹配,然后进行后向查找,找到最长的匹配,但是match length是减去4个字符的结果,例如match length=2,意味着匹配字符长度为6。

表1 LZ4序列数据格式
2.2 LZ4算法流程
LZ4算法过程主要分为5个过程,其中包括散列(hash)计算、匹配、后向查找、参数计算和数据输出,具体流程图见图1。
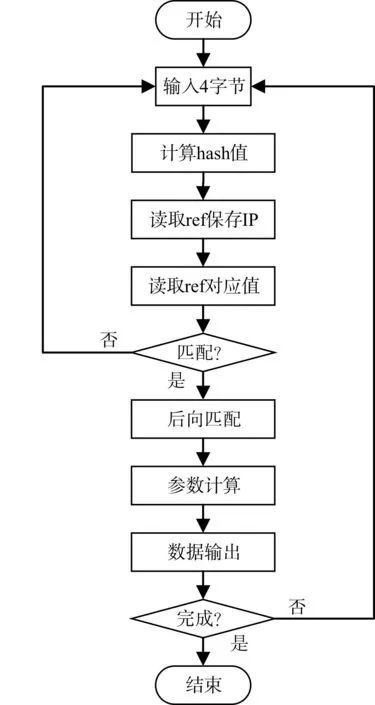
图1 LZ4算法流程图
原始的LZ4算法主要是针对于通用处理器设计的,没有考虑硬件电路进行优化,直接将其应用到硬件电路实现时会出现以下问题:
1)仅仅针对不匹配数据计算hash值,hash计算也不用于后向匹配,这样部分匹配数据的hash值将不会计算。
2)当新数据和hash表中存在的数据不一致时,就发生了冲突,这将需要重新计算hash值,会花费较多的时钟。
3)输入数据受限于hash表地址位宽,hash表中内存地址的最大值就是输入数据的最大长度,这样不能连续不断地压缩数据。
4)输出延迟不能确定,在原始格式中,在查找完成一次全部匹配之前不会输出任何数据,如果匹配长度很大,也需要在查找完成后才能输出,这样会使得数据在硬件中来不及输出。
为了改善硬件压缩速度,将LZ4数据格式更改如表2所示。其中token和offset的数据格式没有变,仅改变了literal和literal length,在token之后立即接上最大15个字节的literal,如果更长需要先加上一个字节的literal length,然后后面接上最大128个字节的literal,如果更大后面重复以上。LZ4块序列最后面是match length,匹配长度小于15+4时没有后面的match length字节,如果超过的话就额外添加两个字节表示,总的匹配长度是上面三者的总和。

表2 修改后LZ4数据格式
针对上面4个LZ4算法出现的问题的具体改善措施如下:
1)由于FPGA具有并行性,所以可以利用它在后向匹配时仍然计算hash值,这样可以改善压缩比。
2)为了减少hash冲突浪费的时间,改善压缩速度,增加一个与hash表对应的word表,不同的是hash表中存地址,而word表中存的是hash值对应的数据,这样在查找匹配时,可以在读hash表中地址时也能读取数据,然后进行匹配。
3)为了在硬件上连续的进行压缩,在hash表中增加一个有效位,数据有效置位,无效清零。定期清理hash表,当数据无效时就清零有效位,这样就不会出现地址存满导致无法匹配。
4)为减小输出延迟,将官方的数据格式修改为表2所示,当不可匹配字符超过300个字节,匹配长度设为4个字节,例如不可匹配字符长度是40k,那么对于新的格式在literal length到达300字节就可以输出了,这样大大的减少了等待匹配的时间。
综上所述,修改后的LZ4算法流程图如图2所示。
3 AES算法分析
为改善传统DES算法短密钥的缺点,美国国家标准局NIST于2001年公布高级加密标准算法(AES)[6],AES算法规定分组长度为128位,密钥长度可为128位、192位和256位。相应的迭代轮数分别为10、12和14轮。本文实现为128位密钥,工作模式为CBC密文块链接模式。
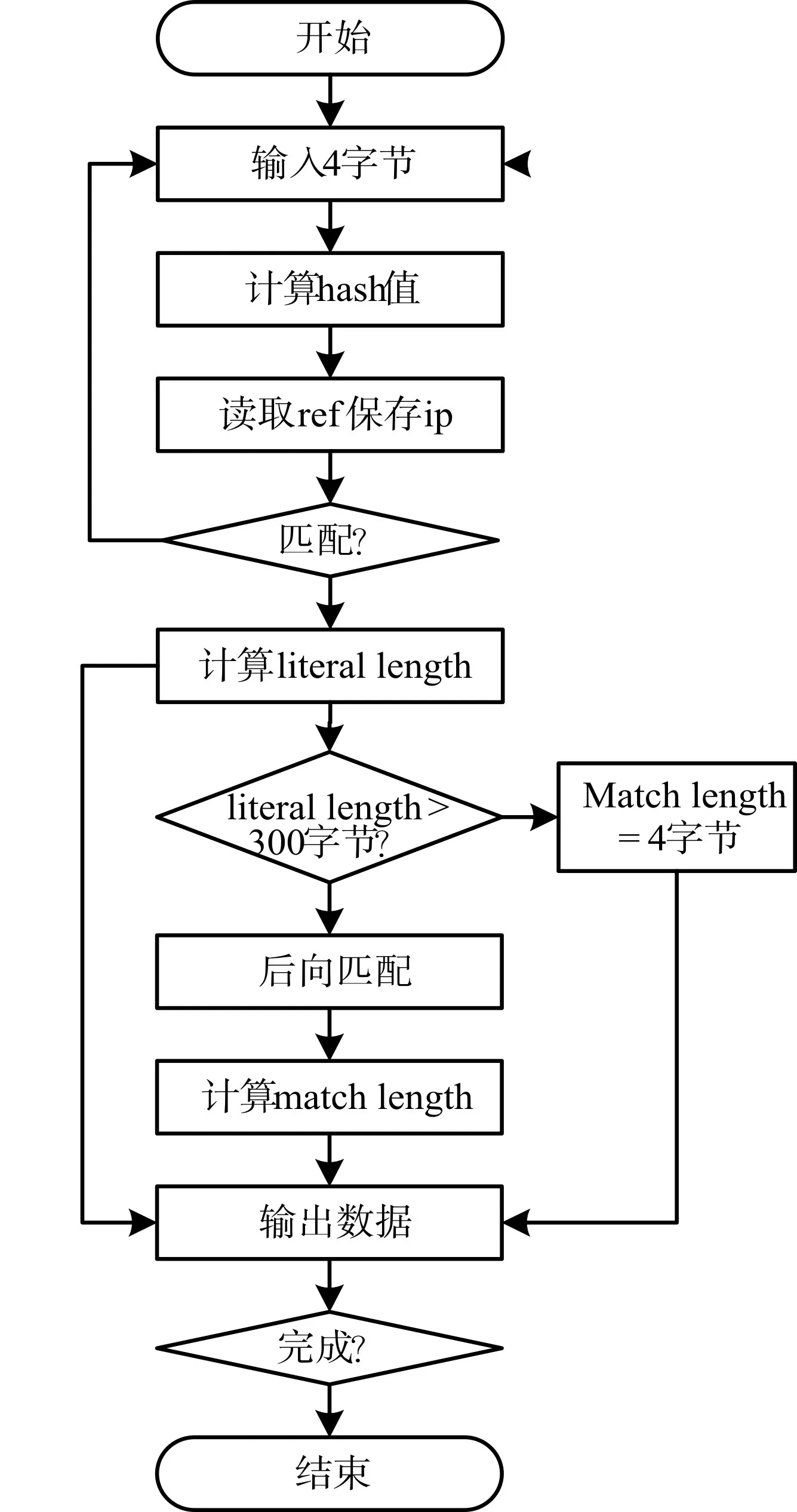
图2 修改后LZ4算法流程图
AES算法是在一个4×4的字节矩阵上进行运算,这个矩阵称为状态矩阵(state)。以本文研究的128位密钥来讨论,共进行10轮迭代,每轮迭代(除最后一轮)主要包括四个步骤[7]:字节代替、行移位、列混合、轮密钥加。
1)字节代替(SubByte):首先在伽罗华域GF(28)上计算乘法逆,然后再进行仿射变换。由于输入的字节只有256种可能,而且这种变换只是将源字节和另一字节一一映射,因此可以使用查找表来存储所有的可能情况,称为替换盒(S-box),里面的值就是字节代替变换后的值,继续参与其后运算。
2)行移位(ShiftRow):将矩阵中的每个横列进行循环移位。状态矩阵第一行循环左移0字节,第二行循环左移1字节,第三行循环左移2字节,第四行循环左移3字节[8]。
3)列混合(MixColumn):利用线性转换来混合矩阵中每行的4个字节。列混合可看做状态矩阵与一个常数矩阵相乘,打乱行线性变化。
4)轮密钥加(AddRoundKey):矩阵中的每个字节都与该次循环的轮密钥做异或运算,每个轮密钥的生成来自于密钥扩展。
5)密钥扩展算法:输入原始的128位密钥,产生10轮子密钥,通过循环字移位和字代替来实现。
6)CBC密文块链接模式:在CBC模式中,第一个明文分组与初始矢量IV相异或,然后再进行分组加密,后面的明文也要和前一密文相异或,然后进行分组加密,形成一条加密链,这样明文和密文之间的顺序不再有固定的关系[9]。
综上所述,AES加密算法流程图如图3所示。

图3 AES算法加密流程图
4 FPGA实现
本文实现了LZ4数据压缩[10]和AES数据加密模块[11]的流水线设计,整体实现了实时处理,每个时钟都可以输入数据,不浪费一个时钟。
4.1 硬件设计框架
本文的FPGA设计在Xilinx公司的Kintex-7 KC705评估板上实现,软件开发环境为Vivado 2016.4版本。在开发软件中设计了Verilog代码,然后仿真测试、观察波形,最后在评估板上进行了实现和测试[12]。
LZ4和AES模块的硬件结构框架分别如图4和图5所示,中间使用一块FIFO来连接两个模块。LZ4提出者没有考虑硬件的实现,所以算法改动较大,但是AES算法在设计时就考虑了硬件的实现,因此其结构适合硬件实现不需要进行格式改动。
输入数据使用ROM每个时钟产生8位数据,然后移位产生32位数据,计算hash值,写hash表和word表,匹配比较,然后如果匹配就后向查找,并计算literal length和match length,最后整理格式输出16位的压缩数据,然后进入连接模块,将数据存入FIFO内,输出128位待加密数据,送入加密模块,然后经过10轮变换输出密文数据[13]。

图4 LZ4算法的硬件结构框架

图5 AES算法的硬件结构框架
4.2 乒乓优化策略
乒乓优化以面积换取速度,将输入的数据按时钟分成两块,分别送入两个缓存/处理核内,然后分别进行处理,输出的数据再经过合并处理模块来将数据按时钟进行合并,这样就可以连续地输出数据,这样的优化策略一般可以将速度提高1倍。
本研究在LZ4数据输出的时候,为提高数据的输出速度,并且为了不妨碍数据的缓存,使用了乒乓优化,开辟两块RAM供存入数据,将输入的8位数据变成输出16位的数据,这样也为后面AES算法要输入的128位数据节省了读入时间。由于LZ4算法输出的压缩数据是16位,读取128位待加密明文数据需要8个时钟,但是AES加密有10轮变换,共需要11个时钟,这样数据将不能及时处理,无法做到实时系统,因此,使用乒乓优化策略来加速处理,每8个时钟来回切换AES加密核,处理之后合并数据,这样就能连续加密计算,提高了速度,做到了实时处理。AES乒乓优化策略如图6所示。
5 实验结果分析
实验平台为Kintex-7 KC705评估板,芯片为XC7K325T-2FFG900C,系统时钟频率为200MHz差分LVDS时钟,然后经过时钟生成IP核输出220MHz时钟信号供本实验模块使用。
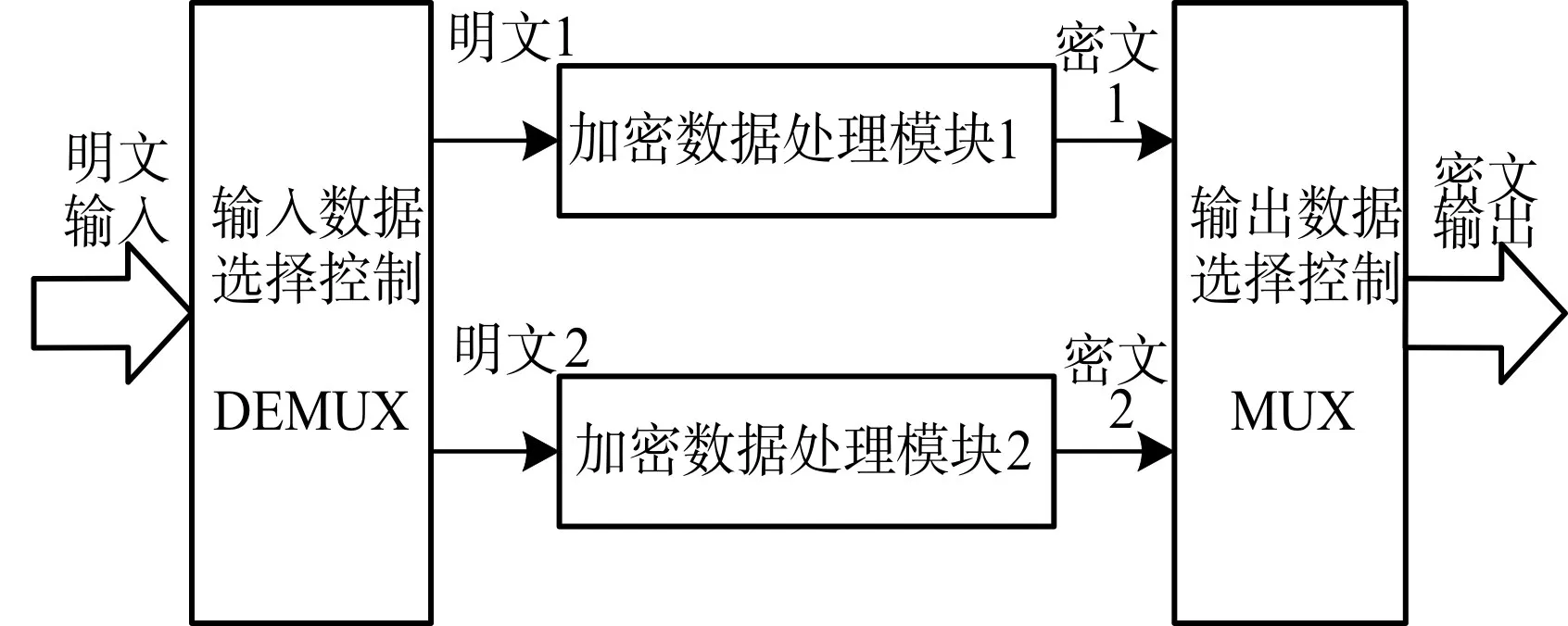
图6 AES乒乓优化策略
仿真测试数据来自于ROM中产生的数据,每个时钟产生8位数据,然后经过压缩加密输出128位数据。
LZ4压缩和AES加密模块资源总消耗如表3所示,资源消耗包括了数据生成的ROM模块。

表3 资源消耗表
LZ4算法的FPGA实现与同类FPGA压缩比较如表4所示。与同类压缩核LZRW[14]、LZW[15]、LZMA[16]的FPGA设计相比,本设计的各项指标都大大优于同类。

表4 无损数据压缩算法性能比较
对于AES算法,大多都是逻辑运算,只有轮变换需要消耗时钟,因此本实验设计的瓶颈不在AES算法,只是AES在乒乓优化时消耗了双倍的资源换取速度,以满足实时处理的需求。
本文设计整体上实现了流水线的处理,能在每个时钟都接收处理数据,并且实时输出。经过板级测试,设计最高可运行在220MHz的系统时钟,每个时钟输入处理8位,即吞吐率为1760Mbps。如表4所示,本文所设计的LZ4硬件加速器比之前最好的设计提高了1.5倍,为目前已知的性能最高的数据压缩加速电路。
由于FPGA的并行性,可以通过实现多个压缩核并行进一步提高压缩吞吐率。同时加上并行的加密模块,可以实现高速实时的数据压缩加密加速器。
6 结语
本文实现了LZ4压缩和AES加密算法的FPGA加速电路,通过修改LZ4的数据格式将其更适于硬件计算,并且通过乒乓优化将AES数据处理速度翻倍,以适应实时处理数据的需求。与现有设计对比,本文的设计的数据压缩加速器吞吐率比同类电路有着显著提升,硬件资源消耗也较小。未来的工作将重点设计多个压缩和加密模块并行的高速实时电路,进一步提升性能。
猜你喜欢
销售与市场(营销版)(2022年8期)2022-08-16
故事作文·低年级(2022年2期)2022-02-23
故事作文·低年级(2022年1期)2022-02-03
销售与市场(营销版)(2021年10期)2021-11-21
电脑报(2021年41期)2021-11-04
电脑知识与技术(2019年29期)2019-12-16
电脑爱好者(2019年8期)2019-10-30
计算机与网络(2018年2期)2018-09-10
农机使用与维修(2014年10期)2014-10-23
恋爱婚姻家庭·养生版(2010年8期)2010-05-14
