
基于Faster-RCNN的车牌检测*
2020-03-04 05:13艾曼
计算机与数字工程 2020年1期
艾 曼
(华中科技大学自动化学院 武汉 430074)
1 引言
机动车车牌作为车辆主要识别标志之一,在智能交通管理中发挥重要作用,车牌定位和识别也是近年来研究的热点问题。因为特殊使用环境,车牌上的文字内容在较窄范围内,文字间尺度变化不大,独立识别任务已经取得较高准确率,因此车牌定位直接影响车牌整体识别效果。
目前车牌定位算法主要基于人工设计的图像特征实现,例如基于形态学特征的算法[1]、基于视觉词袋的定位算法[2]和基于彩色图像的定位算法[3]等。在辨识度高、水平方向、环境影响小的前提下,车牌识别已成功应用在停车场、检查站管理中,但在恶劣天气、拍摄角度不固定、背景复杂等众多场景中,车牌定位和识别仍然是个难题。
基于深度学习的定位算法,该类算法主要分两类思想实现:回归方式和分类方式。对于回归方式有 YOLO[4]和 SSD[5]算法,将图像作为输入,输出层则为表示车牌区域的坐标和长宽,但是该类算法将图像分割成固定大小的网格进行回归预测,使得车牌区域较小时检测精度不高,且由于是回归方式,预测车牌时只能输出当初训练网络的个数,即预测的车牌个数是固定的;分类方式算法首先利用候选区域提取算法[6~9]获得车牌的候选区域,再通过分类网络识别出车牌区域,该类算法有RCNN[10]、fast-RCNN[11],以及将候选区域提取嵌入到网络中的 Faster-RCNN[12]。
其中Faster-RCNN模型在2015年COCO检测大赛一举夺魁,并在PASCAL VOC 2007和PASCAL VOC 2012上实现了当时最高的目标检测准确率。虽然后续推出 R-FCN[13]、Mask R-CNN[14]等改进框架,但基本结构变化不大,另外SSD,YOLO等精度上低于Faster—RCNN,因此选择Faster-RCNN作为车牌检测的框架。
本 文 选 取 ZF-Net[15]、VGG-16[16]以 及ResNet-101[17]三种不同的卷积神经网络分别与Faster-RCNN相结合,通过实验对比其在12740张车牌图片上检测车牌的准确率。
2 Faster-RCNN
继RCNN和fast RCNN之后,为了进一步减少检测网络的运行时间,微软Shaoqing.Ren等提出了最新的目标检测方法Faster-RCNN。他们设计一种区域建议网络(region proposal network,RPN)来生成建议区域(region proposals)。RPN的出现替代了之前 Selective Search[18]和 EdgeBoxes[19]等方法,它和检测网络共享全图的卷积特征,使得区域建议检测几乎不花时间。
RPN是一个基于全卷积的网络,它能同时预测输入图片的每个位置目标区域框和目标得分(属于真实目标的概率值)。RPN是通过end-to-end的方式进行网络训练,旨在生成高质量的区域建议框,用于fast-RCNN的分类检测。通过一种简单的交替运行优化方法,RPN和fast-RCNN可以在训练时共享卷积特征。由此可见Faster-RCNN的整体结构可认为是“RPN+fast-RCNN”的集成。二者结合,分工明确。RPN网络主要作用于生成高质量建议区域框,fast-RCNN则是起着学习高质量建议区域特征以及分类的作用。Faster-RCNN在生成建议区域的改进,使得检测效率提升。
2.1 RPN网络结构
RPN网络的作用是输入一张图像,输出一批矩形候选区域,类似于以往目标检测中的Selective Search方法。该网络结构基于卷积神经网络,是一种输出包含二类softmax和bbox回归的多任务模型。以ZF网络为参考模型,网络结构如图1。
其中,虚线以上是ZF网络最后一层卷积层前的结构,虚线以下是RPN网络特有的结构。首先是3*3的卷积,然后通过1*1卷积输出分为两路,其中一路输出是目标和非目标的概率,另一路输出bbox相关的四个参数,包括bbox的中心坐标x和y,宽w和长h。
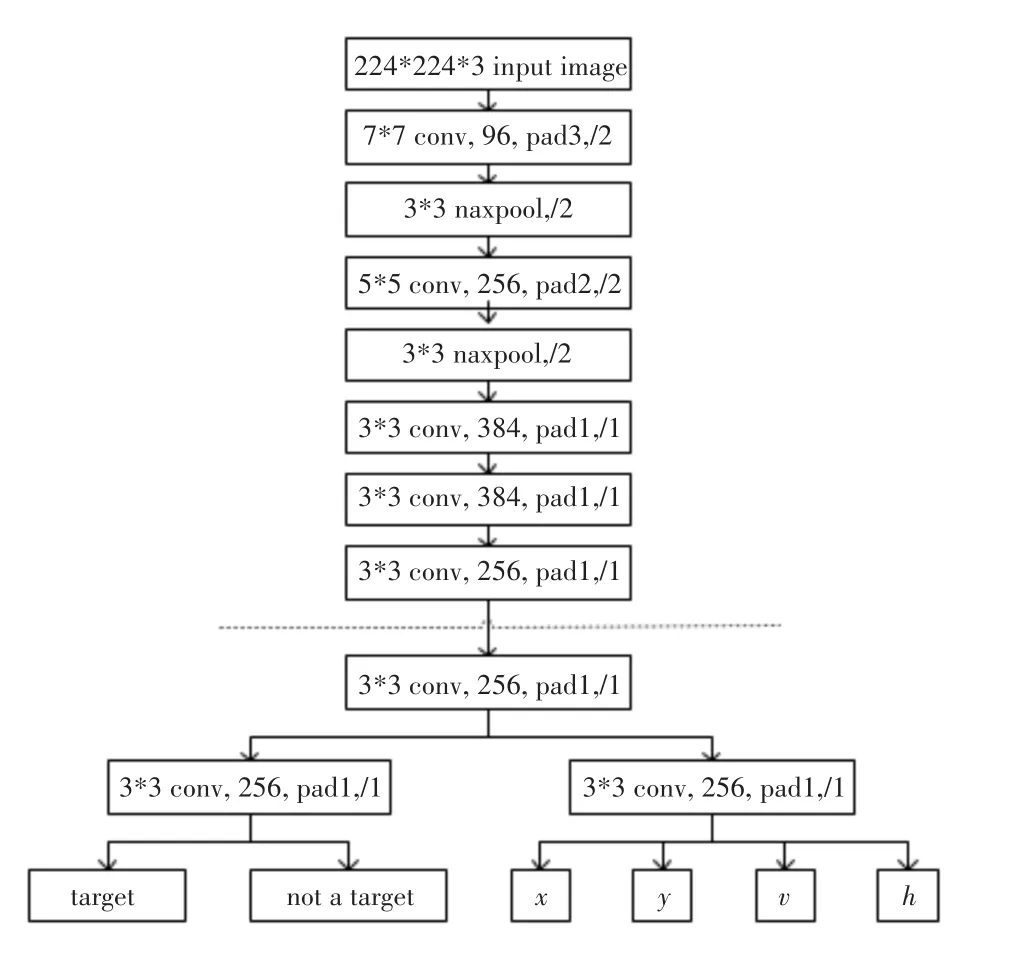
图1 以ZF为例的RPN网络结构
2.2 Anchor机制
Anchor是RPN网络的核心。由于目标大小和长宽比例不一,要确定每个滑窗中心对应感受野内是否存在目标就需要多个尺度的窗。Anchor即给出一个基准窗大小,按照倍数和长宽比例得到不同大小的窗。
2.3 训练
RPN网络训练涉及ground truth和loss function的问题。对于左支路,ground truth代表anchor是否为目标,用0或1表示。判定一个anchor内是否有目标的规则为
1)假如某anchor与任一目标区域的IoU最大,则该anchor判定为有目标;
2)假如某anchor与任一目标区域的IoU>0.7,则判定为有目标;
3)假如某anchor与任一目标区域的IoU<0.3,则判定为背景。
IoU指预测box和真实box的覆盖率,其值等于两个box的交集除以两个box的并集。其他的anchor不参与训练。
于是,代价函数如式(1)所示。
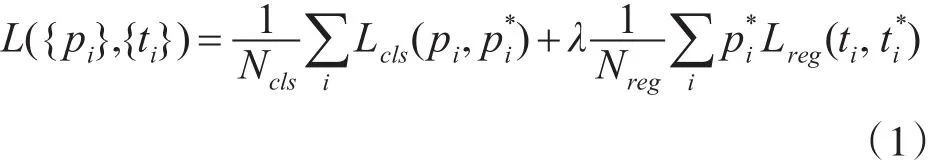
式(1)中代价函数分为两部分,对应着RPN两条支路,即目标与否的分类误差和bbox的回归误差,其中Lreg采用在Fast-RCNN中提出的平滑L1函数。回归误差中Lreg与相乘,bbox回归只对包含目标的anchor计算误差。此外,计算bbox误差时,不是比较四个角的坐标,而是计算tx,ty,tw,th,具体计算如式(2)所示。
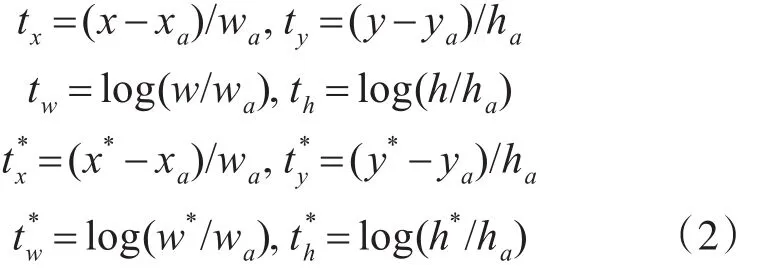
2.4 联合训练
采用四步训练法:
1)单独训练RPN网络,网络参数由预训练模型载入;
2)单独训练Fast-RCNN网络,将第一步RPN的输出候选区域作为检测网络的输入;
3)再次训练RPN,此时固定网络公共部分的参数,只更新RPN独有部分的参数;
4)再次微调Fast-RCNN网络,固定公共网络的参数,只更新Fast-RCNN部分的参数。
至此,网络训练结束,网络集检测和识别于一体,测试阶段流程如图2所示。
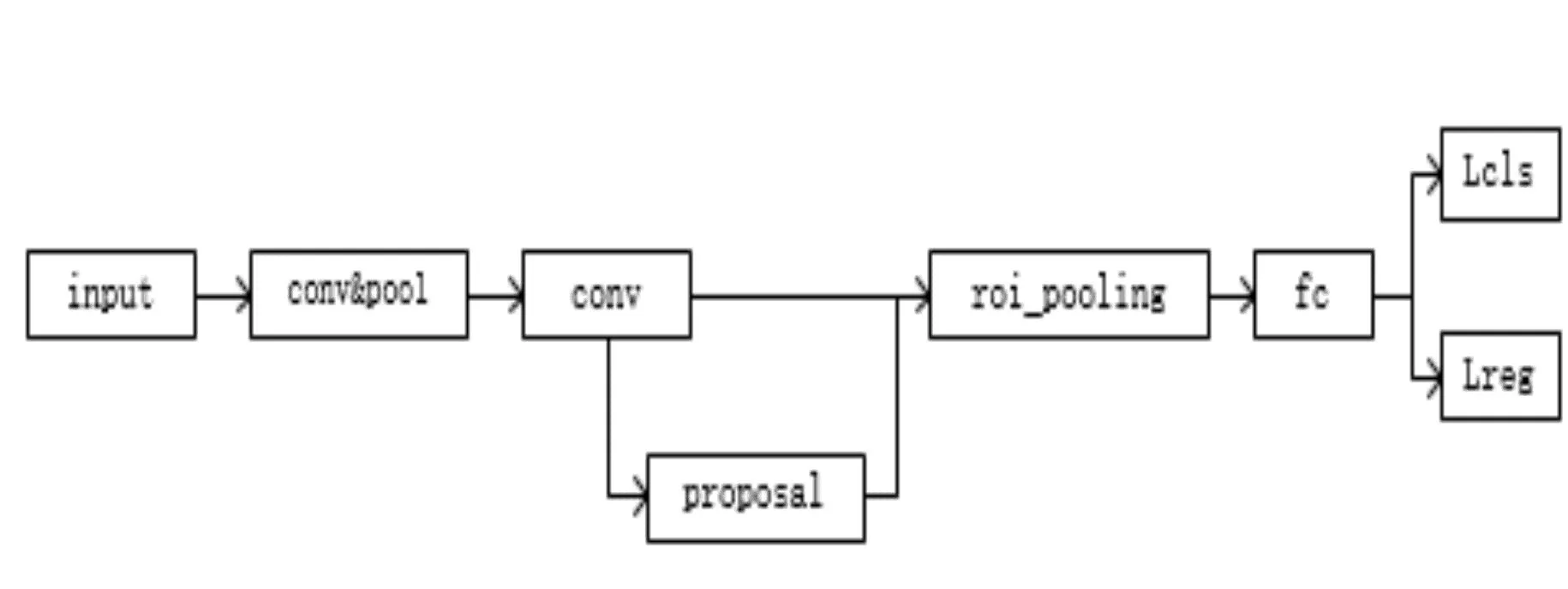
图2 Faster-RCNN测试阶段流程图
3 数据集准备
因国内还未有公开的车牌数据集,无法在统一平台上比较车牌检测各方法的性能,给出定量精度指标。实验训练和测试图像均来自网络车牌图像以及人为拍摄的图片,共1274张车牌图片,除了车牌水平方向、清晰、简单背景外,还专门采集了光照很弱、分辨率低、背景包含树木、人物等干扰信息的车牌图像,验证本文方法有效性和鲁棒性。由于车牌数据集的数量有限,人为对数据集进行了扩充,包括旋转,高斯模糊等,最后得到12740张图片。图3为光照很弱、分辨率低的示例图,图4为背景包含树木等干扰信息示例图。
4 实验结果与分析
实验步骤:
1)按照VOC2007数据集的格式修改自己数据集,将JPEGImages中的图片进行人为的标注,生成对应的Annotations文件夹。其中数据集按8∶2的比例随机生成了训练验证集和测试集,训练验证集按8∶2的比例随机生成了训练数据集和验证数据集;

图3 光照很弱、分辨率低的车牌示例图

图4 背景包含树木等干扰信息的车牌示例图
2)将ImageNet分类预训练所得到的ZF,VGG-16和ResNet-101三种卷积神经网络模型放入pretrained_model中,在每次实验中分别选择其中一种模型;
3)修改相应的类别参数,如本文需要修改类别参数为2类,分别代表车牌和背景。
整个实验均基于深度学习框架Pytorch,在实验的过程中,最开始训练过程不收敛,最后经过逐步修改参数,将学习率减小为10-5时模型开始收敛。
测试结果中矩形框标注出车牌区域,数字代表该检测框是车牌的概率,图5为图3中示例图片对应的检测结果,图6为图4中示例图片对应的检测结果。

图5 图3车牌的检测结果

图6 图4车牌的检测结果
统计在测试集上的实验结果,Faster-RCNN与ResNet-101结合检测的准确率最高,同时,对比了使用SSD框架在同一个数据集上的实验结果,SSD检测车牌的效果较差,因为车牌区域占整个图片比例较小,而SSD对小目标检测效果不佳。统计结果如表1所示。

表1 实验结果统计表
5 结语
用Faster-RCNN模型与三种卷积神经网络相结合的方法研究车牌检测,在收集的车牌数据集上进行训练和测试,发现基于Faster-RCNN与ResNet-101结合的方法,相对于ZF和VGG-16效果更佳,检测准确率达到97.2%,而且可以一定程度上解决光照弱,分辨率低,有干扰信息等状况下车牌定位不准确的问题。由于车牌数据集的准备较困难,在未来的工作中,希望通过相关部门收集更多的具有实际意义的车牌数据集,以便进一步研究车牌识别。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
动漫界·幼教365(中班)(2021年4期)2021-05-23
小猕猴智力画刊(2017年5期)2017-05-25
科技创新导报(2016年32期)2017-04-22
娃娃乐园·3-7岁综合智能(2016年2期)2016-10-24
娃娃乐园·3-7岁综合智能(2016年6期)2016-09-19
语文世界(初中版)(2014年8期)2014-10-14
