
采用GPU的视觉定位系统加速实验
2020-03-04 05:12王玲玉董文博
计算机与数字工程 2020年1期
王玲玉 董文博
(1.中国科学院大学 北京 100049)(2.中国科学院空间应用工程与技术中心 北京 100094)(3.中国科学院太空应用重点实验室 北京 100094)
1 引言
为了解决视觉定位系统实时性差的困境,GPU(Graphic Processing Unit)逐渐被引入到科学家们的研究范围内。在GPU发展初期,由于编程困难的缘故很难被推广应用。直到21世纪初,NVIDIA公司研发了一种通用的并行计算结构CUDA(Compute Unified Device Architecture),它大大地降低了编程的困难,加速了GPU的发展,同时也更加适合解决复杂的计算类问题。
Malik M[1]等发现对于计算密集型视觉应用[2~3],CPU和GPU之间的差距随着图像尺寸的增加而降低;对于非密集型应用,由于图像尺寸的增加,在平台之间观察到比较明显的性能和能效差距。在energy-efficiency(EDP)的情况下,GPU对于大于500×500的图像尺寸而言是最有效的平台。
Richard Vuduc[4]等认为虽然理想化的 GPU 可以提供更好的性能,但是我们发现至少对于同等CPU的调整以及对实际工作负载和调用环境的考虑,我们可以用两种现代化的四核CPU插槽在性能上大致匹配一个或两个GPU。事实上,将矩阵转移到GPU并结合GPU特定数据重组将会产生额外成本。也就是说,GPU的最佳实现方式不同于CPU的最佳或基准实施方式。实际上,由于合并访问的性能要求,这种数据结构调整在GPU上更为重要;没有它,GPU不会超过CPU[5]。
一些研究工作已经报告了在CPU上并行执行计算机视觉算法的性能结果,并将其与加速器实现进行了比较[6~8]。Cope[9]等对图像卷积在 GPU,FPGA和CPU上的实现性能进行了比较。Russo[10]等比较了GPU和FPGA上的图像卷积处理。
此外,Asano S 等[11~12]使用图像处理中二维滤波器,立体视觉和k-均值聚类这三个简单问题比较了GPU与CPU(四核)的性能,GPU可以显示其潜力,其中所有像素都可以独立处理。对于使用共享阵列的更复杂的算法,GPU由于其非常小的本地内存而无法执行这些算法,或者由于其内存架构导致的内存访问限制,无法显示出良好的性能。在这些算法中,GPU比CPU要慢得多(如果我们找到可以克服局限性的算法,但是我们找不到它们,可能会实现更好的性能)。
本文的目的是针对GPU在一个实际的视觉系统中的应用,探究GPU是否能够取得更快的速度,以及能比CPU取得怎样的提高。
2 视觉定位系统
我们设计了一个视觉定位系统,用于复杂场景下的目标识别和位姿检测,并为实时控制系统服务。系统的软件主要包括图像采集、图像匹配和位姿解算3个部分。图像采集是由摄像机拍摄图片完成;图像识别和匹配是为了得到目标在图像坐标系下的坐标;位姿解算是通过目标的图像坐标和先验知识,得到目标与摄像机之间的相对位姿信息,实现对目标的视觉定位。
其中,图像匹配算法分为两个部分。1)粗匹配(目标识别):利用CNN训练好的model判断场景中是否有目标存在,没有目标存在时直接处理下一帧图像。相对于没有进行判断场景中是否有识别目标存在的情况,我们系统整体的定位速度有所提升,加快了系统的工作效率。2)精匹配:有目标存在时,进行目标和图像之间的特征匹配,得到目标在图像坐标系下的精确位置。
基于系统在CPU下运行速度太慢,很难保证整个控制系统的实时性,我们将整个系统的算法移植到GPU的Linux平台上。NVIDIA的Jetson TX2有6个CPU核心,4个Cortex-A57、2个自研的Denver(丹佛)核心,GPU则是Pascal架构,256个CUDA核心,搭配8GB 128bit LPDDR4内存。
通过命令我们可以查看当前CPU的工作模式,并将其模式设置为6个CPU全部工作的状态。并且,我们需要决策整个系统的算法内容,哪些函数需要用GPU进行优化,哪些函数在CPU上运行计算。
文中会涉及到CPU和GPU性能的比较,此处的比较主要是针对使用Jetson TX2上自带的CPU和使用GPU加速系统的粗定位和精定位而言。
3 系统组成和GPU加速理论分析
在特征匹配中常用的算法有 ORB[13](Oriented FAST and Robust BRIEF)算法,SIFT算法和SURF算法三种。ORB算法分为特征点提取和特征点描述两部分。在ORB算法中,使用FAST[14]特征点检测算法来进行特征点提取,利用BRIEF[15]特征描述子算法来进行特征点描述,并将两者结合起来,在两者原有的基础上做了改进与优化的算法。考虑到ORB算法寻找特征点及计算描述子的速度较快,我们利用GPU加速提取图片的ORB特征,为精匹配做准备。
我们的整个系统的工作流程为:1)摄像头采集图像,调用训练好的模型来判断场景有无目标存在。当系统判断场景中有目标存在时,进行精定位。否则,直接处理下一帧图像。2)将CPU上的图片数据下载到GPU上,调用GPU加速模块进行特征点检测和特征提取工作。我们利用ORB算法提取目标的关键点和特征描述子,采用特征向量之间的欧式距离判断图像中特征点的相似性,将满足最小距离的两个特征点匹配起来。采用KNN[16](K-Nearest-Neighbor)匹配算法对特征向量进行匹配,再判断图像间的特征点匹配是否是一一映射,对于不是的点剔除掉。3)利用 RANSAC[17](Random Sample Consensus)算法对匹配正确的特征点进行数据拟合,求解单应性矩阵,建立特征点的对应关系,进行位姿解算。系统的软件流程图如图1所示。划线标注的部分使用GPU进行加速的模块,其中利用CNN训练好的模型是离线进行的,在系统运行时可以直接使用。
理论上的GPU可以加速的部分分析如下:
1)图像模型训练阶段,利用caffe框架离线训练卷积神经网络时,由于GPU可以多核并行运算,大大加快了模型训练的时间。我们的GPU有6个CPU核心,理论上训练速度可以加快几十倍。
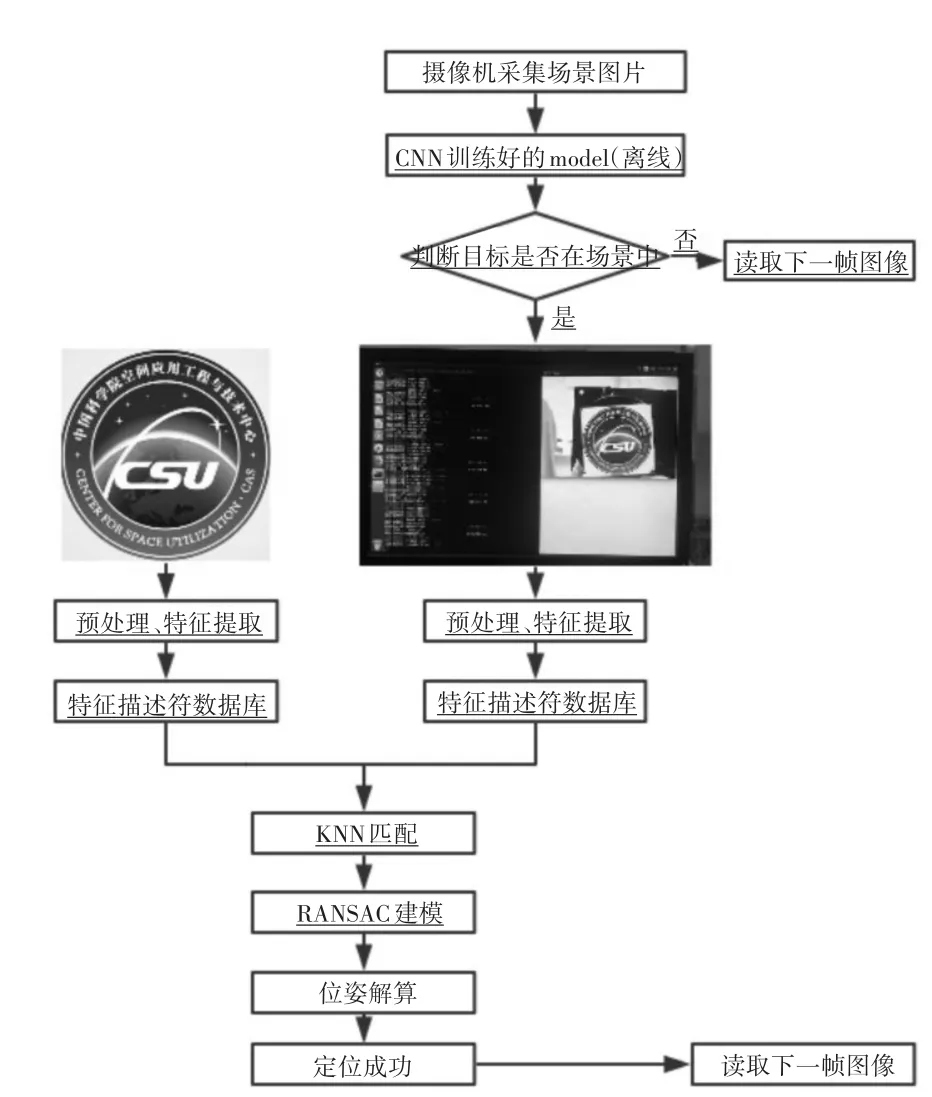
图1 系统软件流程图
2)图像传输:当摄像头采集到图片时,我们需要进行图像数据的传输,此时CPU和GPU的速度几乎是一样的。
3)图像识别:接着,我们利用GPU调用caffe的分类模型来判断场景中是否有目标出现。神经网络可以采用并行计算,理论上能够加速5~10倍。
我们采用OpenCV中的cudafeatures2d等里面存在的CUDA加速库,调用函数例如cv::cuda::ORB和cv::cuda::DescriptorMatcher等来完成系统的加速工作。
虽然使用GPU可以调用一些加速函数,但是由于CPU和GPU之间数据传输时间消耗的问题,在有些情况下总消耗时间GPU甚至会比CPU还要慢。
考虑到GPU适用于图形运算,而CPU是设计用来处理通用任务的处理、加工、运算以及系统核心控制等工作,所以我们将CPU和GPU结合起来进行使用,以达到最佳效果。
4 实验结果
4.1 粗定位加速实验结果
系统的前端是判断场景中是否有目标存在,此时我们需要调用卷积神经网络训练好的模型进行判断。通过调用深度学习框架自带的分类模块来完成,在代码中,我们选择GPU加速来完成。
我们取系统在CPU和GPU下连续20帧的粗定位时间,如图2所示。
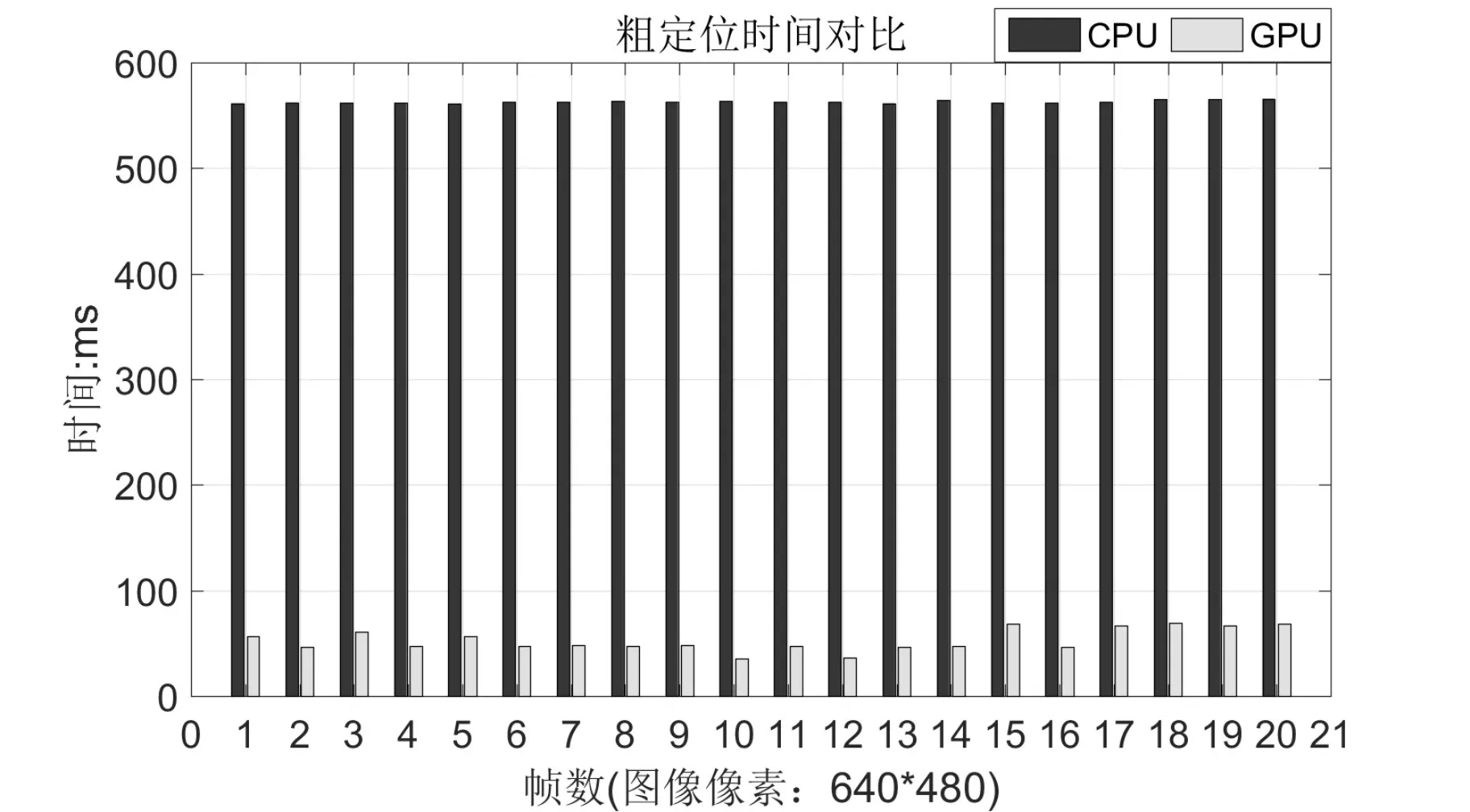
图2 CPU和GPU下的粗定位时间对比
对比使用CPU和使用GPU,经统计连续20帧系统处理的时间,我们取均值,发现当图像像素为480×360时,粗定位过程中CPU平均耗时是GPU的8.7546倍;当图像像素为640×480时,粗定位过程中CPU平均耗时是GPU的10.6272倍。
4.2 精定位加速实验结果
我们取系统在CPU和GPU下连续20帧的精定位时间,如图3所示。

图3 CPU和GPU下的精定位时间对比
对比使用CPU和使用GPU,经统计连续20帧系统处理的时间,我们取均值,发现当图像像素为480×360时,精定位过程中CPU平均耗时是GPU的1.0021倍;当图像像素为640×480时,精定位过程中CPU平均耗时是GPU的1.0466倍。
由此,我们可以看出,在精定位过程中,GPU和CPU所用时间相差并不是很大。并且随着图像像素的增大,这种差距会不断缩小。即图像像素越大,GPU加速效果越好。
5 CPU和GPU加速对比
在进行CPU和GPU对比之前,我们定义加速比来衡量GPU的优化性能。加速比=CPU运行时间/GPU运行时间,此处我们涉及到的CPU运行时间和GPU运行时间是各种开销和数据传输的总时间。表1是当图像像素为640×480时,视觉系统各个模块消耗的统计时间。

表1 系统处理一帧大小为640×480图像的时间
此外,我们还比较了当图像大小为640×480和480×360时,系统在CPU和GPU环境下的运行时间,并做了表2的对比分析。

表2 系统处理一帧图像时CPU和GPU执行时间对比
根据实验结果可以看出,整个系统在粗定位模块的加速效果较为明显,在位姿解算模块使用GPU反而比使用CPU还要慢。所以我们联想将CPU和GPU结合起来,粗匹配和精匹配用GPU来实现,定位模块用CPU实现,从而将系统用CPU和GPU相结合来实现。
通过表格,我们发现,使用CPU和GPU相结合时,视觉定位系统可以从1帧/s达到7帧/s左右,远远快于单独使用CPU或者单独使用GPU的情况。尤其在采用深度卷积网络时的粗定位环节(最占用时间的环节)。
6 GPU加速识别讨论
为了研究图像像素大小对于GPU加速的影响,我们取像素分别为 320×240,400×300,480×360,560×420,640×480,比较不同像素作用下,GPU对CPU在粗匹配模块的加速比。以图像像素不断增加为X轴,加速比为Y轴,如图4所示。
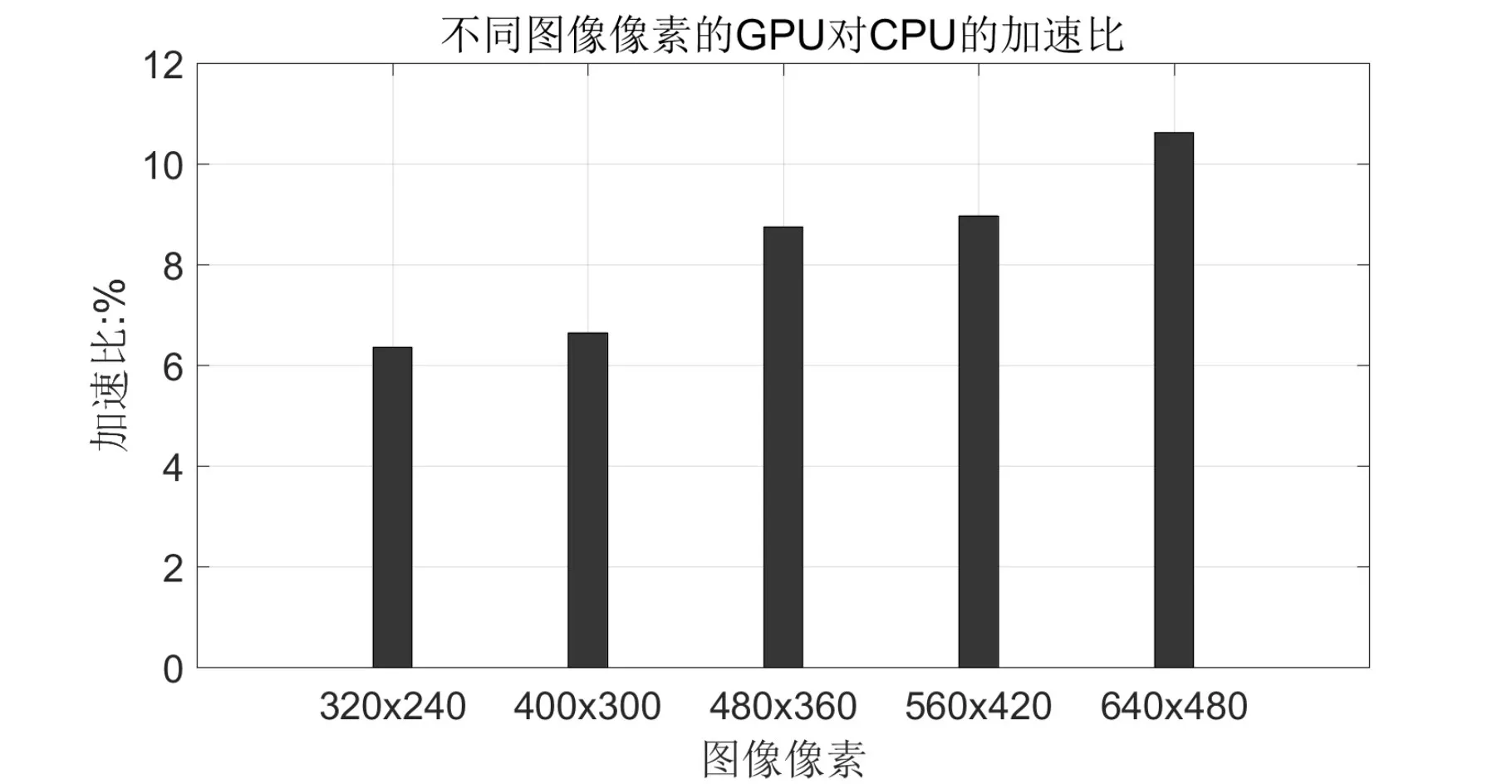
图4 不同像素的GPU对CPU的加速比
通过图像我们发现,当图像像素越大,GPU的加速效果体现越好。但这个分析仅限于我们设计的系统中粗定位模块。
最后,我们认为GPU并不是一定可以对任意系统加速,并且它的功耗是比较大的。
7 结语
据我们所知,CPU适合处理拥有复杂的指令、逻辑判断、循环、分支等的程序,而GPU更加适合高度的并行性、巨大的数据量、数据耦合度低、高的计算密度以及与CPU尽量少的数据传输等特点。在几组对比分析中,我们也发现了这个规律。当图像像素为480×360时,我们在粗定位系统中采用GPU加速,相对于CPU而言,平均耗时加速到8.7546倍。并且,随着图像像素的增加,GPU的加速效果会愈来愈好。同时,我们发现GPU在图像处理方面比CPU效果好很多,而处理数据相关性不大的计算类问题时,CPU表现更加突出。
总之,我们应该针对具体应用选择合适的GPU加速方案。下一步的计划是根据系统中算法已有的并行性把算法改变成并行算法,使之更适用于GPU编程模型的并行算法。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
小哥白尼(军事科学)(2022年2期)2022-05-25
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
红领巾·萌芽(2019年8期)2019-08-27
中学生数理化·高一版(2016年6期)2016-05-14
CHIP新电脑(2016年3期)2016-03-10
读者(2015年9期)2015-05-04
意林(2011年10期)2011-05-14
