
基于OpenPose人体姿态识别的变电站危险行为检测
2020-02-25 05:47朱建宝许志龙孙玉玮马青山
自动化与仪表 2020年2期
朱建宝,许志龙,孙玉玮,马青山
(国网江苏省电力有限公司南通供电公司,南通226001)
随着相关软硬件技术的成熟和成本的降低,视频监控已成为变电站安全生产管控过程中的一大助力,然而,目前变电站对于设备管控和人员管控还处于被动监控阶段,即通过人力来进行人员的异常行为监控,或者将监控系统作为事后分析资料的来源,不仅浪费了宝贵的视频资源,而且也无法自动进行事中分析和预警,操作人员仍处于繁重的监控工作中,因此,为了实现变电站智能化和安全生产管控自动化,有必要开展变电站智能化视频监控研究。
计算机视觉技术是人工智能的分支方向,主要通过视觉图像信息的处理,达到识别和理解图像内容的目的,智能视频监控借助于计算机强大的计算能力,依靠计算机视觉技术,从监控图像或视频中提取关键信息并快速分析,并将分析结果反馈给监控系统进行处理,从而达到智能识别、理解和处理监控视频的目的[1]。
目前,智能视频监控中的人体行为分析主要是对视频序列进行运动目标检测、目标跟踪和目标行为分析,运动目标检测需要将运动目标从背景中精确提取出来,主要方法有光流法[2-3]、帧间差法[4-5]、背景减法[6-7]等,这些都是基于运动目标在视频中的特性而设计的算法,实际上并没有真正达到感知图像的效果,目标跟踪算法分为基于特征的跟踪[8]、基于区域的跟踪[9-10]、基于模型的跟踪[11]和基于轮廓线的跟踪[12-13],这些跟踪算法适用于不同的目标和场合,缺乏普适性,往往针对特定场景需要专门设计一类算法,费时费力,目标行为分析可分为基于模型的行为分析方法[14]和基于相似度量的行为分析方法[15],与前述目标跟踪算法类似,这些方法同样复杂且冗余,缺乏普适性。
近年来随着人工智能技术的发展,基于视频图像开展人员异常行为监控已成为可能,在变电站人员行为监控中,最重要的问题是人体关键点分析,这类问题在深度学习中可以被统一归为人体姿态估计问题,多年来人们发展出了多种人体姿态估计方法,最早的方法只适用于单人,先识别出人的各个部分,然后再连接各部分来获得姿态,近年来多人姿态估计也取得了较快的发展,多人姿态估计分为两类,第一类是自顶向下(Top-down)的方法,即先检测出多个人,再对每一个人进行姿态估计,这种方法具有较高的准确率但是处理速度不高,如AlphaPose;第二类是自底向上(Down-top)的方法,即先检测出关节点,再判断每一个关节属于哪一个人,这种方法可以做到实时检测人体关键点,如OpenPose。
本文基于OpenPose多人姿态估计算法,提出了一种基于变电站监控视频的人员危险行为检测模型,该模型可用于多种监控环境下的人员姿态关键点的识别和定位,在本文实验平台下检测速度达到每秒20帧,满足变电站实时视频监控的要求。
1 变电站人员危险行为检测整体流程
如图1所示,本文将变电站人员危险行为检测划分为3个子任务:一是变电站安全区域的确定,二是人体关键姿态点的定位,三是在前两步的基础上进行危险行为判断并给予反馈,本文首先通过霍夫变换从变电站监控视频中识别并标定出安全区域,然后基于OpenPose多人姿态估计算法进行实时人体目标检测和人体关键姿态点识别,最后结合人体姿态点信息与变电站安全区域信息,分析人员行为是否是危险行为。

图1 变电站人员危险行为检测整体流程Fig.1 Overall process of detection of personnel dangerous behaviors in substation
2 变电站监控视频中的安全区域标定
目前,区域检测算法主要分为两大类,一是基于传统机器视觉的方法,二是基于深度学习的方法,基于传统机器视觉的方法有边缘检测、霍夫变换、颜色阈值、透视变换等,在区域检测中应用广泛;基于深度学习的区域检测主要通过语义分割网络实现,如LaneNet、SegNet、E-Net、FCNs等,效果较好,但所消耗的计算资源较多,由于变电站监控摄像头的位置相对固定,所记录的视频图像背景基本无变化,传统的机器视觉方法就可以达到较好的区域检测效果,因此本文采用了传统机器视觉方法对视频图像中的安全区域进行标定,处理步骤包括高斯模糊、灰度化、Canny算子边缘检测、霍夫变换以及区域识别。
2.1 算法介绍
高斯模糊又称高斯滤波,通过这一过程可以使得数据平滑并消除噪声,因此被广泛用于图像降噪处理,高斯模糊按像素点进行加权平均,即图像像素点高斯模糊后的值,是由其本身和指定邻域内的像素值在高斯函数计算后得到的权值矩阵下加权平均后得到,如式(1)所示:
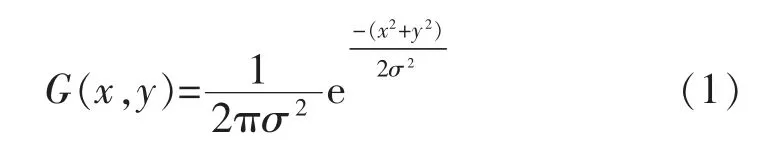
式中:x和y是像素点的坐标;σ是正态分布的标准偏差,分布不为零的像素组成的卷积矩阵与原始图像做变换,每个像素值都是周围相邻像素值的加权平均,这样的模糊处理相比其它的均衡模糊滤波器能够更好地保留图像边缘特征。
灰度化是将彩色像素点的RGB分量归一为同一个值,如式(2)所示,本文根据加权平均法来得到灰度图像。

式中:权重k1=0.299,k2=0.578,k3=0.144。
边缘检测主要是利用变化明显的点会呈现较大的梯度来定位边缘信息,本文使用Canny算子检测边缘,该算子主要是通过卷积来获得梯度,通过设置两个高低阈值,过滤掉梯度幅值较小的边缘噪声,保留高梯度幅值的边缘像素,梯度计算公式如下:
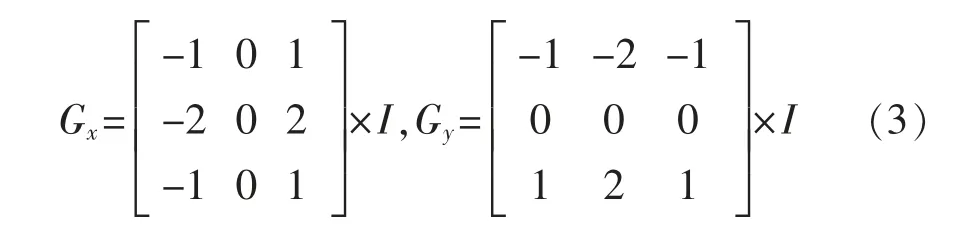
式中:Gx,Gy分别为x,y 方向的梯度,I为原始图像。
霍夫变换被用来从图像中识别几何图形,它是一种基于边缘二值图像寻找直线的方法,一条直线在二维空间可由两个变量表示,即在笛卡尔坐标系中由斜率和截距(k,b)表示,在极坐标系中由极径和极角(r,θ)表示。通过笛卡尔坐标系中某点的任意直线组合在极坐标系中是正弦函数曲线,因此,对边缘二值图像中的点进行坐标变换,在极坐标系中将产生无数正弦曲线,因此,在极坐标系(r,θ)平面中相交于同一点的正弦曲线数量说明通过该交点的直线由更多的点组成,因此直线的可能性很大,通过设置阈值,可以使得霍夫变换达到检测直线的目的。
2.2 实验流程
安全区域标定的具体流程如下:首先,将变电站的监控视频流转化为一帧帧的图像,再将图像转化为灰度图,同时用高斯模糊进行去噪处理;然后,使用Canny算子对图像轮廓进行提取,得到边缘二值图像,再使用霍夫直线检测,提取轮廓图中的直线;最后,对提取出的直线集合进行处理,得到安全区域的点集,并用红色线对安全区域进行标定,处理效果如图2所示。

图2 安全区域标定流程中的结果展示Fig.2 Results in the process of calibrating safe area
3 基于OpenPose的多人姿态估计和行为检测
3.1 算法框架
OpenPose多人姿态估计模型由美国卡耐基梅隆大学的研究人员提出,如图3所示。
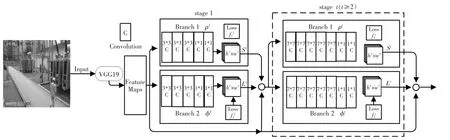
图3 整体网络结构图Fig.3 Diagram of overall network structure
该模型使用VGG-19 深度神经网络提取图像的原始特征图F(Feature Map),然后再分成两个分支输入,一部分使用卷积网络(CNN)预测人体姿态关节点的热度图,另一部分使用CNN 得到所有相连关节点的部分亲和域,部分亲和域是记录肢体位置和方向的2维向量,关键点热度图和部分亲和域在每一个阶段下与输入特征层的关系映射视为St和Lt,其输入层除第一个阶段为VGG-19网络输出的特征层外,其余阶段的输入层均为前一个阶段的两个输出向量与VGG-19输出层的连接组合,即:
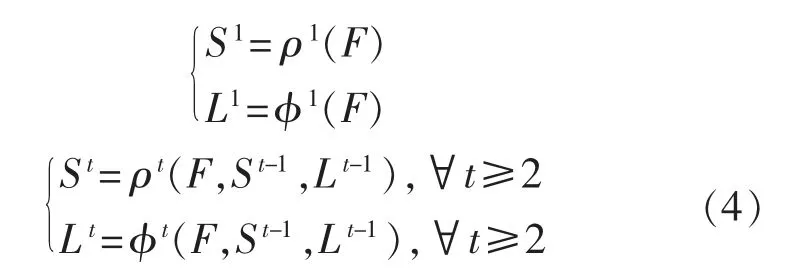
通过多阶段的预测,所得到的预测结果将更加精确,当从最后阶段得到置信热度图和部分亲和域后,也就得到了所有关节点的位置信息和相连关节点的方向向量。
对于给定的肢体c,通过训练找到一个连线配对方式使得总亲和度最高,如式(5)所示:
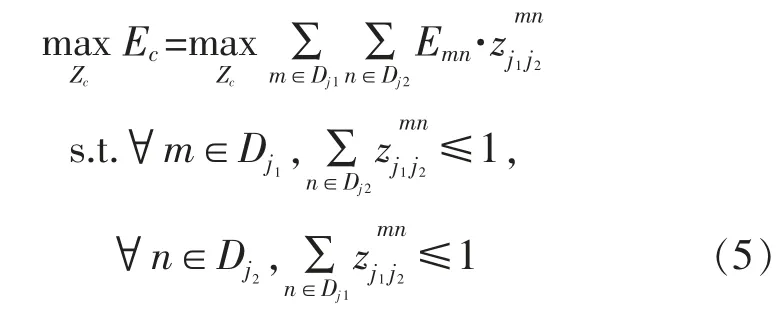
式中:Emn是与的亲和度;Ec是肢体c上涉及的两类关键点间的连线总亲和度,该最优化问题可用Hungarian 贪心算法求解。
通过各肢体之间独立优化配对,可以解决每个肢体涉及的两类关键点的连线聚类问题,然后依据相同关键点衔接组装成整个身体的姿态。
3.2 实验数据集的增广
图像增广是通过对图像进行一系列的变换,产生相似但又有所不同的训练样本,从而扩大数据集的规模,同时也可以降低模型对某些属性的依赖,提高模型的泛化能力,本文使用了平移、翻转、裁切、旋转、加噪等多种方法来对图像进行增广以扩充训练集,对于图像变换的过程中产生的空白区域选用黑色填充,以减少对目标特征的影响,部分数据增广效果如图4所示。

图4 训练图像的数据增广Fig.4 Data augmentation for training images
3.3 模型训练与测试
本文使用在计算机视觉研究中应用广泛的COCO数据集作为人体关键点模型的训练数据集,使用变电站监控视频中的图片样本作为测试数据集,数据集中的人体关键点共17个,包括手臂、脚等,训练与测试所基于的软硬件平台如表1所示。

表1 软硬件实验平台Tab.1 Experimental platform of hardware and software
输入图片的大小为368×368,一次训练所有样本,循环次数设置为5,初始学习率设置为0.0001,每批次输入10 张图片,最后一层热度图和部分亲和力场的损失随训练次数的变化情况如图5和图6所示,其中横坐标为迭代次数,纵坐标为总误差,从图中可以看出,随着迭代次数的增加,热力图和亲和力场的损失函数逐渐减小。

图5 最后一层热度图损失随训练次数的变化Fig.5 Variation of heat map loss of the last layer with iterations
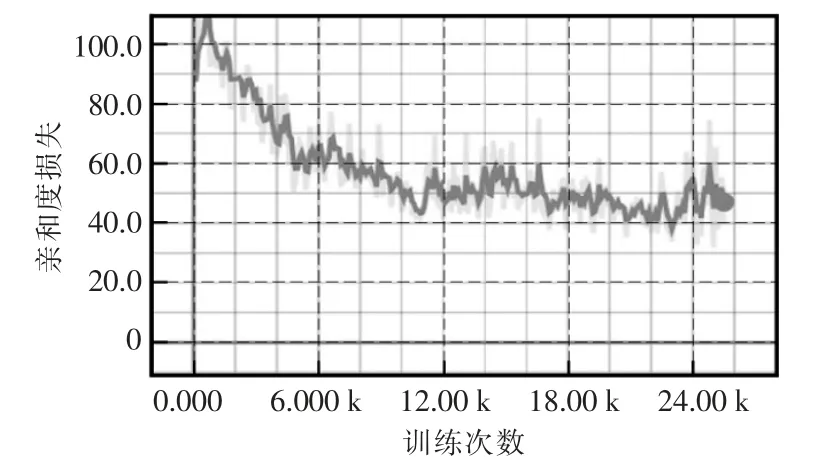
图6 部分亲和力场损失随训练次数的变化Fig.6 Variation of partial affinity field loss with iterations
将变电站监控视频中抽取的图片输入到训练好的模型,得如图7所示的结果,从图中可以看出,人体姿态点识别模型训练效果较好,能够较好地检测出人体姿态关键点,并在图像中准确标注出,测试还发现,该模型对测试摄像头视频流的检测速度达到每秒20帧左右,实时性较好。
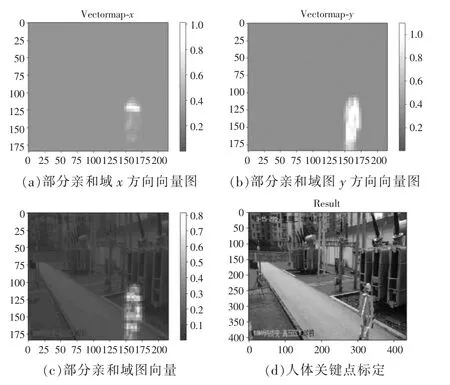
图7 人体关键点输出图Fig.7 Human body key point output diagram
3.4 危险行为检测
前文通过传统图像感知的方法标注了变电站安全区域,获得了安全区域框的点集,也通过基于OpenPose的多人姿态估计模型获得了人体关键点数据位置点集,从人体关键位置点集中选取人的双脚位置,通过判断双脚位置点是否位于标注的安全区域内,即可得到人员是否处于危险区域内的结论。
4 结语
为了适应变电站视频监控智能化的趋势,本文提出了一种基于OpenPose多人姿态估计算法的变电站人员危险行为检测模型,该模型包括3个子任务,分别是安全区域的识别和标定、变电站人员的姿态点分析(可应用于多人)以及巡检危险行为检测,通过训练和测试,该模型在实验环境下获得了较好的识别与检测效果,同时检测速度也能满足实时性要求。
猜你喜欢
建材发展导向(2022年3期)2022-04-19
今日农业(2021年8期)2021-11-28
建材发展导向(2021年11期)2021-07-28
学生天地(2020年3期)2020-08-25
电子制作(2019年10期)2019-06-17
汽车观察(2018年9期)2018-10-23
电子制作(2018年8期)2018-06-26
电子制作(2017年8期)2017-06-05
诗选刊(2015年4期)2015-10-26
新高考·高一物理(2015年5期)2015-08-18
