
面向方面记忆网络的IT产品细粒度情感分析
2020-02-19 14:09李晋源杨其越王沛尧崔国荣
计算机工程与应用 2020年3期
李晋源,康 雁,杨其越,王沛尧,崔国荣
云南大学 软件学院,昆明650500
1 引言
随着人工智能、大数据技术的广泛使用,网购中的在线点评数据包含着巨大的潜在价值,有助于消费者的选择与企业在产品开发与销售环节方面的决策。因此在互联网数据呈爆炸性增长的背景下,如何从海量数据中挖掘有价值信息成为了急需解决的问题。产品具有多维属性,不同消费者购买产品时会依据其各自偏好而会更多关注某些方面的特征。在线点评分为数字评分和在线评论,数字评分的粒度比较粗且难于细化,而在线评论能够表达消费者对产品各方面属性的真实感受,为其他购买者所信赖。因此如何对在线评论进行分析、挖掘,并将挖掘的信息运用到网络销售和顾客选购参考标准中,成为在线评论情感分析的重要方向[1-3]。
在线评论多为缺乏组织结构的文本信息,导致研究者难以直接获取评论文本中所包含的有效信息。因此如何从繁杂无序的数据中获取有效信息就显得尤为重要。目前,许多研究者对情感分析算法进行了研究,并取得一定的成果。杨立公等[4]对使用马尔科夫逻辑网将句子上下文与情感特征相结合进行情感分析,实现跨领域文本的情感分析。明均仁[5]将关联规则方法运用到文本挖掘的情感分析中,设计出融合语义,关联挖掘的文本数据情感分析方法,提高了情感分析的准确率。Medhat等[6]提出对商品进行情感分析的常规分析步骤为商品评论、情绪识别、特征选择、情感分类、情绪极性判断。罗慧钦等[7]提出基于隐朴素贝叶斯方法进行商品评论情感分类。
基于上述背景,本文提出一种深入挖掘评论信息的有效方法,以用户需求为导向来对产品评论数据进行基于方面的更细粒度情感分析。
本文的主要贡献如下:
(1)本文使用特征提取效果更好的Bi-LSTM-CRF模型对IT产品评论数据进行分词,同时在方面词的提取上进行深入细致的分析,利用哈工大的句法依存关系客观地对评论数据中的方面词进行抽取。
(2)采用基于self-attention机制的深度记忆网络模型对从评论数据中提取出的方面词进行情感分类。模型引入多头注意力(Multi-headed attention)机制方法对embeeding层的输出进行编码,同时采用共享参数,可以学习到每个上下文单词的重要性/权重。
(3)通过量化情感评价指标,获取用户对IT产品的热门关注点以及相应的情感评价倾向,为以后探索构建面向用户需求的产品评估体系做基础。
2 相关工作
主题词抽取是文本主题挖掘的基础工作之一,本文采用公冶小燕等[8]提出的基于改进的TF-IDF算法及共现词的主题词抽取算法进行IT产品主题词的抽取,结合已有的搜狗词库等专业词库来构建主题词库。
情感分析中分词结果的好坏将直接影响后续信息处理的结果。由于神经网络方法能够极大地减少特征工程的工作量,中文分词的方法也从传统的非神经网络方法迁移到基于神经网络方法上来。Chen等[9]提出了一种带有自适应门结构的递归神经网络(Gated Recursive Neural Network,GRNN)。针对滑动窗口的局部性,Chen[10]提出用长短时记忆神经网络(Long Short-Term Memory Neural Networks,LSTM)来捕捉长距离依赖。本文采用Bi-LSTM-CRF模型[11-12]来实现中文分词任务,对文本序列采用word2vec方式[13]进行字级别的分布式向量化,既利用了双向LSTM模型能够保存上下文信息的优势,同时也利用了CRF层从句子层面考虑前后标注之间的影响,提高中文自动分词的准确率和召回率。
相比粗粒度的情感分析,更细粒度的情感分析能实现对在线评论数据的深度挖掘。在细粒度情感分析的任务上,Kim等[14]基于Word Net建立情感词典,并以此识别情感词与情感极性,再通过观点词探测出产品特征并计算情感倾向。Xu等[15]使用主题模型识别隐式属性,从而计算属性情感倾向。Carenini等[16]使用词语相似性对特定领域的产品属性进行属性分类,以类为标准计算类情感倾向。郑安怡等[17]提出了一种新的ITS算法对文本情感分析领域内的特征加权进行研究。传统的神经模型如Tree-LSTM[18]以隐式方式捕获上下文信息,而且无法明确地展示出重要的上下文线索,使用相同的方式操作每个上下文单词,因此无法明确显示每个上下文单词的重要性。
3 研究问题
本研究旨在深入挖掘产品在线评论数据中有价值信息,对用户所关注的产品方面词进行情感分类。因此本文主要解决如下两个问题:
(1)如何从在线评论数据中客观准确地抽取反映用户所关注的产品方面词。
(2)基于评论文本中的方面词,如何进行更细粒度情感分析,获取针对方面词的情感类别,量化情感指标。
4 依存句法分析的方面-情感词对提取
特征观点是指从在线评论中挖掘出的商品属性及其相应的情感词所形成的组合。特征观点对的抽取,是对在线评论进行细粒度情感分析的基础。Zhao等[19]提出在目标极性词(T-P)搭配提取前,采用情感语句的压缩步骤(Sent Comp)去除了情感分析中不必要的信息,降低句法分析时评论语句信息冗余带来难度。
本文采用哈工大的依存句法分析[20]的方法,充分考虑句子的结构信息,并结合邻近法作为补充对评论数据中方面—情感词对进行抽取。依存句法分析是通过语言单位内成分之间的依存关系揭示其句法结构,识别句子中的“主谓宾”、“定状补”这些语法成分,用于分析各成分之间的关系,进而提取出每条评论数据中的方面-情感词对。LTP的依存句法分析关系如表1所示,关系类型表示每对相互依存的词之间存在怎样的句法关联。

表1 句法依存分析标注表
通过对评论文本的词性标注与句法分析发现,评论数据中的方面词通常是名词和动名词,而体现用户情感的主要为形容词和名词。因此可通过词性与依存句法关系组合的句法模板,对方面-情感词对进行抽取。
评论集具有语法不严谨,表达随意等特点,很多句子没有严格按照语法规则来表达,因此本文制定以下6条规则根据句法依存关系提取方面-情感词对,按照语法的规范性分为一般情况和特殊情况,一般情况包括规则1、2、3、4,特殊情况为规则5、6。
规则1若评论中方面词作为主语,谓语为情感词时,则抽取SBV关系,根据ADV等关系,可得到<SBV,主语,情感词>或者<SBV,主语,修饰词,ADV,情感词>,若谓语为非情感词,其后关系为CMP、VOB等,且CMP、VOB所指向的是情感词,因此可得到<SBV,主语,谓语,CMP/VOB,情感词>。
例1“蛮不错,外观很棒”,如图1(a)所示,评论中“外观”作为主语,“很”为修饰词,“棒”作为情感词,抽取<SBV,主语,修饰词,ADV,情感词>,因此可得到方面-情感词关系对(外观,很棒)。图1(b)中,“系统”作为主语,“反应”作为谓语,“慢”作为CMP关系中情感词,因此可得到(系统,慢)。

图1(b)规则1示例2
规则2若评论中方面词存在ATT关联时,需要将ATT关系中的非情感词和方面词连接起来,将情感词作为该方面词的情感词,表示为<ATT,方面词,情感词>或者<ATT,非情感修饰词,方面词ATT,情感词>。
例2“电脑外观满分”,如图2所示,评论中方面词“外观”关联两个“ATT”关系,方面词“外观”前面的ATT关系中的“电脑”为非情感修饰词,则方面词为“电脑外观”,后面的“满分”为情感词,因此可得到方面-情感词的关系对(电脑外观,满分)。
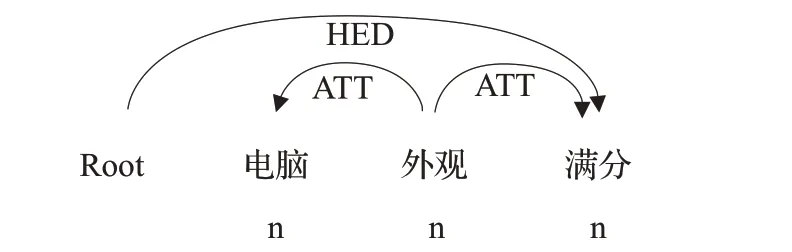
图2 规则2示例
规则3若评论中出现一个方面词且核心词为动词,其宾语为方面词,则依据ADV,ATT等关系找到情感词,从中选取同一分句中距离不超过6的情感词,则可抽取<VOB,宾语,谓语>,其宾语,谓语依据规则1,2构成方面词和情感词。
例3“可惜不支持Win7系统。”,如图3所示,核心谓词“支持”,其宾语为“系统”,根据ATT关系可得“Win7系统”为方面词,“不支持”为距离小于6的动词情感词,因此抽取得到方面-情感词对(Win7系统,不支持)。

图3 规则3示例
规则4评论中含有并列关系,可通过COO并列结构和规则1,2,3,抽取方面词-情感词对。
例4“看电影和玩游戏都很顺畅”,如图4所示,存在COO并列结构,“电影”和“玩游戏”是并列结构,结合规则1,抽取得到(电影,很顺畅),(玩游戏,很顺畅)。
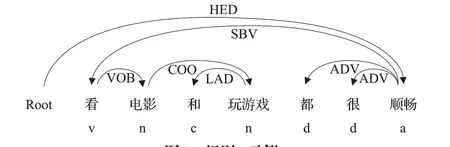
图4 规则4示例
规则5评论中只含有一个关键词且不符合规则1,2,3,4,因此可根据距离不超过6,找到情感词,再根据ADV,ATT等关系找到修饰词组成新的情感词。
例5“唯一感到不顺畅的就是鼠标”,如图5所示,该句中存在方面词“鼠标”,根据规则4找到距离不超过6的情感词“顺畅”,再依据ADV找到修饰词“不”,组成新的情感词“不顺畅”,因此抽取到的方面-情感词对为(鼠标,不顺畅)。

图5 规则5示例
规则6若含有明显情感词且无关键词的情况下,可用比较常见的搭配进行关联,然后使用ADV,ATT等关系找到修饰词。
例6“有明显颗粒感,看着不舒服”,如图6所示,该句中无方面词,找到一个名词情感词“颗粒感”,通常使用“颗粒感”形容屏幕,然后根据ATT关系找到修饰词“明显”,因此抽取得到方面-情感词对(屏幕,明显颗粒感)
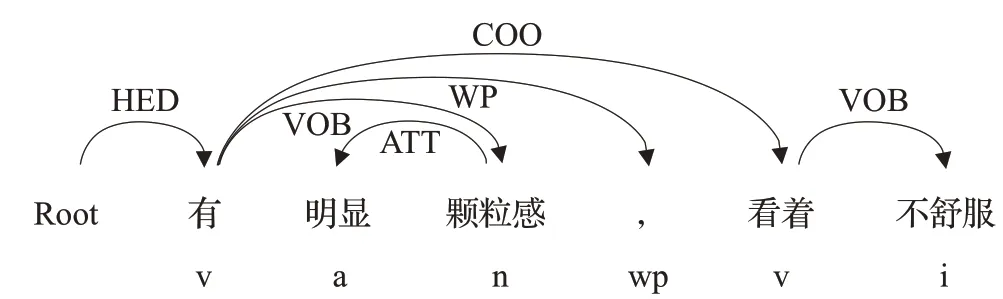
图6 规则6示例
由以上6条规则可得到其规则覆盖率,如表2所示,一般情况中的规则提取方面-情感词对占到90.84%,特殊情况中规则6使用常用的关联搭配占3.34%,使用规则6原因是在评论集中表达的内容往往是人们默认为已知的,因此有缺省方面词。表4统计出最频繁搭配表及其出现的次数。如表3所示,列举的10个常用方面-情感词对关联搭配。

表2 规则覆盖率

表3 常用方面-情感词对关联搭配(取10个)
5 面向方面深度记忆网络模型
面向方面的情感细粒度分类是产品评论情感分析方法的核心部分,本文提出基于self-attention机制的深度记忆网络模型来对方面词进行情感分析,如图7所示。
给定一个句子m={w1,w2,…,wi,…,wn}和其方面词(aspectword)wi,采用词嵌入的方式对句子的每个单词进行向量化,方面词向量和上下文向量,如式(1):

其中,ek=[ ]0,…,0,1,0,…,0是第k个标签的one-hot编码形式,通过embeeding矩阵UE,得到300维的词向量。
设置一个编码器的模块,如图8所示,采用多头注意力(Multi-headed attention)机制方法对embeeding层的输出进行编码,使得上下文的每个单词与句子中的所有单词进行self-attention计算,学习句子内部的词依赖关系,捕获句子的内部结构,得到上下文的隐藏状态,如式(2)、(3):

图7 基于attention的深度记忆网络

MultiHead(Q,K,V)=Concat(head1,head2,…,headh)WO,
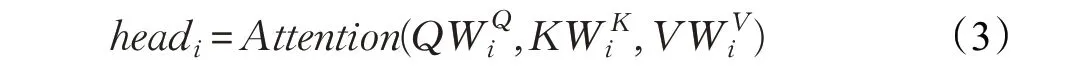

图8 Multi-headed attention模块
由于上下文中的每一个词不仅对于句子的表示贡献度不同,而且不同的上下文词对特定方面词的情感倾向的重要性也是不同的。因此模型有针对性地处理相对重要的单词,即将编码后的外部存储器m(m∈Rd×k)和一个方面词向量vaspect∈Rd×1作为输入,由attention(注意力模型)输出一个连续矢量vec(vec∈Rd×1),再计算输出向量作为每段记忆(每个存储器m)的加权和,即:

其中K是记忆量的大小,∂i∈[0,1]是mi的权重且
对于每一份记忆mi,使用前馈神经网络来计算它与这个aspect的语义相关性。评分函数计算如式(5):

其中Watt∈R1×2d,batt∈R1×1。得到{g1,g2,…,gk}后,将其代入一个softmax函数来计算最后的重要分数{∂1,∂2,…,∂k},如式(6):

最后一层中的文本表示为情感分类的特征。由于每个组件都是可微的,整个模型可以通过梯度下降进行端到端的有效训练,其中损失函数是情感分类的多分类交叉熵(categorical_crossentropy)如式(7):

6 实验结果与分析
6.1 数据集与实验参数
为了达到预期效果,实验数据集使用经过预处理的40 000条IT产品评论数据以及公共数据集Restaurant。深度记忆网络模型的训练过程中,批大小(batch_size)设置为32,迭代次数设置为4,同时使用初始值为0.9,学习率为1E-3的Adam优化算法来训练模型。
为验证本文提出的模型在文本分类上的效果,本文采用深度学习框架Keras进行实验研究。服务器配置如下:
14.04-Ubuntu,CP为Intel酷睿i7-5820K处理器,主频3.30 GHz,32 GB内存,GPU为NVIDIAGeForce GTX970,4 GB显存。
6.2 实验结果与分析
如表4所示,本文提出的面向方面的深度记忆网络模型,在公共数据集Restaurant[21]的分类准确率相比模型LSTM、TDLSTM+ATT[22]和ContextAVG模型都所提升。同时,实验通过叠加计算层的层数来测试模型的性能,可知计算层数增加时,模型准确率有明显下降。
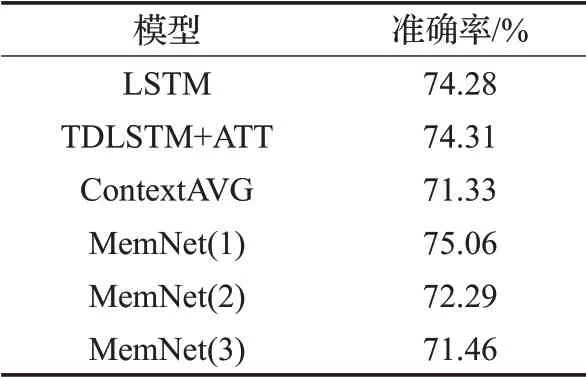
表4 模型在不同计算层下的准确率
同时,实验对IT产品评论数据集进行面向方面的细粒度情感分析。在依存句法分析获取的方面-情感词对的基础上进行人工处理得到10 000条数据用来训练模型,然后对余下的数据进行基于方面词的情感分类预测。实验部分结果如图9与如表5所示,不仅可以得到当前用户对于IT产品集中关注点,还可以得到具体产品的情感倾向与量化值。譬如“显示器”的评价偏向于正向,而“散热器”的评价尤其是在“风扇”属性方面用户情感偏向于负向。因此,根据用户对IT产品的情感需求,未来在IT产品制造与设计方面,需要侧重于散热方面尤其是在风扇上性能的改进。

图9 部分评价对象的情感指标

表5 部分评价对象的不同属性的情感指标
7 总结
本文提出了一种面向方面深度记忆网络的细粒度情感分析方法,通过引入self-attention机制来对依存句法分析提取的方面词进行情感分类,进而量化情感指标,从中得到用户对产品的集中关注点以及相应的情感倾向与量化指标,实验表明该方法在IT产品细粒度情感分析方面有着良好的效果,有助于为产品设计者、制造商和管理者提供详细的决策信息。
本文仅涉及自然语言处理应用和领域需求分析研究的主要部分,这是一个复杂而广泛的主题。未来,不仅将对产品评论数据的方面词抽取和分类的准确性再进一步深入的研究,同时也会研究构建以用户需求为导向的评价体系。将情感和需求分析相结合并将其应用于特定的决策应用是一种具有生命力的方向。
猜你喜欢
红外技术(2022年11期)2022-11-25
小猕猴智力画刊(2022年3期)2022-03-29
数学小灵通(1-2年级)(2021年4期)2021-06-09
作文周刊·小学一年级版(2021年48期)2021-01-04
安阳工学院学报(2020年2期)2020-06-05
少年文艺·开心阅读作文(2018年1期)2018-01-19
Coco薇(2017年11期)2018-01-03
电脑知识与技术(2017年26期)2017-11-20
暨南学报(哲学社会科学版)(2016年9期)2017-01-15
信息安全研究(2016年3期)2016-12-01
