
可编程数据平面的业务相关路由方法
2020-02-19 14:08吴博,吴静,罗威,朱劼
计算机工程与应用 2020年3期
吴 博,吴 静,罗 威,朱 劼
1.武汉大学 电子信息学院,武汉430072
2.中国舰船研究设计中心,武汉430064
1 引言
面对越来越丰富的网络业务,人们对于网络服务质量的要求也不断提高。如何灵活调度网络资源,实现特定业务流量的路径规划成为一个问题。软件定义网络中将交换机的控制和转发解耦,形成一种由数据面、控制面和应用面组成的三层架构。控制器具有全局逻辑视图,交换机成为简单的转发设备,实现了对网络进行集中式的管理。
在SDN框架下,控制器对网络节点进行全局的控制,通过对网络状态的收集,实现了对数据流的全局调度。文献[1]提出一种方法,根据链路间的距离、带宽等因素周期性地更新网络状态,计算出多条路径,然后在其中选出一条链路利用率最小的路径进行流量传输,即使网络出现故障也可以动态调节,但是该方法没有考虑业务的属性;文献[2]通过SDN控制器对数据层的网络节点进行探测,根据链路带宽,应用ECMP实现路由选路,提高了网络的负载均衡度;文献[3]使用链路的时延带宽作为选路约束,将问题抽象为多约束问题,对于优先级别高的数据进行优先路由,但是这种方法只保证了一种数据流的属性;文献[4]通过在控制器中实行基于DPI的流量分类技术,根据流的需求,动态分配带宽给流,从而提高流的QoS,但是控制器运行dpi引擎需要较高CPU资源,当网络繁忙或网络规模大时,控制器负荷较大。文献[5]通过控制器向交换机发起packet_in指令获取流的ToS字段,以此判断业务类型并利用K最短路径算法为该业务进行路由,但是此方法需要控制器对于每条流都发起询问,效率很慢。以上方法普遍通过控制器的全局视野,利用获取到的网络参数,在算法上进行改进实现路由规划,数据平面只是作为单纯的转发设备进行转发操作,在处理流量时,并没有为流量业务属性进行快速的划分。
可编程数据平面[6]拓宽了对网络自定义的能力。通过改进可编程数据平面的处理流水线,对解析器、匹配器和处理器进行编程,可以实现对业务的识别;同时,可编程数据平面支持对TCP/IP协议外的新型网络协议数据包的处理,可以实现数据包本身对网络状态进行采集。这为网络带来了巨大的灵活性。
根据3GPP对网络中数据流的分类,可分为:信息会话类业务、数据传输类业务、流媒体业务、网络交互类业务[7]。根据业务类型的不同,数据在网络传输中会有不同的传输需求。例如,对于会话类型的业务,此类业务数据量一般较小,但是需要保证业务数据及时的交付,因此此类业务要求传输延时一定要小,而对带宽没有特殊的要求;而对于类似文件传输、视频点播这种业务,由于其传输的数据量大,因此对网络的带宽有较高的要求,而对时延并不敏感。
本文在SDN的框架下,结合可编程数据平面的特性,通过重新定义交换机处理数据包的流程,提出一种基于业务属性的路由方法,可以在数据平面上实现业务的自动区分和网络链路状态的收集,并在控制面上为不同业务选路。最后通过搭建实验平台验证了本文所提方法的可行性和有效性。
2 方案分析与设计
为了实现一种业务相关的路由选路,需要考虑以下问题。
(1)首先,为了分担控制面上的处理压力,应该如何在数据面上协助实现业务流量的自动识别。
在SDN架构下,数据面上的交换机是一种白盒设备,往往仅做匹配转发动作,自身并没有决策能力,所有分析决策能力被集中在控制器上,这就导致了控制器的处理压力巨大。并且交换机将功能固化在芯片中,严重依赖于厂商,在协议扩展上不具有灵活性且更新周期长。而在可编程数据平面上,由于不再受限于传统的TCP/IP协议栈的束缚,可以自定义数据包的结构,通过改变交换机处理数据包的业务逻辑,识别包头中的特定字段,就可以实现数据面对于流量的自动识别,分担了控制面的处理压力。
(2)其次,在获取网络链路参数时,应该如何确保信息的时效性。
为了能够保证业务传输的需求,只有获取了网络的状态参数,才能以此作为依据为业务数据选择一条符合传输要求的路径。对于网络链路参数的采集[8],大多普遍采用南向接口,例如通过OpenFlow轮询获取交换机的信息推算出链路的状态[9];或者通过在交换机上安放sflow周期性采样[10];或者通过额外流量探针探测网络的状态[11]。这些方法收集的数据细粒度大,准确度低,不能很好地反映当前的网络状态。而在可编程交换机上,可以在数据包上嵌入所需要的交换机内部信息,例如时间信息、队列信息、出口计数器的信息等[12],这样每当数据包流经交换机,测量信息随着业务流量进行传输。由于测量数据为传输过程中交换机本身的数据,细粒度高,可以很好地反映网络的状态。
(3)最后,如何针对特定业务,规划出适合不同业务的路径。
不同业务在传输中对网络状态的要求不同,为了能够实现在全网中根据业务的要求进行选路,需要针对性地改进选路算法。在算法中,面对不同业务类型的流量,特定的改变算法中的约束条件,使之规划出的路径能够满足传输要求,保证业务质量。
基于上述问题,在数据面上采用可编程交换机,发挥可编程交换机的可自定义的优势,利用P4[13](Programming Protocol-Independent Packet Processors)语言对其进行编程,改变数据转发流水线的逻辑,实现业务流量的自动划分,分担控制器的处理压力,同时对网络链路的状态参数进行采集;在控制器上根据收集到的链路状态信息,由选路应用为不同业务规划路径。因此本文提出的基于可编程数据平面的业务路由(Business Routing Based on Programmable DataPlane,BR-DP)总体框架如图1所示。

图1 总体架构图
3 方案实现
3.1 业务分类与识别
在数据包的IP包头中存在6个比特的DSCP字段,用于区分服务代码。利用这6个比特可以将业务分为4个类型[14],如图2所示,分别是类选择器CS、加速转发EF、确保转发AF和默认BE。典型的DSCP值有流式视频CS4(100000)、交互式语音EF(101110)、大块数据AF11(001010)等。

图2 DSCP分类图
为了能够在交换机内实现对业务种类的识别并进行相应的操作,需要在原有转发基础上改进交换机对于数据包的处理流水线,增加对特定字段的匹配操作实现对业务的识别,在识别到业务属性后将流分配到不同流表中执行对应的转发规则,整个处理流程如图3所示。在整个流水线中,可编程交换机对数据的处理基于“匹配-动作”模式。
首先,进入“匹配”阶段,为了能够自动识别流量的业务类型,在匹配过程中,包头解析器不仅需要提取数据包的源地址、目的地址、源端口和目的端口用于基本的转发,而且要添加对DSCP字段的获取。通过对DSCP字段进行匹配,交换机可以实现对业务种类的自动识别。当识别到流量所属业务类型后,就要进入“动作”阶段。
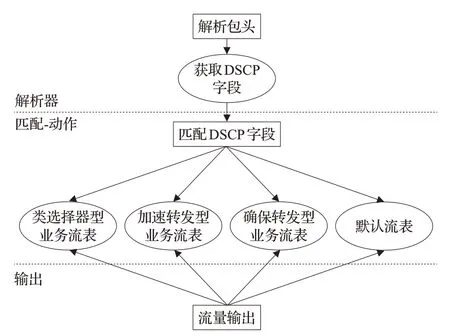
图3 业务处理流程图
在动作阶段中,要在交换机中定义不同的流表,如类选择器型业务流表、加速转发型业务流表、确保转发型业务流表和默认流表。每个流表对应着不同DSCP类型的业务。上层控制器上的选路应用会为不同属性的业务规划出相应合适的路径,并以流规则的形式通过南向接口分发至对应的流表中,指导数据包的转发规则。数据包在匹配阶段中识别到流量业务属性后,根据业务的属性,由交换机将数据流分配到不同的流表,并按照流表中的转发规则进行相应的转发。
3.2 链路状态信息收集
为了给接下来的选路应用提供选路依据,需要对网络的链路状态信息进行采集。在可编程数据平面上,可以通过数据包本身携带测量信息的方式或者控制器通过南向接口采集的方式,得到多种网络状态参数,例如时间、队列、端口信息等。本文选取时间敏感的语音业务和带宽敏感的视频业务为例进行说明,对网络的链路延时和剩余带宽容量进行采集。
3.2.1时延测量
时延在为对时间敏感型的业务路由规划时是一项重要的参照指标。本文对于每跳链路的时延采集采用带内测量的方式。首先,利用P4语言编写可编程交换机处理数据包流程,根据需求,可以指定需要测量的具体指标,每个交换机根据指令会将相应的指标嵌入到数据包中。编译好的文件经由控制器通过南向接口部署到每台交换机上。其次,控制器具有全局视图,可以获知交换机是否处于数据包传输路径上的边缘节点。当正常的数据包进入到网络中,在开始的边缘节点交换机上会被打入带内测量指令标签。然后,数据包流经每台交换机,交换机根据指令,将自己的内部信息封装到每个包头里。最后,在最后一跳交换机上,控制器识别并指导交换机弹出带内测量信息报告,剩余部分恢复为正常数据包交付到目的主机,流程如图4所示。
当数据包通过每个交换机时,交换机在每个数据包头上嵌入此数据包从入口进入交换机的时间戳,那么数据包从这一跳的i交换机到下一跳的j交换机的链路延时dij如公式(1)所示,其中包括了这一跳链路的处理延时、排队延时、传输延时和传播延时。

图4 带内测量示意图

3.2.2 剩余带宽测量
每条链路的剩余带宽对于带宽敏感型的业务流量有重要意义。在可编程交换机中,通过编程在每个表项添加一个计数器counter。每完成一次流表项匹配操作后对计数器进行更新,这样就可以记录每个端口流经的包的个数和比特大小。在每一个测量周期Δt内,通过南向接口命令来获取counter的值,在每次获取到值后再将counter清零,以此来记录这段测量周期内流经的数据信息。
对于交换机Si的i端口,在一个测量周期内发送的数据包字节数为tx_bytes,接收到的数据包字节数为rx_bytes,则链路的输入吞吐率和输出吞吐量分别如公式(2)和(3)所示:

那么数据占用的带宽B(Sii)和剩余带宽B_available(Sii)如公式(4)和(5)所示:

3.3 选路实现
3.3.1 算法基础
蚁群算法[15]是一种受启于蚁群觅食行为的算法。相比于传统路由算法,蚁群算法简单,收敛速度快,可以动态地适应网络拓扑的变化,具有极高的适应性和扩展性,且是一种全局搜索算法,能够有效地避免局部最优。
获取到了每段链路的延时和剩余带宽后,就可以构建网络的延时矩阵和剩余带宽矩阵,用延时和剩余带宽取代路径长短的概念,将问题抽象为网络模型如公式(6)描述:

网络中有i个节点,j条边,用图G(N,E)表示,其中节点n1,n2,…,ni的集合为N,表示每个交换机代表一个节点;边e1,e2,…,ej的集合为E,表示每两个节点间的链路。
基本的蚁群算法描述如下,蚂蚁k从i节点到j节点的跳转概率如公式(7):

其中,τij(t)为在时间t时刻链路eij残留的信息素;ηij(t)为选择下一跳为新路径的启发函数;α作为信息素函数的作用系数,表示在蚂蚁选路的过程中信息素的影响能力;β为启发函数的作用系数,表示选路过程中受启发函数的影响能力。对于作用系数来说,如果α越大,信息素的影响力就越强,会造成局部最优的状况,而β越大,启发函数的影响能力越强,选择路径时更加随机,会造成收敛慢的状况。nodesk为蚂蚁下一跳可选的路径节点集合,为了防止蚂蚁走回路状况的出现,每当走过一个节点,就从nodesk集合中剔除这个节点。
在寻路过程中,蚂蚁走过的路径会留下信息素,而信息素也在不停的挥发,因此,网络中路径的信息素会不停的更新。因此信息素按照公式(8)和(9)进行更新。

其中,ρ为挥发系数,(1-ρ)为信息素剩余系数,因此下一时刻的信息素浓度为上一时刻剩余信息素浓度与信息素浓度增量的和。其中Q为信息素浓度强度,Lk表示蚂蚁k所经过的路径长度。
3.3.2 参数重定义
在经典蚁群算法中,路径长短作为影响因子。为了适应对于不同业务传输过程中的不同的需求,引入获取得到的链路指标作为选路的参考信息。在判定业务类型后,将对应的网络性能参数运用在启发函数和信息素更新的计算中,实现对不同业务的路由。
针对不同业务在网络传输中的需求不同,对应改变算法中的参数设置。当业务判定为时延敏感的语音业务时,令启发函数ηij(t)=1/dij(t),信息素更新函数中的Lk为所经过路径的延迟之和,表示延时越低,留下的信息素越多;当业务判定为带宽敏感的视频业务时,令启发函数ηij(t)=B_availableij(t),信息素更新函数中的Lk为所经过路径的剩余带宽之和的倒数,表示剩余带宽越多,留下的信息素就越多。
3.3.3算法流程
基于业务性质的选路步骤如图5所示。

图5 算法流程图
根据不同的启发函数,分别为时延和带宽生成两条最优路径,通过控制器分别下发到路径上的交换机的对应的流表中。当数据经过交换机时,交换机会匹配包头中的DSCP字段,判断数据包所属的业务类型,然后执行对应流表中的转发规则,以此实现流量的业务属性自动识别和转发。
4 实验与评估
4.1 仿真平台搭建
园区网中承载着文件传输,视频点播,语音聊天等各种业务,为了模拟这一场景,验证本文方法的可行性,利用mininet搭建小型网络拓扑,其中使用的交换机是支持P4语言的bmv2交换机,拓扑如图6所示。

图6 实验拓扑图
图中包含8台bmv2交换机,设定每条链路带宽为80 Mb/s,延迟3 ms。同时为了模拟真实的网络场景,让H1用iperf分别向H2~H5主机打UDP流量作为背景流量。实验过程中,以H1为发送端,H6为接受端,以5 Mb/s的增幅分别传输DSCP为101110和100000的流量,以此模拟语音业务和视频业务。
配合网络节点的数量,设置蚁群的参数初始值,其中蚂蚁数量为30,迭代50次,信息素和启发函数的启发因子分别为1和5,挥发系数0.5,总量Q为10。根据获得的延时拓扑和剩余带宽拓扑,分别为不同业务生成相关路由规划策略,以流表项的形式下发至交换机中。
4.2 性能比较
对比实验中,数据平面向控制平面发送OpenFlow信息,控制器通过解析ToS字段判定业务属性;并通过对OpenFlow携带的信息进行处理,获取到链路的状态,而控制器的选路采用蚁群算法,称这种基于OpenFlow的方法为BR-OF。另一个对比实验中,业务的判断以及网络状态的采集同样采用OpenFlow信息获取,而控制器的选路应用采用K最短路径算法,利用多元素的路径权值进行路由规划,简称为BR-K。本文设置四个对比实验,分别从端到端响应时间、时延和吞吐量比较三种方法在业务识别时的响应速度和最终的选路效果以及在本文方法下不同业务的表现。
(1)端到端响应时间比较
首先观察端到端响应时间的表现,即从源主机发送数据到目的主机接收所经过的时间。为了尽量减少链路时延对于结果的影响,让三种方法下路由算法输入的链路参数一致,并采用视频流量进行实验。实验中,对业务流量处理方法不同,导致对业务流量响应的时间也不相同。在BR-OF、BR-K方法中,当数据包输入网络后,控制器会发起OpenFlow请求,通过OpenFlow询问数据流量所属的业务,在判断业务属性后,为该流进行路由计算,在整个过程中,OpenFlow信息的传输和路由计算都会产生额外时间;而本文的BR-PD方法,业务属性的判断发生在交换机解析数据包的过程中,节约了控制器询问的时间;在判别数据所属业务后,数据会执行对应流表中的表项,进行相应的转发,而流表中的转发规则是控制器周期性获取链路状态后预先下放的,这也节约了一部分路由计算的时间。因此由图7可知,在同样的场景设定下,BR-PD的端到端响应时间要明显低于BR-OF和BR-K,同时,随着源主机发送业务速率的提高,响应时间呈上升趋势,这可能由于随着负载的加重,拥塞导致的延时变大。由此可以说明,BR-PD在自动识别业务响应速度方面有一定优势。
(2)延时比较

图7 端到端响应时间
在另一组实验中,观察语音流在不同方法下的延时情况。如图8所示,可以看到BR-PD下的延时明显低于BR-OF和BR-K。这是因为,在BR-OF和BR-K中,链路延时的采集是通过在两个节点间反复发送OpenFlow信息,然后整合这些信息推算出测量时刻的链路延时,推算过程中包含控制器到交换机间的rtt;另外,测量的延时反映的仅仅是测量那一时刻的链路状态,而链路的延时是一个时变的参数,因此BR-OF和BR-K方法获取的链路延时不够准确。并且,BR-K是将多个链路参数加权进行选路的,因此对于只单纯从延时角度看不占优势。而BR-PD方法采用带内测量的方式,延时信息是交换机嵌入的自身实时信息,通过收集测量周期内所有的链路延时并取平均值,可以反映这段时间该链路的延时平均水平,相较于另外两种方法,获得的延时信息比较准确。准确的链路状态信息可以为后续的选路提供准确的参考,因此BR-PD方法可以为时间敏感的语音流提供一条延时较小的路径。
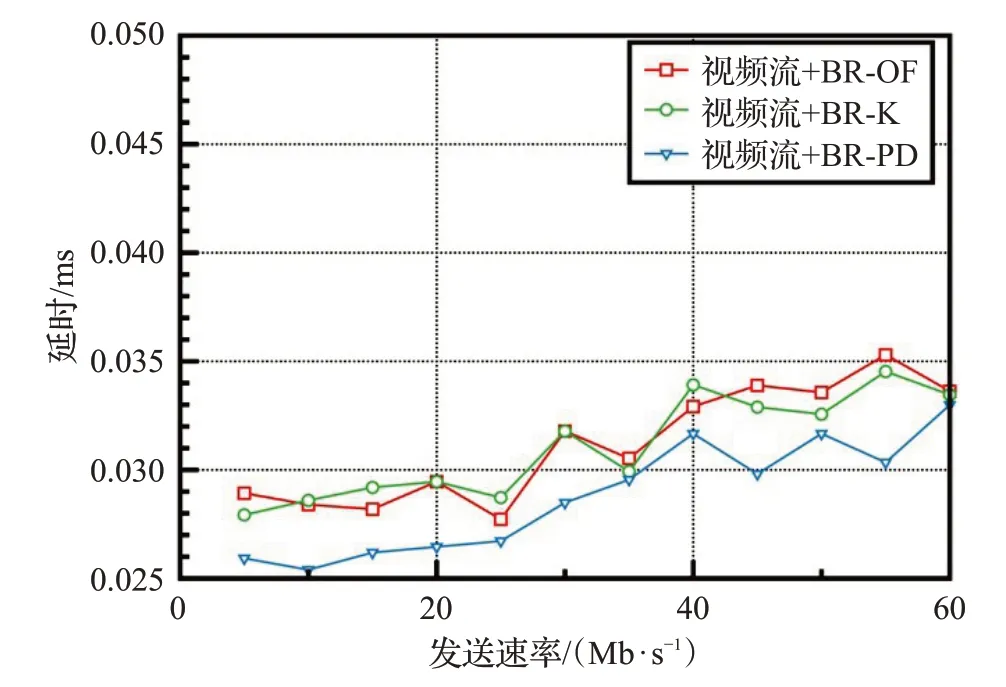
图8 时延
(3)吞吐量比较
在H1向H6持续10 s发送80 Mb/s的视频流量,吞吐量结果如图9所示,可以看到三者的差异并不是很大。这是因为,在获取链路的可用带宽时,BR-OF、BR-K是通过OpenFlow获取交换机端口计数器的数据,而BR-PD是通过可编程交换机的P4Runtime接口获取交换机计数器的数据。三者都是通过南向接口访问交换机获取到链路端口的使用状态,因此三者获取的链路可用带宽信息大同小异,总体上为视频流规划的路径所表现的性能相当,但BR-K是由多参数进行加权选路,单从吞吐量来看结果略逊。

图9 吞吐量
(4)不同业务比较
在BR-PD方法下,对比语音流和视频流两种业务的延时和吞吐量,结果如图10和图11所示。可以得知,该方法可以对不同业务进行相应的路由规划,对于时间敏感的业务,语音流的延时要小于视频流的;而对于带宽敏感的业务,视频流的吞吐量要略大于语音流。

图10 不同业务时延
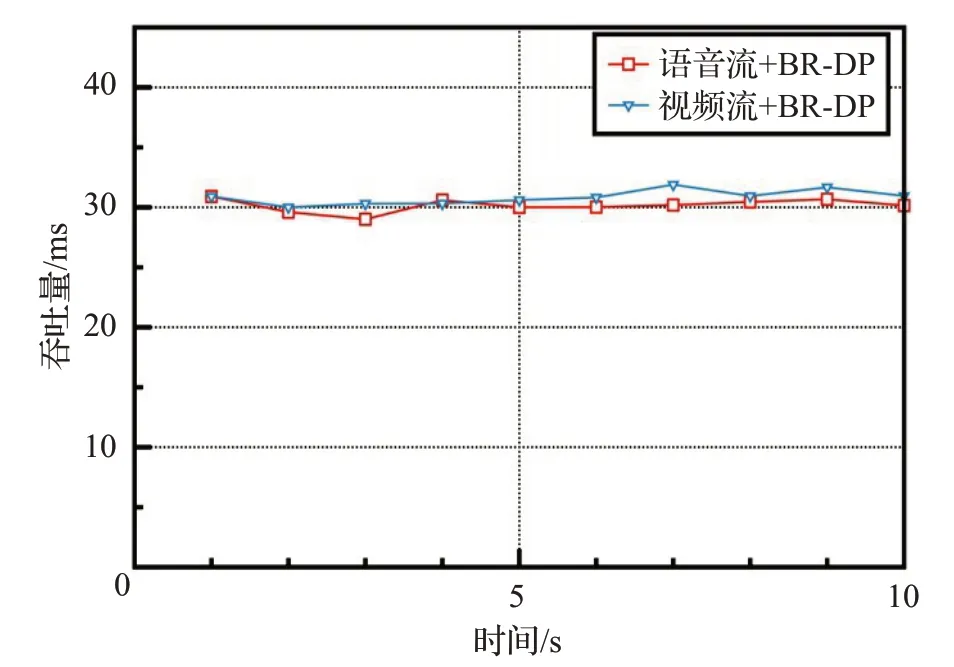
图11 不同业务吞吐量
根据以上的对比结果可以得出,BR-PD方法可以在数据面上快速地自动识别业务流量的属性,并能为选路应用提供时效性网络参数,根据不同业务对于网络的不同需求,可以规划出合适的路径进行传输,满足业务的传输要求。
5 结束语
本文在SDN的网络框架下,发挥可编程数据平面的特性,提出了一种数据面与控制面协作的选路方法。在可编程数据面上,通过对字段进行解析,匹配不同的流表,实现了在交换机上快速自动判别数据的业务属性并进行相应转发;同时通过带内测量的方法,在不引入额外网络负担的前提下,可以统计到网络中各个节点的时效性参数。在控制面上,将网络的实时性能参数应用到蚁群算法中,生成匹配的路由规则并下发至数据面。下一步,将对流量的业务类型做出更细致的区分,并对控制器中的算法进一步优化,使其成为一种更优的路由方案。
猜你喜欢
计算机与数字工程(2022年3期)2022-04-07
民用飞机设计与研究(2020年4期)2021-01-21
自动化仪表(2020年10期)2020-11-13
电子制作(2019年14期)2019-08-20
网络安全和信息化(2019年7期)2019-07-10
电子制作(2019年24期)2019-02-23
物联网技术(2018年8期)2018-12-06
中国公共安全(2017年11期)2017-02-06
船舶力学(2015年6期)2015-12-12
自动化博览(2014年9期)2014-02-28
