
基于深度信息的人体姿态识别研究综述
2020-02-18 15:16李方迪
计算机工程与应用 2020年4期
田 元,李方迪
华中师范大学 教育信息技术学院,武汉430079
1 引言
随着人工智能技术飞速发展以及许多新兴智能科技在人们日常生活中大量普及,在人工智能领域,计算机视觉和人机交互技术具有重要的地位,人体姿态识别在人机交互领域具有重要作用,并且在道路行为监控、人体运动分析、医疗康复训练、舞蹈教育培训等方面都有重要应用前景。根据输入图像的类型,姿态识别又分为基于RGB图像和基于深度图像的方法。彩色图像在复杂环境和光照变化下鲁棒性较差,而用于采集深度图像信息的设备,如Microsoft推出的Kinect设备和ASUS公司的Xtion,性价比高,可以捕捉彩色和深度信息,能够在光线不好的条件下工作,并且可以提供骨骼信息,简化人体检测任务[1]。Li等人[2]综合利用了Kinect提供的深度数据、骨架数据,通过人体测量学知识和反向传播神经网络,有效提高了姿态识别的实时性和鲁棒性。朱大勇等人[3]则利用Kinect摄像机采集人体的骨骼信息以及关节点对应的3D数据来进行动作识别。Reddy等人[4]同样是采用Kinect设备获取深度信息,设计了专门针对坐姿和站姿的人体姿态识别系统。因此,基于深度信息的人体姿态识别技术已成为目前的热门研究课题。
如图1所示,基于深度信息的人体姿态识别的主要步骤分为三部分:首先对深度信息传感设备采集到的图像数据进行预处理,然后提取出相应的人体姿态图像特征,最后采用合适的分类算法进行姿态分类识别。基于深度信息的人体姿态识别技术应用领域十分广泛[5]。例如在游戏领域,通过体感技术来获取玩家的姿态动作进行人机交互操作,能够使游戏玩家摆脱传统游戏交互设备的约束,从而大大提升玩家的游戏体验。在医疗领域,通过深度信息进行自然肢体运动检测,可以使医护工作人员的工作量得到有效减少,并且患者康复训练的效果也得到了有效提高。在教育领域,通过把基于深度信息的人机交互技术融合进课堂教学中,为师生提供了更为自然的人机交互方式。
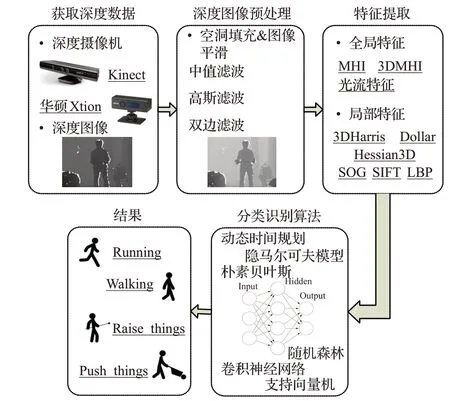
图1 基于深度信息的人体姿态识别流程图
本文对近几年基于深度信息的人体姿态识别研究相关文献进行了归纳梳理,从深度图像预处理、特征提取和人体姿态识别算法三方面进行了研究概述,重点阐述了不同算法在人体姿态识别过程中的主要应用和改进思路。首先,介绍了在深度图像预处理中的空洞填充和图像平滑的研究进展和解决方法;然后,介绍了特征提取的方法以及图像特征的几大类型;接下来,介绍了卷积神经网络、支持向量机、随机森林等算法在人体姿态识别中的应用发展;最后,总结归纳出目前的主流研究方法,根据存在的不足,为未来研究方向提供思路。
2 深度图像预处理
使用RGB-D获取的深度图像信息可以很好地反映目标的三维信息,但是由于测量时受到一些外在不确定因素的影响,在一定程度上会导致采集到的深度信息不稳定,因此深度图像的修复在进行人体姿态识别过程中占有重要地位。为了使数据更加精确,在进行图像特征提取之前,需要对原始的深度图像数据进行空洞修复、图像平滑等预处理操作。
2.1 空洞修复
由于受物体表面的材质、相互遮挡以及阴影轮廓等诸多因素的影响而造成数据缺失或者匹配失败,从而导致了深度图中部分区域的深度测量值为0的情况,也称为黑洞噪声。关于深度图像的空洞修复问题,最简单的处理办法就是利用空洞区域边缘的有效像素点来对空洞部分进行填充。
针对Microsoft公司的Kinect传感器所获取的深度图像,Yang等人[6]提出了一种基于8通道的空洞填充方法。该算法首先将具有8个连通度的空洞聚类,通过分析相邻像素的深度分布,为每个聚类分配一个深度值。该方法在深度颜色信息不相关的情况下,通过赋予适当的深度值,有效地进行了空洞修复。该算法使整个连通域中的像素成为一个整体,并没有考虑每个像素的差异,因而具有一定的局限性。
不同于Yang等人只采用深度信息进行空洞填充的方法,赵旭[7]结合了彩色图像信息,提出了一个能进行自适应处理的迭代联合三边滤波器。即在单帧的情况下,把彩色图像的边缘和深度图像的边缘没有对齐的深度像素点坐标都重置为0,通过该滤波器进行黑洞填充。但是在深度图中如果存在范围较大的空洞,该算法修复的效果并不理想。
对于空洞较大的情况,王福伟等人[8]通过与彩色图像信息结合来引导填充深度图像存在的空洞。首先对深度图中空洞点的具体位置坐标进行定位,然后根据彩色图像的颜色特性具有相似性,来判断空洞点的位置是在前景还是在背景,有效地进行了像素级别的填充。不过该算法对环境背景有一定要求,如果是在复杂背景或者较暗的环境中,算法的处理效果不太理想,导致修复的深度数据可能具有较大的误差。
郑欢[9]对于空洞产生原因进行了详细了解,并提出了一种基于区域大小的黑洞填充方法。首先对深度图像的黑洞进行连通域分析,对由被投射物体表面材质的吸收、折射和反射所产生的黑洞,利用黑洞周围的邻域中值信息来进行填充;对由遮挡产生的黑洞,利用基于区域大小的黑洞填充方法进行修复,其中利用邻域信息对较小的黑洞区域进行修复。
依据空洞区域大小来进行空洞填充的思路,胡天佑[10]根据分割区域里的空洞大小将区域分为没有空洞的区域、空洞较小的区域、空洞较大的区域和全部都是空洞的区域。针对不同的区域分别采用合适的空洞修复策略,空洞较大的区域使用中值填补算法,空洞较小的区域采用快速行进算法进行填补,对于出现的大面积空洞,则通过非局部均值处理,利用邻近相似区域对空洞进行填充。
与之前的空洞填充方法不同,钱锐[11]则把RGB-D摄像机同步采集到的彩色图像利用C-means聚类算法进行区域分割,从而使物体的结构信息在目标场景中更加明显,通过邻域内的同类像素来不断对边缘空洞点进行填充,使有效像素值不断向空洞内部扩散,最后完成全部空洞区域的修复。
目前的空洞填充方法大多数都是基于空间相关性的思想,也就是利用深度图周围像素的深度值来估计空洞部分的深度信息,从而达到空洞修复的目的。然而空洞区域由于大小和背景环境存在差别,同一算法对不同的空洞区域修复效果也存在区别,同时对于处理大量深度图像信息的情况,空洞填充算法的性能也至关重要,耗时太长也会对后续识别效率有所影响。因此,空洞填充方法的普遍性和鲁棒性有待进一步提高。
2.2 图像平滑
深度摄像机获取深度图像时会存在一些常见的噪声,例如椒盐噪声、高斯噪声等,通过抑制噪声对图像的影响使图像亮度得到改善的方法就是图像平滑。图像平滑常用的方法就是对其进行滤波操作,图像处理领域常用的滤波有中值滤波、高斯滤波、双边滤波等。中值滤波(Median Filter,MF)处理椒盐噪声的效果比较好,但是对深度图像中高斯噪声滤波效果不好;高斯滤波(Gaussian Filter,GF)虽然能够有效地平滑深度图像,但会丢失深度图像的边缘信息;双边滤波(Bilateral Filter,BF)可以在滤波的同时保留原始图像的一些边缘信息,但是往往会带来伪边缘效应,同时不能够有效地去除外点,并且计算量相对较大。
针对双边滤波存在的权值不稳定性问题,联合双边滤波(Joint Bilateral Filter,JBF)在双边滤波器的思想上进行了拓展,将指导图像替换为另一个特征比原图像清晰的图像,用来获取图像像素值之间的权重系数。Feng等人[12]将空域距离原则和彩色图相似原则进行了结合,提出了一种能够自适应噪声平滑的联合双边滤波。
为了改善联合双边滤波在原始场景中深度信息的精确度,余亚玲等人[13]提出一种新的预处理算法。通过构建深度图的测量和采样模型,从而得到深度图的蒙特卡罗不确定度评价模型,然后利用计算的深度值估计区间来判定和滤除深度图像中的噪声点和非噪声点,从而达到修复噪声点的作用。
深度相机和彩色相机之间的立体匹配误差使得其成像结果之间存在一些偏差,这就使得深度图像的物体边缘信息和彩色图像中的物体边缘信息并不相同。因此Jung[14]使用了自适应的联合三边滤波器来对深度图像和彩色图像进行增强,并且提出了一种基于二值模式的块匹配方法,对深度图像和彩色图像进行块匹配,然后根据块之间的相似度,依次对彩色图像和深度图像进行联合三边滤波。
不同于以上算法,基于全局的图像增强方法通常可以保留更多整体结构信息。Diebel等人[15]最先提出了一种基于马尔可夫随机场的深度升采样方法。Park等人[16]通过改进原始马尔可夫随机场模型中的平滑约束项,并使用彩色图像的分割信息以及彩色图像的梯度信息作为新的约束项,解决了之前方法处理结果中的深度图像边缘过平滑的问题。Kim与Yoon[17]使用双向图像梯度作为权重项对马尔可夫随机场模型的平滑项进行修改,消除了深度图像中由物体边界区域的噪声造成的影响。
图像平滑是深度图像预处理的关键环节,针对深度图像存在不同的噪声类型,采取合适的滤波器进行图像平滑处理具有重要的意义。不过图像平滑处理也应适度保留特征信息,不能过度平滑,否则会对最后的图像识别结果造成一定的影响。
3 特征提取
从图像序列中将描述人体姿势的有效特征提取出来是保证准确识别动作的重要前提[18],不同特征的效果会与目标跟环境的特性具有很大的关联。同一特征对于不同类别动作的描述能力会有些差异,不同特征对于同一类别动作的描述能力也参差不齐,特征描述根据不同特点可以分类为全局特征描述和局部特征描述[19],因此如何根据已有的数据信息和识别目标来选择合适的特征描述符是人体姿势识别的关键。
3.1 基于全局的特征描述
全局特征描述就是采用一种自上而下的描述方式,把识别目标当作一个整体[19]。全局特征涵盖了全面的人体信息,由于容易受到识别目标定位的准确性以及背景剔除等图像预处理的影响,全局特征描述也具有一定的局限性,例如对噪声、遮挡以及摄像机视角变化等因素十分敏感。
轮廓和形状特征是两种比较常见的全局特征描述。Bobick等人[20]以两种方式把监测视频里运动目标的轮廓变化信息聚合成二维图像,采用运动历史图(Motion History Image,MHI)来反映不同姿势在运动过程中存在的先后顺序。Ni等人[21]在MHI的基础上提出了三维运动历史图(3D-MHI),也就是在原来运动历史图的基础上增加了两个附加的通道,分别是前进的运动历史图和后退的运动历史图。Liang等人[22]把运动历史图扩展到三维图像,并提出了三维运动轨迹模型(3D Motion Trail Model,3DMTM)。
除此之外,也可以采用光流轨迹来代替形状信息,光流特征能够利用图像序列中像素在时间维度上的变化和相邻图像帧之间的相关性来描述目标的运动特征,且不依赖于环境背景的减除。也就是说,光流特征表示的是时变图像中识别目标的运动速度,但是光流特征会受到动态环境背景的噪声影响[19]。
3.2 基于局部的特征描述
局部特征描述是一种由下到上的描述方式,就是只提取运动目标中有用的部位,将观察目标视为一个局部描述子或者局部图像块的集合[19]。与全局特征对比,局部特征不会随着环境背景噪声、物体遮挡或者人体运动的变化而改变,对尺度、平移和旋转等动作也具有较好的稳定性。局部特征的提取一般分为局部特征区域的检测和对局部特征区域描述两部分。
3.2.1 时空兴趣点
局部特征区域检测中比较常用的方法就是检测局部的时空兴趣点。时空兴趣点一般是由运动突变引起的,在运动幅度较大的地方含有丰富的信息。3DHarris、Dollar、Hessian3D是三种比较常见的时空兴趣点检测器。
其中3Dharris是Laptev[23]提出的,它是为了检测在局部的时空维度里运动目标同时产生较大变化的点,将二维Harris角点检测扩展到了时空域。为了改善3DHarris检测到的稳定兴趣点特征分辨力较低、不利于识别的问题,Dollar等人[24]通过将输入的视频序列进行高斯平滑和一维Gabor滤波,从而提出了一种新的检测算法。Shotton等人[25]保留了Harris检测子尺度不变的优点,把二维的Hessian算法扩展到三维图像当中,提出的Hessian3D检测算法也可以和Dollar检测子一样获得稠密的兴趣点。
3.2.2 局部描述子
梯度分布的描述子是局部特征区域描述中最常用的方法,它的基本思想是不用知道梯度或者边缘精确的位置信息,而是通过局部强度梯度的分布或者目标边缘方向来对局部目标的外观和形状进行特征描述。
Lowe[26]首先提出了尺度不变特征变换(Scale-Invariant Feature Transform,SIFT),利用阶梯式的滤波方法来确定不同空间中尺度变化都比较突出的关键信息点。Scovanner等人[27]在SIFT的基础上提出了能够很好地描述三维数据的时空信息,并且具有良好性能的3DSIFT描述子。
为了实现人体检测,Dalal等人[28]提出了基于统计图像密集局部单元格中梯度方向的直方图特征(Histogram of Oriented Gradient,HOG)。HOG特征能够对运动目标的局部形状信息进行很好的描述,鲁棒性较好。Kläser等人[29]在HOG的基础上提出了计算三维梯度并且对时间与空间方向上的梯度进行量化的HOG3D描述子,HOG3D能够很好地描述运动特征信息。
针对SIFT和HOG只能描述局部图像的零阶统计量这一问题,Li等人[30]提出了一种利用多变量高斯函数将每个像素点与其邻域相关联来表示局部图像一阶和二阶统计量的L2EMG(Local Log-Euclidean Multivariate Gaussian)描述子。L2EMG既可以表示局部图像的低阶统计量,也可以表示局部图像的高阶统计量。Shi等人[31]根据L2EMG描述子可以表征图像的高阶统计量的优点进行特征提取,并且使用宽度学习算法进行学生学习姿态识别,取得了很好的效果。
Ojala等人[32]提出了一种可以描述图像的局部空间结构的局部二值模式(Local Binary Patterns,LBP)。LBP描述子在纹理特征的分类中有很好的区分能力,运算简单,计算效率高,并且不受旋转和灰度的变化影响。为了在每个关节节点附近的局部区域提取深度外观信息,Wang等人[33]提出了能够提取交互物体的尺寸、形状等信息的局部占有模型(Local Occupancy Patterns,LOP)。LOP是针对每帧图片中每个骨骼关节节点周围的局部三维空间进行特征提取工作。
4 姿态分类识别算法
分类器是姿态识别过程中最后也是最关键的一步,根据表征人体动作的特征向量进行训练,从而给每一个被测对象进行不同类别的标记。根据选取的特征描述来选择合适的姿态识别算法具有重要意义。在姿态分类识别中,主流的分类算法有动态时间规划、隐马尔可夫模型、支持向量机以及卷积神经网络等方法。
4.1 动态时间规划法
动态时间规划(Dynamic Time Warping,DTW)最早应用于语音识别中,主要用于孤立词的识别,在姿态识别中可以解决不同目标完成动作的时间长度不一的问题。DTW属于模板匹配算法,通过给定距离矩阵,找到一条从左上角到右下角的路径,以便路径传递的元素值之和最小。
针对DTW算法在每次运行时都要规划路径,存在巨大的计算量和占用大量空间等问题,何剑彬等人[34]对DTW算法进行了改进,提出了一种新的全局路径窗口,减少运算量且不降低正确率,但对于肢体遮挡问题具有局限性。针对动态时间规整在动作识别中存在时间结构突变、光照变化敏感等不足,方云录等人[35]提出了一种改进的动作识别算法。该算法利用DTW对图像序列抽样形成的随机时间规整反复进行随机抽样,提取序列数据的时间弹性TE特征,然后采用主成分分析(Principal Component Analysis,PCA)降维生成序列子空间,最后利用线性判别分析完成姿势识别,不过对于运动姿态识别率不高。针对DTW算法在人体动作识别中的时效性问题,桑海峰等人[36]提出了一种快速动态时间弯曲距离算法,有效地解决了动作序列在时间轴上扭曲问题,并为了加快识别速度提出了下界函数和提前终止技术。但由于动作库局限性,该算法只能识别自定义动作,在人机交互中存在一定局限性。
4.2 生成模型
隐马尔可夫模型(Hidden Markov Model,HMM)是一种关于时序的概率模型,有两个独立的假设:一个是随机过程假设,即每个隐含状态序列发生与否只与前一个状态有关联;另一个是观察状态独立假设,即观察状态的序列之间相互独立,每个观察状态只与当前对应的隐含状态有关系,与其他隐含状态无关。针对传统的基于混合高斯的隐马尔可夫模型(GMM-HMM)的动作识别,杨世强等人[37]提出了基于深度置信网络的隐马尔可夫模型(DBN-HMM),由训练好的深度置信网络(Deep Belief Networks,DBN)模型结合GMM-HMM模型获得的状态转移概率矩阵求出更准确的观察概率,从而对动作序列进行识别,不过该方法对于不同动作鲁棒性较差。
在假设选取的特征之间存在强独立关系的情况下,朴素贝叶斯分类器(Naive Bayesian Classifier,NBC)是一种基于贝叶斯定理的简单概率分类器。对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。陈平平等人[38]对传统朴素贝叶斯算法进行了改进,通过数据分析方法对康复训练动作进行分析,从而针对不同人群进行阈值计算,处理掉在阈值误差范围外的动作关节点信息,由此提高人体姿态的识别率,但是识别对象局限于中风患者,缺乏普遍性。
4.3 判别模型
与生成模型相比,判别模型不仅需要的样本数量较少,且准确率也较高,大大节约了计算资源。由于不需要求解不同类别的条件概率,简化了学习问题,但是当样本数量较多时,收敛速度没有生成模型快。
4.3.1 传统分类器
随机森林(Random Forest)是由一组相互独立的决策树所组成的组合分类器,预测结果是由每棵决策树对预测值进行投票而决定的。随机森林学习框架主要包括四部分:随机选择样本,随机选择特征,构建决策树,根据决策树的投票情况进行分类。在原有基础上,许多学者进行了创新改进,例如蔡轶珩等人[39]提出了一种多级随机森林整合算法,其算法流程首先是采用排列组合思想对各分类结果进行两两求与运算,同时保留相同的分类点,去掉不同的分类点;然后考虑不同分类结果之间的差异性,针对第一阶段的整合结果依次进行求或运算,最终可以得到更加准确的动作识别结果。该方法鲁棒性好,但是对于遮挡情况的处理效果不好,实时性有待证明。
支持向量机(Support Vector Machine,SVM)是机器学习领域最常用的一种分类方法,它的目标是找到一个最大限度分离两个类别的二分类超平面。因其在图像分类方面具有良好的性能,支持向量机也是常用的姿态识别分类器。使用SVM进行姿态识别的文献很多,例如Manzi等人[1]利用X-means算法提取关键位姿特征,经过自组织特征映射网络优化训练后采用多类SVM进行分类识别。该方法识别准确率高,但是不能识别数据集以外的未知动作。
4.3.2 卷积神经网络
由于随机森林和支持向量机等传统分类算法对输入的深度图像有一定要求,无法对原始的图像进行处理运算,因此卷积神经网络(Convolutional Neural Networks,CNN)具有很明显的优势。卷积神经网络是一种前馈型神经网络,由于该网络避免了对图像的复杂前期预处理,可以直接输入原始图像,因而在姿态识别领域也获得到了广泛应用。Mohamed等人[40]利用RGB-D相机提供的不同类型的视觉数据,分别采用SVM和CNN两种方法进行了对比。SVM使用的是RGB-D相机提供的3D基础骨骼特征,CNN使用的是2D深度图像。最后在FLIC数据集和LSP数据集上的实验结果表明,这两种方法具有相当的性能和较高的精度,在深度图像上应用时,基于CNN的方法略胜一筹。
针对提取图像特征时不同图像区域和提取出的不同抽象特征被平等对待的问题,赵勇等人[41]在CNN基础上,根据图像的全局特征和局部特征来计算关节的最终定位概率,从而进行动作识别。实验结果表明,此算法收敛速度更快,在FLIC数据集和LSP数据集上测试的平均估计准确度也有所提升,但是此算法在人体各关节位置变化较快的情况下识别率并不高,具有一定的局限性。在赵勇研究的基础上,韩贵金[42]提出了一种基于改进CNN和加权SVDD(Support Vector Data Description)算法的关节外观模型,并将其用于人体姿态估计。该算法对各个部位的估计准确度都具有一定的提升,但是当人体关节存在遮挡时,识别率不高。
Eleni等人[43]将卷积神经网络与长短期记忆网络(Long Short-Term Memory,LSTM)相结合用于手势识别,取得了不错的效果。与之类似,张儒鹏等人[44]将Inception卷积神经网络进行了优化,设计了用多个小卷积核替换一个大卷积核的O-Inception结构,并且与LSTM进行了结合,提出了一种基于OI-LSTM神经网络的姿态识别模型。该模型在WISDM数据集和UCI数据集上都具有较高的识别率和鲁棒性,但是由于测试数据集的差异性,该模型性能的普遍性有待进一步研究。
4.4 主流算法优缺点分析
对于姿态识别主流算法,不同的算法由于自身算法结构的差异性,以及特征提取的不同,所使用的范围也具有一定的差异,不存在绝对完美的算法,使其能够适用所有的分类问题,因此要使人体姿态识别效果达到相对较高的水平,根据不同的特征条件和适用范围选取合适的算法具有重要意义。表1对本文提到的不同改进算法进行了总结。

表1 基于深度信息的人体姿态识别常用算法
5 存在的问题及展望
本文通过广泛调研基于深度数据的人体姿态识别相关文献,从深度图像预处理、特征提取以及姿态分类识别算法三方面进行了总结概述。对于RGB-D摄像机采集到的深度图存在空洞、噪点等问题,介绍了联合双边滤波器、自适应迭代联合三边滤波器、基于马尔可夫随机场的深度升采样等方法来进行空洞填充和图像平滑;对描述人体姿态的不同特征进行了分类介绍,例如光流特征、MHI、3DHarris以及SIFT、HOG等特征并进行姿势特征提取;从动态时间规划法、隐马尔可夫模型、支持向量机以及卷积神经网络等方法介绍了目前主流的姿态识别分类算法。
基于深度信息的人体姿态识别具有很大的发展前景,但要使人体姿态识别方法走向实用化,还有以下问题亟需解决。
(1)多人姿态识别
目前大部分文献研究的重点都是单人姿态识别,多人姿态识别要比单人姿态识别的难度大,在许多应用环境中,多人姿态识别也有较高的重要性。例如在课堂上对不同学生个体进行姿态识别和学习分析时,需要多人姿态识别技术,实时监测学生的学习情况。同时,多人姿态识别在道路交通安全方面也有很大的应用价值,通过多人姿态识别技术可以在道路监控中对行人动作进行检测,及时反馈危险行为信息。因此,多人姿态识别方面需要进行更多的创新和提升,如何提高识别准确率使其能够达到应用的标准将是未来研究的热点。
(2)肢体遮挡问题
由于目前姿态识别算法对静止物体的识别相对简单,但是对于运动的人体就存在肢体遮挡问题。在人机交互领域,运动姿态的识别具有很大的应用前景。由于人体运动存在着复杂和不规范的问题,在使用RGB-D摄像机采集数据时,如果出现肢体遮挡情况,很容易影响识别结果的准确性,因此对肢体遮挡修复算法的研究具有重要作用。例如李昕迪等人[45]将人体运动结构简化为骨架运动,通过计算骨骼长度范围对人体关节点运动范围进行约束分析,最后通过几何原理修复了被遮挡关节点的位置信息。不过邓益侬等人[46]提到人体动作具有时间连续性,姿态连续性信息可以对遮挡修复问题提供另一种解决思路。
对于复杂的人体姿态识别,肢体遮挡是一个常见的问题。目前对于骨骼信息的遮挡修复研究取得了很大的进步,但是由于不同的人在同一个姿态上的表现也会存在一定的差异性,需要研究更具有鲁棒性的算法,从而提高人体姿态的识别率。
(3)头部姿态和手部姿态识别
人体姿态包含头部姿态和手部姿态,但是在识别过程中并没有重点关注头部和手部具体的动作。陈甜甜等人[47]对目前基于深度信息的手势识别方法进行了总结,提出在特征选择和复杂手势方面都存在一些热点问题有待研究。对于头部姿态,梁令羽等人[48]将头部姿态识别问题视为分类问题,提出了一种基于Bagging-SVM集成分类器来估计头部姿态的算法,具有良好的识别效果。
如果姿态识别能够细化到手势识别和头部姿态识别,将会对被识别者进行更详细的信息分类,但是增加更多特征点会使算法识别速度变慢,识别准确率也会有所影响。因此如何将人体姿态识别与手势识别进行融合,也是今后有待思考的问题。
(4)构建更精确的包含深度信息的人体姿态数据集
姿态识别算法的训练精度跟所训练的数据集息息相关,同一算法在不同数据集中表现情况不尽相同。目前网络公布的人体姿态数据集各有千秋,常见的单人数据集有FLIC图像集[49]、LSP图像集[50]等,但是包含更详细精确信息的数据集却很少。由于缺少深度信息姿态数据集,基于深度信息的人体姿态识别算法模型的训练效果和识别效果也有待验证。因此,构建一个权威的更精确的人体姿态数据集对今后算法的比较研究具有重要意义。
(5)提高人体姿态识别的准确性、鲁棒性和实时性
人体姿态识别技术如果要在日常生活中发挥作用,必须保证其准确性、鲁棒性和实时性都达到较高的水平。目前存在的人体姿态识别方法具有多样性,各具特色,而且对于单个算法的优化已经接近饱和状态,很难实现更大的突破。在目前的研究中,往往根据不同算法的优缺点将算法进行融合,使得融合结果在姿态识别数据集中的表现均优于单个算法。因此,通过算法结合的方式来提高姿态识别的准确性、鲁棒性和实时性将会成为今后研究的热点。
猜你喜欢
小哥白尼(趣味科学)(2022年1期)2022-04-26
大科技·百科新说(2021年10期)2021-12-31
上海金属(2021年2期)2021-04-07
学生天地(2020年18期)2020-08-25
学生天地(2020年3期)2020-08-25
小猕猴学习画刊·下半月(2019年6期)2019-08-13
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
特别健康(2018年3期)2018-07-04
故事作文·高年级(2017年2期)2017-03-01
