
3D SoC并行测试中TAM调度优化设计
2020-02-18 15:17吴欣舟
计算机工程与应用 2020年4期
吴欣舟,方 芳,王 伟
1.合肥工业大学 计算机与信息学院,合肥230009
2.合肥工业大学 管理学院,合肥230009
1 概述
近年来随着数字集成电路特征尺寸向纳米级发展,单个芯片晶体管数目已达到十亿量级,片上系统(System on Chip,SoC)集成规模越来越大,传统的2D芯片面临着功耗升高、电路时延增加、带宽要求提升等问题,三维堆叠集成电路(3D Stacked ICs,3D-SICs)是由多层2D芯片互连而成,利用过硅通孔(Through Silicon via,TSV)作为数据传输通路连通多层晶片,缩短了芯片内部互连线长度,提高了系统性能,成为突破2D芯片性能瓶颈的有效解决方案,得到集成电路产业界的广泛关注和研究[1-4]。随着3D芯片电路复杂性不断增加,测试时间和测试功耗问题成为研究人员所面临的关键问题。
3D芯片测试过程分为绑定前测试、绑定中测试和绑定后测试三个阶段,其中绑定中测试是指每一次层与层之间完成互连后针对该部分堆叠的测试,它可以提早检测出绑定过程中由制造工艺带来的芯片故障,尽早丢弃损坏部分,从而降低芯片测试成本。经过封装后的三维片上系统的引脚位于芯片最底层,而各芯核分布在不同层。芯片测试过程就是通过测试访问机制(Test Access Mechanism,TAM),将从测试引脚传入芯片的测试向量移位至相应芯核,并捕获测试响应,将响应输出到自动测试仪(Automatic Test Equipment,ATE)中,通过对比测试响应与预期输出结果是否相同来判定该芯片是否故障。每个芯核通过测试外壳与外围逻辑电路隔离[5-9],测试外壳又称为芯核封装设计,它控制系统TAM带宽与芯核内部扫描链的分配。测试外壳由多个外壳边界扫描单元和一个外壳指令寄存器(Wrapper Instruction Registers,WIR)组成,通过改变WIR的值可以对芯核的测试模式进行选择。
并行测试方法允许3D SoC中的不同芯核同时进行测试,有效提高了3D芯片测试效率,目前国内外针对3D芯片并行测试的研究越来越成熟。文献[10]使用整数线性规划方法,在测试功耗以及管脚和TSV个数等约束条件下,通过公式化模型给出最优的绑定结构;文献[11]基于时分复用的方法,通过TSV对测试频率进行层间分频和层内分频,最终合理划分至各芯核,使各芯核轮流占用TAM资源,并使用离散粒子群优化算法求出最优的三维布图;文献[12]将测试过程看作装箱问题,有效利用TAM带宽,使得相同功耗约束下并行测试集中的测试长度彼此接近,减少了测试时间。传统方法没有考虑对测试外壳结构进行调整,所采用的算法有一定的局限性。
2 3D SoC并行测试设计
2.1 测试结构设计
图1展示了可并行测试3D SoC的一般结构。该示例中3D芯片由三层晶片堆叠而成,其中底层分布了四个芯核,中间层分布了两个芯核,顶层分布了三个芯核。在实际测试过程中,一部分芯核单独接收测试数据进行测试,如Core 4;另一部分核与核之间被串联形成更长的扫描链进行测试,如Core 1、Core 2、Core 3。在各晶片相互绑定前,三层2D芯片相互独立地进行绑定前测试,而针对绑定前测试中TSV尚未连通的状态下单层2D芯片电路不完整的情况,一般采用在电路中增设控制端、观测端D触发器的方式解决[13]。在各晶片绑定前测试过程中,可以允许分布在不同扫描链上的各测试会话进行并行测试,即层内并行测试,如Layer 1在绑定前测试时,Session 1与Session 2可以并行执行测试[14]。在绑定中测试阶段,TSV作为层间数据通路将不同层连接起来,由于测试引脚均位于芯片最底层,测试数据需要通过TSV才能进入上层晶片进行测试,此时绑定前测试过程中的扫描链可以被打破,新层中的芯核集被加入到所有待测芯核的集合中,各芯核间经过重新组合,划分为新的扫描链进行绑定中测试,此时不同的测试会话间仍可以进行并行测试,即层间并行测试,如图中Session 1与Session 3可以并行执行测试。但是在实际测试过程中,由于测试数据寄存器(Test Data Register,TDR)数量有限,以及各晶片绑定中硬件结构等限制,导致部分会话间往往无法并行测试,这就要求提出的方案必须满足系统的测试并行性约束。

图1 三层3D SoC并行测试结构
2.2 传统的并行测试过程
在3D芯片多核并行测试过程中,用于传输测试向量的TAM资源有限,因此需要对各芯核测试调度过程进行优化,以便最大限度地利用TAM带宽。传统方法将测试调度过程看作装箱问题,使各芯核按序进入测试调度,但是并未考虑到系统当前状态下可能存在的少量TAM资源余量,这部分空闲的TAM资源将造成测试过程中存在诸如图2所示的空闲时间块Idle。

图2 传统方法的测试调度过程
图2展示了传统方法下的测试调度过程。初始状态进行并行测试的芯核分别为Core 1、Core 2、Core 3,此时等待队列中即将进入调度的是Core 4;当t1时刻Core 3测试完成并释放资源后,系统剩余的空闲TAM资源仍无法满足Core 4所需带宽,此时Core 4仍将处于等待调度状态;经过若干时钟周期到达t2时刻,Core 2完成测试并释放资源,系统空闲TAM宽度满足Core 4测试要求,Core 4进入测试,此时系统中又出现了新的空闲块,大量闲置的TAM造成了系统资源浪费。本文提出了一种新型的测试外壳结构,利用空闲的TAM对等待队列中的芯核进行提前测试,最大限度地利用了系统资源,同时该方法将在功耗及测试并行性共同限制下,寻找合适的测试调度顺序,从而减小总测试时间。
2.3 功耗来源及约束
目前集成电路产业快速发展,CMOS电路因其低功耗特性得以大规模应用,并且随着制造工艺的提升,单只CMOS管平均功耗也在不断下降,但是由于片上系统晶体管数目的增加,特别是对于更高集成度的3D芯片来说,单只CMOS管功耗的降低幅度很难赶上电路中CMOS管数量的增加幅度,导致3D芯片面临着更严峻的功耗挑战。同传统的2D芯片一样,3D芯片功耗也分为动态功耗和静态功耗两部分,如式(1)所示,Ps表示静态功耗,Pd表示动态功耗。其中静态功耗主要由输入保护二极管和寄生二极管的反向漏电流组成,动态功耗由Pc与Pt构成,分别表示节点电压跳变时电容充放电功耗,以及输出跳变时驱动管与下级负载管瞬间导通功耗,如式(2)。

由于测试过程中电路中寄存器频繁跳变,测试功耗将远大于正常工作情况下产生的功耗,因此测试过程需要对功耗加以限制。尤其在3D SoC并行测试中,电路集成度高,并行测试的芯核数量多,每一时刻的测试总功耗是由同时执行测试的各芯核所产生的功耗叠加而成,因此并行测试相较于非并行测试功耗更高,将测试功耗作为约束条件成为不可忽略的环节。本文选取平均功耗与最大峰值功耗两种指标作为功耗约束的度量。平均功耗是指在一段时间内系统产生测试总功耗的平均值,用于衡量测试过程在总体上的功耗大小状况。峰值功耗是指系统在某一时刻可以产生的功耗最大值,用于衡量瞬时电路开关活动对系统的影响。
3 本文方案
3.1 问题描述
本文所解决的问题是在功耗以及芯核测试并行性的限制下,最大限度地合理分配TAM资源,降低总的测试时间。被测SoC的形式化描述如下:假设该3D SoC总层数为m,总芯核个数为n,最底层至最高层依次编号为l1,l2,…,lm,各芯核完成测试的时间分别为t1,t2,…,tn,最大峰值功耗约束为Pmax,测试平均功耗约束为Pavg,每层晶片的测试功耗分别设为p1,p2,…,pm,集合C为不能并行测试会话的集合,各晶片绑定次序为由底层向顶层按序层层绑定。
对于单个芯核而言,设Nin为目标芯核输入端口数,即该芯核通常情况下所需TAM的条数,设M为芯核内部扫描链条数,设Nvalid为TAM资源不够时临时分配给该芯核的TAM条数,它将通过测试访问端口(Test Access Port,TAP)中的控制模块以二进制编码形式发送给目标芯核。
3.2 优化的测试外壳设计
本文针对测试调度阶段提出一种更灵活的TAM分配方式,设计出一种新的测试外壳结构,仅使用了较小的硬件开销,便可以使3D SoC最大限度地利用TAM资源。该测试策略在功耗及测试并行性的共同约束下实现,有效缩短了测试时间,尤其是针对绑定中测试阶段堆叠层数较多的情况,效果更加显著。对于TAM宽度一定的3D SoC而言,芯核测试调度过程被抽象为装箱问题,等同于图2坐标系中的矩形,每个矩形的长和宽分别代表一个芯核测试所耗时间和所占TAM宽度。传统方法下矩形无法被分割,导致装箱问题的解可能会在坐标系中产生Idle区域。为了突破传统方法,需要对电路结构进行改良,减少或消除Idle时间块。随着Idle区域的减少,TAM资源使用率得到提升,测试便可以提前完成。
本文芯核测试结构如图3所示。
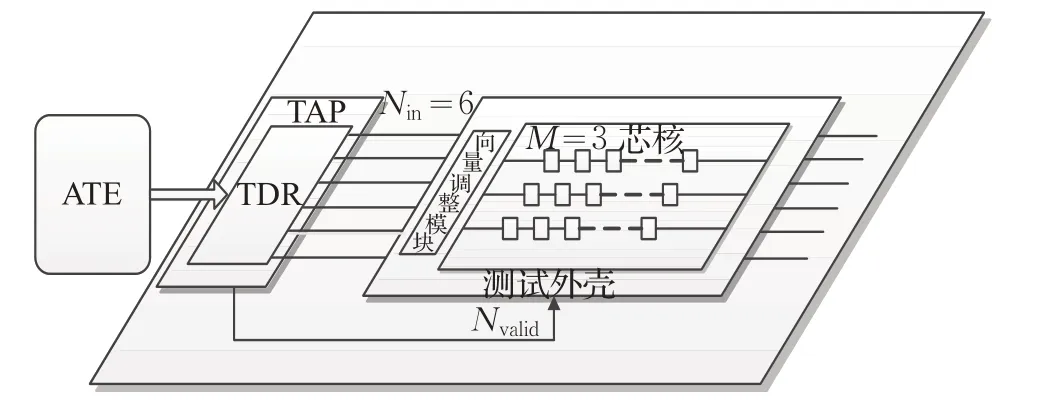
图3 芯核测试结构设计
为了实现上述目标,本文在测试访问端口与每个芯核测试外壳之间增加一条单向数据通路,目的是使TAP通知即将进入调度的芯核当前系统所剩TAM资源数量Nvalid。如果系统当前剩余TAM数量达到目标芯核输入端口数要求,即Nvalid≥Nin,则测试激励不进入向量调整模块,芯核正常进行测试;如果系统当前剩余TAM数量小于目标芯核输入端口数且存在至少一条空闲TAM,即0<Nvalid<Nin,则首先由TAP通知待测芯核可用于测试的TAM的数量Nvalid,测试激励由Nvalid条TAM输入至向量调整模块,重新对可用TAM数量Nvalid和芯核内部扫描链条数M制定数据分配策略。具体的测试模式选择流程如图4所示。

图4 芯核测试模式选择流程
对于系统TAM资源不足的情况,测试激励被重新按序分配至Nvalid条TAM上,随即进入待测芯核扫描外壳中的向量调整模块,至此产生一个多条TAM对应多条内部扫描链的数据分配问题。向量调整模块首先将Nvalid条可用TAM上的数据整合成一条串行数据流,使多条TAM上的数据依次存入数据缓冲区,此过程解决了测试输入过程中N∶1的问题;当数据缓冲区处于非空状态时,向量调整模块中的译码器根据TAP传入的选择信号选通相应扫描链,缓冲区中的测试激励按序分配至各条扫描链,此过程解决了测试数据流进入芯核内部扫描链的1∶M的问题。现假设图5为图3芯核正常状态下(Nin=6,M=3)的数据分配策略:①、②两条TAM数据输入对应芯核内部第一条扫描链SC1,依次为SC1提供测试激励;同理③、④两条TAM数据输入对应芯核内部第二条扫描链SC2,依次为SC2提供测试激励。图6为图3芯核接收TAM数量为Nvalid(Nvalid=2<Nin=6,M=3)时的数据分配策略:首先由自动测试仪对原测试集传输方式进行调整,使测试向量沿两条可用TAM传输至待测芯核,测试外壳中的向量调整模块将两条TAM上的测试数据整合成一组串行测试数据,测试向量一旦进入缓冲区,外壳中的扫描链选择译码器将依次选通三条芯核内部扫描链,使测试数据按位进入各条扫描链,待系统中有其他TAM资源被释放,TAP会再次通过数据通路通知芯核,并按照系统当前剩余的TAM资源数重新选择数据分配策略。向量调整模块电路结构如图7所示。
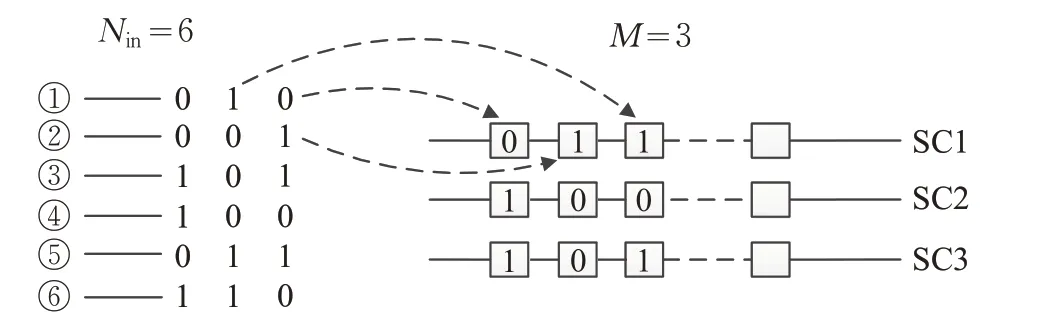
图5 数据分配传统方法举例
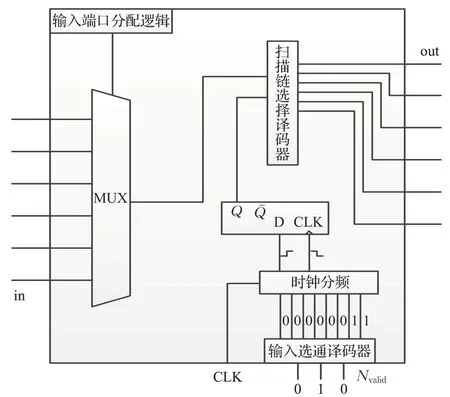
图7 输入向量调整模块电路结构
3.3 测试顺序调整
在改进的测试外壳结构基础上,需要寻找合理的芯核调度顺序,由于改进的测试外壳结构使系统TAM资源最大限度地得以利用,芯核并行测试不再受装箱问题空闲区域的影响,各芯核的调度顺序只需考虑功耗及测试并行性约束。本文的调度方法首先将待测芯核按序排列作为等待队列,根据3.2节提出的新结构,待测芯核依次进入测试,并尽可能将系统TAM资源分配给芯核,此时的芯核调度顺序称作测试预排序,在此基础上需要对并行测试过程进行最大峰值功耗、平均功耗、测试并行性约束判定,从而调整测试顺序。
最大峰值功耗需满足在tn时间内测试过程最大功耗小于等于Pmax,约束公式可以写成式(3)的形式;平均功耗约束如下,设在任意tn-1到tn的时间段内,参与并行测试的芯核编号为i~j,则该时间段平均功耗应满足式(4);测试并行性约束需满足任意时刻被分配为并行测试的芯核之间必须在硬件结构上是可并行的。

图6 系统TAM不足时的数据分配

如果预排序方案在三个约束下出现无法满足条件的芯核,则该芯核和下一个待测芯核调换测试顺序,直到所有芯核测试顺序满足约束条件。图8以图2的案例为例,假设Core 3和Core 4分布于不同的测试会话中,而此时这两个测试会话共用同一组TDR,从而导致这两个芯核无法并行执行测试,则Core 4和Core 5调整测试顺序,此时系统满足所有约束条件,可以进入测试阶段。
4 实验结果与分析
为验证本文提出的3D SoC并行测试调度策略的有效性,选取ITC’02测试基准电路作为验证载体[15],选取d695、u226、p22810、p34392、p93791作为实验对象,通过C++语言编程模拟实现了本文的策略。为了便于对比,设参数α为本文方法相对文献[11,16-17]方法关于测试应用时间(Test Application Time,TAT)的优化比例,定义TA为利用本文方法产生的TAT,TB为对比文献方法产生的TAT,则α的定义如式(5)所示。

为保证实验对象与对比文献一致,实验首先选取p22810、p34392、p93791三种测试电路在系统TAM数量为32,最大功耗阈值为80 mW的条件下进行层内并行测试。文献[16]方法选取种群规模N=2 000,允许误差err=0.005,最大迭代次数T=100进行测试,产生的测试时间、最大功耗、平均功耗及优化比例如表1所示。
从表1中可以看出,本文提出的TAM调度策略适用于绑定中测试过程中各层层内芯核并行测试的情况,在三种不同测试电路上的实验结果显示该方法测试时间较其他文献方法均有所减少,但测试功耗会有少量提升。原因是本文方法提高了系统TAM利用率,减少了空闲时间块,系统TAM在功耗阈值限制范围内被高效率利用,尽管在功耗阈值设定较小的情况下,本文方法完成测试所需功耗偏高,但如图9所示在相同的功耗阈值限制下,本文方法所需测试时间比其他文献降低了至少3.339%。因此可以得出,在同样功耗限制条件下,本文策略可以取得更少的测试时间,进而降低测试成本。比较发现p22810、p34392、p93791的Module数量分别为29、20、33,由表1可知,本文方法在p93791上相比其他文献方法优化比例最高,因此本文方法更适合于芯核数量较多的芯片。
表2展示了d695、u226、p22810、p34392、p93791分别作为3D SoC的底层至顶层晶片,在自底向上绑定过程中不同堆叠产生的测试结果,表中文献[11,16-17]数据的最后一行记录了本文方法在当前堆叠状态测试产生的TAT相比该文献提出方法的优化比例。横向对比本文方法产生的测试时间可以看出,堆叠层数越多,TAM使用率越高。因为随着堆叠层次的增加,可供调度的芯核增多,原先由于功耗和测试并行性约束被阻塞的TAM资源经过测试顺序调整被合理调度并重新利用。纵向比较本文方法与其他文献方法的测试时间,优化比例最少达到2.118%,最高达到24.189%,并且随着堆叠层数的增加,优化比例也不断提高,说明本文策略对于堆叠层数多的3D SoC效率较高。
五层3D SoC堆叠在不同的功耗阈值约束下的测试结果如图9所示,在给定功耗阈值的条件下,文献[11,16]方法的芯核调度顺序也将被重新调整。实验表明,本文的测试方法在不同功耗阈值限制下得到的测试时间较其他方法均有所减少,功耗阈值越大,本文方法测试效果提升越显著。
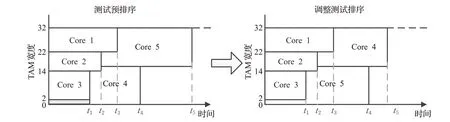
图8 优化的测试调度策略

表1 各层测试时间及功耗结果比较
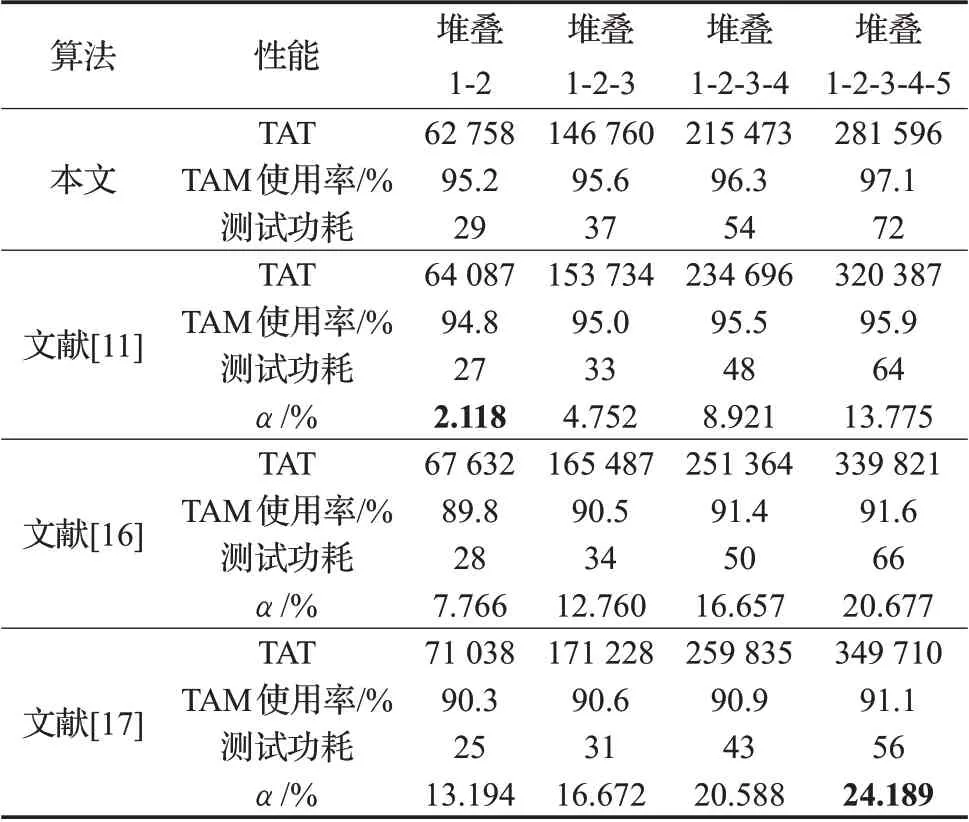
表2 不同堆叠的测试时间及功耗结果对比
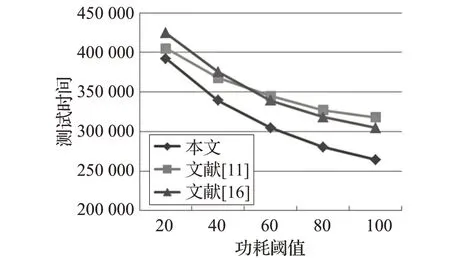
图9 功耗阈值与测试时间的关系
5 结论
本文提出了一种3D SoC并行测试调度策略,设计了相应的测试外壳结构,最大限度地利用了系统TAM资源,有效地降低了测试时间;同时考虑到在功耗和测试并行性的共同约束下,合理地对芯核测试顺序进行调整,更接近实际生产与测试中的情况。在ITC’02 SoC标准测试集上的实验结果表明,本文方法相比文献[11,16-17]方法的测试时间减少,且具有较小的硬件开销,对于实际测试过程有重要的启发意义。
猜你喜欢
北京航空航天大学学报(2022年7期)2022-08-06
原子与分子物理学报(2020年5期)2020-03-17
铁道通信信号(2020年10期)2020-02-07
装备制造技术(2019年12期)2019-12-25
北京航空航天大学学报(2019年9期)2019-10-26
成都信息工程大学学报(2019年3期)2019-09-25
模具制造(2019年7期)2019-09-25
三门峡职业技术学院学报(2019年1期)2019-06-27
个人电脑(2016年12期)2017-02-13
山东工业技术(2016年15期)2016-12-01
