
基于高密度肌电的对称位置发音肌肉对语音识别贡献的研究
2020-02-10 01:44王小晨朱明星杨子健黄剑平陈世雄李光林
集成技术 2020年1期
王小晨 朱明星 杨子健 汪 鑫 黄剑平 陈世雄 李光林
1(中国科学院深圳先进技术研究院 深圳 518055)
2(中国科学院大学深圳先进技术学院 深圳 518055)
1 引 言
说话是人类特有的表达情感、传递信息、参与社会活动的交流方式[1],是人类正常生活中最重要的技能之一。无论是在生活还是在工作中,都不可避免地需要通过说话与他人交流。说话是一个非常复杂的面颈部多块肌肉在中枢神经系统的控制下协同收缩运动的过程,这伴随着肌肉电信号的产生[2-3]。发不同的音时,发音肌肉的收缩模式、收缩力量和协同方式是不同的,对应的肌肉电信号特征也会不同[4]。表面肌电图法(Surface Electromyography,sEMG)是目前采集肌电信号的常用方法,能通过无创、简单、稳定的操作,检测到可靠的肌肉电生理信息[5],因此被广泛用于肌电语音识别研究。
早在 1985 年,第一个使用肌电信号进行语音识别的研究就在 Sugie 和 Tsunoda[6]的实验室展开,他们采集口腔附近的肌电信号对 5 种日语元音字母进行分类。1989 年,Morse 等[7]提取sEMG 信号幅值、方差等特征值分类 10 个英文单词,分类精度达到了 60%。2018 年,Srisuwan等[8]在受试者的面颈部共 6 个位置贴上肌电电极,以评估 14 个特征评估标准及 4 种分类器对单个泰语单词进行分类时的性能,并找到一种接近最佳的标准和分类算法。Janke 等[9]对从受试者发音时面颈部 6 个位置采集到的肌电数据进行研究,捕捉到从发音肌肉运动时产生的 sEMG 信号到语音波形的映射。Jong 和 Phukpattaranont[10]招募 7 名健康受试者和 5 名构音障碍受试者开发了一个语音识别系统。该系统使用从 12 名受试者脸部和颈部共 5 个通道里记录的 sEMG 信号对 9 个泰国音节进行分类。Diener 等[11]使用sEMG 技术在语音识别方面做了大量工作,提出了使用深度神经网络实现从表面肌电信号到目标声学语音输出的映射。
上述研究中,设置的电极数量均较少,且选取的电极位置都不同,分类结果也有显著差异。由于发音过程涉及到的肌肉多达 30 余块[12],使用肌电信号进行语音分类时,电极的位置和数量会对分类准确性产生重要影响[13]。而目前基于sEMG 的语音识别方法选取电极位置及数量时没有一个客观的指标,也不清楚与发音相关的面颈部左右两侧对称位置电极对肌电语音识别的贡献是否存在冗余[14-15]。
为解决后一个问题,本文提出使用几乎覆盖全部发音肌肉的高密度肌电电极,探究面、颈部左右两侧对称位置电极对肌电语音识别的贡献。首先,使用关于面中部、颈中部对称的共 120 通道电极采集 8 名发音正常的受试者的表面肌电信号。其中,发音测试为 5 个中文单词和 5 个英文单词。然后,对信号预处理后分组提取 4 种时域特征输入支持向量机(Support Vector Machine,SVM)分类器,进行语音分类。最后,对分类结果进行分析,比较面、颈部对称位置肌电信号在语音识别时的贡献程度。
2 实验方法
2.1 信号采集方法
本研究共招募 8 名健康受试者(sub1~8),其中 6 名男生、2 名女生,年龄为 22~26 岁(平均年龄为 24 岁)。所有受试者均未患有可能影响实验结果的说话和吞咽问题。实验开始前,受试者均阅读知情同意书并签字,且允许出于科学目的公开发表他们的照片和数据。
本实验使用荷兰 TMS 公司研发的高密度肌电采集系统(REFA 128-model system),以 2 048 Hz采样率采集面、颈部共 120 通道高密度肌电信号。其中,电极对称放置于受试者面、颈部,分为面部左侧(20 个通道)、面部右侧(20 个通道)、颈部左侧(40 个通道)、颈部右侧(40 个通道)4 个区域,如图 1(a)所示。通道以面、颈部中间位置为对称轴左右对称放置,行、列编号如图 1(b)所示。实验前,使用酒精棉擦拭电极位置,清除皮肤表面的油脂和角质。实验在屏蔽房中进行,以保证测试过程相对安静,受试者发音不被影响。整个实验过程符合中国科学院深圳先进技术研究院人体实验伦理道德规范(审批编号为 SIAT-IRB-170815-H0178)。

图1 高密度表面肌电电极在面颈部左右两侧的分布Fig.1 Distribution of the high density sEMG electrodes on the left and right sides of the face/neck regions
2.2 实验过程
实验时,受试者调整舒服的姿势坐在椅子上,保持 40 s 的静息状态(不说话、也不做任何身体运动),记录下此时的肌电信号作为基线(P11)。随后,受试者按照平时说话的音量及音调进行 10 组发音任务,包含英文 5 组单词:“Thanks”(P1)、“Yes”(P2)、“No”(P3)、“Hello”(P4)和“Goodbye”(P5),以及对应着相同含义的中文 5 组日常短语:“谢谢”(P6)、“是的”(P7)、“不是”(P8)、“你好”(P9)和“再见”(P10),具体如表 1 所示。每组任务包括1 s 的发音过程和 3 s 的休息,两过程交叉连贯,共重复 6 次,以采集整个过程的表面肌电信号。

表1 5组英文和 5组中文发音任务Table 1 Speaking tasks of five Chinese words and five English words
2.3 信号处理
由于采集到的原始肌电信号不够干净,即混杂着心电、运动伪迹、工频等各种噪声,故分析肌电特征前需对信号做预处理工作。首先,使用30~500 Hz 的巴特沃斯带通滤波器滤除大量心电干扰和面部伪迹;然后,设置 50 Hz 及其倍数频率的陷波滤波器去除工频干扰,得到较为干净的肌电信号(数据维度为:120×信号长度)。
使用长度为 250 ms 的分析窗口对滤波后的各通道信号计算均方根(Root Mean Square,RMS),再利用计算出的高密度表面肌电信号的最大和最小 RMS 值对所有通道的 RMS 值进行归一化得到归一化均方根(Normalized Root Mean Square,NRMS),并画出左右对称位置的 NRMS叠加图。由于一段发音过程持续时间较短,保留的特征点不足,故首先根据肌电信号原始波形,确定每段发音过程的起始点与结束点,对滤波后的信号进行人工截取,得到 14 段发音活动的肌电信号;然后,将这些信号进行拼接,得到整段全为发音过程的肌电信号,处理过程如图 2 所示;最后,提取零交叉(Zero Crossing,ZC)、斜率符号变化(Slope Sign Change,SSC)、波形长度(Waveform Length,WL)和平均绝对值(Mean Absolute Value,MAV)4 个特征[16],得到11×4×N维度的数据。其中,11 为类别数;4 为特征数;N为通道数。四种特征的定义如下:
(1)零交叉(ZC)是在时域中定义 EMG 信号频率信息的度量,为单位时间窗口内信号通过零幅值的次数,其定义如公式(1)~(2)所示。

其中,xi为i点的 EMG 信号;N为 EMG 信号的长度。
(2)斜率符号变化(SSC)记录了在单位时间窗内 EMG 信号斜率的改变次数,其定义如公式(3)~(4)所示。


图2 肌电信号处理过程Fig.2 sEMG signal processing

(3)波形长度(WL)是 EMG 波形在某个时间段上的累计长度积分,其定义如公式(5)所示。

(4)平均绝对值(MAV)是 EMG 信号分析中最常用的一种时域特征,表示一段 EMG 信号幅值绝对值的平均值,可反映肌电的强度,其定义如公式(6)所示。

将特征值输入 SVM 分类器作分类,使用 5倍交叉验证方法来减少生成训练和测试数据的可变性。其中,SVM 是一种二分类模型,有两大主要优势:更高的速度、用更少的样本(千以内)取得更好的表现[17]。这使得该算法非常适合本文分类问题。另外,使用统计方法比较面部和颈部肌肉左右两侧对称阵列的分类精度。
3 实验结果
3.1 发音时面、颈部左右两侧肌肉间的相关程度
图3 展示了一名受试者说一次“Hello”时的面部(a)、颈部(b)左右对称通道叠加的 NRMS波形。图中蓝线表示面部/颈部左侧的 NRMS 波形,而红线则表示面部/颈部右侧的 NRMS 波形。从图 3 可以看出,所有的 NRMS 波形均呈现相同的特点:随着发音过程慢慢上升,达到峰值后开始下降直至静息时的水平,面部整体峰值低于颈部。面部和颈部左侧的 NRMS 波形与右侧的波形以相似的速率变化。
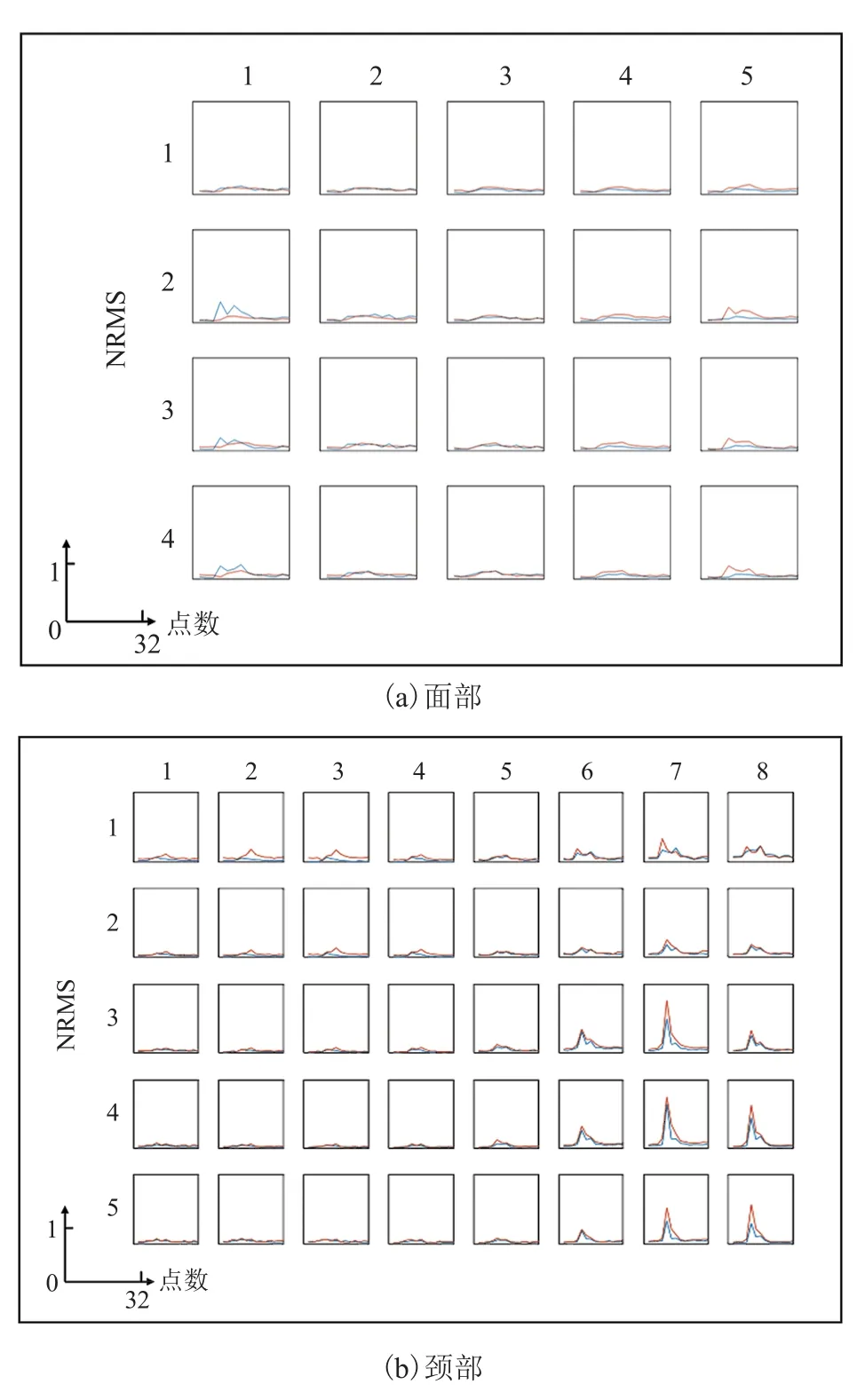
图3 面、颈部左右两侧高密度肌电信号的 NRMS 波形叠加图Fig.3 Superposition of NRMS waveforms of high density sEMG recordings from the left and right sides of the facial and neck muscles
相关系数是用于反映变量之间相关关系密切程度的统计指标,能够刻画两个变量之间的相关程度,P值可以描述相关程度计算结果的“显著程度”[18]。分析面部、颈部左右两侧肌肉之间的相关性有助于理解发音过程中面、颈部对称位置的运动模式相似程度。使用相关系数、P值计算公式对面部、颈部对称通道的 NRMS 波形相似性进行统计,结果如表 2 和 3 所示。表中的序号下标分别对应图 3 波形叠加图的行、列编号,如 F11 表示图 3(a)中 1 行 1 列。可以看出,面部左、右两侧对称通道 NRMS 波形的相关系数范围为 0.395 5~0.929 5,平均值和标准偏差为0.714 9±0.165 3;颈部对称通道 NRMS 波形的相关系数范围为 0.464 2~0.988 5,平均值和标准偏差为 0.840 5±0.150 6。显然,面部左右两侧的相关性比颈部低,但整体上存在相关性。同时,只有 F21、F31、F41、N12、N13 这 5 个靠近面、颈部边缘对称位置的 NRMS 波形间无显著相关,其余位置的 NRMS 波形间均显著相关。
3.2 使用面部左右两侧对称位置肌电信号的语音分类精度对比
表4 和 5 分别为使用一名受试者面部左右两侧对称位置的肌电信号进行语音分类的结果。表中对角线上加粗的数据是正确分类的精度,而其余数值则是误识别为其他发音任务的概率。
从表 4 可以看出,静息状态(P11)的分类精度最高,为 1;P1、P3 和 P4 的分类准确率较高,均超过 0.9;而 P6 的分类准确率最低,为0.647 9。面部左侧的平均分类精度和标准偏差值为 0.823 8±0.106 6。从表 5 可以看出,使用面部右侧肌电信号的分类精度仅在 P1、P3 和 P11 识别任务处高于 0.8;有 6 个识别任务的分类精度低于 0.7,最低为 0.664 5(P9);无声模式的分类精度同样为 1。面部右侧的平均分类精度和标准偏差为 0.752 8±0.108 8。由此可见,面部右侧的平均分类精度较左侧低,左右两侧的偏差范围均大于 0.1,波动非常大。比较表 4 和 5 也能看出,除了 P6 外,其余发音任务的分类精度都是面部左侧较高。

表2 面部左右两侧对称通道 NRMS 波形的相关系数Table 2 Correlation coefficients of NRMS waveforms on the left and right sides of the facialmuscles

表3 颈部左右两侧对称通道 NRMS 波形的相关系数Table 3 Correlation coefficients of NRMS waveforms on the left and right sides of the neckmuscles
由于大部分受试者静息状态(P11)的分类精度几乎都达到了 1,故将它排除在外后,再对所有受试者的其余 10 个发音任务的分类精度进行统计,结果如图 4 所示。图中柱状图的高度代表受试者的 10 个发音任务分类精度的平均值,上下的垂直误差条表示标准偏差范围。蓝色柱状图表示受试者面部左侧 20 个通道肌电信号;红色柱状图表示受试者面部右侧 20 个通道肌电信号。从图 4 可以看出,使用面部左侧肌电信号的平均分类精度中只有 sub6 超过 0.8;面部右侧肌电信号的平均分类精度中 sub4、sub7 都高于0.8。sub7 的垂直误差条的长度最短,标准偏差不超过 0.1;其余的受试者波动范围都大于 0.1。此外,sub2、sub4、sub6、sub7、sub8 的左右平均分类精度高度差较大,均高于 0.5。使用t检验方法对面部两侧平均分类精度进行比较发现,sub2、sub4、sub6、sub7、sub8 的左右两侧间均存在显著性差异。

表4 使用面部左侧肌电信号的 11 种语音分类精度Table 4 Classification accuracies of 11 speaking tasks using the left side of facial SEMG signals

表5 使用面部右侧肌电信号的 11 种语音分类精度Table 5 Classification accuracies of 11 speaking tasks using the right side of facial SEMG signals
3.3 使用颈部左右两侧对称位置肌电信号的语音分类精度对比

图4 所有受试者使用面部左、右侧不同通道组合的平均分类精度与标准偏差Fig.4 Average classification accuracy and standard deviation for all subjects using different channels of facial muscles
使用同一受试者颈部左、右两侧对称位置的肌电信号进行语音分类的结果如表 6 和 7 所示。与面部相同,静息状态的分类精度同样为 1,可见静息状态与发音时的肌电特征有着显著区别。从表 6 可以看出,使用颈部左侧肌电信号对 11 类发音任务进行分类时,所有的单词分类精度都超过 0.8,且 P3、P4 的分类精度超过 0.9;颈部左侧的平均分类精度和标准偏差值为 0.877 9±0.059 8。从表 7 可以看出,使用发音任务 P6、P9 和 P10在颈部右侧处的肌电信号的分类精度较低,小于0.8,而 P2、P4 的分类精度高于 0.9;颈部右侧的平均分类精度和标准偏差为 0.858 7±0.071 9。
与面部相似,使用受试者颈部左右两侧对称位置的高密度表面肌电信号的同一单词的分类精度并不完全相同。在 P1、P3、P6、P7、P9 和P10 中,使用颈部左侧通道信号的分类精度高于使用颈部右侧通道的分类精度,其余单词则相反。但颈部的分类精度整体高于面部,且颈部两侧分类精度的差异略小于面部。

表6 使用颈部左侧肌电信号的 11 种语音分类精度Table 6 Classification accuracies of 11 speaking tasks using the left side of neck SEMG signals

表7 使用颈部右侧肌电信号的 11 种语音分类精度Table 7 Classification accuracies of 11 speaking tasks using the right side of neck SEMG signals
对所有受试者颈部左、右两侧的肌电信号进行分类,得到的分类精度如图 5 所示。从图 5 可以看出,只有使用 sub8 颈部右侧的表面肌电信号进行分类时,平均分类精度低于 0.8;sub4 的两侧、sub5 的左侧以及 sub8 的右侧标准偏差均略高于 0.1,且只有 sub8 左右平均分类精度高度差大于 0.5,差异比较明显。
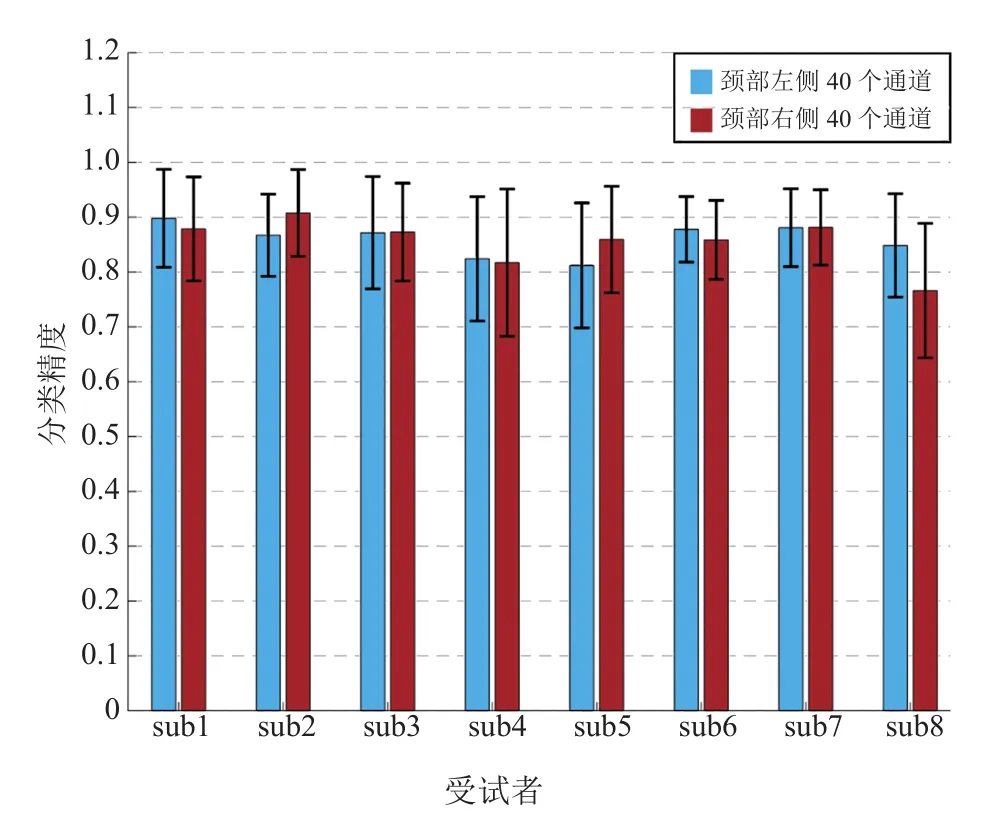
图5 所有受试者使用颈部左、右侧不同通道组合的平均分类精度与标准偏差Fig.5 Average classification accuracy and standard deviation for all subjects using different channels of neck muscles
比较图 4 和 5 可以发现,颈部的平均分类精度比面部高,且标准偏差更低、差异更小,分类效果更稳定。使用t检验方法对颈部左右两侧平均分类精度进行比较发现,只有 sub8 左右两侧间存在显著性差异。
4 讨 论
语音的产生是一个面部和颈部肌肉共同运动的过程,而肌肉活动产生肌电信号[19]。因此,分析肌电信号对了解语音产生过程中肌肉活动的详细信息非常有帮助。前人已经使用 sEMG 技术在语音识别方面做了大量工作,但实验设置的电极数量较少,选取的电极位置依赖实验操作者的经验,分类结果也具有显著差异[6-11],最高的分类精度是 Jong 和 Phukpattaranont[10]在 2019 年的研究中对健康受试者的泰语识别,为 0.945。由于面颈部肌肉结构复杂,少数几个电极不能完整覆盖发音肌电活动。为精准量化电极数量、确定电极位置,本文利用高密度电极对发音相关的面、颈部左右两侧对称位置肌电在语音识别中的贡献进行了初步考察。
本研究使用关于面中部、颈中部对称的共120 通道高密度表面肌电电极采集 8 名发音正常的受试者分别发 5 个中文单词和 5 个英文单词时的表面肌电信号。首先,对面部、颈部左右对称位置的 NRMS 波形进行分析比较发现,面部和颈部左右两侧的 NRMS 波形具有相同的变化特性,但面部的波形相关性比颈部低。这说明面颈部左右两侧肌肉发音的规律是相同的,但面部左右差异更大。这可能与颈部肌肉活动是被动的,而面部肌肉可以主观控制有关。然后,将不同通道肌电信号按照分布区域分为 4 组,提取 ZC、SSC、WL 和 MAV 四种特征值,并将其输入 SVM 分类器进行 11 种语音模式的分类。结果显示,所有通道电极的平均分类精度均可达0.98,高于 Jong 和 Phukpattaranont[10]研究成果中最高的 0.945,表明高密度电极相较于少数凭经验放置的电极能提升分类精度。同时,使用同一受试者面部左右两侧通道(各 20 个)信号对相同单词的分类精度存在明显差异,而颈部两侧的差异则略小。所有受试者面部、颈部左右两侧不同通道组合的平均分类精度与标准偏差显示,颈部左右两侧的分类精度差异相较于面部对称位置是比较小的,表明颈部对称位置肌肉电活动对语音识别的一致性更高。因此,使用颈部对称位置的sEMG 信号进行语音分类时的贡献具有一致性。
5 结 论
本研究提出使用面、颈部对称位置的高密度肌电信号对 11 种语音模式进行分类,以比较面、颈部对称位置肌电信号在语音识别时的贡献程度。结果表明,面、颈部左右两侧肌肉发音的规律是相同的,但面部左右两侧间差异更大。单独使用颈部左右两侧的肌电信号分类结果差异不大,但单独使用面部左右位置的肌电信号分类精度差异较明显。因此,颈部对称位置的 sEMG 信号对语音识别贡献程度具有一致性,而面部则不具有。该实验结果有助于减少记录电极的数量,为选择语音识别通道的最佳位置奠定了基础。
猜你喜欢
中国典型病例大全(2022年7期)2022-04-22
中国药学药品知识仓库(2022年1期)2022-03-23
成都信息工程大学学报(2021年4期)2021-11-22
科技传播(2019年24期)2019-06-15
北京航空航天大学学报(2017年9期)2017-12-18
小学生时代·大嘴英语(2015年12期)2016-01-07
体育科学研究(2015年4期)2015-02-28
小学生时代·大嘴英语(2014年11期)2014-12-04
汽车电器(2014年8期)2014-02-28
小学生时代·大嘴英语(2014年1期)2014-02-28
