
基于深度特征加权的图像表示方法
2020-02-08 08:16赵相坤谢博鋆吴树芳
郑州大学学报(理学版) 2020年1期
朱 杰, 赵相坤, 谢博鋆, 吴树芳
(1. 中央司法警官学院 信息管理系 河北 保定 071000; 2. 首都医科大学 生物医学工程学院 北京 100069; 3. 河北省机器学习与计算智能重点实验室 河北 保定 071002; 4. 河北大学 数学与 信息科学学院 河北 保定 071002; 5. 河北大学 管理学院 河北 保定 071002)
0 引言
随着计算机网络技术的发展,图像信息在网络中占据的比例日趋增大。如何有效组织、管理和检索图像资源已经成为当前的一个热点问题[1]。为提高图像检索的综合性能,研究者多从图像表示的有效性入手,将特征描述与特征聚合的方法作为突破口进行研究。
一些图像检索方法采用尺度不变特征变换(scale-invariant feature transform, SIFT)描述子[2]或费希尔矢量(fisher vector, FV)[3]等底层特征描述子描述图像局部特征,然后利用词袋(bag of words,BOW)模型对图像进行编码,实现图像表示,用于检索任务。为了在图像表示中融合语义信息,文献[4]以一些特殊的颜色、形状和材料等为基本元素,将图像表示为这些基本元素的集合,但是这种方法不能准确地描述所有物体的特征。卷积神经网络(convolutional neural networks,CNNs)凭借其接近于语义的图像内容描述能力,逐渐成为图像分类、检索等领域的主流算法[5-7]。传统的CNNs模型主要用于图像分类,包含卷积层、池化层和两个全连接层,最后一层为输出层,用softmax的方式输出属于所有类别的概率。现实中的图像检索有别于图像分类,无法对神经网络进行训练,所以,多采用从预训练CNNs的不同层次提取出的卷积特征,即深度特征对图像进行表示,然后通过计算查询图像与其他图像的相似度,生成检索排序结果。如何对深度特征合理加权从而突出对象内容,并将加权特征进行聚合生成图像表示是目前的研究重点之一。
文献[8-9]最早提出通过聚合不同响应的方式进行图像表示,通过合理利用最大池化、归一化与白化方法,聚合不同通道特征映射的响应,用于产生低维度的图像表示。文献[10]通过将不同通道中局部区域的最大激活值进行聚合,从而生成突出对象内容的图像表示。文献[11]提出的SPoC方法通过给图像中间区域赋予高权值的方法和池化的策略来表示图像内容,从而提高检索准确率。文献[12]通过聚合空间响应和计算通道的稀疏性来计算空间权重和通道权重,然后通过池化方式对每个通道上的描述子进行聚合。
文献[13]通过对不同层次的深度特征进行聚类生成字典,然后采用局部聚合描述子向量 (vector locally aggregated descriptors, VLAD)的方式进行编码,能够生成更加合理的特征表示。但是,用聚类生成的字典作为特征表示,容易忽略不同特征的内在差异,且聚类结果的不稳定性会直接影响特征表示的准确性。此外,聚类产生的字典无法在图像表示中突出对象内容并且弱化背景内容。图像检索中普遍采用将最后一层的深度特征的池化结果用于生成图像表示[10, 12]。文献[14]将特征映射累加求和生成激活映射,并且将激活映射中大于阈值的位置认为是对象区域。但是,阈值通常被设定为激活映射中响应的平均值,这种根据经验阈值来判断对象区域的方法也无法准确突出对象内容。为此,在文献[12,14]的基础上,本文提出了一种全局化的深度特征加权(deep feature weighting,DFW)图像表示方法,DFW利用预训练CNNs,通过计算图像卷积层深度特征的位置重要性、区域重要性和通道重要性,给深度特征加权,并通过聚合、池化的方法生成图像表示。
1 基于深度特征加权的图像表示

图1 图像表示流程Figure 1 Flowchart of image representation
本文提出的DFW图像表示方法流程如图1所示,对于任意输入图像,首先提取出最后一个池化层的所有特征映射,然后通过计算特征映射的空间权重、区域权重和通道权重对深度特征进行加权,并通过特征聚合生成图像表示。本文提出的方法主要有以下优点: 给深度特征加权能够突出对象内容,从而进行更有针对性的图像表示;特征池化的方法能够保证生成低维度的图像表示。
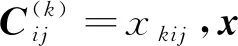
1.1 位置权重
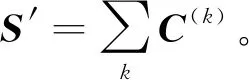
文献[11]根据图像库中对象位置普遍存在于图像几何中心的特点,提出了一种中心优先的特征加权方式,这种方式给临近几何中心的特征赋予较高的权值,而给远离几何中心的区域赋予较小的权值。但是,通常情况下对象出现在图像中某一个或多个连续区域,并且分布于图像的不同位置,所以物体应该有多个中心。特征聚合之后的特征映射中,响应值越高的位置,越有可能是对象所在的位置。为此,我们将响应值最高的前m个位置认为是中心点,假设一个中心点为c(cx,cy),图像中任意位置p(i,j)相对于c的位置权重为
αcxcyij=exp{-((i-cx)2+(j-cy)2)/(2σ2)},
参数σ与特征映射的长和宽有关[11],σ=1/3·min(W,H)。通过计算位置p相对于所有中心点的位置权重,选择出其中的最大值作为p的位置权重αij。将通过高权值位置感受野的对比,验证中心点比SPoC的中心优先方法能够更准确地发现对象区域。

图2 不同区域的采样Figure 2 Sampling in different areas
1.2 区域权重
S′中的任意位置对应着原图像中的某个部分,发现S′中表示对象内容的粗略区域,对于图像表示中的特征合理加权有着重要意义。对象区域可以依靠从S′中选择的一些大小相同的区域进行表示。首先,在S′中进行l尺度上的密采样,将S′划分成不同的区域,采样点之间间隔的像素间隔为l/2,采样得到的区域边长为4l,1≤l≤min(W,H)。采样过程如图2所示,采样区域的矩形边长为l,星型为采样中心。
不同的区域对于描述对象特征有着不同的重要性,同时相同区域内的深度特征对于描述图像特征有着相同的重要性。区域内响应的重要性决定着区域的重要性,区域R的区域权重计算公式为
其中:n为区域R中的响应个数;Ω代表特征映射中所有位置的集合;a=0.5;b=2。区域重要性分析中将每个区域认为是一个整体,即区域R中每个位置响应的区域重要性都为βR。由于每个位置可能会包含在多个区域当中,所以S′中任意位置p(i,j)的区域重要性βij为包含此位置的所有区域的重要性的平均值。
1.3 通道权重
通道重要性即同一个层次中,不同通道的响应在图像表示时的重要性。通道中非0元素所占比例越高,对于对象的描述能力越弱[12]。对于任意通道k,用Qk代表该通道特征映射中非0元素的比例。特征映射中的0元素表示对卷积核无响应,Qk越小则通道k对于某类特征的描述越精确,其计算公式为
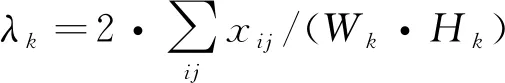
2 实验
2.1 数据集
数据集1是INRIA Holiday图像集[15](Holiday),包含1 491幅图像,其中500幅用于查询,并且每一幅图像对应着一个组,剩下的991幅图像用于测试检索结果。
数据集2是Oxford Buildings图像集[16](Oxford 5 K),图像集中包含了从Flicker中收集的5 062幅牛津地标性建筑的图像。这些图像可以分为11类,每个类别中的5幅图像用于查询。
数据集3是Oxford Buildings 100 K[17](Oxford 100 K),在Oxford 5 K的基础上增加的100 K图像组成。
图像库4是Oxford Paris[17](Paris),包含了6 412幅从Flicker上收集的巴黎地标的图像,共包括了埃菲尔铁塔等12个种类的查询。
2.2 实验设计
在Oxford 5 K、Oxford 100 K和Paris图像库中,我们将整幅图像作为卷积神经网络的输入。使用无监督图像检索方法[10-12],采用平均精度均值(mean average precision, MAP)来衡量检索的效果。该指标是针对查询集合的平均正确率的均值,MAP值越高,系统检索出来的相关文档越靠前。为了与文献[10]提出的方法进行比较,本文采用与该文献一样的网络结构与参数,即预训练卷积神经网络VGG16[18]。由于深层次的卷积和池化特征能够包含更多的语义信息,所以我们将Pool5层的深度特征作为基础,生成DWF图像表示。位置权重中的m越大,特征映射中不同位置的位置权重越相似,m越小则越能够突出不同位置的重要性,因此实验中我们设置m=3。区域权重计算过程中,尺度l的取值分别为3、4、5。算法采用余弦相似度衡量查询图像与图像库中其他图像之间的相似性,并按照相似性从高到低的顺序排列查询结果。查询扩展(query expansion,QE)能够有效提高检索性能,我们将前5个查询到的图像表示进行平均池化与L2归一化,进行二次查询与排序。我们的算法在图像表示的时候不需要改变图像的比例,在实验中保持了图像的原有特性。此外,由于Pool5层的特征映射维度为256,生成的图像表示也为256。
2.3 检索性能分析
如表1所示,DFW和DFW+QE两种方法与其他图像表示方法的MAP比较。Tr.Embedding[19]方法的MAP值最低,原因在于该方法采用人工特征SIFT作为局部描述子,通过局部特征聚合生成图像表示,而其他算法与此不同,均采用深度特征用于图像内容的描述,能够生成更接近语义的图像表示。与DFW相同,Neural Codes[8]采用预训练网络提取图像特征,但由于没有给不同位置的特征加权,所以,检索性能要低于DFW。R-MAC[10]通过多尺度采样的方式将图像划分为若干区域,并选择一些区域进行特征聚合生成图像表示,这种方法可以认为是一种特殊的特征加权方法,即被选择的区域权重为1,其他区域权重为0。背景信息在图像检索中也有一定意义,DFW给所有深度特征加权,并没有去掉背景信息,所以,有更强的图像全局表示能力。Spatial Pooling[20]将特征映射平均划分为若干细胞单元(cell),在不同细胞单元内通过最大池化的方法提取特征,该方法类似于DFW中的中心点计算方法,但Spatial Pooling的方法中,每个中心点必须在不同细胞单元之内,而DFW则没有此限制,可以更加灵活地发现中心点。此外,SPoC[11]采用了中心特征赋予较高权值的方法,这种方法在一定程度上突出了中心区域的特征,但是由于对象可能出现在图像的任意位置,中心加权的方式在处理某些图像的时候会给背景赋予较大权值。DFW采用了多中心的特征加权方式,以最大响应位置为中心,同时通过与中心的距离关系计算位置重要性,能够更加准确地发现对象区域。为了体现出本文位置重要性的优势,实验中将本文的位置重要性代替了SPoC中的高斯加权方式,发现SPoC的MAP在数据集Oxford和Holiday中提高了3%左右。
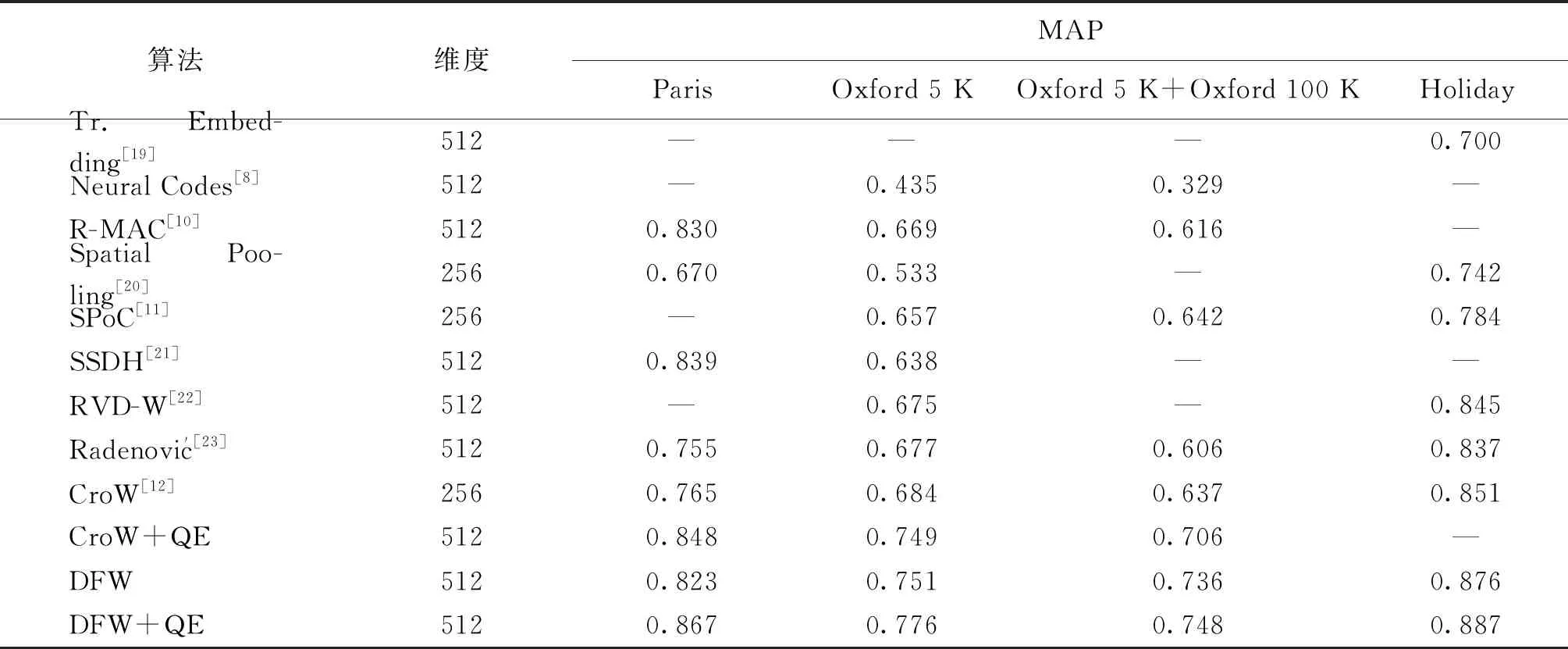
表1 DFW与其他算法的MAP比较Table 1 The comparison of MAP values between DFW and other methods
CroW[12]在特征加权的时候考虑到了位置重要性和通道重要性,其中位置重要性主要由激活映射来决定,并没有考虑到不同响应之间的位置关系,以及相邻响应之间在对象区域发现中的相关性,DFW考虑到近邻响应在图像区域位置的表示时应该有相似的作用,并在位置重要性的基础上加入了区域重要性,使得近邻位置响应的加权更加合理。此外,CroW在计算通道权重的时候将响应值是否为0作为稀疏性的判断标准,与此类似,在显著性图的显著区域发现问题中,通常将2倍的平均显著性值作为0元素判断标准,DFW 将2倍的响应平均值作为0元素判断标准,能够更加准确地给对象区域赋予较高权值。通过实验比对可以发现,DFW的MAP值比CroW高出了2%。当将DFW的通道权重代替CroW通道权重时,CroW的MAP则提高了1%左右,此结果说明本文的通道权重能够更好地识别对象特征。
通常情况下,图像表示维度越高,对于图像内容的刻画越准确。从表1可以发现, DFW在维度为256的时候,MAP值要高于Spatial Pooling和SPoC、CroW等。当采用Conv5-3层提取深度特征的时候,DFW的维度为512,MAP有了进一步的提升。查询扩展可以为查询提供更加准确的描述,实验中将首次查询结果的前5幅图像特征表示平均池化与归一化后,将结果与原图像进行合并。从表1中可以发现CroW和DFW算法在添加了查询扩展之后,MAP都有了显著提升。

2.4 对象可视化分析
图3为DFW+QE的图像检索结果,图中最左边一列的图像为查询图像,其中红色框标识出的区域为标准查询中提供的对象所在位置,其余为检索结果为前5的图像。从查询结果可以发现,该方法对于光照和对象的角度有着比较好的鲁棒性。此外还可以发现,检索结果中图像的背景特征不一致,该方法对不同背景信息有着较好的鲁棒性。其原因主要在于DFW将图像表示中对象的特征赋予了较高的权值,而背景特征赋予了较低的权值,所以在和池化的特征聚合过程中,对象的特征占据了主导因素,使得图像表示更加有针对性。

图3 DFW+QE的检索结果Figure 3 Retrieval results of DFW+QE

图4 SPoC与DFW位置重要性对比Figure 4 Comparison of position importance between SPoC and DFW
SPoC依据图像库中的普遍规律给图像中心区域赋予较高权值,而边缘区域赋予较低权值。而DFW则通过发现聚合特征映射中的高响应区域判断对象位置。图4展示了SPoC与DFW位置重要性在发现对象区域上的区别,图中4(a)为原始图像,4(b)第一行与第二行分别为SPoC与DFW位置重要性高权值部分对应的感受野。两种算法在特征映射权重最高的前20个位置中随机选择了5个位置,并显示出这些位置对应的感受野。通过对比可以发现,由于原始图像中对象的位置均没有处于图像的中心位置,SPoC将高权值赋予了背景上的特征,而DFW的位置重要性则赋予了对象区域。
区域权重计算的本质是根据对象出现的连续性特点,判断不同区域对于表示对象内容的重要性。如果l过大,会导致特征映射中采样区域对应原始图像中的范围过大,不利于对象区域的发现,如果l过小,赋权值的过程中不能体现出区域的整体性。实验中,我们对l的取值进行了3组测试,即{1,2,3}、{3,4,5}与{5,6,7},并发现当取值为{3,4,5}的时候取得了最好的检索效果。
3 结束语
本文提出的DFW图像表示方法,同时考虑到深度特征的位置重要性、区域重要性和通道重要性,使得生成的图像表示能够准确地体现对象的特征。DFW利用预训练卷积神经网络提取图像特征,利用特征映射的特点,加权并生成了低维度的图像表示。在图像检索的任务中,DFW的MAP比其他的算法高出2%左右。在未来的研究中,我们将研究如何构造基于深度加权特征的图像哈希算法,用于提高检索速度,并将其应用于司法领域。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
心理学报(2022年5期)2022-05-16
邮电设计技术(2021年2期)2021-03-13
当代陕西(2020年17期)2020-10-28
科学与财富(2019年27期)2019-10-25
数码世界(2019年9期)2019-09-07
电子制作(2019年14期)2019-08-20
人大建设(2018年5期)2018-08-16
计算机与数字工程(2018年5期)2018-05-29
证券市场红周刊(2018年3期)2018-05-14
