
混合决策信息系统的模糊效用三支决策模型
2020-02-08 08:39岳文琦童向荣张中喜
郑州大学学报(理学版) 2020年1期
岳文琦, 张 楠, 童向荣, 张中喜
(1.烟台大学 计算机与控制工程学院 山东 烟台 264005; 2.烟台大学 数据科学与智能技术山东省高校重点实验室 山东 烟台 264005)
0 引言
三支决策模型[1-2]是Yao等基于决策粗糙集理论模型并结合实际决策情况扩展的分类决策,相对于经典的粗糙集模型[3]提高了容错率,较二支决策更符合人们日常决策行为。三支决策模型已得到诸多学者的完善与发展[4-13],在数据挖掘、集成学习和信息处理等众多研究领域[14-17]得到广泛应用。文献[18]提出序贯三支决策模型的代价敏感分类方法。文献[19]提出了基于三角范数和三角余模的半三支决策空间到三支决策空间的转换方法。文献[20]提出基于行动的三支决策的有效性度量。文献[21]和文献[22]将期望效用理论引入三支决策模型,提出效用三支决策模型。三支决策模型中属性约简算法主要有代价敏感近似属性约简算法[23]、风险最小化属性约简算法[24]、正域最大化属性约简算法及定性和定量属性约简算法[25]。
混合决策信息系统中存在实值型、布尔型和类别型等混合类型数据,现有的三支决策模型不能处理混合类型数据。本文提出的模糊效用三支决策模型补充了三支决策模型在处理混合类型数据方面的空缺。该模型在混合决策信息系统中使用混合距离函数[26]处理混合属性,用高斯核函数定义决策表属性集的模糊T-等价关系,然后构造相应的模糊条件概率,使用效用函数构造概率阈值划分论域。本文在模糊效用三支决策模型中提出正域分布保持和最大效用属性约简算法。正域分布保持属性约简算法以保证约简前后不改变决策表正域为约简目标,可以求出不改变所有决策类正域的约简;最大效用属性约简算法以追求决策者最大满意程度为约简目标,可求出比决策表属性集更大的约简。近似分类质量实验表明正域分布保持启发式算法属性约简前后不改变决策表正域。J48正确分类率对比实验表明本文提出的两种算法高于文献[21]和文献[24]算法分类正确率;算法运行时间实验比较三种不同决策态度中两种算法的运行效率;约简效用表明最大效用启发式算法可以在混合决策信息系统中找到比决策表属性集更大效用的约简。
1 基本概念
1.1 混合决策信息系统
存在多种类型数据的信息系统或决策系统,称为混合决策信息系统。本节主要介绍混合决策信息系统和混合距离函数定义。
混合决策信息系统HIS=(U,AT=C∪D,V,f),其中:U表示对象的集合;AT表示属性的集合;C表示混合条件属性的集合;D表示决策属性集合;V表示属性值的集合;f:U×AT→V是一个信息函数,是对象到混合属性值关系的映射。
定义1[26]给定混合决策信息系统HIS=(U,AT=C∪D,V,f),C={a1,a2,…,an},n=|C|, ∀x,y∈U,a(x),a(y)∈V,混合距离函数HD(x,y)定义为

定义2[27-29]给定混合决策信息系统HIS=(U,AT=C∪D,V,f),∀x,y∈U,对于∀A⊆C,对象x和y之间的模糊关系用高斯核函数定义为
μA(x,y)反映了论域中的对象x和y对于属性集A的隶属程度,σ2的值由专家经验给定。
1.2 效用三支决策模型
效用是决策者在决策活动中对于决策后果的偏好[30],假定决策者对备择选项带来的效用进行预期,则决策者的最终决策目标为最大化期望效用。
给定状态集Ω={X,Xc},X表示对象x属于决策类,Xc表示对象x不属于决策类,决策方案A′={αP,αB,αN},αP表示判定对象x属于正域,αB表示判定对象x属于边界域,αN表示判定对象x属于负域。在不同状态下采取不同的决策方案的效用值如表1[21]所示。

表1 效用函数Table 1 The utility function
2 模糊效用三支决策模型
本节结合模糊概念和决策者的主观效用,提出一种新的模糊效用三支决策模型,在该模型中提出两个约简目标(最大效用和正域分布保持)。
2.1 期望效用决策规则
期望效用决策规则以追求决策者最大满意程度为决策目标,通过贝叶斯风险决策过程,获取决策规则,选取效用值最大的决策方案进行决策。
定义3给定混合决策信息系统HIS=(U,AT=C∪D,V,f),∀x,y∈U,∀A⊆C,模糊隶属度函数为μA(x,y),包含对象x的模糊类定义为
定义4给定混合决策信息系统HIS=(U,AT=C∪D,V,f),∀x,y∈U,∀A⊆C,模糊隶属度函数为μA(x,y),U={x1,x2,…,x|U|},决策类X∈U/D,混合信息系统下的模糊条件概率定义为
P(X|[x]μA)表示模糊T-等价类[x]μA被正确分类到X中的概率,模糊类[x]μA关于X的隶属度越高,x被划分到X中的概率越高;反之,模糊类[x]μA关于X的隶属度越低,x被划分到X中的概率越低。
决策者采取决策方案A′={αP,αB,αN}产生的期望效用为定义5。
定义5给定混合决策信息系统HIS=(U,AT=C∪D,V,f),∀A⊆C,X∈U/D,模糊类为[x]μA,采取三种决策方案αP、αB和αN的期望效用分别为
Ψ(αP|[x]μA)=u(λPP)P(X|[x]μA)+u(λPN)P(XC|[x]μA),
Ψ(αB|[x]μA)=u(λBP)P(X|[x]μA)+u(λBN)P(XC|[x]μA),
Ψ(αN|[x]μA)=u(λNP)P(X|[x]μA)+u(λNN)P(XC|[x]μA)。
定义6给定混合决策信息系统HIS=(U,AT=C∪D,V,f),∀A⊆C,决策类X∈U/D,模糊类为[x]μA,对于∀x∈U决策规则为:
1) 若模糊条件概率满足P(X|[x]μA)≥α,则判定x∈POSA(X);
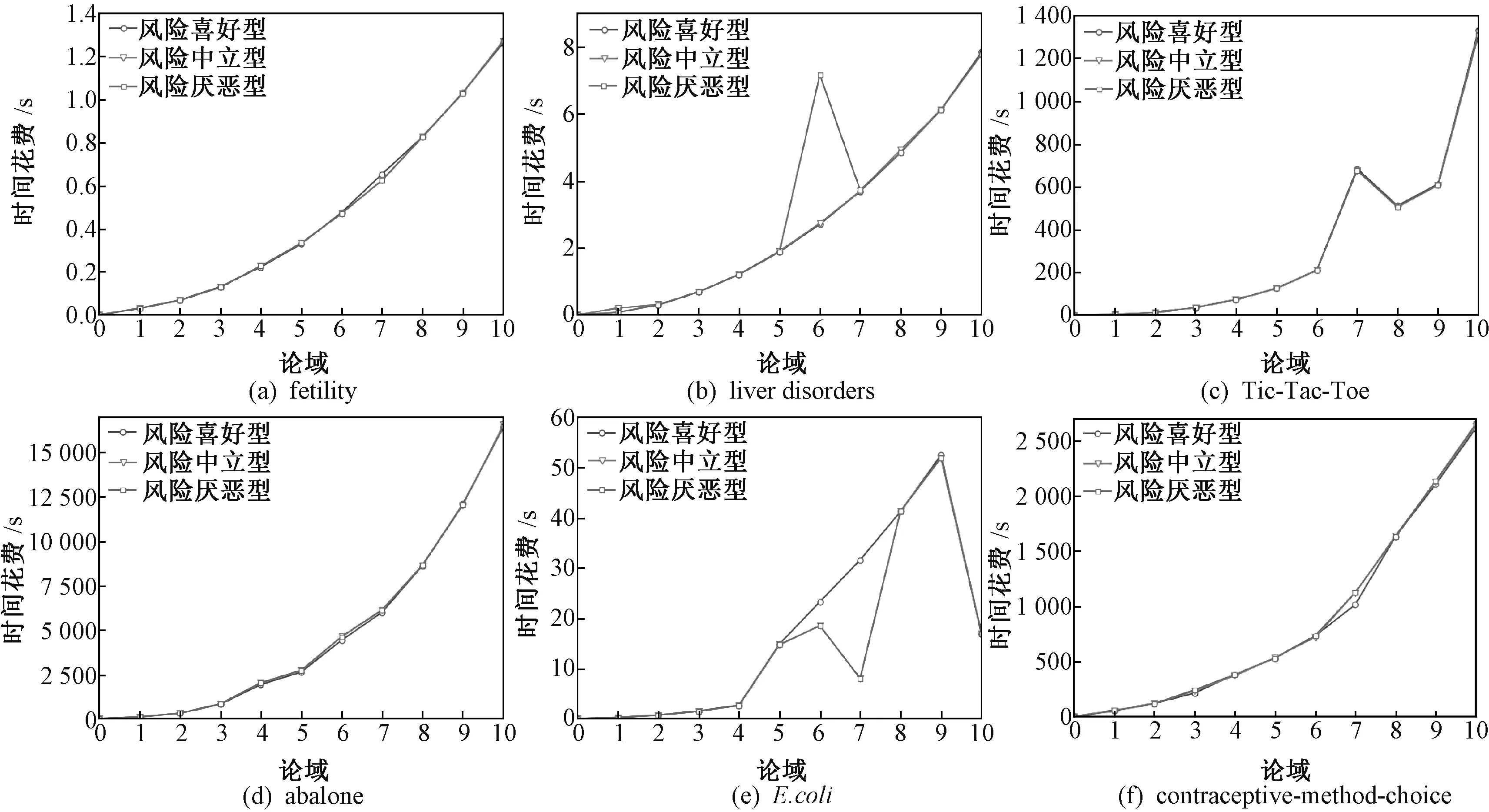
2) 若模糊条件概率满足β 3) 若模糊条件概率满足P(X|[x]μA)≤β,则判定x∈NEGA(X)。 现实生活中,决策者进行决策时,所有的决策结果产生的影响并不完全一致。信息系统中,决策表中不同决策类也存在差异。针对决策表中每个决策类生成不同的概率阈值,划分论域、正域、边界域和负域及全部效用为定义7。 定义7给定混合决策信息系统HIS=(U,AT=C∪D,V,f),决策类集合U/D={X1,X2,…,Xm},m=|U/D|,0≤β<α≤1,对于∀A⊆C,∀X⊆U/D,对象x划分到所有决策类X的正域、边界域和负域产生的正域效用、边界域效用和负域效用分别表示为 改革开放以来,历次党代会报告都以一系列新思想新观点新论断极大地推进了马克思主义中国化,促进了中国特色社会主义理论体系的形成和发展,党的十八大报告(以下简称报告)也是如此。笔者认为,报告对中国特色社会主义理论体系的新发展,主要体现在以下十三个方面。 信息量是一个事件所带来的具体信息的量度,本节主要内容为结合条件信息量[31]和正域分布保持[32]给出模糊效用三支决策模型下混合属性条件信息量的定义。 定义8给定混合决策信息系统HIS=(U,AT=C∪D,V,f),决策类集合U/D={X1,X2,…,Xm},m=|U/D|,0≤β<α≤1,对于∀A⊆C,混合属性集A的条件信息量定义为 由条件信息量的定义可得 本节中两个约简目标(最大效用和正域分布保持)均采用前向贪婪循环算法进行属性约简。 定义9给定混合决策信息系统HIS=(U,AT=C∪D,V,f),且A⊆C,当且仅当A满足以下两个条件时,A是C的一个最大效用属性约简。 1)UtilityA≥UtilityC; 2) 对于∀A′⊂A,UtilityA′ 定义10给定混合决策信息系统HIS=(U,AT=C∪D,V,f),A⊆C,ai∈C-A,最大效用启发式属性约简算法的外部属性重要度为 定义11给定混合决策信息系统HIS=(U,AT=C∪D,V,f),A⊆C,0≤β<α≤1,当且仅当A满足以下两个条件时,A是C的一个正域分布保持属性约简。 定义12给定混合决策信息系统HIS=(U,AT=C∪D,V,f),A⊆C,ai∈C-A,正域分布保持启发式属性约简算法中的外部属性重要度为 构造混合决策信息系统中的最大效用启发式属性约简算法(forward greedy algorithm of maximal utility attribute reduction, FG-MUAR),算法如下。 算法1最大效用属性约简算法 输入:混合决策信息表HIS=(U,AT=C∪D,V,f)。 输出:决策表的一个约简A。 A=∅。 计算决策表所有属性集效用UtilityC。 若UtilityA 若不满足条件则结束循环。 对于∀ai∈A,若满足条件UtilityA-{ai}≥UtilityA,则A=A-{ai}。 输出约简A。 构造混合决策信息系统中的正域分布保持属性约简算法(forward greedy algorithm of positive region distribution preservation, FG-PRAR),算法如下。 算法2正域分布保持属性约简算法 输入:混合决策信息表HIS=(U,AT=C∪D,V,f)。 输出:决策表的一个约简A。 Core(C)=∅。 A=Core(C)。 若不满足条件,则结束循环。 输出约简A。 本节实验采用6个UCI数据集(取自http://archive.ics.uci.edu/ml/index.php)进行实验,数据集均带有分类属性。所有实验均在Windows7、CPU Intel®CoreTMi5-6500、8.00 GB内存的个人计算机上进行,所用编程环境为Python3.6。实验分为算法运行时间和实验对比表(近似分类质量、J48分类正确率、约简效用)两个部分。 使用函数式u(λΔ)=d(-λΔ+c)b(Δ∈{PP,BP,NP,NN,BN,PN})[30]作为效用函数式,给定参数取值范围d∈[1,10],c∈[1,10],λ∈[0,10]。 表2 实验数据集Table 2 Experimental data sets 本文提出的FG-PRAR算法与FG-MUAR算法原始数据和属性约简后的近似分类质量[3]如表3所示。 表3 近似分类质量Table 3 Approximate classification quality FG-PRAR原始数据表示FG-PRAR算法中决策表的近似分类质量。FG-MUAR原始数据表示FG-MUAR算法中决策表的近似分类质量。 FG-PRAR算法可以保持所有决策类的正域不变,因此FG-PRAR约简与FG-PRAR原始数据的近似分类质量数值相同。FG-MUAR约简与FG-MUAR原始数据对比,近似分类质量发生改变,原因是FG-MUAR约简前后会引起决策表正域的改变。近似分类质量数值为0是由于随机产生的概率阈值过大,因此划分出的决策表正域为空集。近似分类质量数值为1是由于随机产生的概率阈值过小,导致论域中所有对象均被划分到决策表正域。 使用Weka软件中J48分类器并采用十折交叉验证法验证决策表的4种算法属性约简后的J48分类正确率。本次实验使用10次随机产生的概率阈值,其平均分类正确率如表4所示。 原始数据表示决策表的J48分类正确率。表4中本文所提出的FG-PRAR算法属性约简结果的分类正确率在多数情况下可以大于等于原始数据的分类正确率。本文所提出的FG-PRAR算法的正确分类率均大 表4 J48分类正确率Table 4 Classification accuracy comparision with J48 于文献[21]中最大期望效用算法(maximum expect utility, MAXEU)和文献[24]中最小决策损失算法(minimum decision cost, MINDC)的正确分类率,存在两种原因:1) MAXEU算法和MINDC算法缺乏处理离散型数据和混合数据的能力,所以要在属性约简前对数据进行预处理,会对数据造成一定的损失,最终对数据的分类正确率造成一定的影响;2) MAXEU算法和MINDC算法均未考虑到决策表中不同决策类的差异,没有为每个决策类生成不同的概率阈值,而是统一采用一致的阈值划分论域,因此这两种算法在6个数据集上的分类正确率均低于本文提出的FG-PRAR和FG-MUAR算法分类正确率。 FG-MUAR算法保证属性约简后不降低原始决策表的效用,约简应该具有比原始决策表更高或者相等的效用,据决策者对待风险的三种主观态度,可以将效用函数分为:当b=1时,效用函数为风险中立型(RN);当b>1时,效用函数为风险厌恶型(RA);当b<1时,效用函数为风险喜好型(RP)。FG-MUAR算法在三种风险态度下约简结果的效用值如表5所示。 表5 约简效用Table 5 The utility of decision table and reduct 在三种风险态度下使用的效用函数参数不同,因此三种风险态度下的决策表效用不同。FG-MUAR算法的目标即为使决策者的效用值最大化,由表5可以得知,FG-MUAR算法在6个数据集中约简结果的总效用值均大于原始决策表的总效用值,因此约简结果有效。对比三种决策态度中约简结果的效用值相差较小,表明三种不同决策态度中决策者对待决策结果的满意程度基本一致。 不同决策者对待风险的决策态度不同,在决策过程中的决策行为也不完全相同。为分析两种算法在三种不同决策态度中的决策效率,比较FG-PRAR和FG-MUAP两种算法在决策者不同决策态度中随着论域变化的运行时间。图1和图2实验采取的方式是将每个数据集的论域数目均等分成十份,依次加入一份样本,比较加入样本后FG-PRAR算法在三种决策态度中的运行时间,x轴表示样本份数,y轴表示算法运行时间。 图1 FG-PRAR算法随论域数目增加运行时间的变化Figure 1 The running time of the FG-PRAR algorithm increases with the sizes of the universe 由图1可知,随着样本数的增加,三种决策态度中FG-PRAR算法运行时间基本一致,图1中数据集(b)、(d)随着样本数的增加,风险中立型的算法运行时间没有严格单调递增,是因为不同样本下使用不同的概率阈值划分的正域可能不同,当前样本数使用的随机概率阈值划分出的正域比前一份样本数使用的概率阈值划分出的正域较小,因此算法运行时间略有下降。本文提出的FG-PRAR算法是保持约简结果正域与决策表正域一致。总体来看,不同决策态度对于FG-PRAR算法运行时间影响较小。 对于FG-MUAR算法,三种决策态度中样本数与算法运行时间的关系如图2所示。 图2 FG-MUAR算法随论域数目增加运行时间的变化Figure 2 The running time of the FG-MUAR algorithm increases with the sizes of the universe 由图2可知,在决策者不同决策态度中,随着论域的增加,运行时间曲线的变化并不完全一致,不同决策态度对于FG-MUAR算法运行时间略有影响。FG-MUAR算法计算正域、负域和边界域的全部效用,相对于FG-PRAR算法的运行时间更长。图2数据集(b)、(c)、(e)中的三种不同风险态度曲线随着论域数目增加,并不是严格单调递增,这是由于随着样本数的增加,每个属性的模糊T-等价关系表也随之变化,由此计算的模糊条件概率可能增加、不变或减少,从而引起效用值的变化,最终影响FG-MUAR算法的运行时间。在现实生活中,决策者的心理满足程度也可能随着时间的变化或者事件的改变而发生变化,图2曲线的不单调变化更贴合实际生活中决策者的决策情况。 在混合决策信息系统中,本文结合模糊和效用提出一种新的模糊效用三支决策模型,提高了三支决策模型处理混合数据的能力。本文在该模型中提出正域分布保持和最大效用启发式属性约简算法,实验表明了两种算法的有效性。然而效用函数在决策表属性约简过程中并不具有单调性,两种算法仍需遍历删除冗余属性求解约简,寻找三支决策模型中主观效用与客观数据结合的单调启发式因子是后续所要研究的主要内容。
2.2 正域分布保持定义
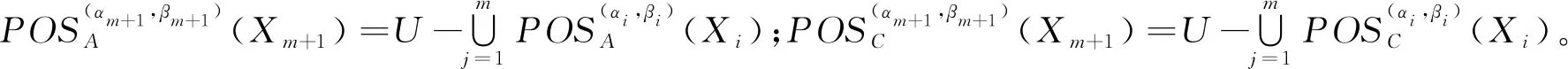
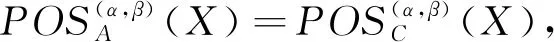
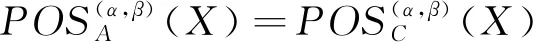
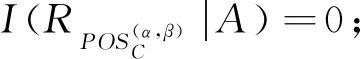
3 混合模糊效用三支决策模型属性约简算法
3.1 算法介绍
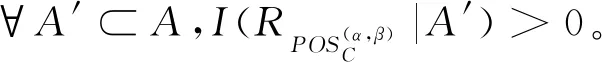
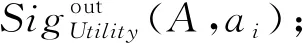
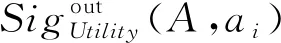
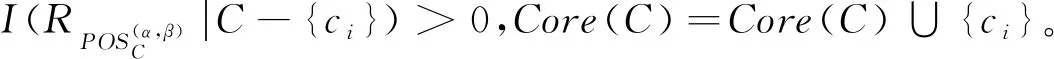
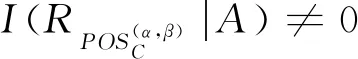
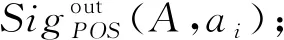
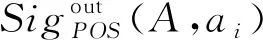
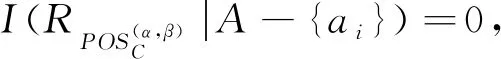
4 实验分析
4.1 实验对比表

4.2 算法运行时间
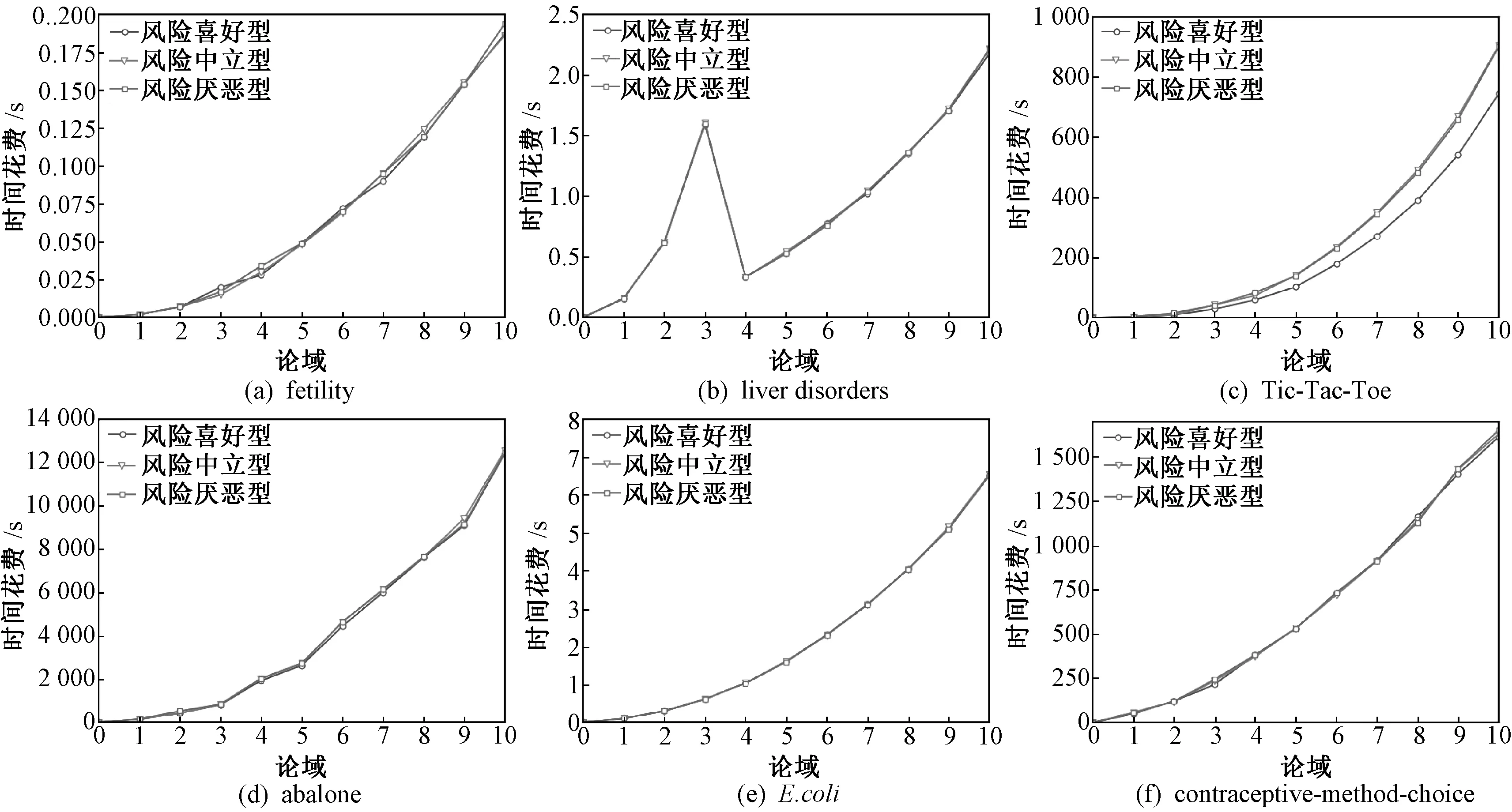
5 结束语
猜你喜欢
哈尔滨轴承(2022年1期)2022-05-23建材发展导向(2021年7期)2021-07-16洛阳师范学院学报(2021年2期)2021-03-31中国药学药品知识仓库(2021年18期)2021-02-28小型微型计算机系统(2019年9期)2019-09-09计算机与生活(2019年3期)2019-04-18冰雪运动(2018年3期)2018-12-29电子制作(2018年11期)2018-08-04华东师范大学学报(自然科学版)(2018年3期)2018-05-14消费导刊(2017年20期)2018-01-03
