
面向军事信息系统的自动化软件部署算法
2020-02-07 13:33戴文博卫津逸
计算机与现代化 2020年1期
戴文博,徐 珞,卫津逸
(华北计算技术研究所创新中心,北京 100010)
0 引 言
软件部署是针对软件进行安装和配置的过程,其最终目标是能够使软件在客户端上正常运行。软件部署的工作内容十分复杂,在面向服务(或客户端/服务器)环境中,有许多不同的客户端和服务器的类型[1],客户端在访问服务器时会有多种多样的硬件和软件先决条件要求。现阶段的软件部署方式分为手动软件部署和自动软件部署这2种。手动软件部署仍然是当下主流的部署方式,针对小型的软件工程项目,由于其软件量小、依赖少,手动部署和自动部署并没有太大的差异,然而,由于大型的军事信息系统软件库大、依赖结构复杂等问题,手动部署需要大量的人力和时间,往往一套完整的系统布置就需要一周的时间,当版本产生大量迭代时会严重影响项目进度。而通过自动部署工具完成的软件部署能够轻松高效率地完成软件的安装配置。目前国内外已经有很多这方面的工具[2-5]。这些工具分为2类,其中之一是以Jenkins、Apt为代表的C/S类型的部署管理工具,另一类是以Docker为代表的虚拟化容器工具。
Jenkins是现阶段自动部署中最常见的工具,它是一个开源的、可扩展的持续集成、交付、部署的基于Web界面的集成工具平台。它允许持续集成和持续交付项目,无论用的是什么平台,可以处理任何类型的构建或持续集成。作为现在使用最为广泛的自动部署工具,Jenkins能够自定义插件,通过各种各样的插件提供相应的自动部署功能。
Apt是Linux下的包部署管理工具,当客户端需要安装、升级或删除某个软件包时,客户端计算机取得DEB索引清单压缩文件后,会将其解压置放于/var/state/apt/lists/,而客户端使用apt-get install或apt-get upgrade命令的时候,就会将这个文件夹内的数据和客户端计算机内的DEB数据库比对,知道哪些DEB是已安装、未安装或是可以升级的。
Docker也是一种常见的自动部署工具,它是PaaS提供商dotCloud开源的一个基于LXC的高级容器引擎,源代码托管在Github上,基于go语言并遵从Apache2.0协议开源。文献[6]指出Docker是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何Linux机器上,也可以实现虚拟化。Docker部署是完全镜像式的部署,需要先在镜像上完成部署后再移植。
军事信息系统从业务方面来看,业务种类繁多,各业务之间关系交错复杂;从研制角度来看,军事信息系统研制工作往往会有大量不同的厂家,各厂家软件无法保持一致,服务量大,技术不统一,从而导致软件依赖关系复杂,因此,需要屏蔽不同技术实现差异,提出统一的规范化软件描述,并且对各软件依赖关系进行统一。
然而针对大型军事信息系统,上述Jenkins并没有很好地解决依赖问题,Apt只能作为Linux软件运行,无法进行跨平台部署,Docker在面对软件数量繁多,部署情况复杂的情况下很难全部列举镜像。因此本文提出一套规范化的软件部署模型,并且通过XSD进行描述,其次在软件依赖冲突算法的基础上对深度优先遍历算法进行改进,提出软件部署序列生成算法,并通过实验验证软件部署的效率有所提高。
1 自动部署框架
1.1 规范化软件部署结构
软件部署模型的内容可以分为资源、机制、策略和属性这4大块,如图1所示。其中,资源模型是指在部署期间的所有实体,包括已部署的软件和目标的系统。机制模型定义了在部署期间对资源产生影响的操作(安装、配置、复制、删除等)。策略模型是指对机制选择的执行方式描述,例如为了提高系统安全级别,当前安全策略涉及禁止安装程序。属性模型描述了资源、机制、策略模型的属性,用于参数化部署目标,属性可以用来实例化当前的资源,例如部署软件的大小、依赖文件、相关约束等。
部署模型是以递归的形式存在的,每一个实例都由其他各部署模型组成。例如,当前的部署机器可能是由各部署目标软件组成的,因此,每个模型都提供实体的结构化以及分层描述[20-24]。
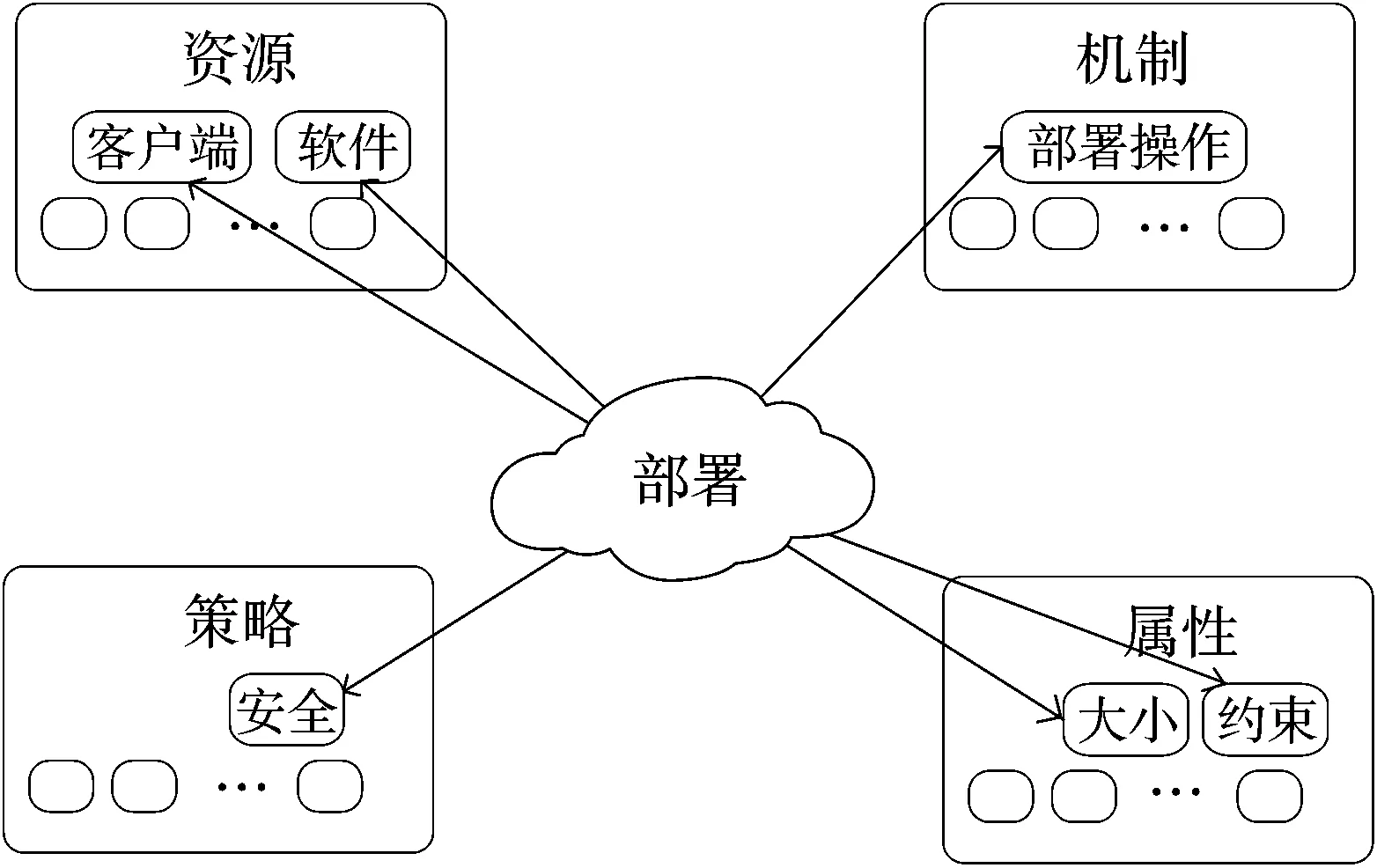
图1 规范化软件部署结构
资源,指定为目标系统或者部署的软件,它可以表示为资源组件的树结构的抽象形式。例如,一个大型信息系统中由数台计算机组成,每台计算机都拥有一个操作系统和多个应用程序。
机制,是一种可以在部署期间执行的操作,对目标系统产生影响。它可以表示基本操作(例如传输、复制等)或更繁复的操作,例如安装、配置、卸载等。
策略,策略的选择来源于资源以及机制的选择,这里可选择基本策略,如维护系统的某个属性,或者复合策略,如在相关的仅在进行资源优化策略后进行更好的服务质量策略。
属性,属性描述了资源的各详细属性,例如软件的具体属性有软件大小、软件运行硬件要求、软件依赖应用程序等。
1.2 自动化软件部署模型

图2 自动化软件部署模型
自动化软件部署由核心服务器、软件库服务器、部署客户端这3个部分组成,如图2所示,客户端从核心服务器请求数据,生成软件安装目标脚本,核心服务器基于该脚本,根据软件依赖冲突监测算法生成软件的依赖关系表,将该表作为软件部署安装算法的输入,得到软件安装顺序表,通过该表向目标客户端部署软件。
1.3 形式化软件描述
由于大型军事信息系统中,软件种类复杂、数量繁多,因此,需要对软件进行统一的形式化管理,本文通过使用XSD进行软件描述[8-13]。
XSD全称是XML Schema,是指XML结构定义,即可标记拓展语言,通过这种语言使得计算机之间可以处理各种各样的信息。XML Schema描述了XML文档的结构,可以用一个指定的XML Schema来验证某个XML文档,以检查该XML文档是否符合其要求。文档设计者可以通过XML Schema指定一个XML文档所允许的结构和内容,并可据此检查一个XML文档是否是有效的。XML Schema本身是一个XML文档,它符合XML语法结构,可以用通用的XML解析器解析它。XSD具有以下优点:
1)XML Schema基于XML,没有专门的语法;
2)XML Schema可以像其他XML文件一样解析和处理;
3)XML Schema支持一系列的数据类型(int、float、Boolean、date等);
4)XML Schema提供可扩充的数据模型;
5)XML Schema支持综合命名空间;
6)XML Schema支持属性组。
根据软件的部署需求以及军事信息系统分类复杂的特性,将软件描述成3个部分,分别是软件固有属性、软件依赖库以及软件部署状态。其中软件固有属性包括软件名称、软件所需运行内存大小、软件所需运行硬盘大小以及软件描述备注。软件描述文件如下:
1.4 软件结构存储
基于软件形式化描述,每个软件都有其相对应的直接依赖关系,此外,如果当前软件的依赖软件还依赖于其他软件,此时即产生了间接依赖关系,由于间接依赖关系众多,并且由于软件版本的更新迭代时常会发生变化,因此,采用树结构进行各软件的存储[14]。
每当该软件需要依赖于其他的软件时,即增加一个它的孩子节点,将其放置于被依赖软件中,以此增加树结构,直到所有软件全部添加至树或森林中。所有的叶节点即为不需要依赖的软件。
2 软件依赖冲突检测
2.1 软件依赖冲突定义
部署软件需要通过依赖其他软件才能够安装运行,此时,该部署软件与依赖软件间的关系称之为部署依赖关系。具有依赖关系的软件必须要在其依赖的软件被部署以后才能够开始部署。
根据软件依赖冲突的性质,可以将其分为3大类:强依赖、弱依赖以及负依赖。
强依赖是软件部署的必要条件,如果没有满足强依赖的条件,则部署无法进行下去。
弱依赖是指软件部分组件指定的条件,如果当前依赖不存在,软件可以正常使用,但是相关组件服务无法使用。
负依赖是指禁止部署的冲突,当前目标机器中已经存在的软件同部署软件冲突,二者即为不可兼容,互为负依赖。
对此,基于文献[7]形式化定义了部署及依赖关系。
定义1声明一个二元组(s1,s2),该二元组称作软件依赖r,s1是依赖软件,s2是s1依赖的软件。s1和s2具有以下关系:s1∩s2=Ø。
定义2声明一个三元组(S,E,R),该三元组称为一次软件部署D,其中,S是指所需部署的所有软件的集合,E代表的是目标及其存在的软件集合,R代表的是软件依赖的集合。D具有以下关系:
1){s1|(s1,s2)∈R}⊆S;
3)S∩T=Ø。

2.2 依赖冲突检测
根据上述形式化部署依赖定义,可以得到相对应的依赖冲突检测算法。
进行部署完整性检查,在一次部署过程中一个完整的部署意味着该部署中的所有软件均存在于部署软件集合中。即,{s1|(s1,s2)∈R}⊆E∪S。
其次进行依赖循环性检查,如果存在循环的软件依赖,则会导致部署不可进行,因此需要根据软件的属性递归寻找目标软件的依赖软件,直至依赖软件集合为空,或者不存在依赖关系。即,如果部署D中满足∀s∈S·(ss),则D中不存在循环依赖,反之,满足上述条件,则说明本次部署是不可进行的。
2.3 自动化依赖冲突解决
通过自动化解决依赖冲突,可以解决软件的强依赖和负依赖冲突问题导致的安装部署问题。基于依赖冲突的性质,可以将依赖冲突分为3类:
1)硬件强依赖冲突。硬件依赖冲突是由于部署软件与目标机器之间存在硬件约束关系未符合要求的情况。例如部署软件所需硬盘容量大于实际目标机器硬盘容量,或者部署软件所需运行内存大于实际内存分配容量。对于该硬件冲突,在实体机器上无法采用自动化的方式解决,只能将错误信息返回给用户,并提供一个解决方案[15]。
2)操作系统强依赖冲突。操作系统依赖冲突是指目标机器上的操作系统不符合部署软件的要求,例如当前部署软件需求14.04版本以上的Ubuntu系统,但是目标机器上的Ubuntu版本只有10.01,此时无法完成部署,返回给用户错误信息,并提供解决方案[16]。
3)软件负依赖冲突。软件依赖冲突是由于已经存在于目标机器上的软件和需要部署的软件不兼容所导致的依赖冲突。例如,Python2和Python3互相不兼容[17],但是可能需要同时使用。当发生此类依赖时可能产生3种情况:
①当前目标机器上软件由于版本冲突导致的部署失败,此时如果部署版本比目标机器上低则不需要部署,从部署状态信息中删除;如果部署版本比目标机器上的高,则删除目标机器版本,安装当前版本软件。
②当前目标机器上软件与部署软件负依赖冲突,此时核心服务器会备份当前机器环境,检查冲突软件是否处于依赖库中,如果不存在,则删除,否则产生依赖循环,无法完成软件部署,将出错信息返回给用户,并提供解决方案。
③当前目标机器上软件在运行过程中无法部署软件,此时需要关闭当前软件,再次重新进行软件安装。
3 软件部署序列生成算法
3.1 算法描述
在一次软件部署中,如果部署D(S,E,R)不是完整的,即部署D上有依赖软件未列入部署状态信息或未在部署目标机器上存在,则需要遍历部署软件信息,找到未列入的依赖软件并将其列入部署信息中,即如下查找依赖软件集合[18-20]:{s1│(s1,s2)∈R}(S∪E)。
在一次部署D中,当前部署软件的依赖软件部署序列,可以采用由深度优先遍历算法(DFS)改进的软件部署序列生成算法,具体算法过程如下:
1)任选一个顶点v1开始进行深度优先遍历,访问该顶点。
2)沿深度方向,依次遍历v1的未访问邻接点。若访问到结束则继续执行下列步骤,如果访问到所需部署软件的节点v2,则执行步骤4。
3)一次遍历完成后,若有未访问顶点,则任选一个未访问顶点作为起始点,并执行步骤2。
4)将当前软件库树剪枝为以v2为根的软件部署树。
5)以当前软件为顶点v2继续进行深度优先遍历,访问该节点,记录进入部署序列,继续执行下一步。
6)继续沿深度方向,依次遍历v2未访问的节点,否则判断该节点上的软件是否已经在目标机器上部署,如果已经部署则将该节点及其孩子节点从部署树中删除,否则记录进入部署序列,重复执行步骤6,直到当前遍历结束。
3.2 算法伪代码
根据算法步骤,具体代码实现如下:
bool visited[MAXNODE]; //顶点的访问标识数组
void Find_d_software(Tree Softwares){ //初始化深度优先遍历
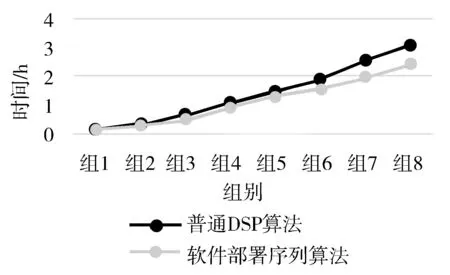
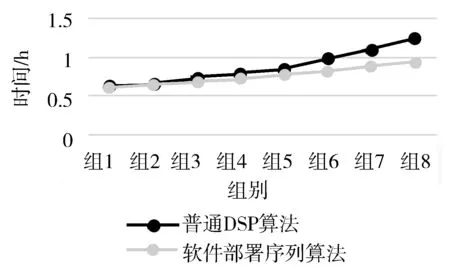
for(i=0; i visited[i]=false; } } TREE find_d_software(TREE Softwares, int v1){ //深度优先遍历软件库,直到找到需要部署软件为止 Visit[v1]; visited[v1]=true; w=FirstAdj(Softwares,v1); if(v1.softwareinfo.name==Deployment_software.name) { w=0; Deployment_software.id=v1; deployment_tree=cut_off_tree(Softwares,v1); //根据当前部署顶点,生成新树 } while(w!=0){ if(!visited[w]{ DFS(Softwares,w); } w=NextAdj(Softwares,v1,w); } } void make_d_sequence(TREE secquence_tree, int v2){ //根据生成的新树,进行遍历,生成部署序列树secquence Visit[v2]; visited[v2]=true; w=FirstAdj(Softwares,v1); if(software_if_exit(v2.software_infor_name));//判断当前节点软件是否已经部署在目标机器上 secquence_tree=delete_sequence(secquence_tree,v2);//删除目标节点及其子树, secquence=(secquence,v2);//将当前节点软件放入部署序列中,sequence以链表形式存储 while(w!=0){ if(!visited[w]{ DFS(Softwares,w); } w=NextAdj(Softwares,v1,w); //返回:v的在邻接点w后的邻接点,0表示不存在 } 由于使用的仍然是DSP深度优先遍历的改进,因此算法的时间复杂度并没有显著的变化,仍然为o(n2),但是由于进行了树的剪枝,因此当遍历到需要部署的软件后,树的结构发生变化,遍历时间会减少,并且由于记录了已经在目标机器上部署的软件,因此,减少了针对已经部署软件,也进行了剪枝,减少需要遍历的内容。 为了验证软件部署序列算法的效率以及正确性,本文将其与未使用软件部署序列算法的自动软件部署进行对照,并且对软件库软件个数、部署软件个数,采用控制变量法进行了2组实验,实验1保持了在软件库个数一致的条件下,通过增加部署软件个数,对部署时间进行了测量;实验2通过保证部署软件个数一样的情况下,对软件库软件总个数进行增加,并测量软件部署时间。表1、表2分别为实验1、实验2的详细实验信息。 表1 实验1详细信息 软件数量组1组2组3组4组5组6组7组8软件库软件个数300300300300300300300300部署软件个数104080120160200240280 表2 实验2详细信息 软件数量组1组2组3组4组5组6组7组8软件库软件个数305090120150180240300部署软件个数2020202020202020 根据本文设计实验,得到实验1部署时间关系如图3所示。 图3 实验1部署时间关系图 根据图3实验1部署时间关系图,可以明显地看出,随着部署软件数量的增多,部署时间会越来越长,这是由于随着部署软件数量增多,部署依赖关系越来越复杂,且遍历时间由于递归关系呈指数增长,但是使用了软件部署序列算法后,部署时间有所下降。 图4 实验2部署时间关系图 根据图4实验2部署时间关系图,可以明显地看出采用软件部署序列算法后,无论软件库总数如何增大,其部署20个软件的部署时间增长速度较缓,反观采用普通DSP算法的部署组数增长速度较快,这是由于软件部署序列算法遍历到已经部署好的软件时可以直接跳过遍历,并且只需要根据当前部署软件树部署即可,而不需要进行全局的软件节点遍历。 此外,在实验中同时也出现了2个始终无法部署的软件,经检查,发现这2个软件的共同依赖软件并没有列入软件部署库。 本文相对于软件部署冲突检测机器自动调整算法中采用的图结构而言,采用树的结构进行软件部署,软件存储结构有所优化,软件部署效率从而提升;相对于基于敏捷开发的持续部署系统关键技术研究中心采用的软件构建描述方法,本文使用了XSD描述方法,描述结构清晰,描述方式更加便捷。 本研究针对现有的软件部署方法无法满足军事信息系统进行持续部署的工作现状,根据软件依赖关系,提出了基于依赖关系的自动化软件部署模型,并提供了一个软件部署的描述方法,在此基础上提出了软件部署序列算法,并且提供了实验,验证了此算法的可靠性。3.3 算法分析
4 软件部署序列算法验证
4.1 实验设计


4.2 实验结果
5 结束语
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
成都信息工程大学学报(2021年5期)2021-12-30
今日农业(2021年7期)2021-07-28
非公有制企业党建(2020年5期)2020-06-16
传媒评论(2019年5期)2019-08-30
电影(2018年8期)2018-09-21
传媒评论(2018年4期)2018-06-27
传媒评论(2018年4期)2018-06-27
传媒评论(2018年2期)2018-06-06
