
基于双向概念格的坦克驾驶模拟训练关联规则挖掘
2020-02-06 00:35邓青薛青高恒翟凯
兵工学报 2020年12期
邓青, 薛青, 高恒, 翟凯
(陆军装甲兵学院 演训中心, 北京 100072)
0 引言
随着仿真技术在军事领域的应用,模拟训练已成为世界军事强国普遍采用的一种重要训练手段[1-2]。通过坦克驾驶模拟器开展模拟训练,可以在保证经济性的同时弥补实装训练准备周期长、训练代价高等缺陷[3-4],大大提高训练效率。坦克驾驶模拟训练结束往往会产生大量数据,包括训练操作数据、受训人员数据、训练科目数据、训练结果数据等,这些数据具有规模大、维度高、非线性等特征,相互之间蕴含着各种复杂的关系[5]。在传统的坦克驾驶模拟训练结果分析中,主要是以人为主的统计分析,易受分析人员专业知识、个人偏好的主观影响,对训练的影响因素考虑不全,无法精确指导受训人员进行坦克驾驶操作技能训练,也难以从这些复杂数据中发现有价值的训练规则。为解决这一问题,关联规则挖掘被引入坦克驾驶模拟训练数据的分析,以期从中获取训练指导规律。
关于坦克模拟训练的关联规则挖掘,国外公开的文献资料不多,对具体的挖掘过程及算法也没有涉及。美军训练与条令司令部提出了战斗增强分析法,采集模拟训练中的作战部署、作战半径、车辆位置等数据,研究坦克分队战场机动的影响因素[6]。美国陆军研究院开发了数据挖掘工具包,内置关联分析套件,成功应用于装甲装备战损分析,为装备试验提供了依据[7]。美国兰德公司基于联合冲突战术模拟训练系统,运用定制的关联规则挖掘算法研究了坦克模拟训练交战数据,辅助装备使用决策同时减少昂贵的装备测试费用[8]。国内王泽璞等[9]运用FP-Growth算法对火炮模拟训练数据进行了关联分析,但该算法采用频繁模式树的非线性结构,存储代价大且搜索效率随着树的增长明显下降。邓桂龙等[10]、马建军[11]、MOHAMMAD等[12]运用Apriori算法分别研究了某型空地作战模拟训练系统和炮兵专业技术训练产生的数据,得到了一些有趣的规则,但Apriori算法每次生成频繁项集都需要扫描数据库,导致计算开销大,在大数据集上运行效率不高。而针对坦克驾驶模拟训练数据的关联规则挖掘还很匮乏,以上传统的方法由于存储开销、计算效率问题,无法直接用于坦克驾驶模拟训练数据。
概念格是一种新型知识表示模型,主要思想是根据二元关系提出概念结构[13-14],体现概念外延和内涵的包含关系。通过搜索概念内涵可以快速得到闭项集,且不会丢失任何信息,因此概念格非常适合产生蕴含规则。运用概念格的核心是要搜索构造概念节点,概念格的经典Bordat[14]算法通过拆分形式背景建立子概念格,再对子概念格进行合并,整个拆分、合并操作比较繁琐,且无法处理多值数据。
针对坦克驾驶模拟训练数据的特点[15],本文提出一种基于双向概念格的关联规则(BCLAR)挖掘方法。该方法利用矩阵布尔化将多值数据转化为单值背景,然后计算内涵秩和外延秩,分别从格的顶层、底层构建概念节点,最后增加规则后件固定作为约束条件,过滤不相关的概念节点,提取用户所需的关联规则。
1 基于BCLAR挖掘方法
定义1假设K=(O,A,R),其中,O是对象集合,A是属性集合,R是从对象集映射到属性集的二元关系[16],即R⊆O×A,则称K是形式背景。
通过形式背景的定义可以将待挖掘的数据对象进行有效表达,对于坦克驾驶模拟训练产生的数据决策表可视为一种特殊的形式背景。
定义2对于X⊆O,Y⊆A,记X*={y∈A|∀x∈X,(x,y)∈R},Y′={x∈O|∀y∈Y,(x,y)∈R},X*代表对象集X中所包含的相同属性集合,Y′代表具有属性集Y中全部元素的对象集合。若X*=Y,Y′=X同时成立,则称C=(X,Y)是形式背景中的概念[12]。其中:X是概念外延,记X=Ext(C);Y是概念内涵,记Y=Int(C);K=(O,A,R)中的所有概念集合记作B(K)。
定义3假设C1=(X1,Y1)、C2=(X2,Y2)是形式背景K=(O,A,R)的两个概念,当C1≤C2⟺X1⊆X2⟺Y2⊆Y1,则“≤”称为概念之间的偏序关系,C2是C1的父概念,C1是C2的子概念。B(K)通过偏序关系所构成的完备集L(K)=(B(K),≤)称为概念格[13]。
对一个形式背景K=(O,A,R)而言,都存在与其对应的唯一偏序关系集,不论形式背景中的数据对象、属性关系如何排序,它们最终所生成的概念格都具有唯一性,这是概念格的一个重要性质,也是构建概念格过程中进行双向搜索的重要依据。
对概念格中的概念C1=(X1,Y1)、C2=(X2,Y2)进行交、并操作,有
C1∩C2=(X1∩X2,((Y1∪Y2)′)*),
(1)
C1∪C2=(((X1∪X2)*)′,Y1∩Y2).
(2)
根据定义2可知,按上述交、并操作后,C1∩C2、C1∪C2依然是概念,保证了概念格的完备性,其中求交运算的实质是寻找共同节点即子节点,求并运算则是产生父节点。由此可以求出形式背景K=(O,A,R)所对应概念格的上确界、下确界:
(3)
(4)

1.1 多值背景转换
多值背景是指形式背景中对象集与属性集之间的关系不能仅通过0或1表示,在属性集中含有更多的数值型量化属性。传统的概念格用于对数据表进行挖掘时,所要求的是对象集与属性集之间存在二元关系,即单值背景。而坦克驾驶模拟训练产生的数据表属于多值背景,例如,在运用坦克驾驶模拟器进行联网战术训练时,数据库所保存的坦克机动速度、坦克毁伤程度等数据均为多值背景范畴。因此,为了运用概念格挖掘其蕴含的关联规则,需要先将原始多值背景转化为单值背景。由于形式背景与矩阵之间可直接转换,本节采用矩阵布尔化的方法以求取单值背景,具体步骤如下:
输入:原始多值背景K=(O,A,R)。
输出:单值背景矩阵P.
步骤1根据等价关系对K进行划分,使形式背景结构简化,避免后续对相同的对象重复搜索概念格节点。在此基础上,将K中对象与属性分别转化为二维矩阵的行与列,并把二者的映射关系转化为矩阵的元素值,从而得到K的矩阵形式MK.
步骤2利用文献[17]中的离散化算法对MK中的数据进行离散化处理,得到各属性的划分区间及编码表示。
步骤3根据离散化后的各属性编码情况进行布尔化处理。若编码结果为1,则该属性是冗余的,可不用考虑;若编码结果为2,则直接转化为布尔型0、1;若编码结果大于2,则将该属性进行扩展,新增加的属性在原属性命名基础上增加一个二维下标进行标识,属性扩展长度为该属性离散化的编码个数,相应的属性值根据扩展前的数据取布尔值0、1.
步骤4判断K中的属性是否处理完毕,若已处理完则转步骤5,否则转步骤3继续进行布尔化处理。
步骤5输出最终转化后的单值背景矩阵P.
下面通过一个例子简要说明上述转换方法。表1为利用坦克驾驶模拟器进行对抗训练时所采集的部分数据,并以多值形式背景表示。
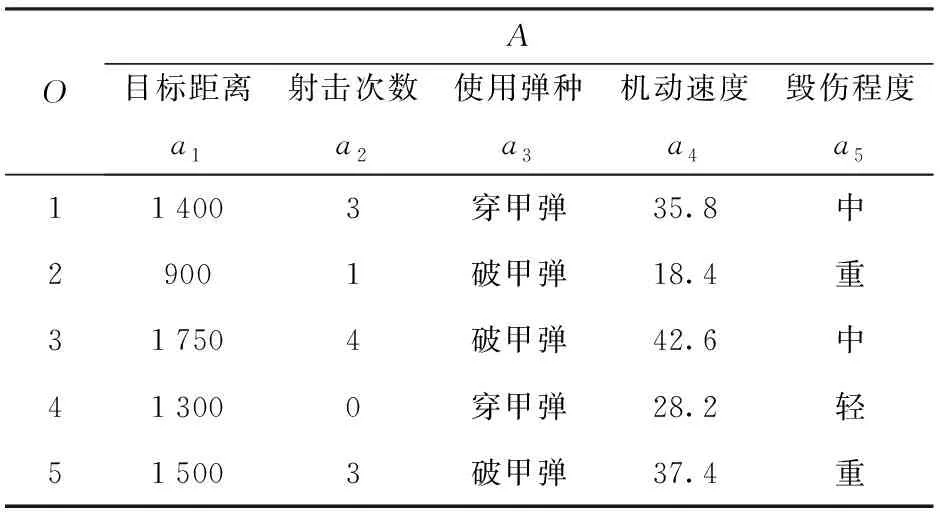
表1 多值形式背景
通过对数据离散化得到编码如表2所示。
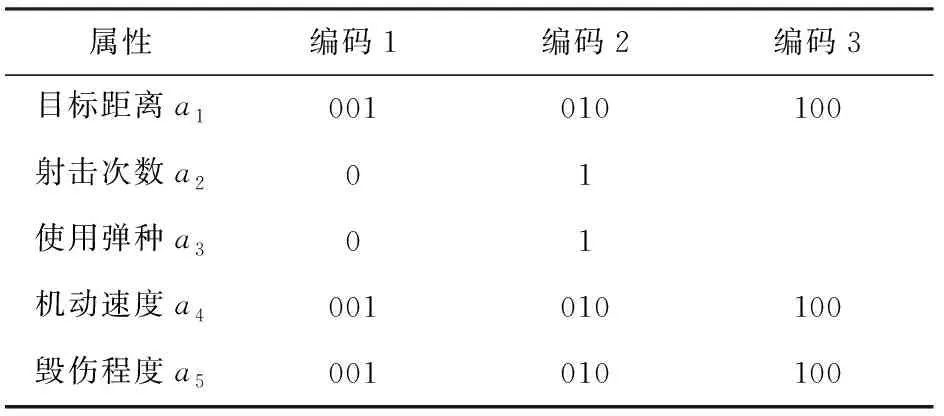
表2 离散化编码表
对表1中的数据进行离散化编码、矩阵转化,得到M′K:

对M′K中编码数大于2的属性进行布尔化处理,得到单值背景矩阵P:

1.2 双向概念格构建
在将多值背景转化为单值背景并以矩阵表示之后,基于同一形式背景所产生的概念格是唯一的,其结构具有不变性特点,本文采用矩阵秩的方法来定义内涵秩和外延秩,然后通过计算这两个秩的值从概念格顶层上确界和底层下确界同时搜索概念节点,并结合支持度阈值对概念格进行约简,最终实现概念格的双向构建,以此提高建格效率。
1.2.1 基于内涵秩构建概念格
定义4设L(K)=(B(K),≤)为形式背景K=(O,A,R)所对应的概念格,C=(X,Y)是L(K)中的一个概念,则对C可分为以下两类[18]:
1)∃a∈Y使得(a′,a)∈R,其中a′为具有属性a的对象集合,并且满足|a′|=|X|,则称C为第1类概念;
2)∃C≤Cp1、C≤Cp2,其中Cp1、Cp2为C的父概念,使得Cp1∩Cp2=C,则称C为第2类概念。
根据对偶原理和概念格的唯一性,由定义4可知,∃Cs1≤C、Cs2≤C,其中Cs1、Cs2为C的子概念,使得Cs1∪Cs2=C,从而为双向构建概念格提供可行条件。另外在求概念节点时,关键是构造第2类概念,传统做法是通过对所有上层概念进行求交运算[19-20],从而找到所需的概念节点,但运算量较大且存在计算冗余。为此引入外延秩、内涵秩协同搜寻概念节点,并对上述求交运算进行简化。
定义5对K=(O,A,R)转化为矩阵P后,∀o∈O、∀a∈A. 如果在P中o所对应的行含有m个1,则称外延秩为m,记作rE(o)=m;如果在P中a所对应的列含有n个1,则称内涵秩为n,记作rI(a)=n.
性质1设L(K)=(B(K),≤)为形式背景K=(O,A,R)所对应的概念格,C1、C2、C3∈B(K)且均为第1类概念,C为第2类概念,C≤C3、C3≤C1、C3≤C2,C1∩C2为第2类概念并与C3具有相同的内涵秩,则在构造C时,只需计算上层的第1类概念与其他第1类概念的交集。
证明根据定义3、定义5,不失一般性,令rI(Int(C1))=rI(Int(C2))=d,rI(Int(C3))=rI(Int(C1∩C2))=d-1,C的上层第1类概念为C3,与其他第1类概念求交,有
rI(Int(C1∩C3))=rI(Int(C2∩C3))=d-2.
(5)
因为rI(Int(C3))=d-1,C3与C1、C2的交集各有d-2个内涵秩,由此可以得d-3≤rI(Int(C1∩C2∩C3))≤d-2. 先假设
rI(Int(C1∩C2∩C3))=d-3.
(6)
由(5)式、(6)式可得
rI(Int(C1∩C3))-rI(Int(C1∩C2∩C3))=
rI(Int(C2∩C3))-rI(Int(C1∩C2∩C3))=1.
结合rI(Int(C1))=rI(Int(C2))=d可推出rI(Int(C1∩C2))≤d-2,显然这与rI(Int(C1∩C2))=d-1相矛盾,说明rI(Int(C1∩C2∩C3))=d-3的假设不成立,则有rI(Int(C1∩C2∩C3))=rI(Int((C1∩C2)∩C3))=d-2与(5)式的内涵秩一致,表明第1类概念与第2类概念之间交集形成的概念可以由第1类概念求交得出,即在构造C时,只需计算上层的第1类概念与其他第1类概念的交集。
由定义5可知:对于内涵秩,从概念格的顶端至底端是逐步减小的,内涵数量增加,概念逐步细化;对于外延秩,从概念格的底端至顶端是逐步减小的,外延数量增加,概念逐步泛化。因此通过迭代计算内涵秩和外延秩,并利用概念的交、并操作对概念节点分层提取,从而实现概念格的双向构建。
步骤1根据(3)式计算概念格的上确界(Xsup,Ysup)=(((∪Xi)*)′,∩Yi),其中Xi⊆O、Yi⊆A,Xsup、Ysup分别为上确界的概念外延和概念内涵,将上确界作为概念格的顶层节点。
步骤2计算j=max {rI(a)|a∈A-∩Yi,Yi⊆A},扫描形式背景矩阵找到内涵秩为j所对应的a,则顶层节点的子节点为(Xj,Yj)=((a∪Ysup)′,a∪Ysup)且全部属于第1类概念。
步骤3令=j-1,由定义4可知,rI(a)=的概念节点包含两部分。其中一部分由内涵秩为j的第1类概念与上层所有的第1类概念按(1)式进行求交操作,选择相应内涵秩为的概念,对于其他秩小于的概念可作为下层的备选节点。另一部分通过扫描形式背景矩阵找到内涵秩为所对应的a,则可求得概念节点为(Xj-1,Yj-1)=((a∪Yj)′,a∪Yj). 为减少后续关联规则提取过程中的候选项集数量,引入支持度约束作为判断条件,即如果节点的外延个数小于最小支持度supmin,则其内涵所对应的项集一定是不频繁的,因此可以去除该节点,不再参与求交运算,否则保留该节点。
步骤4若j>0,则转步骤3继续搜索相应的内涵秩及其所包含的节点。否则输出最终的概念。
1.2.2 基于外延秩构建概念格
步骤1根据(4)式计算概念格的下确界(Xinf,Yinf)=(∩Xi,((∪Yi)′)*),其中Xi⊆O、Yi⊆A,Xinf、Yinf分别为下确界的概念外延和概念内涵,并将下确界作为概念格的底层节点。
步骤2计算l=max {rE(o)|o∈O-∩Xi,Xi⊆O},扫描形式背景矩阵找到外延秩为l所对应的o,则底层节点的父节点为(Xl,Yl)=(o∪Xinf,(o∪Xinf)*)且全部属于第1类概念。
步骤3令=l-1,由定义4可知,rE(o)=的概念节点包含两部分。其中一部分由外延秩为l的第1类概念与下层所有的第1类概念按(2)式进行求并操作,选择外延秩为的概念,对于其他秩小于的概念可作为上层的备选节点。另一部分通过扫描形式背景矩阵找到外延秩为所对应的o,则相应的概念节点为(Xl-1,Yl-1)=(o∪Xl,(o∪Xl)*)。
步骤4若l>0,则转步骤3继续搜索相应的外延秩及其所包含的节点,否则输出最终的概念。
1.3 后件约束关联规则提取
在实际的关联规则提取过程中,通常挖掘的目标是明确的,例如要分析坦克驾驶模拟训练成绩的影响关联因素,因此可以提前确定产生规则的后件,启发搜索内涵间的相互关系,从而减少冗余计算、提高算法运行效率。本节以生成的概念节点为基础,通过分析外延数与支持度阈值的关系得到频繁概念节点,然后以规则后件固定作为约束条件过滤不相关的节点,最后提取满足置信度阈值的关联规则。
对于概念节点C=(X,Y),当外延数大于最小支持度时,称此节点为频繁概念节点。由于外延是具有共同属性的全部对象集合,内涵Y所对应的项集为频繁闭项集。根据Apriori反单调性[11]类比可知,任何频繁概念节点的父节点都是频繁的,任何非频繁概念节点的子节点都是不频繁的。因此,通过计算频繁闭项集可以避免产生所有候选项集,极大地提高规则产生效率。
设C=(X,Y)为L(K)=(B(K),≤)中的一个概念节点,约束条件为Res且Res(C)=True成立,则C为符合条件的约束概念节点。本文中采用的约束条件为确定的规则后件项集D⊆A,可通过析取范式记为D=a1∧a2∧…∧an,ai∈A.
在1.2节得到所有概念节点后,按以下步骤提取关联规则,若对规则结果不满意,则可以调整支持度阈值,快速生成频繁概念节点,避免传统关联规则提取过程中因支持度变化需要重新扫描数据库生成频繁项集的问题:
步骤1遍历概念格的所有节点,依据支持度阈值产生频繁概念节点,并将具有相同内涵数的概念节点作为一组。
步骤2采用D=a1∧a2∧…∧an作为约束条件,从分组的频繁概念节点中生成符合条件的概念节点集S.
步骤3取出S中的一个概念节点C=(X,Y),并令=S-C,产生形如Y-D⟹D的规则。
步骤4计算规则Y-D⟹D置信度,当项集Y-D不属于任何一个节点的内涵时,由外延与内涵的封闭性可知,Y-D与Y具有相同的对象数,所产生的规则置信度为1,将Y-D⟹D加入规则集。反之,当Y-D属于某一个节点的内涵时,所产生的规则置信度为|X|/|(Y-D)′|,若满足置信度阈值条件,则将该规则加入规则集,否则将其删除。
步骤5判断概念节点集,若为空集,则关联规则提取结束,输出最终产生的规则集,否则转步骤3.
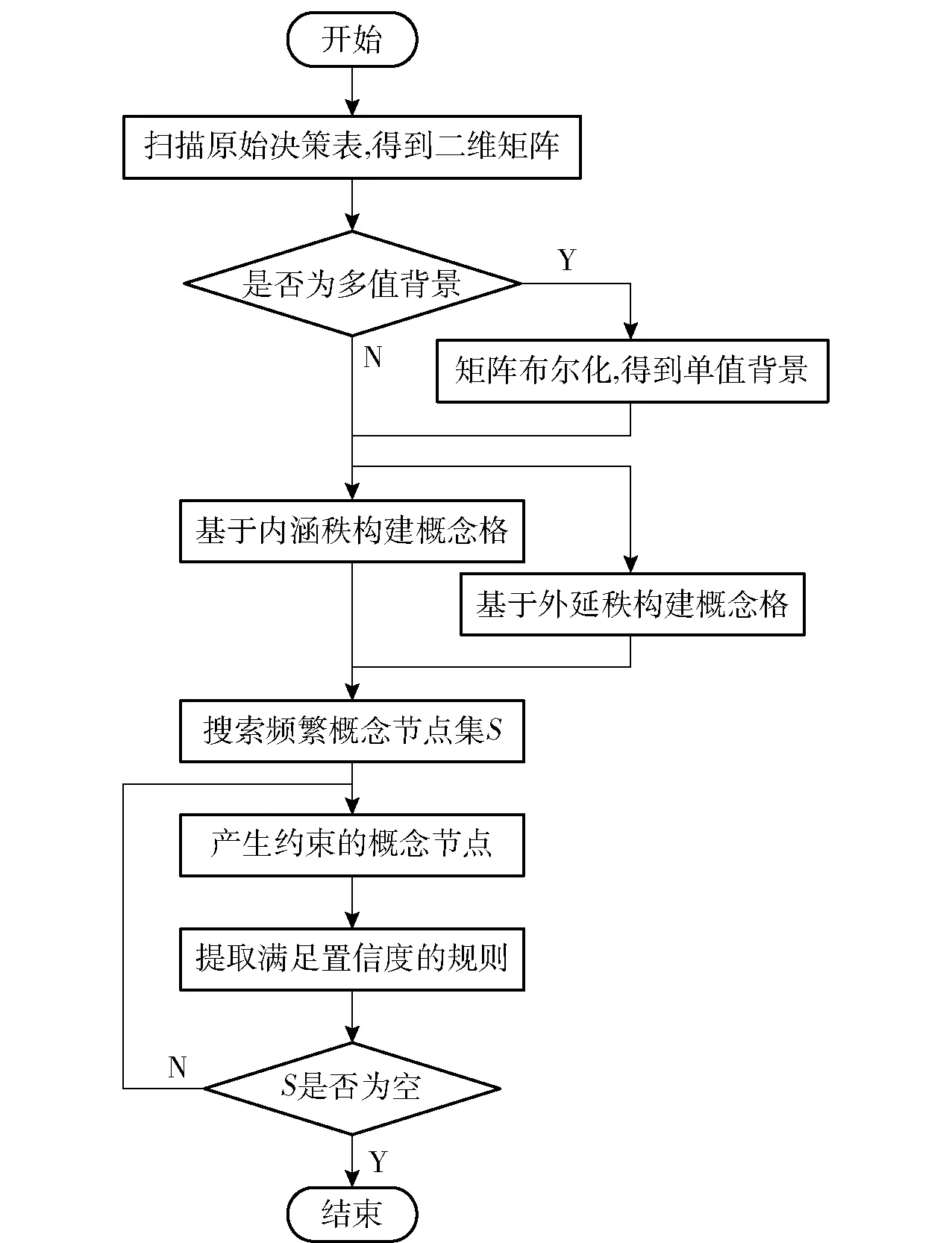
图1 基于BCLAR挖掘方法流程Fig.1 Mining process of association rules based on bidirectional concept lattice
通过以上对关联规则挖掘的3个阶段具体描述,给出基于BCLAR挖掘方法流程如图1所示。
1.4 对比分析
为检验算法的可行性与有效性,选择Apriori算法和Bordat算法进行对比分析,实验所需数据来自两类:一类是真实数据集,通常具有较大的数据密度,包括Connect、Mushroom数据集;另一类是合成数据集,通过IBM的实验数据生成器获得,并记作Tμ.Iλ.D∂,其中μ代表含有的项集总数,λ代表数据库中频繁项集的平均长度,∂代表数据库所包含的数据对象总数。实验中共生成两个数据集,分别为T10.I5.D500(T10)、T15.I8.D800(T15)。表3对4个数据集的基本信息进行了简要描述。

表3 实验数据集描述
由于在实际的关联规则挖掘过程中,对挖掘算法的复杂度和被要求资源的承载度有较高要求,选择运行时间以衡量关联规则算法复杂度,生成的频繁项集数量作为占用内存的评价指标,同时为消除误差,每次实验重复进行5次,选择各指标的平均值作为最终评价标准。
1.4.1 算法运行时间分析
设定支持度阈值为10%,置信度阈值为60%,以上3种算法在4个测试数据集上的运行时间如图2所示。由图2可以看出,对于小规模数据集T10、T15,BCLAR算法与Apriori算法、Bordat算法的运行时间相差不大,说明在数据密度较小情况下减少了整个搜索空间,相应产生的候选项集规模也随之减小,3种算法都能快速提取相应的规则集。随着数据规模变大,Apriori算法的运行时间急剧增长,该算法需要重复扫描数据库且迭代验证候选项集,导致在大规模数据集上消耗时间显著增加,而BCLAR算法、Bordat算法直接根据概念格节点生成频繁项集,避免了候选和验证的重复操作,所需时间比Apriori算法少,且BCLAR算法在构建概念格时从顶部和底端同时搜寻概念节点,在时间上具有一定优势。
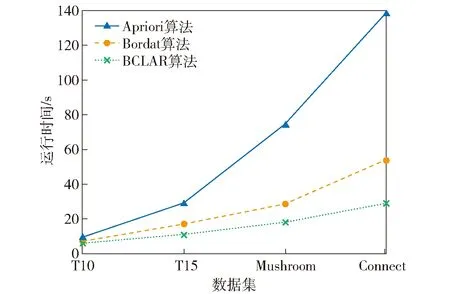
图2 3种算法在不同规模数据集的运行时间Fig.2 Run times of three algorithms in different scale datasets
1.4.2 频繁项集数量分析
以Mushroom数据集为例,通过设定不同的支持度阈值(分别为1%、5%、10%、15%、20%、25%),比较3种算法所产生的频繁项集数量,如图3所示。从图3的结果可以看出:随着支持度阈值的增加,频繁项集数量都呈逐渐减少的趋势;Apriori算法在支持度阈值较低时,频繁项集的个数明显大于BCLAR算法和Bordat算法,主要是由于Apriori算法搜索大量候选项集,再进行连接操作会产生数据集中不存在的无效项集,导致频繁项集数量较多;后两种算法根据支持度阈值从概念格节点上搜索到的是频繁闭项集,可以有效减少频繁项集数;BCLAR算法在从顶层向下构建概念节点时,结合支持度阈值提前删除了不频繁的概念节点,相当于进行了剪枝处理,从而使频繁项集的搜索空间大大压缩,产生的频繁项集数比Bordat算法少。
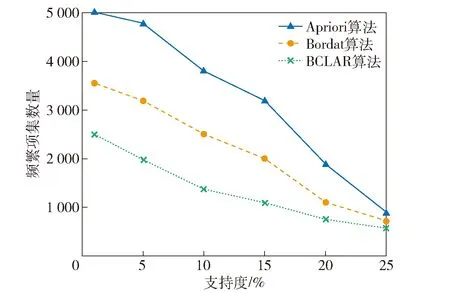
图3 3种算法在不同支持度下的频繁项集数量Fig.3 Number of frequent itemsets of three algorithms with different support degrees
从1.4.1节、1.4.2节对比分析可以看出,BCLAR算法在运行时间和生成的频繁项集数量方面比Apriori算法、Bordat算法具有一定优势,能适用不同规模和密度的数据集,为了说明这种优势的存在,下面从理论上进一步分析。在时间复杂性方面,Apriori算法在每次产生频繁项集时,都需要扫描一次数据库以进行候选和验证操作,时间复杂度为O(|∂|η+1),|∂|为数据对象总数,η为最大频繁项对应的项集总数。Bordat算法通过扫描一次数据库,自顶向下构建概念格,时间复杂度为O(22η|∂|);BCLAR算法在产生形式背景后不再扫描数据库,通过双向构建概念格,时间复杂度为O(22η-1|∂|),比其他两种算法的时间复杂度要小,同时当支持度阈值发生变化时,不用重新扫描数据库,直接在原始概念格上搜索频繁概念节点,提高了算法运行效率。因此,BCLAR算法具有更好的时间特性。在空间复杂性方面,Apriori算法由于迭代执行连接和剪枝操作,产生大量候选项集,最坏情况可能呈指数增加,占用较多内存空间。BCLAR算法采用概念格的形式存储数据,直接计算概念节点的外延数得到支持度,从而产生无冗余的闭频繁项集,极大地减少了内存空间的占用。
2 坦克驾驶模拟训练关联规则挖掘
通过BCLAR算法对坦克驾驶模拟训练产生的数据进行分析,进而探索一些适用的关联规则,用于发现训练问题,以更好指导坦克驾驶模拟训练的组织实施。
2.1 数据来源
某型坦克驾驶模拟器是与实装物理外观一致、操作规程一致、使用方法一致的模拟训练装备,同时还研发了专用的数据采集工具,用于采集驾驶模拟器的整个训练过程数据,支持设置数据采集的时间段,支持TB级数据量的存储,能满足分布式、集中式存储的不同需求。
从系统数据库中选取坦克驾驶模拟训练涉及的训练对象数据、训练过程数据、训练结果数据,建立数据决策表如表4所示,其中论域U={u1,u2,…,un},数据属性集A={军衔,年龄,服役年限,文化程度,体能,训练等级,训练科目,理论测试,训练次数,成绩评定}={X1,X2,X3,X4,X5,X6,X7,X8,X9,Y1}。根据坦克驾驶教范相关规定,并结合训练人员实际情况,对属性集A的取值说明如下:
1)军衔。取值范围:列兵、上等兵、下士、中士、上士。
2)年龄。取值范围:18≤X2≤32,X2∈Z,Z为整数集。
3)服役年限。取值范围:1≤X3≤12,X3∈Z.
4)文化程度。取值范围:初中、高中、大专、本科。
5)体能。取值范围:优秀、良好、及格、不及格。
6)训练等级。取值范围:无等级、初级、3级、2级、1级。
7)训练科目。取值范围:基础驾驶动作、坡上驾驶、低速挡驾驶、分个通过限制路和障碍物、换挡驾驶、各种速度驾驶、连续通过限制路和障碍物、道路驾驶。
8)理论测试。取值范围:1≤X8≤100.
9)训练次数。取值范围:1≤X9≤8,X9∈Z.
10)成绩评定。取值范围:1≤X10≤100.
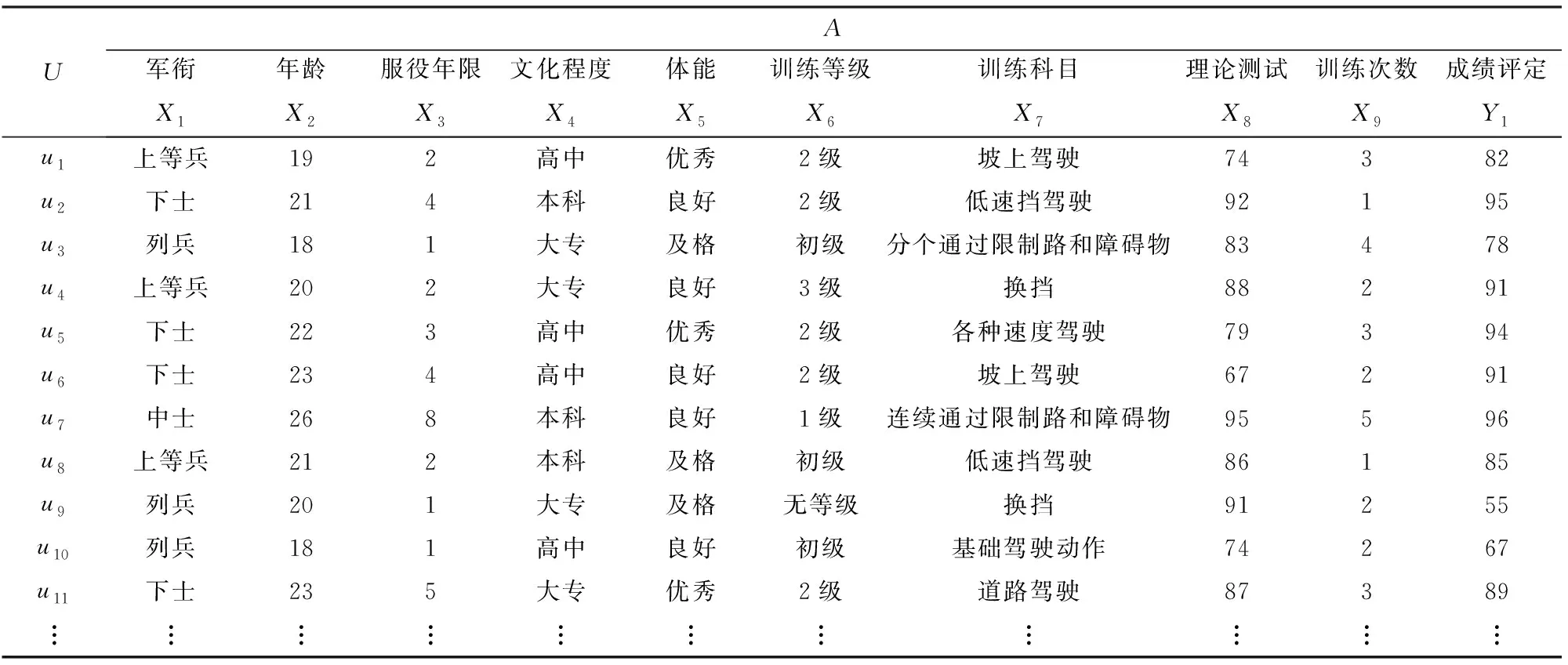
表4 坦克驾驶模拟训练数据决策表
2.2 数据预处理
由表4显示的内容可知其为混合型决策表,既包含连续型属性又含有离散型属性。为了更好地提取泛化知识,采用文献[17]中的离散化算法对混合型决策表中的数据进行处理,产生各属性的离散化编码如表5所示。从表5中可以看出,年龄属性被离散化成一个区间,表明其对坦克驾驶模拟训练成绩影响最小,在后续进行关联规则挖掘时可以不予考虑。
根据离散化编码依据对原决策表的数据进行处理可得表6,其显示的内容为多值形式背景。为了运用概念格进行关联规则的挖掘,需要首先采用BCLAR算法中的多值关系转换模块,将原始多值形式背景离散化后采用矩阵形式表达为M′K,然后利用布尔化操作将M′K转换为单值背景矩阵P:
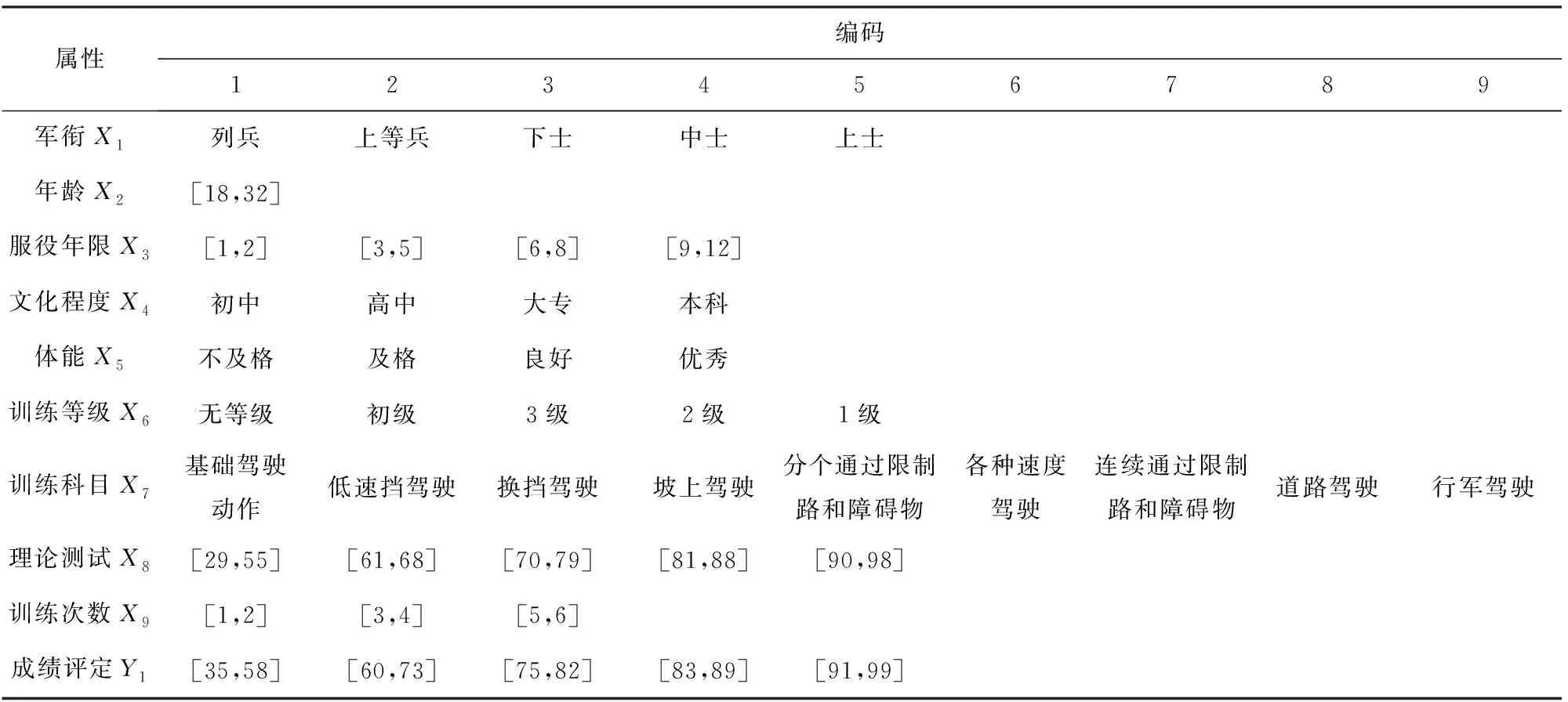
表5 决策表的属性离散化编码

表6 离散化处理后的决策表

2.3 关联规则提取
得到单值背景矩阵P后,计算内涵秩和外延秩,从而逐层产生概念节点,实验中设定支持度阈值为10%,置信度阈值为65%,根据实验结果也可以动态调整参数设置。由于对坦克驾驶模拟训练数据实施关联规则分析重点是研究对坦克驾驶技能成绩的影响因素及内在规律,选择训练成绩评定作为规则后件固定的约束条件,从而删除一些与之不相关的频繁概念节点,最终生成的约简关联规则如表7所示。
以表5为依据,对最终得到的关联规则分析如下:
1)规则1:X11∧X43∧X44∧X71∧X91⟹Y14,即具有大专以上文化程度的列兵经过1~2次训练,在“基础驾驶动作”训练科目中成绩评定为[83,89]。表明高学历入伍的士兵接受能力、动手操作能力较强,在受过较短时间训练后,能在基础训练科目上取得较好成绩,体现了高学历教育在增强士兵军事本领上的重要作用。因此针对这类具有较高学历士兵,可以有针对性地集中组训,适当加快训练进度,从而有效提高他们的驾驶专业技能水平。

表7 坦克驾驶模拟训练中的关联规则
2)规则2:X14∧X15∧X64∧X65∧X77⟹Y15,即具有2级以上训练等级的中士、上士,在“连续通过限制路和障碍物”训练科目中成绩评定为[91, 99]。表明作为坦克驾驶队伍主体的2级、1级驾驶员具有较高的操作技能水平,在难度较大的科目“连续通过限制路和障碍物”中获得了优异成绩。因此在平时训练中可以充分发挥这些专业人才的帮教作用,让他们充当小教员,缩短复杂训练科目时间,提高训练效率。
3)规则3:X72∧X91⟹Y14∧Y15,即在“低速挡驾驶”训练科目中,经过1~2次训练可取得良好以上的训练成绩,表明“低速挡驾驶”训练科目相对容易,受训人员在经过较少的训练后即可以掌握此项技能。因此针对该科目可以适当减少训练时间,提高坦克驾驶模拟器的利用率。
4)规则4:X11∧X12∧X13∧X79∧X94⟹Y11∧Y12,即列兵、上等兵、下士在“行军驾驶”训练科目中经过7~8次训练,成绩总体仍然比较差,评定分数位于[35, 58]、[60, 73]两个区间,表明“行军驾驶”科目的训练效果不够理想,具有一定的普遍性,应该考虑系统因素。通过分析某型坦克驾驶模拟器发现,对“行军驾驶”科目功能的设计还不够详细,仿真模型与真实训练场景还有一定误差,需要进一步研究改进,从而满足坦克驾驶模拟训练的全覆盖要求。
5)规则5:X11∧X42∧X75∧X81∧X82⟹Y12,即具有高中文化程度的列兵对驾驶理论掌握较差,在“分个通过限制路和障碍物”训练科目中,成绩评定为[60, 73],表明此类受训对象对驾驶理论不够熟悉,而“分个通过限制路和障碍物”训练科目的动作要领比较复杂,通过方法也不尽相同,涉及操作的扣分点多达17项。因此在操作驾驶模拟器前,需要对相关的理论进行认真学习,熟练掌握通过各种限制路和障碍物的方法步骤,为实际操作训练打下基础。
3 结论
本文提出一种基于BCLAR挖掘方法,并将其用于坦克驾驶模拟训练结果分析。得出主要结论如下:
1)通过矩阵布尔化操作对坦克驾驶模拟训练数据进行多值转化处理,可有效拓展概念格的适用范围。
2)BCLAR算法利用内涵秩和外延秩同时构建概念格,设计支持度阈值约简概念节点,运行时间和生成频繁项集数量优于Apriori算法和Bordat算法。
3)在解决某型坦克驾驶模拟器训练结果分析时,BCLAR算法可以提取用户所注的关联规则,对坦克驾驶模拟训练具有一定的指导作用。
猜你喜欢
学与玩(2022年8期)2022-10-31
计算机应用与软件(2022年7期)2022-08-10
哈尔滨理工大学学报(2021年4期)2021-10-07
小学生学习指导(小军迷联盟)(2020年12期)2021-01-05
计算机与数字工程(2020年7期)2020-10-09
中学科技(2018年2期)2018-03-15
科技知识动漫(2017年5期)2017-05-11
中学科技(2016年12期)2017-01-07
中学科技(2016年11期)2017-01-07
小哥白尼·军事科学画报(2009年4期)2009-05-11
