
基于支持向量机的农业供应链金融信用风险评价
2020-02-05 08:00曾梓铭
吉林金融研究 2020年12期
曾梓铭
(桂林电子科技大学 商学院,广西桂林 541004)
一、引言
农业供给侧结构性改革使现代农业体系不断完善发展,农业产业化速度和规模空前提升,农业中小企业的融资需求不断增加,从而催生出庞大的农业融资市场。然而,由于农业中小企业自身普遍存在信用弱、抵押物少、资金周转困难等问题,加上农产品具有价格波动大、生产周期长、易腐烂变质等特点,使其很难向商业银行获取融资。供应链金融的出现,为解决农业中小企业融资难问题提供了新途径。供应链金融以整条供应链为考察对象,改变了传统的风险管理模式,将针对单个企业的风险管理转为对整条供应链的风险管理。
然而,由于信息不对称,商业银行对于农业中小企业的营运情况、盈利状况等信息掌握不完全,融资过程存在较大不确定性,容易引发信用风险。同时,加上信用风险在供应链上具有传导性,单个企业的信用风险容易传染到供应链上其他企业,使风险危害成倍扩大,对供应链稳定运作产生冲击。我国农业供应链金融处于发展初期,商业银行对利用供应链金融进行融资的农业中小企业的资信水平评估尚不成熟,农业中小企业仍存在较高的信用风险。因此,如何有效提高供应链金融信用风险评估水平,降低贷款风险的发生,是农业供应链金融健康发展的关键。
二、文献综述
在供应链金融风险评估方法上,胡海青等(2011)[1]结合核心企业信用状况和供应链关系,发现基于SVM的信用风险评价模型在供应链金融风险评估中更具有优越性。吴屏等(2015)[2]通过归纳线上供应链金融风险因素的特征,建立基于BP神经网络的信用风险评估体系并验证了其有效性。逯宇铎等(2016)[3]以汽车上市中小企业为研究样本,运用Lasso-logistic模型进行变量筛选和参数估计,得出了较高的评估准确率。戴昕琦(2018)[4]结合线上供应链金融融资模式特点,利用随机森林模型与SMOTE 算法构建信用风险评估模型,证明了基于C-SMOTE算法的随机森林模型能显著降低商业银行线上供应链金融风险。李健等(2019)[5]以汽车供应链作为样本,运用随机森林模型和盲数理论筛选变量,并通过对比多种评估模型的预测效果,发现PSO-SVM模型具有较高的预测准确率。
在农产品供应链金融的研究上,方焕等(2017)[6]在理论分析的基础上,构建Logistic模型来预测农业类企业的违约情况,为供应链金融信用风险评估提供了新的理论思路。杨军等(2017)[7]对农业中小企业的三种融资模式进行分析,并构建Logistic模型对农业供应链金融信用风险进行评估。邹建国等(2019)[8]运用主体加债项的评估方法,结合主成分分析和Logistic回归度量供应链金融模式下的农户信用增进。
综上所述,众多学者对供应链金融信用风险的评估方法进行了多方面研究,但在农业供应链金融信用风险评估上,大多学者仍然采用Logistic模型。随着计算机技术的发展,机器学习算法开始广泛应用于信用风险评估,并取得良好效果。鉴于此,以农业中小企业为研究样本,将SVM模型用于构建农业供应链金融信用风险评估体系,以提升评估准确率。
三、指标体系与算法模型
(一)指标体系
通过对以往文献采用的评估指标进行归纳和总结,结合医药供应链金融信用风险的特征,筛选出如下指标:净资产收益率(X1)、资产报酬率(X2)、资产净利率(X3)、销售净利率(X4)、成本费用利润率(X5)、资产负债率(X6)、流动比率(X7)、速动比率(X8)、产权比率(X9)、现金流动负债比(X10)、营业收入增长率(X11)、营业利润增长率(X12)、净利润增长率(X13)、总资产增长率(X14)、存货周转率(X15)、应收账款周转率(X16)、流动资产周转率(X17)和总资产周转率(X18)。
由于选取了18个初始变量,变量维数较高,无论是使用经典计量算法或机器学习算法,都存在模型指标的高相关性和高维性,导致模型拟合过度、参数估计无效等后果。因此先对变量进行因子分析,提取出具有主要解析能力的变量,再利用得到的变量进行实证分析。
(二)算法说明
1.Logistic模型。Logistic模型受自变量的多维相关性影响很大,需要先采用因子分析法,减少变量之间的相关性,选出有代表性的自变量。Logistic回归模型的前提是企业的守约概率服从Logistic分布,把供应链金融信用风险评估体系中一系列指标(Xk,k=n)作为自变量,通过建立Logistic回归模型预测企业是否有违约风险。Logistic模型的Y作为因变量,只有0和1两个取值,0为违约,1为守约。
2.SVM模型。支持向量机(SVM)是机器学习方法中常用的分类模型,近几年广泛应用于信用风险研究。支持向量机的原理是寻找一个最优分类超平面分割训练样本,确保最小的分类错误率。分类超平面表示为:

其中w是可调整的权值向量,b是偏置。归一化后,使线性可分的样本集合(xi,yi),xi∈Rn,n是样本数量,yi∈{+1,-1}(i=1,2,…,n),满足:

支持向量机的核心思想是尽可能使两个分开的类别具有最大间隔,这样才能使分隔有更高的可信度,使新样本有更好的泛化能力。由两个平面距离推导可得分类间隔为2/‖w‖,即‖w‖最小化等价于分类超平面最大化。为了方便后续求导和计算,进一步等价于‖w‖2/2最小化。使式(2)等号成立的样本点叫做支持向量,满足条件(2)的最小超平面被称为最优分类超平面。
四、信用风险实证分析
(一)数据来源与因子分析
通过选取58家上市农业中小企业为研究对象,利用RESSET数据库获取企业2017-2018年度相关数据。在116个样本中,违约样本为78个,无违约样本为38个。
在做因子分析之前,需要检验各变量之间的关联度,判断变量是否适合做因子分析。利用变量做KMO和Bartlett检验,得到KMO值为0.731(KMO>0.6),说明适合做因子分析。利用最大方差旋转分析法,得到前5个因子的累计方差贡献率为81.4%,表明这5个因子能够较好地反应所有变量信息。因此,选取前5个因子作为初始变量,进行实证分析。
(二)信用风险评估
1.基于 Logistic 模型的信用风险评估。运用Logistic模型,将上述因子分析得到的5个主因子作为自变量,企业信用水平作为因变量进行回归分析,得到回归结果如表1。
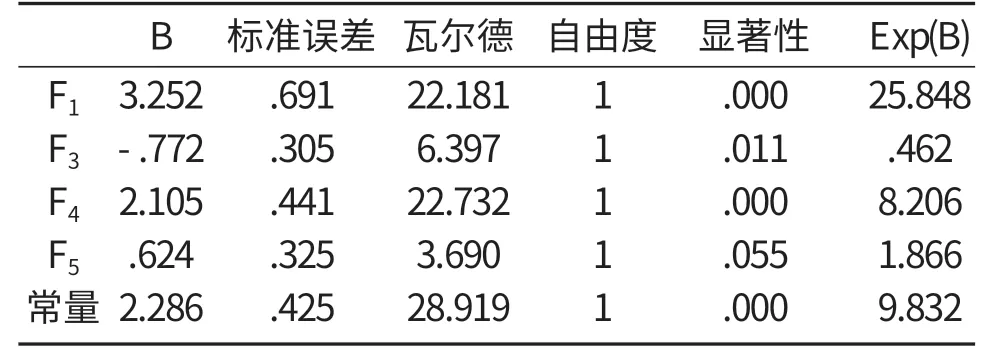
表1 方程中的变量
根据表1结果可知,最终筛选出F1、F3、F4和F5这四个变量,可以得出Logistic回归模型的概率方程为:

从表2可知,模型对违约企业判别的准确率为76.3%;对无违约企业判别的准确率为94.9%,模型的总体评估准确率为88.8%。经进一步计算,Logistic模型的第一类错误率为23.7%,第二类错误率为5.1%。

表2 Logistic模型评估结果
2.基于SVM的信用风险评估。同样将提取的5个主因子作为解析变量,运用Python3的Anaconda科学计算平台构建SVM模型,对116个样本进行信用风险评估。为了确保模型的有效性,对选取81个样本(接近总样本数的70%)作为训练集,用于构造SVM模型;选取35个样本作为测试集,以检验模型的泛化能力。
SVM分类模型引入核函数能够实行高维空间的内积运算,从而解决非线性分类。通过选择合适的核函数和调节相关参数,可以提高SVM分类模型的预测准确率。本文选择径向基核函数(RBF)来实现SVM模型在高维空间的内积运算,并综合考虑最大分类间隔和最少错分样本,在高维空间构造软间隔,采用交叉验证方法确定参数C=80,gamma=0.1。
以训练集112家企业的数据为基础,将5个主因子作为输入向量进行训练,使用径向基核函数(RBF)建立SVM预测模型。运用得到的RBFSVM模型对测试集样本进行测试,预测效果如表8。

表3 SVM模型评估结果
由表3可知,模型对训练集样本的评估准确率为93.8%,对测试集样本的评估准确率为94.3%,模型的总体评估准确率为94.0%。经进一步计算,可得SVM模型总体第一类错误率为10.5%,第二类错误率为3.8%。
3.两种模型评估结果对比。由表4可知,SVM模型的总体预测准确率为94.0%,比Logistic模型高了5.2%,说明SVM模型具有更高的评估准确率。第一类错误率表示对违约样本的识别能力,因此第一类错误率通常比第二类错误率更重要。SVM模型的第一类分类错误率为10.5%,比Logistic模型低了13.3%,表示SVM能更加有效地识别违约企业,满足商业银行对中小企业信用风险评估的要求。
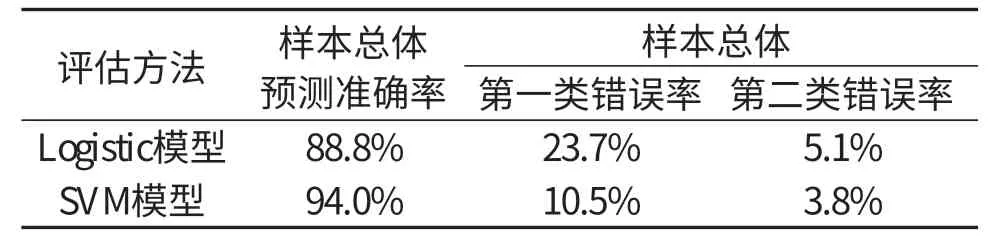
表4 评估结果对比
五、结论
本文以上市农业中小企业为研究样本,构建供应链金融信用风险评估体系,并分别运用Logistic模型和SVM模型进行信用风险评估。结果表明,SVM模型的总体评估准确率比Logistic模型高了5.2%,第一类分类错误率低了13.3%,证明了在农业供应链金融下SVM模型的优越性和有效性,为农业供应链金融信用风险评估提供了新方法。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
新课程·上旬(2019年1期)2019-03-18
中国交通信息化(2018年5期)2018-08-21
教师·中(2017年3期)2017-04-20
试题与研究·教学论坛(2016年27期)2016-08-11
当代经济(2016年26期)2016-06-15
新疆财经大学学报(2015年3期)2015-12-10
系统工程学报(2015年2期)2015-02-28
