
基于局部扰乱的社会网络隐私保护
2020-02-02 06:46胡晓依乔丽娟王宇
电子技术与软件工程 2020年15期
胡晓依 乔丽娟 王宇
(曲阜师范大学软件学院 山东省曲阜市 273100)
在线社交媒体服所务产生的与日俱增的海量数据,为发现敏感信息提供了机会。为了满足人们对数据的需求,数据发布者一直在发布数据,以提供给数据挖掘者进行分析。但是,这产生了隐私的泄露问题,因为在许多社交网络数据中,顶点属性和顶点之间的关系可能很敏感。因此,任何公开发布的信息都可能会涉及有关个人的隐私问题。
在某些情况下,网络中个体或身份信息不敏感,而个体之间的关系是保密的,比如金融交易网络,电子邮件网络和社交网络,其中链接的存在即金钱交易,私人电子邮件或两个人之间的友谊被认为是敏感的。这些数据发布之后,社会网络中的数据被攻击者大量收集,他们通过分析这些数据获得有价值的信息,这将造成严重的隐私泄露。因此研究解决隐私泄露的匿名方法成为一大研究热点[4][5]。
保护边隐私的一种匿名化处理方法是随机化方法,即将社交网络建模为无向图,并随机删除现有边(u,v),并添加相同数量的边,从所有不存在的边中随机选择不存在的边(w,z),将其添加到社会网络图中。随机化方法的主要缺点是,对社会网络的结构具有较大的破坏性,因为对于不存在的链接(w,z)是从整个空间中随机选择的。例如,在两个远程节点之间添加边,或删除连接两个子图的唯一边,将极大地影响最短路径和可达性分析。

表1:数据集信息统计
本文考虑了频繁子图中敏感边隐私的保护问题。具体来说,我们要确保攻击者在社交网络分析中无法准确地推断出敏感边的存在,以确保边的隐私需求。本文提出的基于敏感边的隐私保护方法(Privacy protection of sensitive side),简称SEPP,能够在保证社会网络隐私保护需求的前提下,极大地保留数据的可用性。
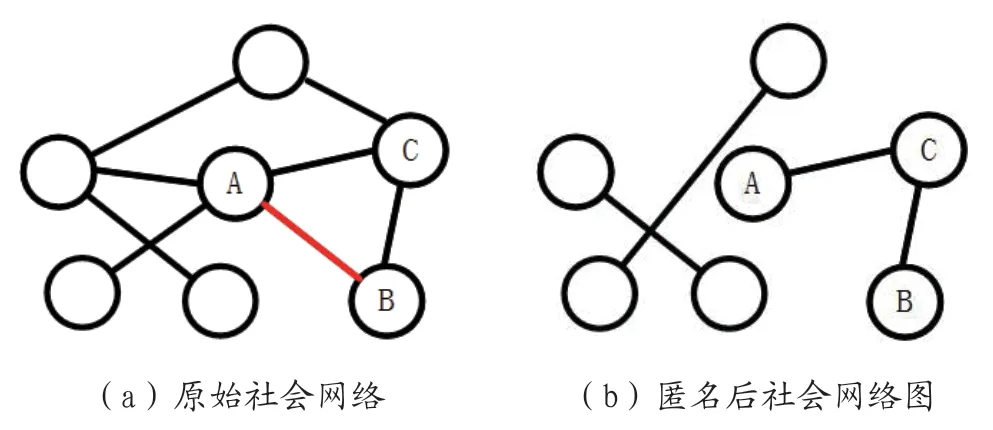
图1:社会网络隐私保护实例

图2:攻击模型中用于敏感边推断的两种子图:三角形、矩形
1 相关工作
社会网络隐私保护研究是一个热门研究领域。它起源于关系型数据的研究,而典型的k-匿名技术是由Samarati 和Sweeny[6][7]在2002年提出来的。在社交网络发布隐私保护的研究中,k-匿名是通过聚类泛化来实现的,即所有的社会网络图中的节点都被划分到n 个簇中,每个簇中节点的个数都不小于k。当发布数据时,每个簇都被泛化成一个超级节点,而簇与簇之间的边也被泛化成超边。子图匿名意味着,当攻击者将目标节点的子图信息作为背景知识时,在社会网络图中至少存在k-1 个难以区分的其他节点的子图结构。然后,利用图迁移技术使得目标节点的敏感信息被泄露的概率不高于1/k。为了保护目标节点的敏感信息,通过添加噪音和修改边来确保攻击者在发布的社会网络图中,识别目标节点的可能性不高于一个确定的概率。该方法的优点是,它不需要改变原始社会网络数据中节点和边的个数。这在统计分析应用中具有较大的优势。
2 现有的隐私保护技术
现有的隐私保护方法如果只通过在社会网络图上增删边,极有可能使得攻击者通过分析发布的社会网络图来推断出两个节点之间的关联关系。假设图1(a),图1(b)是表示社会网络中的朋友关系,A,B 之间的关系是敏感的。如图1(a)是原始的社会网络图,如图1(b)是使用简单随机添加删除边得到的匿名后的社会网络图,我们假设攻击者拥有强大的背景知识,在此基础上攻击者通过分析频繁子图模式来预测这些隐藏链接的存在。如图1(b),攻击者极有可能推断出节点A,B 有关联。
3 基于局部扰乱的社会网络隐私保护
针对上述存在的问题,本文研究了社会网络发布中隐藏边的隐私保护问题。根据社会活动个体对隐私保护的不同要求,本文提出了一种基于社会网络的敏感边的隐私保护机制,将现有隐私保护技术与不确定图思想结合起来,设计了一种新的隐私保护方法。图2是攻击模型中用于推断的两种子图:三角形、矩形。

算法1.k—分组算法输入:原始的社会网络图G,敏感边集T 及参数k;输出:组集F;1.节点根据度数降序排列;;2.group g=new group{t};3.while |V|>k do 4.while |g|>k do 5.for each (u,v)∈E do 6.compute 7.8.9.10.End while 11.
边t 的频繁子图表示为wt,如三角形、矩形,Wt表示链接t 的频繁子图,边的权重为子图的个数|Wt|。目标边t 的相似度表示为|Wt|,目标t 的相似度是f(P,t)=|Wt|,其中目标边的相似性意味着更高的概率被推断。定义了集合T 中所有目标边的总相似度。文献[2]中TPP 算法的目的是通过删除一个有限集作为保护者来为所有的目标提供保护,以此来抵挡对抗性的边预测,该有限集是由可替换的非目标边组成,用作保护者,其中其中C 是常数。该相似度越高,则敏感边被推断出的概率就越高。本文提出的匿名方法模型,首先根据节点的度数不同,将节点按度的大小降序排列;然后根据三角形、矩形的结构特征,用权值大小表征边的相关程度,通过计算尽可能选择对三角形、矩形数量影响大的边;然后随机删除这些边;接着,对于任意边,赋予每条边一个存在概率,用来混淆边真实存在的概率;最后得出匿名图。
根据现有隐私保护模型的原理,对原始图添加删除边操作,在添加删除边的过程中,改变原始图中的频繁子图结构,同时减少对结构的破坏;对原始图中的频繁子图进行随机化处理,即三角形及矩形。

算法2.随机化算法输入:组集F;输出:匿名后的社会网络图G';1.While |F|>0 do 2.For each do 3.随机删除边(u,v),其中4.随机添加一条边(w,z),其中 且5.Sample with probability 6.End for 7.End while 8.Return G'//返回匿名图
4 实验结果和分析
4.1 实验数据集和对比算法
本文在三个数据集上对数据可用性进行测试,数据集的详细信息如表1所示,其中数据集WebK-B 是包含来自4 所大学的877 个网 站(http://linqs.umiacs.umd.edu/projects//projects/lbc/index.html),Citat-ion 数据集http://www.cs.umd.edu/projects/linqs/projects/lbc/index.html 是一个论文引用数据集,它包含2550 篇论文和6101 个引用关系。Cora (http://www.cs.umd.edu/projects/linqs/projects/lbc/index.html)数据集,该数据集是有向图,有 2708 个节点和 5429 条边。

图3:数据集WebKB

图4:数据集Citation
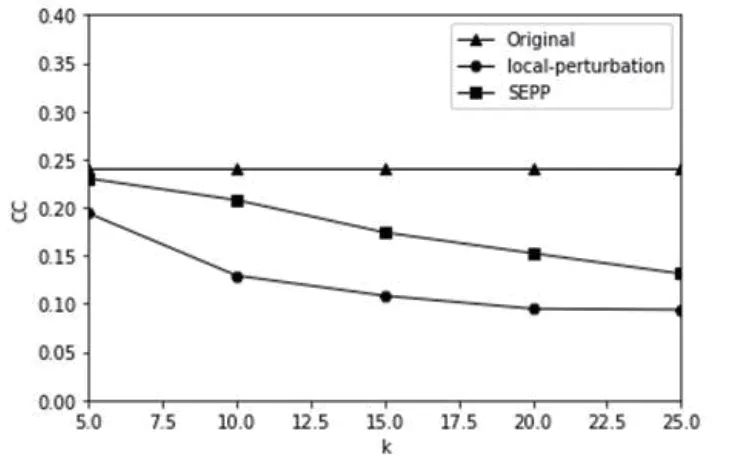
图5:数据集Core

图6:数据集WebKB
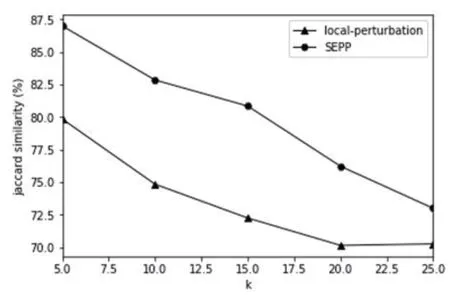
图7:数据集Citation

图8:数据集Core
4.2 实验结果和分析
本文采用平均聚类系数作为评价指标,所有的算法均保证在同一实验环境下进行,各算法在3 个数据集上的实验结果对比图见图2-图4。平均局部聚类系数越接近原始图表示算法效果越好。两种匿名方法后的社会网络图的平均局部聚集系数都呈下降趋势。如果参数k 较大,则匿名度较大,并且匿名损失将增加。图3-图5分别代表的是3 个数据集在k 的不同取值下平均局部聚类系数的变化。
图6-图8分别代表的是3 个真实数据集在不同k 值下杰卡德相似系数的变化。从整体来看,随着k 值的增加,匿名处理对原始社区具有较为严重的破坏。Local-Perturbation 方法随着k 值增加,其对应的杰卡德相似系数下降幅度较大,而本文中提出的局部扰乱数据匿名方法所对应的杰卡德相似系数下降幅度明显较弱。更明显的是,在k 的不同取值情况下,SEPP 隐私保护方法的杰卡德相似系数值较大,说明它能更好的保护社区结构。这足以证明本文提出的匿名方法能够更好地保护原始社会网络的社区结构。
5 结束语
本文提出了一种新的社会网络隐私保护算法,该算法首先利用k-分组算法,根据TPP 算法对非敏感边进行分组,然后采用随机化方法进行随机添加删除边,最后使得每条边都有相应的概率存在于社会网络中,同时使攻击者唯一识别带敏感标签个体的概率不高于1/k。因此可以达到较好的效果。详细的实验表明,本文算法能够在平均聚类系数和杰卡德相似系数上取得显著提高,能更好的保护社区结构。在今后的工作中,我们将尝试使用更先进的技术来改进算法。
猜你喜欢
自动化学报(2021年8期)2021-09-28
科学与信息化(2021年8期)2021-03-31
同济大学学报(自然科学版)(2019年2期)2019-04-02
活力(2019年21期)2019-04-01
爱你(2018年16期)2018-06-21
电子科技大学学报(2016年2期)2016-08-31
指挥与控制学报(2015年4期)2015-11-01
华东师范大学学报(自然科学版)(2014年1期)2014-04-16
重庆交通大学学报(自然科学版)(2012年4期)2012-02-09
采矿技术(2011年5期)2011-11-15
