
基于GRU深度网络的铁路短期货运量预测
2020-02-01 07:53:20张小强
铁道学报 2020年12期
谭 雪,张小强,2,3
(1.西南交通大学 交通运输与物流学院,四川 成都 611756;2.综合交通大数据应用技术国家工程实验室,四川 成都 611756;3.综合交通运输智能化国家地方联合工程实验室,四川 成都 611756)
运输市场不同方式间竞争越加激烈,铁路运输企业若要进一步提高货运市场的占有率,就必须制定并开展灵活有效的货运营销及制定高效的运输计划。这离不开准确预测计划期内的货运需求量。
目前许多学者已经在运量预测领域进行研究,但大多以年货运量作为时间粒度,对月/日货运量预测研究较少。然而短期需求量是铁路运输企业合理调配货运资源、制定运输生产计划、衡量铁路货运市场体系的重要指标。其受多种复杂因素共同作用,如政策、季节、竞争、运价、国民经济指标等,上下浮动性和季节波动性显著,具有高度非线性和深度不确定性的特点。建立精确恰当的参数化预测函数模型较为困难。本文借助深度网络对时序性数据强大的学习能力,研究结构简单且具有高效记忆功能的GRU深度网络,在充分考虑短期特征向量的选取、预处理阶段原始数据中异常清洗、模型参数设置等基础上,建立铁路短期货运量的预测模型,使月/日货运量预测更加精准。
1 国内外研究现状
现阶段时间序列问题的需求预测方法包括定性分析和定量分析。定性分析包括德尔菲法、专家会议法;定量分析又包括参数模型和非参数模型,其中参数化时间序列方法包括ARIMA、灰度模型,非参数化方法包括卡尔曼滤波器、支持向量机回归(Supported Vector Regression,SVR)、神经网络(Neural Network,NN)[1-5]等。
自然语言处理(Natural Language Processing,NLP)中的长短时记忆网络(Long Short Term Memory,LSTM)广泛用于非语言类时间序列问题。文献[6]指出LSTM NN模型既可学习长距离依赖关系又能确定最佳时间步长。在交通流预测中,LSTM NN比Elman NN、时延神经网络(Time-Delay Neural Network,TDNN)、支持向量机等有更高的预测准确率和泛化能力。文献[7]同样利用LSTM模型的记忆功能,根据城市当前各区域内的出租车出行量和出行行为信息预测后一阶段各区域的出租车需求量。文献[8]精简了LSTM单元结构,提出了门控复杂度更低的GRU结构。文献[9]将GRU应用到城市交通流多步预测中,挖掘交通流前后时间序列间的依存关系。GRU深度网络在短时间序列预测领域,原始时序数据中异常值处理对提高模型精度和鲁棒性至关重要,常规的处理办法是凭人工经验发现异常值并删除,但是该方法效率低下并且无理论依据,不适合铁路货运的大数据处理。
铁路货运需求量预测的研究中,多使用BP神经网络、广义回归神经网络(Generalized Regression Neural Network,GRNN)和径向基网络(Radial Basis Function,RBF)预测年货运量。文献[10]将AdaBoost与BP神经网络相结合,通过训练8个年货运量样本外推2个年货运量,预测精度理想,但未阐述特征向量和目标值间的相关性关系。文献[11]首先利用相关性系数筛选出最优的特征子集,又利用模糊聚类方法解决样本数据自身矛盾问题、强化高度相关指标在神经网络中的作用,最后引入GRNN进行货运量预测,但是使用该模型每个测试样本和全部训练样本都要参与计算,空间复杂度高。文献[12]采用径向基神经网络对年货运量进行预测。这三种模型预测时间粒度太大,在特征向量选择上均弱化了月份、季节等日常因素对目标值的影响,预测成果只对铁路相关部门制定年计划有借鉴作用。但就铁路运输而言,运输企业更看重短期货运需求量,用以制定月计划、灵活调整日班计划和优化货运营销办法。
因此,建立结构简单、高效的铁路短期货运量预测模型并提高精度是铁路货运部门亟待解决的问题。本文将NLP领域中的GRU深度网络与高度非线性且前后时间段相似性不强的日货运量数据结合,引入机器学习(Machine Learning,ML)中的隔离森林算法降噪,构建短期货运量预测模型。
2 GRU理论
循环门单元是LSTM的变体,也是一种特殊类型的循环神经网络(Recurrent Neutral Network,RNN)。
2.1 RNN和LSTM
传统的RNN拥有输入层-隐藏层-输出层3种结构。其基本思想是:时刻i输入为Xi,输出Yi由该时刻隐藏层节点状态Si决定,而Si由Xi和i-1时刻的Si-1共同决定。这意味着RNN网络对前时刻的记忆能力可以影响当前时刻的输出,所以广泛应用在时间序列问题建模上。
当RNN单元发展为标准的LSTM模型,隐藏层结构发生显著变化,包含1个单元和3个门:输入门、输出门和遗忘门。通过这样的模型结构设计增强了隐藏层功能,消除传统RNN网络反向传播时梯度消失或梯度爆炸的问题,可以学习长距离依赖关系。
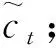

图1 LSTM隐藏层单元结构
2.2 GRU
GRU是LSTM的结构变体,隐藏层单元结构由重置门r和更新门z组成。取消了LSTM中细胞状态和输出门,将LSTM的输入门和遗忘门组合为一个单独的更新门。由于直接通过隐藏层状态ht进行信息传递,简化了LSTM的模型结构,网络复杂度较低。GRU隐藏层单元结构见图2。
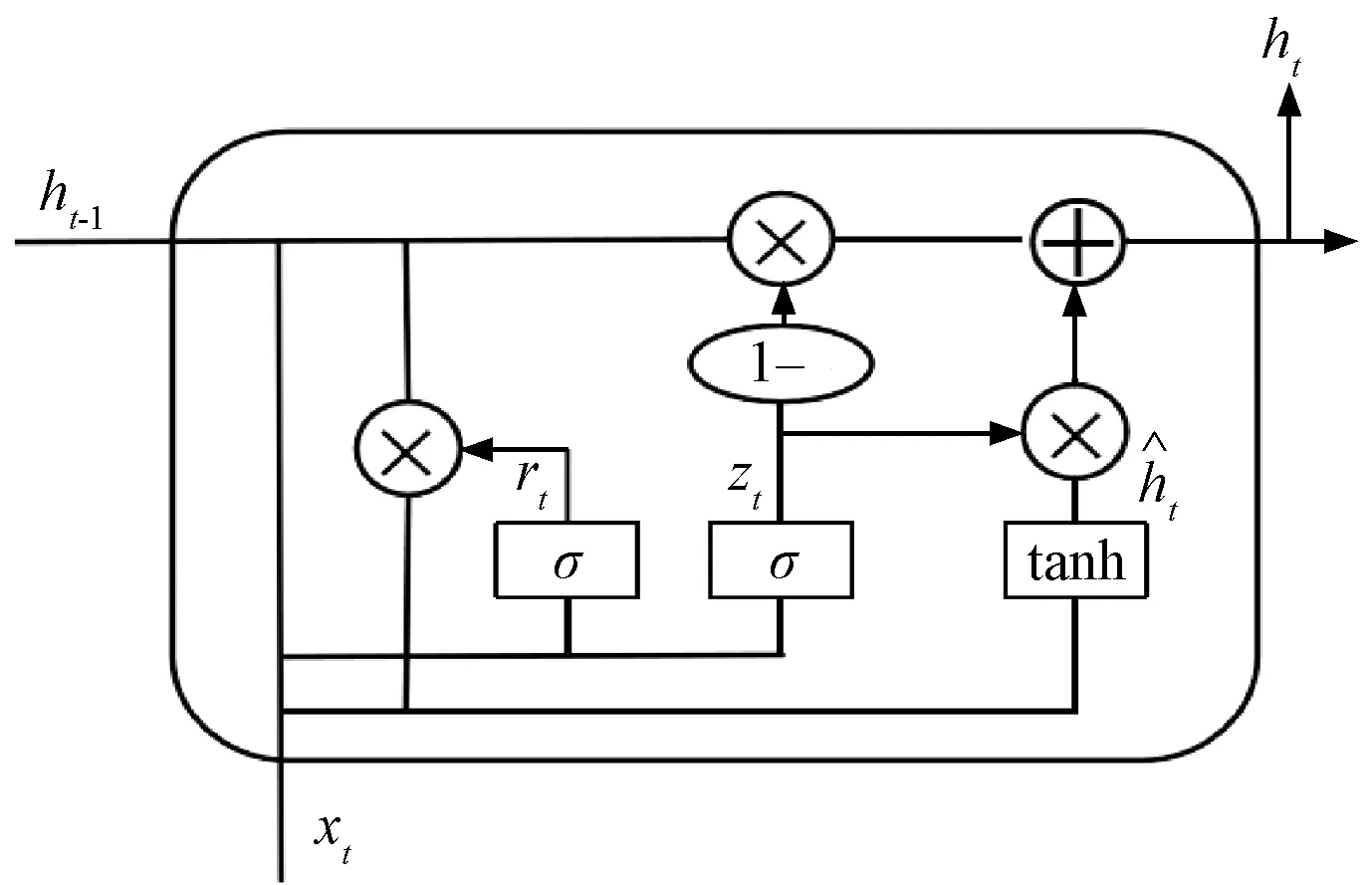
图2 GRU隐藏层单元结构
其时刻t的前向计算方法为[8]
zt=σ(Wz·[ht-1,xt]+bz)
(1)
rt=σ(Wr·[ht-1,xt]+br)
(2)
(3)
(4)
yt=σ(Wo·ht+bo)
(5)
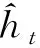
3 短期货运量预测模型构建
本文针对短期货运量预测问题,分别建立基于GRU的单步和多步预测模型。前者侧重挖掘外部影响因素及历史货运量对铁路短期货运量大小的影响,后者是在前者的基础上,可以挖掘货运量自身时序依赖关系的序列对序列(端对端)模型。为了提高输入模型的样本质量、获得更好的预测精度,在数据预处理阶段引入隔离森林进行异常值清洗。
3.1 模型结构及参数确定
两种模型均包含输入层、隐含层和输出层3层基本结构。
(1)输入层
运价、竞争、日期、天气等因素对铁路货运量的影响存在滞后性,体现为货主会根据运输市场运价水平、天气状况调整发货方式;同样铁路运输企业,也会考虑自身的近期运量水平和经济情况,改变经营决策。因此,t时刻的货运量大小yt不仅与当前时刻外部影响因素指标有关,而且与前sstep外部影响因素及历史货运量大小有联系,这里认为sstep之前的所有特征均为无关信息。
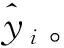
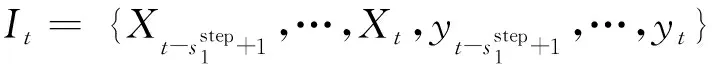
(2)隐含层
隐含层采用多层GRU单元。通过网格搜索法(Grid Search,CV)[14-15]调整超参数,如GRU中隐藏神经元的数量(hidden_dim)、堆叠循环单元的数量(隐含层数)(layers_num)、训练样本批大小(batch_size)和sstep值、学习率、训练次数等。
(3)输出层
输出层输出预测值,这里采用MSE损失函数获得预测值结果的误差大小,计算方法为
(6)
在反向传播阶段,从损失函数开始,逐层对各参数求偏导,求得所有参数梯度,再根据学习率和梯度采用梯度下降算法调整权值。
3.2 隔离森林降噪算法
深度网络预测效果的优劣取决于训练样本的数量和质量。预处理阶段识别并清洗掉与预期对象行为差异较大的异常样本,可提高模型的预测精度。
机器学习里面的异常检测算法广泛应用在分类领域中。通常采用各种统计方法、距离、密度聚类等量化指标描述样本间的疏离程度,将远离所有族中心的样本或密度极低处的样本划分异常点,即少和不同的样本点。这里我们采用隔离森林异常检测方法[16],该方法较ORCA或随机森林等在大量高维数据集异常点识别上效率、性能更优。
隔离森林进行异常检测分为两个阶段:训练阶段和检测评估阶段。
针对有n个样本的数据集X={x1,x2,…,xn},训练阶段是对X进行子抽样生成t棵随机二叉树(称隔离树,iTree)组成一个隔离森林(iForest)。
在检测评估阶段,将测试样本点x输入iForest中的每一棵iTree中,获得该样本在iTree上划入叶子节点到根节点的路径长度h(x),得到期望路径长度E(h(x))。
引入c(n)作为修正值,则x在由n个样本数据集构成的iTrees的异常分数s(x,n)为
(7)
如果样本的s(x,n)非常接近1,则该样本一定为异常值;若s(x,n)远小于0.5,可视为正常样本;如果所有样本的s(x,n)近似为0.5,那所有的样本无明显异常值。
4 案例分析
4.1 数据预处理
案例应用某铁路局2011—2017年7年间货票系统原始数据,部分数据见图3。为了使输入深度网络的货票数据具有准确性、完整性和一致性的特点,对原始数据做以下预处理:
(1)去重去废票
每一张货票有唯一的货票id和废票标志。对原始数据查证后发现,存在大量重复货票记录和废票,因此在货票id及属性值均相同的多条货票中仅保留一条,同时去掉未进行实际运输产生货运效益的废票。
(2)货票信息提取与按日期聚合
去除与货运量预测问题相关性不强的货票属性,仅保留日期、运价、计费重量三种属性,按照日期聚合获得路局当日货运总量(称日货运量,百万t),平均获得当日平均运价水平,分/t·km。
(3)隔离森林算法降噪
使用隔离森林对第二阶段按日期聚合后的日货运量数据进行异常样本检测,并剔除部分对后续深度网络训练有干扰的实际数据,最终获得2 429条能够用于模型训练的日货运量数据。

图3 2016年4月14日至2017年11月30日部分日货运量
(4)外部影响因素选取
现实中,铁路货运量受国民生产总值、产业增加值、物价指数、竞争环境、政策等经济指标和运输能力、运价水平、营运里程等路局生产指标影响,这些指标通常以月、季度和年时间段进行统计。
为保证输入深度网络参与训练的数据量,我们在选取粒度为日的外部影响因素指标时,综合考虑所选的影响因素:对短期货运量预测问题的重要度、合理性和获取难易程度;从深度网络过拟合的角度思考,也不宜选取过多因素。借鉴文献[17-20],我们确定了对铁路短期货运量预测3个非常重要且应用较多的外部影响因素:日期、当日平均运价水平和天气。
这里天气是选取该铁路局7个主要货运站所在5个城市的每日天气状况(数据来源:天气预测网),理由如下:
在对7年间货票原始数据做聚合时发现,这7个货运站点年货运发送总量稳居该铁路局前9,并且占可进行货物到发业务的全部248个站点全年发送总量的份额,从2011年的25%逐年增长至2017年的43%。
以年发货量占比衡量站点的重要程度,将这7个站确定为主要货运站,选择他们所在城市天气状况(晴、雨、雪、霾等)作为短期货运量预测的外部影响因素之一是合理的。
最终获得2 429条数据记录,每条记录间隔时间为1 d,包含当日平均运价水平、日期、天气状况和日货运量。
(5)Max-min归一化
未经标准化的连续型变量往往会导致神经网络训练失败。对输入数据集的连续型变量的数据项进行Max-min归一化,加快神经网络训练时的梯度下降速度,在测试阶段再对预测值做反归一化处理。
(10)
式中:X为原时间序列;X′为归一化后的时间序列;Xmax、Xmin分别为时间序列的最大值和最小值。
4.2 实验结果分析
我们搭建两种GRU模型,一种是将日期、当日平均运价水平和7个主要货运站所在5个城市天气状况3种外部影响因素和历史几日货运量数据,共同作为特征向量预测模型/实验中将外部影响因素和历史日货运量数据统称特征向量预测短期货运量的基于GRU的单步预测模型;另一种为既考虑所有特征向量,又可挖掘货运量时间序列关系的基于GRU的多步预测模型,以下简称GRU单步和GRU多步。
实验中所有预测模型按照2 429条数据记录的80%、20%分别划分训练集和测试集。
(1)单步预测模型参数
在Python3.7、TensorFlow1.12、Keras环境下编写GRU单步算法程序。控制其他超参数不变,sstep在{3,5,8,10,15}范围内搜索,按照单步模型在归一化后的测试集上拟合MSE最小,选择对应sstep值,见图4(a),设为5 d,即用前4天历史日货运量和5天的日期、当日平均运价水平和天气状况其他3种外部影响因素一起,预测第5天的日货运量;保持sstep=5不变,堆叠GRU层数在{1,2,3,4,7}范围内搜索,见图4(b)。其他超参数确定方法类似,最后搭建2层GRU单元和2层全连接层,隐藏神经元数量分别设为20、10、10、1;学习率设为0.01;批大小设为32;优化算法采用Adam;epochs为30时模型效果最优。
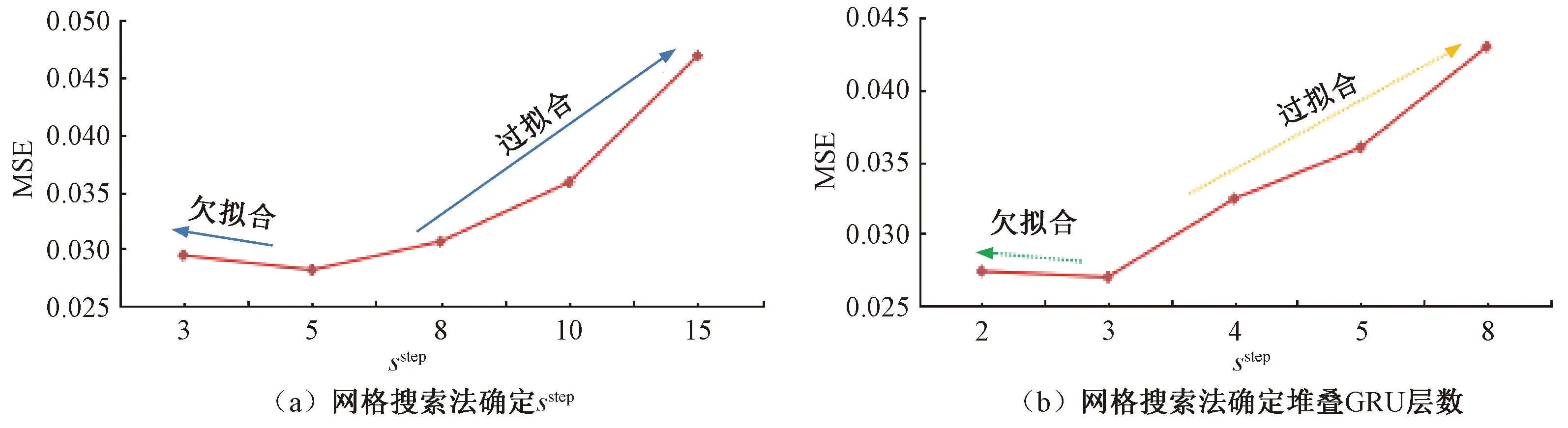
图4 网格搜索法

图5 测试集效果对比
(2)多步预测模型参数
针对预测回归类模型性能通常采用均方误差(MSE)、均方根误差(RMSE)、相对误差(MAPE)和准确率(ACC)等衡量,分别为
(11)
(12)
(13)
εACC=1-εMAPE
(14)

单步模型和多步模型在测试集上预测结果指标见表1。
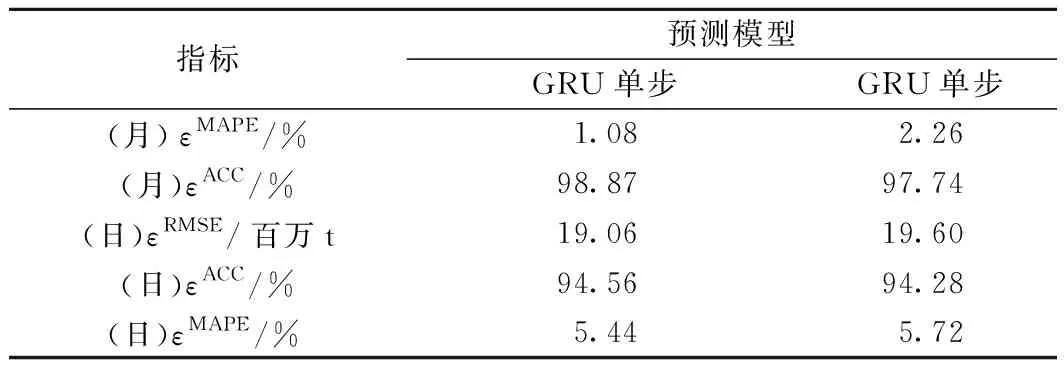
表1 模型指标对比表
由表1可知,在测试集上GRU单步模型预测铁路月货运量εACC高达98.87%,对比GRU多步模型高出1.13%;日货运量预测εACC达到94.56%,εRMSE仅为19.06,对比GRU多步模型εACC高出0.28%,εRMSE降低0.54。

现实中,农历春节一般正值2月,工矿制造企业停工,铁路货源减少,月货运量基本处于全年最低水平。图5(a)发现,2017年2月预测月货运量骤降,两种模型结果都相对精准且符合生产实际,这也检验了模型的有效性。
4.3 对比试验
为了比较GRU方法和其他经典模型在预测铁路短期货运量的性能,分别利用LSTM单步(模型结构与GRU单步类似)、SVR、XGBoost和BP神经网络对同一数据集进行大量反复试验,各模型特征向量选择及参数设置见表2。
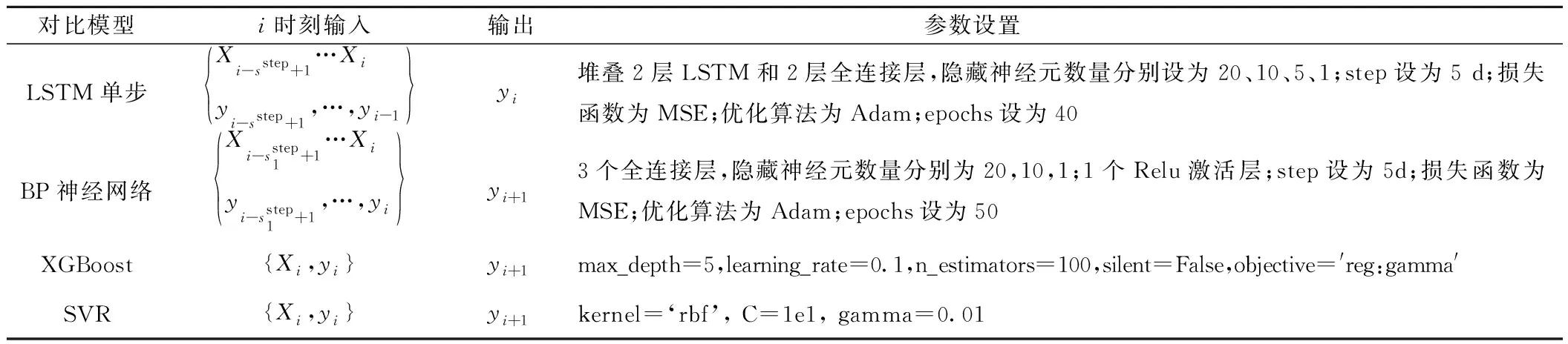
表2 对比模型特征向量选择及参数设置表
选择对比模型在测试集上最优指标结果记录,见表3。

表3 模型指标对比表
由表3和图6可知,在铁路短期货运量预测问题上,即便是GRU多步深度网络模型也总体比LSTM、SVR、XGBoost和BP神经网络性能要优。
从测试集日货运量预测指标上看,SVR可以和GRU多步模型相媲美,RMSE和MAPE仅高了0.72和0.22%。从测试集月货运量预测指标和效果图上看,XGBoost和LSTM单步的对于测试集的预测趋势和效果很接近;XGBoost模型的ACC仅低于GRU多步模型1.09%。
由此可见,GRU深度网络不但能提升模型复杂度去拟合高度非线性的短期货运量数据,并且能自适应考虑自身时序数据间的依赖性关系,所以能够有效预测铁路短期货运量。

图6 测试集月货运量预测效果对比
5 结论
本文结合某铁路局实际货运生产情况,基于Tensorflow框架建立了基于GRU的单步和多步的短期货运量预测模型。前者侧重挖掘日期、当日平均运价水平、天气状况和历史货运量对铁路短期货运量的影响;后者在单步模型的基础上,又能挖掘货运量本身时间序列间的依赖性关系。然后与ML和DL领域主流的时间序列算法模型做比较。实验结果表明:GRU单步模型的准确率在4组对比试验中最高,RMSE最小,泛化能力最强,用其预测铁路短期货运量、制定科学合理的货运月计划和日班计划、加强运输组织是可行的。
在接下来的研究中,我们会结合统计学习知识,进一步探索研究外部经济指标与铁路短期货运量之间的关系。
猜你喜欢
电子制作(2019年19期)2019-11-23 08:42:00
无人机(2018年1期)2018-07-05 09:51:00
大陆桥视野(2017年13期)2017-12-23 19:21:58
无人机(2017年10期)2017-07-06 03:04:36
专用汽车(2016年5期)2016-03-01 04:14:38
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
太空探索(2014年6期)2014-07-10 13:06:11
