
基于SSD算法的课堂行为检测研究
2020-01-26 05:49赵君龚炳江
电脑知识与技术 2020年34期
赵君 龚炳江


摘要:课堂行为是评估学生成绩和授课质量的重要参考因素。目前关于课堂行为的研究多是通过人工问卷或直接观察,准确率低且费时费力。提出使用SSD深度学习算法进行学生课堂行为识别。搜集学生上课视频和图片,经过数据预处理和数据增强操作后构成数据集。训练SSD网络模型以识别学生坐着,举手,看手机,睡觉,写作等行为。最后比较SSD、VGG16、RestNet18三个网络在行为检测方面的准确率,得出SSD模型比较出色。
关键词:行为识别;SSD;深度学习;目标检测;图像处理
中图分类号: TP391 文献标识码:A
文章编号:1009-3044(2020)34-0212-03
Abstract:Classroom behavior is an important reference factor for evaluating students' achievement and teaching quality.The current research on classroom behaviors mostly through manual questionnaires or direct observation, the accuracy is low and time-consuming. A SSD deep learning algorithm is proposed to identify students' classroom behavior. Collect students' video and go through data preprocessing to form a data set.By training the SSD network model, it is possible to recognize the behaviors of students sitting, raising their hands, watching mobile phones, sleeping, whispering, etc.Finally, the accuracy of the three networks SSD, VGG16, and RestNet18 in behavior detection is compared, and the SSD model is relatively good.
Key words:Behavior recognition; SSD; deep learning; Target detection; Image processing
1 引言
近年来,深度学习快速发展并被应用到各个领域。随着国家提出“利用智能技术加快推动人才培养模式、教学方法改革,构建包含智能学习、交互式学习的新型教育體系”[1],实现智能化教学是未来的发展趋势。学生作为课堂的主体,其行为是对课堂氛围、学习效果和授课情况等进行分析的主要依据。目前,关于使用深度学习进行学生课堂行为识别研究的论文不多。魏艳涛[1]等人通过训练VGG16模型,实现了对中学生睡觉、写字等行为的识别。提供了将深度学习用于行为识别的方法,不过准确率还不够。左国才[2]等人通过基于深度学习的人脸识别模型,采用检测眼睛和鼻子的方法来判断学生上课专注度。该研究方法对于学生状态判断比较细致,但是由于课堂中人脸容易被遮挡,因此此方法在实际应用中实施较为困难。尚伟艺[3]则通过Openpose骨骼检测的方式进行学生课堂行为识别。该方法对人体动作检测有很好的效果,不过教室中人员分布比较密集,容易出现两个人之间骨骼关键点错位的现象,进而容易造成识别错误。
目标检测方法分为传统的和基于深度学习的,两者差别主要为是否可以自动完成特征提取,因此后者准确率提升了很多。应用较多的目标检测方法有FasterR-CNN、YOLO和SSD。本文采用的SSD算法在小目标检测上略高于YOLO算法,和FasterR-CNN相差不多;在检测速度上高于FasterR-CNN,几乎和YOLO相同。综合考虑,本文使用SSD目标检测算法展开研究,为学生课堂行为检测提供了新的思路。
2 SSD算法
2.1 SSD网络结构
SSD网络结构包括可以分类图片的基础网络和辅助网络两部分,是由Liu[4]等人于2016年提出的一种基于回归的目标检测算法。本文中基础网络采用修改过的VGG16模型,将其最后的两个全连接层fc6和fc7分别改为3x3和1x1的卷积层,命名为Conv6和Conv7,然后删除最后的全连接层fc8并添加四个卷积层[5]。如图1所示。
2.2 SSD算法原理
1)使用多种尺度的特征图进行检测:从整个网络中选择Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_26这几个特征图进行预测,并且前面的尺寸大于后面的尺寸。
2)每个特征图有其特定数量和大小的先验框:先验框有正方和长方形两种形状,不同形状计算公式不同。具体计算过程如下。
① 首先计算SSD的缩放比:将当前用来检测的特诊图设为[m]层,同时假设[Sk]为[k]个先验框和真实框相比。
第一层计算缩放比的公式为:
[Sk=Smin2] (1)
其他层计算缩放比的公式为:
[Sk=Smin+Smax-Sminm-1(k-1),k∈[1,m]] (2)
通常情况下取[Smin=0.2]、[Smax=0.9],前者代表真实框比先验框的值为最小时;后者则表示值为最大时。
② 计算两个正方形的大小
通过缩放比与原始图像尺寸进行计算得到中间小正方形的大小。此时的Sk不再是缩放比,而是代表中间小正方形尺寸,则令Sk+1为后面那一层先验框的尺寸。
则外面大正方形的大小计算公式为:
[Sk'=SkSk+1] (3)
③ 計算两个长方形的大小
首先给出五种宽高比,然后根据宽高比计算长方形的宽高。
宽高比为:[αr∈{1,2,3,12,13}] (4)
宽高的计算公式为:
[wαk=Skαr,hαk=Skαr] (5)
在上面公式中可以发现,对于不同层的特征图都有其特有的先验框尺寸,就算是在同一个特征图中每个栅格的长方形大小也不同,所以可以高效检测大小形状不一的图像。
3)损失函数
SSD损失函数等于定位损失([Lloc])和置信度损失([Lconf])的加权和,其中[c]表示置信度、[l]表示预测框、[g]表示真实框、[n]表示匹配到的默认框数量、[α]表示两者的权重[6]。
损失函数公式为:
[L(x,c,l,g)=1N(Lconf(x,c)+αLloc(x,l,g))] (6)
定位损失和置信度损失的公式如下:其中[P]代表类别序号,[P=0]时表示背景;[Xij={0,1}]取1时表示检测到类别为[P]的目标,此时先验框有可以相配的真实框;[Cpi]表示预测为[P]这一类别的概率。
定位损失函数公式为:
[Lloc(x,l,g)=i∈PosNm∈{cx,xy,w,h}xkijsmoothL1(lmi-gmj)] (7)
置信度损失函数公式为:
[Lconf(x,c)=i∈PosNxPijlog(cPi)-i∈Neglog(c0i)] (8)
3 模型训练
3.1 制作数据集
1)数据采集
模型训练之前需要大量数据,目前还没有专门用于学生课堂行为识别的数据集,因此本文使用的数据集都是来源教室监控录像和网络图片。视频图像需要经过处理才能作为数据集,从其中选取包含举手、端坐、睡觉、写字、玩手机这几个动作出现比较多视频段。然后,使用OpenCV对选取的视频进行帧采样,分别选出包含以上五个动作的图片进行保存。为了保证训练的速度,尽量保证图片的大小为200k左,如果图片太大会导致训练比较慢。部分图形数据如下所示。
2)数据预处理
数据预处理在深度学习算法中是非常重要的一部分,本文使用的预处理方法有:①随机裁剪,由于SSD涉及了目标框标注问题,因此在随机裁剪后需要修改相应的目标框信息。②在训练时对图像随机添加噪声。
本文能收集的图像数据不多,但是模型训练的精度需要大量数据作为支撑,因此本文使用数据增强的方法来增加数据量。主要包括对图像进行水平、左右和随机方向翻转,水平方向和竖直方向的平移,以及随机改变图像颜色[7]。经过数据增强后,本文数据集共2500张图片。以举手这一动作为例,给出部分数据增强后的图片,如下图所示分别为左右翻转、随机翻转和竖直平移后的图片。
3)标签标注
本文使用目前常用的LabelImg图片标注工具。标注完成后图像的一些基本信息,包括存储位置、大小、类别名称都保存在xml文件中。
3.2 训练SSD网络模型
1)模型训练环境
2)模型训练过程中用到的参数
①训练集、测试集:网络训练用训练集,测试时用测试集。
②batchsize:把所有数据划分为多个小部分,几个部分就有几个batchsize,其大小直接影响模型的性能;
③训练次数(epoch):把所有数据训练完一遍;
④学习率(lr):表示损失函数中梯度下降的步长。
3)SSD模型训练过程
设置好模型参数后,将训练集放入SSD网络进行训练,该过程主要是找到和图片中提前标注好的目标框相配的先验框。先验框有可能找不到相配的目标框,也就是其范围内没有要识别的目标,将这一类先验框定位负样本,如果有的话则为正样本。如果正负样本数量相差很多,会造成损失函数值非常大。因此本文人为减少负样本数量,即在训练中去除一部分负样本,使正负的比约为1:3。
每完成一次训练就会生成一个模型,选择损失函数最低、准确率高的作为本次实验的最终模型,并对其进行测试和优化,直到达到预期效果。为了更加直观的了解训练过程,将得到的数据放到TensorBoard工具中,然后调用相关函数方法就可以看到准确率等值的变化过程。
4 实验结果分析
为了达到比较好的识别效果,本文分别设置不同的模型参数进行试验,然后通过对比选择最优参数。研究的参数主要有三个,训练集和测试集之比、batchsize大小、以及epoch的取值。
将训练集与测试集的比值作为研究对象,分析其值对结果的影响。首先将学习率设置为0.0001、batchsize设置为8,分别选择三组不同的比值,得到的结果见表2。可以看出如果想得到比较高的识别效果,应该加大训练集的量。
在上面实验的基础上,对batchsize取值展开研究。同样分别设置三个不同的取值,实验结果如表3所示。batchsize取值同时影响准确率和速度,太小会影响速度,太大则准确率不能保证,综合考虑本文选择batchsize为8。
分别设置三个不同的epoch值,实验结果如表4所示。当epoch为100时,损失函数值和准确率基本趋于稳定。所以在保证准确率的同时,为了节省训练时间,本文选择epoch为100。
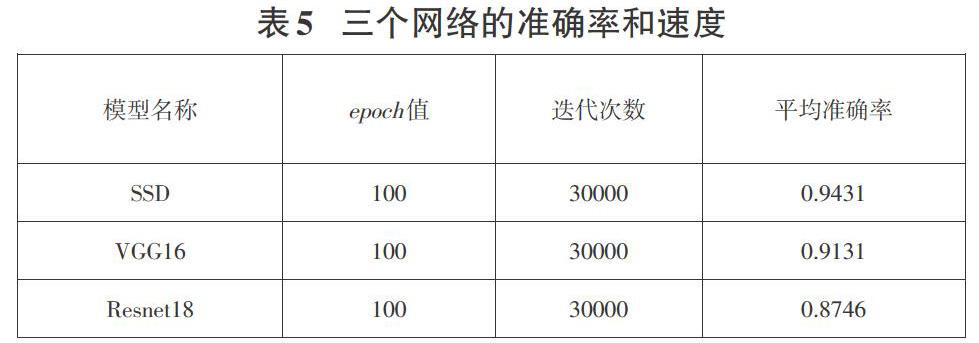
同时为了验证算法的有效性,本文在相同迭代次數和epoch值的情况下,分别选取SSD网络、VGG16网络和ResNet18网络的10次实验结果的平均准确率和速度进行对比。如表5所示,在训练相同次数的情况下,SSD模型的准确率高于VGG16和Resnet网络模型。
通过对不同参数的研究,得出当选取2250张图像作为测试集、250张为训练集,设置学习率为0.0001、batchsize为8时得到的识别准确率比较高。经过30000次迭代后,得到每个行为准确率如表6所示。其中端坐、举手、睡觉准确率比较高,分别为0.9635、0.9705、0.9531。而写字为0.8946、看手机0.8667,效果没有前面三个好。造成的原因有:一方面,看手机和写字这些动作容易受到遮挡不容易识别;另一方面,玩手机和写字两个动作比较细微,造成所采集的部分数据集中手机和笔不清楚,这样就造成关于这两个动作的数据集减少,进而导致训练时不能提取足够的特征。
5 结论
本文分析了目前常用的几种行为检测方法优劣,提出基于深度学习的SSD算法。该算法的模型训练从输入到输出都是自动完成的,包括寻找图像特征。另外SSD算法在完成动作识别的同时还可以定位目标,为针对特定一个的学生进行分析奠定了基础。实验结果表明该方法在学生行为分析方面可以取得不错的效果,例如对举手这一动作识别准确率可以达到97.05%。但是由于采集的数据集数量不够庞大、前期图像标注有轻微误差和教室环境比较复杂,关于写字和看手机这些比较小的动作识别准确率还有待提高。针对这些问题,在后续工作中将继续探讨和研究。
参考文献:
[1] 魏艳涛,秦道影,胡佳敏,等.基于深度学习的学生课堂行为识别[J].现代教育技术,2019,29(7):87-91.
[2] 左国才,韩东初,苏秀芝,等.基于深度学习人脸识别技术的课堂行为分析评测系统研究[J].智能计算机与应用,2019,9(5):135-137,141.
[3] 尚伟艺.基于视频图像的课堂点名及听课状态检测[D].大连:大连交通大学,2018.
[4] Liu W,Anguelov D,Erhan D,et al.SSD:single shot MultiBox detector[M]//Computer Vision – ECCV2016.Cham:Springer InternationalPublishing,2016:21-37.
[5] 彭昕昀,李嘉乐,李婉,等.基于SSD算法的垃圾识别分类研究[J].韶关学院学报,2019,40(6):15-20.
[6] 胡梦龙,施雨.基于SSD方法的小目标物体检测算法研究[J].现代信息科技,2020(3):5-9.
[7] man_world. 数据增强及预处理[EB/OL]. (2018-04-22)[2020-06-02]. https://blog.csdn.net/mzpmzk/article/details/80039481.
【通联编辑:唐一东】
猜你喜欢
制造技术与机床(2018年12期)2018-12-23
电子制作(2018年18期)2018-11-14
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
科学与财富(2016年28期)2016-10-14
电气化铁道(2016年4期)2016-04-16
河南科技(2014年1期)2014-02-27
