
基于机器学习的中文邮件分类研究
2020-01-26 05:49李伟羊巍刘志芳
电脑知识与技术 2020年34期
关键词:机器学习
李伟 羊巍 刘志芳


摘要:由于垃圾邮件的数量的增长,对邮件进行分类已经成为亟待解决的问题。本文提出一种基于机器学习的中文邮件分类方法,采用朴素贝叶斯算法对邮件进行处理。实验结果表明,该方法对垃圾邮件判定结果的准确率较高。
关键词:机器学习;邮件分类;朴素贝叶斯
中文分类号:TP391.3 文献标识码:A
文章编号:1009-3044(2020)34-0185-02
Abstract: With the increase of spam, it has become an urgent problem to classify email. This paper proposes a Chinese email classification method based on machine learning, which uses naive Bayesian algorithm to process emails. The experimental results show that the method has a high accuracy for spam detection results.
Keywords: Machine learning; Email Classification; naive Bayes
隨着互联网技术的发展,电子邮件的应用越来越普及,然而垃圾邮件的出现给用户带来了困扰,因此如何有效地辨别并过滤垃圾邮件变得十分必要。机器学习[1]是根据已知数据不断学习和积累经验,总结出规律并用来预测未知数据的属性,在数据挖掘领域有着十分广泛的应用。文献[2]提出了一种基于神经网络和决策树进行文本分类方法,文献[3]提出了基于互信息的加权朴素贝叶斯进行文本分类的算法。本文使用朴素贝叶斯算法对中文邮件进行分类,从大量邮件中找出垃圾邮件。
1 朴素贝叶斯算法
邮件分类结果评价标准是准确率[5],准确率等于预测对的数与总数的比值,计算公式为:
式中,A表示准确率,TP表示把正类预测为正类数,TN表示把负类预测为负类数,FN表示把正类预测为负类数,FP表示把负类预测为正类数。
2 中文邮件分类
使用朴素贝叶斯算法对中文邮件进行分类,如果邮件中包含“发票”“电话”或“促销”等词汇,并且这些词汇出现比率较高时,那么这封邮件为垃圾邮件的概率要比不包含这些词汇的邮件要大得多。本文使用Python语言的数据分析与机器学习开源库sklearn,在其扩展子库naive_bayes中,提供了三种朴素贝叶斯算法,分别为伯努利朴素贝叶斯、高斯朴素贝叶斯和多项式朴素贝叶斯,本文选择使用多项式朴素贝叶斯算法MultinomialNB进行邮件分类。使用朴素贝叶斯算法对电子邮件进行分类的步骤如图1所示,共分为六个过程。
Step 1:从邮箱中收集大量的正常邮件和垃圾邮件作为训练集;
Step 2:读取训练集内容进行预处理后,进行中文分词,保留有效词汇;
Step 3:统计训练集中每个词汇出现的次数,选取出现次数最多的前N个词汇;
Step 4:计算前N个词汇在正常邮件和垃圾邮件中出现的频率,并生成对应的特征向量,每个分量的值表示对应词汇在该邮件中出现的次数;
Step 5:根据每个邮件的特征向量和邮件的已知分类创建并训练朴素贝叶斯模型;
Step 6:对测试集邮件进行预处理后提取特征向量,使用训练好的朴素贝叶斯模型对测试邮件进行分类。
3 实验与分析
实验的数据为200封邮件,其中正常邮件100封,垃圾邮件100封,分别选取90封,共180封邮件作为训练集,剩下的20封作为测试集。实验采用Python编程实现,中文分词采用分词器jieba,它内置词典,拥有50多万个词条。程序的关键代码如下:
from numpy import np
from jieba import cut
from sklearn.naive_bayes import MultinomialNB
# 创建模型,使用训练集进行训练
model = MultinomialNB()
model.fit(vectors, labels)
#使用模型对测试集进行分类
result = model.predict(vectors)
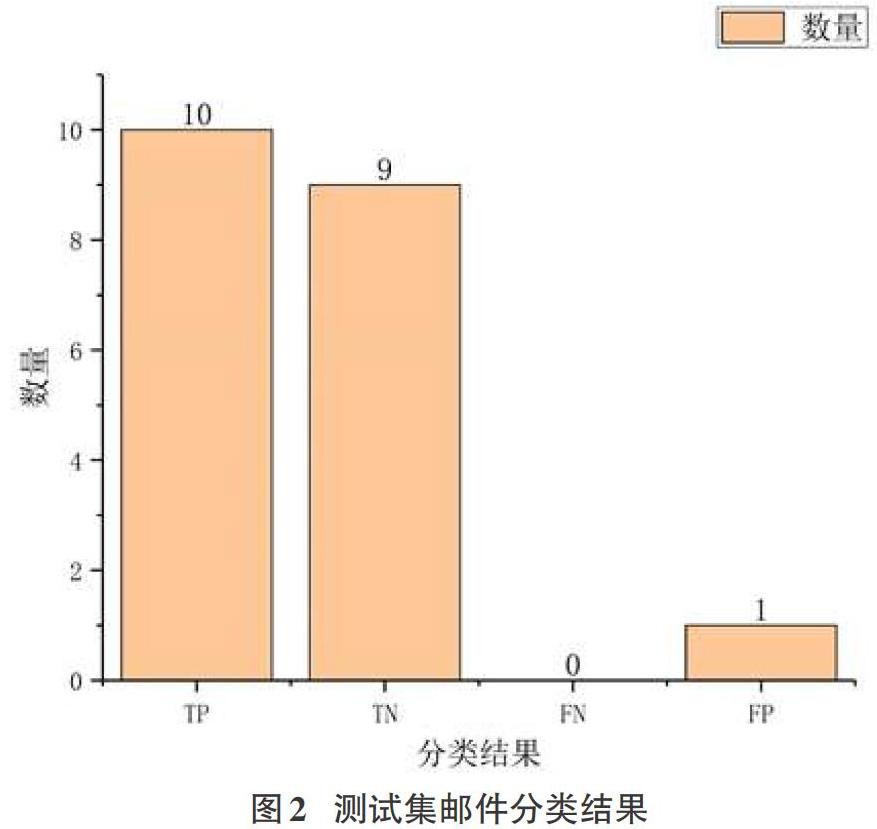
实验结果如图2所示,测试集共20封邮件(10封正常邮件、10封垃圾邮件),分类结果中将正常邮件预测为正常邮件数(TP)为10、将垃圾邮件预测为垃圾邮件数(TN)为9、将正常邮件预测为垃圾邮件数(FN)为0、将垃圾邮件预测为正常邮件数(FP)为1,计算得到实验结果的准确率为95%,符合实验预期。
4 结束语
本文提出了一种基于朴素贝叶斯算法的中文邮件分类的方法,使用Python编写程序进行了实现,最后通过实验结果表明该方法的可行性。下一步的研究工作是将该算法并行化,从而来提高系统对邮件分类的处理能力。
参考文献:
[1] 周志华. 机器学习[M]. 北京:清华大学出版社,2016.
[2] 雷飞. 基于神经网络和决策树的文本分类及其应用研究[D]. 成都:电子科技大学,2018.
[3] 武建军,李昌兵.基于互信息的加权朴素贝叶斯文本分类算法[J]. 计算机系统应用,2017(7).
[4] 梁志剑, 谢红宇, 安卫钢. 基于BiGRU和贝叶斯分类器的文本分类[J]. 计算机工程与设计,2020(2).
[5] 王行甫,杜婷. 基于属性选择的改进加权朴素贝叶斯分类算法[J].计算机系统应用,2015(8).
【通联编辑:王力】
猜你喜欢
科教导刊(2016年26期)2016-11-15
活力(2016年8期)2016-11-12
科学与财富(2016年28期)2016-10-14
